An evolution of asynchronous programming techniques to boost your Shiny apps, how a puzzle from over a century ago could tip the scales for mathematics algorithms solvable in R, and solving the recent 2024 Advent of Code puzzles with data.table.
Episode Links
Supporting the show
Episode Links
- This week's curator: Colin Fay - @colinfay@fosstodon.org [@_ColinFay]](https://twitter.com/_ColinFay) (X/Twitter) @colinfay.bsky.social
- Parallel and Asynchronous Programming in Shiny with future, promise, future_promise, and ExtendedTask
- Writing Signed Trinary: or, Back To the Four Weights Problem
- Advent of Code with data.table: Week One
- Entire issue available at rweekly.org/2024-W51
- Futureverse - A Unifying Parallelization Framework in R for Everyone https://www.futureverse.org/
- Non-blocking operations with ExtendedTask https://shiny.posit.co/r/articles/improve/nonblocking/
- Asynchronous Shiny apps with crew and mirai https://wlandau.github.io/crew/articles/shiny.html
- Bachet’s Four Weights Problem https://rworks.dev/posts/four-weights/
- Advent of Code 2024 https://adventofcode.com/
- Lime Bikes Summary Dashboard https://jokasan.github.io/Lime_Dash/
Supporting the show
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @rpodcast@podcastindex.social (Mastodon), @rpodcast.bsky.social (BlueSky) and @theRcast (X/Twitter)
- Mike Thomas: @mike_thomas@fosstodon.org (Mastodon), @mike-thomas.bsky.social (BlueSky), and @mike_ketchbrook (X/Twitter)
- J-Type - Tetris - Nostalvania - https://ocremix.org/remix/OCR04401
- I Just Skipped Time Yesterday - Puyo Puyo - Rexy - https://ocremix.org/remix/OCR03941
[00:00:03]
Eric Nantz:
Hello, friends. We are back with episode 190 of the Our Weekly Highlights podcast. This is the weekly podcast where we talk about the terrific highlights that have been shared in this week's our weekly issue available at ourweekly.org. My name is Eric Nantz, and, unfortunately, I am fine solo again this week because my awesome co host, Mike Thomas, is currently a knee deep and finishing up some really high priority work projects. I know from experience that the end of the year can be quite intensive to get these things wrapped up because anything can happen. Right? So I'll be holding the fort down today, but as usual, I never do this alone in terms of the project itself because this week's issue was curated by the esteemed Colin Faye, who had tremendous help from our fellow Aroki team members and contributors like you around the world with your awesome pull requests and suggestions.
And one little bit of admin note before we go on further, I am now recording this on my media box that my media server, I should say, that is just as of yesterday of this recording, been refreshed from the ground up to be powered by Nix OS instead of the standard Ubuntu Linux distribution. So, hopefully, you won't notice a thing in terms of listening to this, but I have been knee deep in getting things reconfigured. And I think everything's working, but, hopefully, this episode goes without a hitch. Speaking of our curator of the week, the esteemed Colin Faye himself is leading off our highlights because he has authored a terrific blog post on the think our blog on a very, very important concept to think about with not only within the computation of various data analysis task in R itself, but how it relates to you as a Shiny developer to give your users the best experience and the best response times.
This is a very difficult task, and he leads off the post with, you know, an a very humorous saying about the the 2 or 3 things that are hardest to do in computer science. And, yes, a couple of them do relate to performance, and the one we're gonna be focusing on today is asynchronous computing. And, yes, there is a lot of ways we can tackle this. But first, Colin sets the stage, if you will, to get us all, you know, in the right mindset of the different types of what I'll call performance enhancements or high performance computing aspects that you can give to your computer science type programming task.
One of those is parallel computing. This is tailored more for when you have, say, a group of things that maybe it's, you know, a set of countries in the world with a data set. Maybe it's the states in the United States in a data set. Some kind of grouping where you could do an analysis on one particular group, but that other group doesn't have any impact on it. In other words, while you could do an analysis sequentially across these different groups, it may be more advantageous to lurk look at all these groups in parallel and do separate, you know, analysis tasks for each of them.
So very much the split, apply, combine kind of mapping, reduce out, you know, paradigm that he has some nice illustrations to show how that works. And there is a very important R ecosystem that helps with this framework immensely, and that is the future set of packages. You might call it a future verse, if you will. That's, originated by Henrik Bengtsson, who I've had the great pleasure of meeting at previous RStudio Conferences. But there are many additional packages in the future ecosystem on top of the future package itself that kind of tailor to different back ends or different paradigms that you can do parallel computing.
And, yes, with certain parallel tasks, you can get massive improvements in execution time versus doing the sequential approach. But, like everything, there's trade offs. Right? So maybe parallel computing may not be the best when you have to deal with kind of the upfront cost of what Colin calls the cost of transportation, meaning that you have to somehow allocate to these different processes that are being launched kind of the setup to get things going. 1st, analyzing the code itself to figure out what are the functions that it depends on, what are packages that depends on, any data objects or other R objects that it depends on, and then writing or sending out those prerequisite objects to disk into so it can be loaded into a new R session.
And then when everything's done, you've gotta assemble everything back together. This is pretty much negligible when it comes to, like, more simpler computation task. Not so much for a task that maybe has that upfront cost that maybe takes a bit of time to transfer, and it may end up being faster if you just did it all yourself anyway. I know how that goes in real life too, and Colin's got a great example to illustrate that. So, again, the other key part to keep in mind for parallel computing is even though you are launching these different, you know, group processing on different sessions, whether it's multiple CPU cores or multiple servers, in the end, you're still waiting for that result. You just hope that you don't have to wait much longer.
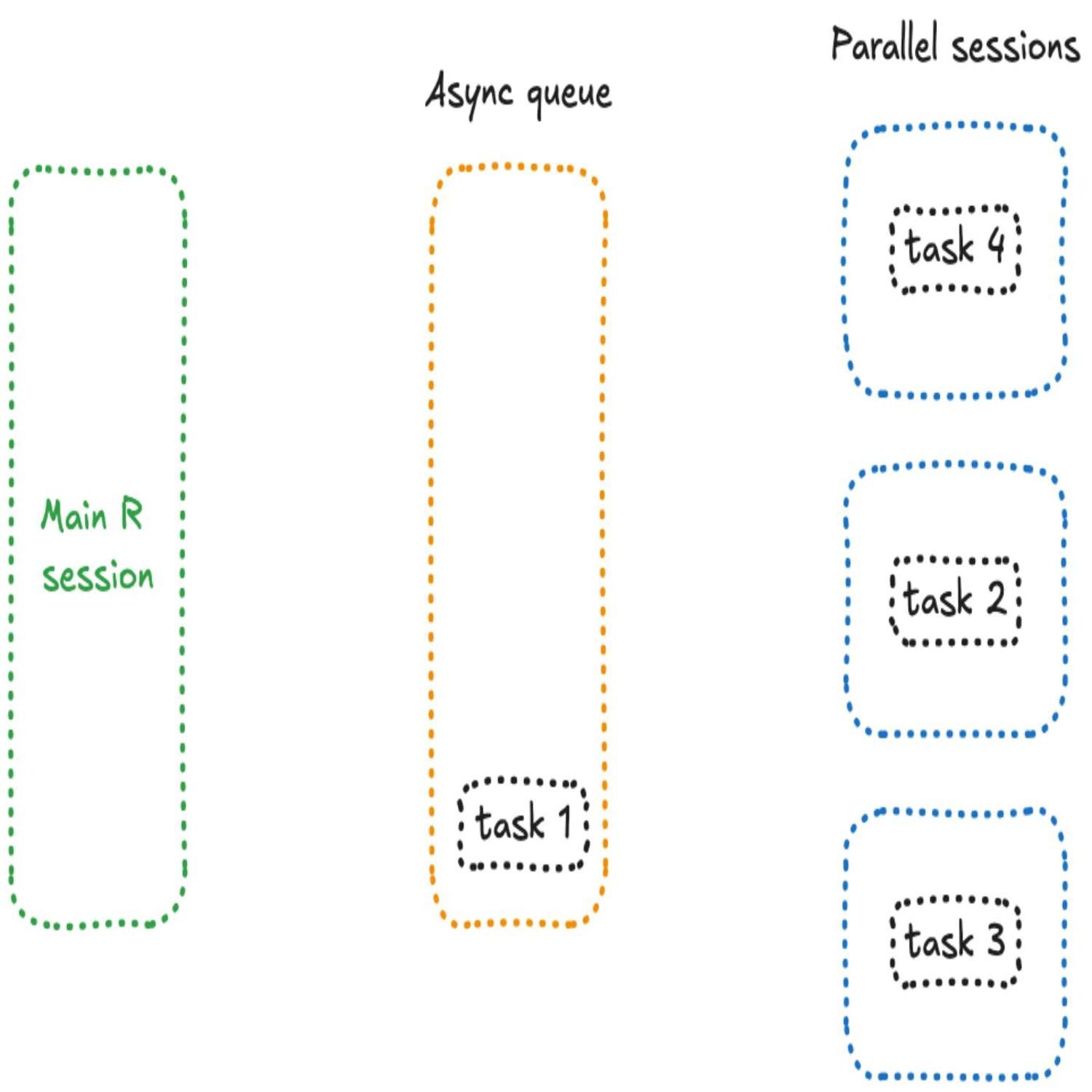
The other paradigm, especially the the meat of this post, is the concept of asynchronous programming. This is a little different because it's not so much dividing an overall, you know, dataset or or or other object into groups and then launching those in parallel, you have maybe various tasks that are, you know, maybe they're related, maybe they're not related. But you wanna make it so that you can launch those in the background and then at some point, get a check to see if they're readily available to you. That's the concept of asynchronous programming.
And, yes, the the future package can help with this too, and he's got examples in the code to show what this might look like with some contrived sleeping and and messaging. Now, another thing to keep in mind is that this is not blocking the r session. You could type over r code in the console, and then when that task is finished that you you launch in the background, a message will pop up depending on how you configure the function to do this. Now, this could be a bit of a challenge to figure out how do you manage a lot of this together, how do you track when a task is done in this asynchronous approach, and then what do you do when you actually get those results?
That's where the promise package comes in and promises, I should say, which is very much inspired by, you know, JavaScript, utilities such as promises that come fundamental of modern JavaScript languages. The promises package kind of gives you that same paradigm where you can define then what happens for a given function that when the result is done or when things go wrong, I e, what should what should it output or what should it return when there's an error in that execution? And then what do you want the user to see or return from when everything is done, whether it worked or not? So there's a good example here about how to tie the 2 together, future and promises in an arbitrary type of function setup.
And you can see that you can, you know, define these 3, you know, these 3, scenarios. What happens when it works? What happens when it doesn't work? And no matter what, what happens when everything is done? This, you may be wondering, okay. That's great, Eric. What does this have to do with Shiny? Right? Well, in Shiny, you definitely want to think about asynchronous programming, especially in the scenario that Colin outlines here when you have multiple users, you know, re using your app at the same time, the traditional paradigm in r, which is affected by Shiny as well, is it's single threaded, I e one overall process running that execution.
Hence, if you don't build asynchronous programming in your Shiny app, if you have 2 users and 1 user starts to launch a task, it maybe takes, you know, a handful of seconds or even a minute to complete. That other user, when they launch that same Shiny app and they hit that button, they have to wait to even start their back their analysis until that first user has completed their task because there's one session per app in a typical execution in R itself. So the good news is everything we just talked about of asynchronous programming can be used in Shiny as well.
The previous generation of this that he starts off with was this combination of future and promises, and it was many years ago at a Rstudio conference that Joe Cheng, the author of shiny himself, had this interesting example of what he called the cranwhales app to show how he could optimize a shiny app in production, and it was using the same integration of future and promises. Now the way they configure this is, again, building upon the the more, streamlined example of the r process itself. But Colin has an example here where it's using what he calls a multi session future plan, which means that asynchronous task is gonna be spun on multiple r processes with 3 workers. We'll keep that in mind for later.
And then based on hitting a button that will basically, format the the current date and time, he defines then the function wrapped in or the set of code wrapped in future to generate a random normal distribution. With a set of numbers and then defining what happens when the result works, when the result fails, and then what happens when everything is done. This takes a bit of bookkeeping to set up, but there is one important assumption to make here. If there are more than 3 users, let's say a 4th user goes to this app, the first three users are able to launch their task when they hit that button in parallel.
But that 4th user, oh, no. Sad panda face. They have to wait because everything is blocked because that meant there were 4 future sessions launched in 3 sessions, and when those sessions are busy that other users gotta wait. So there could be improvements in this, and yes, there are. There is a wrapper combining these two concepts of future and promise called future underscore promise is that you can now launch this asynchronous type processing, get a queue going, and then as these, sessions finish, it can then launch new ones that come as soon as one of those workers become available instead of all the workers being available.
That's a nuance there, and he's got a nice illustration to show this in action along with the revised code to to launch this. So, again, the setup looks pretty similar. You're just swapping in, future underscore promise instead of future. This is working better. But there but, again, that 4th user will still have to wait a little bit until at least one of those three tasks finishes from the previous three users. But there is a new paradigm, something we've covered on our wiki highlights a while back this year, the extended task function that now comes native since shiny version 1.8.1, which is giving you an r six class to provide native asynchronous support without a lot of the what I'll affectionately call somewhat odd setup that the future and promises, package and a shiny or a combination and a shiny app required you to do. You will see the example when you read the post, but it was never quite intuitive to me.
Extended task is in the right direction. I would say to make things a bit easier because you're creating a new task with an r six object, putting in your future promise, where, again, some of that boilerplate still in there. But this is going to help the user experience quite a bit because you get some nice helpers with this as well, such as having a button in your Shiny app that can be automatically relabeled on the spot when the user clicks it to give them an indication that something is happening. So you get a little processing message on that button when they hit the button so this is again a great improvement to help unify things a bit more and extended tasks has some really nice documentation that we'll link in the show notes as well.
So when I saw this post, of course, I love seeing, you know, very, you know, detailed, you know, overviews of asynchronous programming because it is such an important concept in Shiny development. But I did have another thing in mind that could be put in this same paradigm, but I'm gonna flip the script a little bit. Colin is coming at this from multiple users, accessing an application at the same time. That's not always the case. I have situations, and I know many others in it in the in the industry do, where it's not so much many users hitting the app at once, but one user, their experience of running the app, they may want to launch something that's gonna take a while, but yet do other things in the app without the whole session being blocked. So what's I call within session, asynchronous programming is desired.
And for this, yes, extended tasks can be used in this as well, but I do dare say that the combination of Will Landau's crew package with Charlie Gao's MirrorEye package can be a really attractive paradigm for you as a shiny developer. If you know there are gonna be tasks launched in your shiny app that could be as simple or extremely complex, crew with MirrorEye is gonna give you an elegant way to launch these workers without really knowing ahead of time how many to launch per se. It's gonna kind of adapt to it. It's got some defaults that you can tweak, but the example that I'll link to in the show notes is from the vignette of KRU where they have a shiny app where you can hit a button and and simulate basically 1,000 coin flips.
The default version of this, the output of, like, the heads, tails, and the number of flips is very laggy, the update, because everything's kind of being done in one overall process. But with crew and MirrorEye, when you hit that button, it's like looking at a a speedometer, and it just continuously increases faster, and you could be able to type the the numbers. It is amazing to watch. So I would say if you're in this paradigm of within session trying to optimize the performance as best as possible, KRU and Mirai is a combination you definitely want to look at. And the good news is that Will and Charlie have also talked to Joe Cheng about this, and he's been playing with it too. So there may be more integrations between these two paradigms of shiny's extended task and Mirai and Krue in the near future.
Nonetheless, a terrific post by Colin on what can be an extremely difficult concept to master as a shiny developer for many many different reasons, but this is a great way to get started and I invite you to check out these terrific resources in the blog post as well as Will's and Charlie's crew and Mirai package respectively. Oh, there's that time of year wherever you're, you know, getting some much needed time off from the day job, spending time with family or friends or whatnot. You might get a little downtime once in a while, and you wanna, you know, maybe do something interesting and challenging for yourself.
There's definitely an appetite to look at different, you know, various puzzles, especially with coding, which we'll get to in a little bit. But there are some really interesting ways to challenge yourself yourself from very, you know, historical yet very interesting publications from centuries ago. And our next highlight here is giving you a little brain teaser to work on, and, yes, you can use R to help out with it. Data scientist Nina Zumo, who is a consultant for the WinVector consultancy firm, she has a new post on the Rworks blog, which, by the way, I wanna give kudos to R Works because I don't think we've talked about very specifically on this on the show.
This is kind of the spiritual successor to Joe Rickert's immensely successful and highly acclaimed our views blog posts that you would have from his days of revolutions computing in that posit as well. But this is kind of like the next generation of that, and Joe is one of the editors of this along with Isabel Velasquez, but they give you the opportunity to put posts on their blog if you if you wish to contribute. It looks like Nina took them up on this offer multiple times. Nonetheless, what Nina's talking about here is a a great brain cheeser with mathematics that you can, you know, you actually use r to help solve, and this is rooted into the 4 weights problem, which has a long history in it itself.
This was from a article author by Henry Dunanese, from The Strand Magazine back in December of 1908. That's over a 100 years ago, folks. But, yes, this has all been digitally archived, so we can learn from this too. And the basic premise of what it's called the 4 weights problem, think of having a scale that can be bound a weighing scale that has, you know, two sides left and right, and the object is to find 4 weights. They all can't be the same of 4, say, weighted objects that in the integer range of 1 to 40 can be put on these two levers of the weighted scale and still be balanced together.
That sounds it already sounds complicated to me. I mean, this would take me a few maybe a few hours, if not longer, to sit down and do. But you want to be able to find what are the best ways to get to this solution. So you one thing is just find the values that could work that could, you know, add up to the value of 40 without going over. But then how do you balance that together? So so the fundamental paradigm behind a teaser, a brain teaser like this, if you will, is that this is kind of based on a a different type of arithmetic, maybe, than what you may be doing in your day to day because, you know, that she she introduces that there are weights of 1, 3, 9, and 27 that could satisfy this, but you have to figure out then what this unknown quantity x to make sure that on one side of the scale that we can distribute these weights so that the scale actually balances. And, yes, that is somewhat contrived because you wouldn't have to weigh everything if you already know it ahead of time, but this is rooted into modular arithmetic for how you can solve this.
So she starts with kinda, you know, figuring out the best way to kind of change our thinking of this with this unknown quantity x, and how do we shift our lens of this to a base n type representation. This is where it'll get, you know, a little complicated to summarize in audio. But the idea is that you have this you want to represent a non negative integer with up to m digits and binary representation. And if you recall, binary digits can be represented by any number in a range from 0 to some arbitrary m of 2 to the power n minus 1. So there's some pseudo code here to look at the different ways we can transform this x into base 2 notation, and in the end get to a trinary representation of this that can satisfy these requirements. And, yes, there is some neat r code.
To do this, she's got a handy function called basen that will convert that x to it's a base end representation. And it's got a, you know, a simple while loop that based on certain conditions trying to figure out the the best way to represent that. And we can see then that when we want to convert 13 to binary, we can use this function feed in 13 as a verse parameter, and then the base of this notation is usually 2 by default and the number of digits for maximum. And in the end for this example of 13 we get the result of 1, 1, 9, and 1 and then that can be converted to what's called a ternary representation with another function that she has constructed called 2 decimal, where we're gonna feed in the the number of digits to put in that, and hence we get 9,298 as the result to convert that to 18.
So now that that gives us ground in for it to come into base functions. Going back to that 4 weights problem, we've got to now figure out with an equation that she writes here these for the for the x these different kind of coefficients, if you will, in front of these 4 weights and figuring out what are the the the coefficients that we can put in front of that. So, again, some nice r code to kind of loop through this with a a function that she wraps. She calls it way to take this x. And, again, we got, you know, bounded by 40 or or or less. Otherwise, it'll be out of the range. She's got some arithmetic to figure this out, as well as scaling the notation as well, which can be helpful to get that trinary representation in that. And then she gives some examples of trying these functions out, and you can see that we've got a few few different options here.
And in the end, the answer that she comes up with is on one side of the weight scale. You put 1 and 3, weights of 1 and 3, and then the other side is just gonna be the the leftover of x. So there's a well, a few different ways that they carry this out. She's got multiple examples here. But, in the end, I think this is something you're gonna have to sit down with it a bit and maybe, again, try to challenge yourself in some of these other puzzles that could be found in publications like this. But it goes to show you that with basic arithmetic, yeah, R can do just as well as any other programming language to convert, you know, the the pseudo code that you're kind of going through in your head as you come up with an algorithm to fit for purpose functions that can tease this out. And we'll have a link in the show notes as well to Nino's, first Nino's, first blog post about this. It gives more background on kind of the the other ways you could tackle this.
But, yeah, very good brain teaser. I didn't do it justice in audio, but you're invited to check it out if you wanna challenge yourself a bit when you get some downtime this, holiday season. And speaking of challenging yourself, I did allude to a bit earlier, this is also a very popular time of year to challenge yourself with some coding puzzles, too. And the one, you know, area that gets, gets spun up almost every holiday season for the past many years has been the advent of code, where for every day in this advent calendar, a new coding puzzle is released, and you're invited to use whatever language suits your fancy to solve these these challenging problems.
I admit it's on my bucket list to be able to do this someday. I just haven't had as much time yet to do it, but maybe someday I will, maybe in retirement or whatever. But that's not that's not soon for sure. Nonetheless, there is there is some great opportunities to leverage your favorite data science language, such as R, to handle this. And, of course, within R itself, there are many different ways to tackle this too with various packages and whatnot. And so our our last highlight today is authored by Kelly Baldwin, who is a assistant professor of statistics at the California Polytechnic Unif State University, and she's actually authoring this on the data dot table blog, the our data table community blog, to be specific, because she wanted to challenge herself.
She's, again, always been, you know, very happy about the Advent or Code series of puzzles, and she wanted to see, you know what? Just see what it takes to use data dot table and some of these puzzles. So that is really awesome. This blog post has actually been updated with with a couple solutions here based on the puzzles that started on December 1st. And so the first puzzle in this advent of code for this year is a bit of a warm up if you will where you have 2 lists. You might say 2 columns of numbers, and the goal is to compute the distance between the adjacent elements of these lists. But you want to do it from the least, you know, the smallest number first and one list and then the smallest number on the right list. And then kind of keep, you know, sorting accordingly to figure this out in the most elegant way that you can. And so with data. Table, Kelly shows that this can be a pretty straightforward operation where you're just simply using its, sort function to basically mutate in place, if you will, or change the variable in place after reading this text file, and then create a new variable called diff, which is again the absolute value between those two numbers, and then computing the sum of that at the end.
That was pretty straightforward. Basically, four lines of code with data dot table, you know, not too challenging there. And then part 2 is a a little bit different because you can do things a little because in part 2 in part 2, she is now looking at the kind of distance or similarity, if you will, between these these two these different types of distances that have been computed. And sure enough, that's yet another variable that you can assign in data dot table as the sum of the previous of the variable where the or the sum when the value in the first column is equal to the the the various values in the second column only when they're equal, multiply that by the other variable variable one value itself, but then grouping it by those unique values in the first list and then summing up that similarity calculation.
Again, two lines of code for that one. So, again, pretty pretty straightforward once you open that text file to solve that with data dot table. And then there is yet another puzzle that has multiple parts to this as well from December 2nd, where the background of this this puzzle is there are certain reports that basically can be represented, by one line in a in a matrix, and that the report is a list of numbers called levels, which are basically the columns. So in the example that I will link to in the in the show notes or, I should say, the problem in the show notes has 5 levels, 5 columns for each report list, but the goal is to, quote unquote, find when these variable reports are safe, which basically means that the levels are either all increasing or all decreasing, and any 2 adjacent levels differ by at least 1 and at most 3.
So those are 2 constraints to keep in mind. So this this could be a bit of a challenge. Right? So again, what can data dot table do here? So after importing this, this, set of data, Kelly defines a function called check report, where it's gonna determine if these this vector of numbers, in this case kind of like the list in that report vector, if they have negative or positive integers, and then be able to figure out then for whether it's too big or whether it's increasing or decreasing, an indicator for that, and then returning whether that was increasing or decreasing, and if it's not too big. So basically, the report will the check report function will return true if those conditions are met and false otherwise.
So she takes this report, the dataset, transposes it first, and then with data dot table basically computes then for the different, for the different deltas between these different columns in in the dataset applying wherever it works in a check report fashion. So it's kind of doing column wise, but applying that with the apply function on each of these and sure enough she was able to determine that those are those are working well. And then in part 2, she has a function of testing all this to make sure that this is working as well, and sure enough it it is as well. So she wasn't very happy about using the apply function for some of this, so she wanted to, you know, make see if there's another way to do it. And, yes, in data dot table, there is yet another way, another way to do it with data dot table itself where she's using the call sums function.
You know, I should say the call sums function wrapping those, those various calls or those indicators that you can use after you compute those deltas. And, again, very very similar. And she hasn't done anything with data dot table yet for December 3rd or 7th, but we'll check back on the blog as as we progress in Advent of Code to see where this shakes out. So, again, Advent of Code, fun little puzzles to entertain yourself, you know, with some fun challenging exercises. I heard I believe they get harder as as the as the time goes on. But again, there's no nothing's too easy here, so to speak. So great way to challenge your challenge your, skills here and use a little r and your favorite package like data dot table in the process.
And, of course, there's a lot more in this terrific issue of rweekly that Colin Faye has curated for us this week. So I'll take another minute here for my additional find that I wanna talk about here in this issue. And you know me, I always like to see a really great showcase of data science in action with analysis and visualization, and there is a wonderful dashboard that has been contributed to this issue called the Lime bike analysis. This has been authored by Nils Indetrin. And if I had to guess, yes, indeed, my spider senses are correct. This is actually actually a flex dashboard.
Retro, so to speak, with our markdown. But when you look at this, it looks absolutely terrific. And that what a Lime bike actually is, It's an electric bike and scooter sharing company, and they have, you know, they are in various cities around the world. And so they're look this dashboard is looking at from a single Lime bike account in London the different total distances by month and day of week that have been traveled, a nice little set of dashboard icons at the top, and an interactive map looking at the concentration of the trip start and end locations, and another tab for estimated costs.
And boy oh boy, these charts are powered by e charts for r and high charter and leaflet for the math visualization. Really elegant looking dashboard. Lots of great ideas that you could take everyone is stick with flex dashboard or even use this with quartile dashboards as well. Just love the interactivities. These plots just look amazing here, like, interactive clicking. I'm playing with it right now as I speak. Really fun to explore here. So credit to Niles for creating this terrific dashboard. And, again, there's no shiny involved here. This is rendered, if I had to guess, via either GitHub actions or just rendered on the spot when he committed this on on the repo. But lots of lots of great ideas to take from the source code here, so I invite you to check that out as well as the rest of the r weekly issue. We've got a lot of terrific content here for you to look at, but also it is getting near the end of the year, and we may have one issue left for the rest of the year, but we could always use your help for helping with the project, and that can be through your great blog post that you've either authored or you found online, maybe a great new package that has been very helpful to your workflows, or even other great content out there in the art community.
We'd love to hear about it, so you can send us a poll request at r wiki.org. There's a little Octocat icon at the top that'll take you to this week's current issue draft where you can get a template going when you submit a poll request. We have a nice set of pre filled, you know, notes that you can use to figure out which category your contribution goes in, but our curator, Faric, will be glad to merge that in for you. And, also, we love hearing from you on this podcast. We have a lot of a few different ways to do that. You can get in touch with us via the contact page and the episode show notes on your favorite podcast player here. It'll be directly linked there.
You can also send us a fun little boost along the way if you're listening on a modern podcast app like Podverse or Fountain, Cast O Matic. There's a whole bunch out there. You have all details in in the show notes as well. And you can find me on social media these days. I am mostly on Mastodon. I am with the handle at our podcast at podcast index.social. You can also find me on Blue Sky recently, or I'm at our podcast dot bsky dot social, I believe. Either way, it's in the show notes. I just haven't memorized it yet. You can also find me on LinkedIn. You can search my name, and you'll find me there. And just a little programming note, this may be the last episode of 2024 because my, my 2 little ones are not so little anymore, but their time off of school is starting later this week, and we want to spend some good quality time together. So I'll probably be not doing as much technology things and won't have as much focus time to do an episode. But, nonetheless, I definitely thank each and every one of you that have stuck with us throughout the year and have enjoyed our weekly and contributed to the project and contributed your kudos to this podcast.
Again, we love hearing from you. It always is a a great pick me up when we see these great comments, whether it's Blue Sky or her Mastodon or LinkedIn or whatever. We we enjoy the feedback. So with that, I'm gonna close-up shop here. I I fly solo today, and it probably showed, but I did the best I could nonetheless. But, again, hope you all have a wonderful rest of your year in 2024 with however you wanna celebrate holidays, time with family and friends. Enjoy it. Hopefully, you get some good rest and recharge with next year. But, nonetheless, that's gonna close-up shop here for episode 190 of our weekly highlights, and we'll be back with a new episode of our weekly highlights in 2025.
Hello, friends. We are back with episode 190 of the Our Weekly Highlights podcast. This is the weekly podcast where we talk about the terrific highlights that have been shared in this week's our weekly issue available at ourweekly.org. My name is Eric Nantz, and, unfortunately, I am fine solo again this week because my awesome co host, Mike Thomas, is currently a knee deep and finishing up some really high priority work projects. I know from experience that the end of the year can be quite intensive to get these things wrapped up because anything can happen. Right? So I'll be holding the fort down today, but as usual, I never do this alone in terms of the project itself because this week's issue was curated by the esteemed Colin Faye, who had tremendous help from our fellow Aroki team members and contributors like you around the world with your awesome pull requests and suggestions.
And one little bit of admin note before we go on further, I am now recording this on my media box that my media server, I should say, that is just as of yesterday of this recording, been refreshed from the ground up to be powered by Nix OS instead of the standard Ubuntu Linux distribution. So, hopefully, you won't notice a thing in terms of listening to this, but I have been knee deep in getting things reconfigured. And I think everything's working, but, hopefully, this episode goes without a hitch. Speaking of our curator of the week, the esteemed Colin Faye himself is leading off our highlights because he has authored a terrific blog post on the think our blog on a very, very important concept to think about with not only within the computation of various data analysis task in R itself, but how it relates to you as a Shiny developer to give your users the best experience and the best response times.
This is a very difficult task, and he leads off the post with, you know, an a very humorous saying about the the 2 or 3 things that are hardest to do in computer science. And, yes, a couple of them do relate to performance, and the one we're gonna be focusing on today is asynchronous computing. And, yes, there is a lot of ways we can tackle this. But first, Colin sets the stage, if you will, to get us all, you know, in the right mindset of the different types of what I'll call performance enhancements or high performance computing aspects that you can give to your computer science type programming task.
One of those is parallel computing. This is tailored more for when you have, say, a group of things that maybe it's, you know, a set of countries in the world with a data set. Maybe it's the states in the United States in a data set. Some kind of grouping where you could do an analysis on one particular group, but that other group doesn't have any impact on it. In other words, while you could do an analysis sequentially across these different groups, it may be more advantageous to lurk look at all these groups in parallel and do separate, you know, analysis tasks for each of them.
So very much the split, apply, combine kind of mapping, reduce out, you know, paradigm that he has some nice illustrations to show how that works. And there is a very important R ecosystem that helps with this framework immensely, and that is the future set of packages. You might call it a future verse, if you will. That's, originated by Henrik Bengtsson, who I've had the great pleasure of meeting at previous RStudio Conferences. But there are many additional packages in the future ecosystem on top of the future package itself that kind of tailor to different back ends or different paradigms that you can do parallel computing.
And, yes, with certain parallel tasks, you can get massive improvements in execution time versus doing the sequential approach. But, like everything, there's trade offs. Right? So maybe parallel computing may not be the best when you have to deal with kind of the upfront cost of what Colin calls the cost of transportation, meaning that you have to somehow allocate to these different processes that are being launched kind of the setup to get things going. 1st, analyzing the code itself to figure out what are the functions that it depends on, what are packages that depends on, any data objects or other R objects that it depends on, and then writing or sending out those prerequisite objects to disk into so it can be loaded into a new R session.
And then when everything's done, you've gotta assemble everything back together. This is pretty much negligible when it comes to, like, more simpler computation task. Not so much for a task that maybe has that upfront cost that maybe takes a bit of time to transfer, and it may end up being faster if you just did it all yourself anyway. I know how that goes in real life too, and Colin's got a great example to illustrate that. So, again, the other key part to keep in mind for parallel computing is even though you are launching these different, you know, group processing on different sessions, whether it's multiple CPU cores or multiple servers, in the end, you're still waiting for that result. You just hope that you don't have to wait much longer.
The other paradigm, especially the the meat of this post, is the concept of asynchronous programming. This is a little different because it's not so much dividing an overall, you know, dataset or or or other object into groups and then launching those in parallel, you have maybe various tasks that are, you know, maybe they're related, maybe they're not related. But you wanna make it so that you can launch those in the background and then at some point, get a check to see if they're readily available to you. That's the concept of asynchronous programming.
And, yes, the the future package can help with this too, and he's got examples in the code to show what this might look like with some contrived sleeping and and messaging. Now, another thing to keep in mind is that this is not blocking the r session. You could type over r code in the console, and then when that task is finished that you you launch in the background, a message will pop up depending on how you configure the function to do this. Now, this could be a bit of a challenge to figure out how do you manage a lot of this together, how do you track when a task is done in this asynchronous approach, and then what do you do when you actually get those results?
That's where the promise package comes in and promises, I should say, which is very much inspired by, you know, JavaScript, utilities such as promises that come fundamental of modern JavaScript languages. The promises package kind of gives you that same paradigm where you can define then what happens for a given function that when the result is done or when things go wrong, I e, what should what should it output or what should it return when there's an error in that execution? And then what do you want the user to see or return from when everything is done, whether it worked or not? So there's a good example here about how to tie the 2 together, future and promises in an arbitrary type of function setup.
And you can see that you can, you know, define these 3, you know, these 3, scenarios. What happens when it works? What happens when it doesn't work? And no matter what, what happens when everything is done? This, you may be wondering, okay. That's great, Eric. What does this have to do with Shiny? Right? Well, in Shiny, you definitely want to think about asynchronous programming, especially in the scenario that Colin outlines here when you have multiple users, you know, re using your app at the same time, the traditional paradigm in r, which is affected by Shiny as well, is it's single threaded, I e one overall process running that execution.
Hence, if you don't build asynchronous programming in your Shiny app, if you have 2 users and 1 user starts to launch a task, it maybe takes, you know, a handful of seconds or even a minute to complete. That other user, when they launch that same Shiny app and they hit that button, they have to wait to even start their back their analysis until that first user has completed their task because there's one session per app in a typical execution in R itself. So the good news is everything we just talked about of asynchronous programming can be used in Shiny as well.
The previous generation of this that he starts off with was this combination of future and promises, and it was many years ago at a Rstudio conference that Joe Cheng, the author of shiny himself, had this interesting example of what he called the cranwhales app to show how he could optimize a shiny app in production, and it was using the same integration of future and promises. Now the way they configure this is, again, building upon the the more, streamlined example of the r process itself. But Colin has an example here where it's using what he calls a multi session future plan, which means that asynchronous task is gonna be spun on multiple r processes with 3 workers. We'll keep that in mind for later.
And then based on hitting a button that will basically, format the the current date and time, he defines then the function wrapped in or the set of code wrapped in future to generate a random normal distribution. With a set of numbers and then defining what happens when the result works, when the result fails, and then what happens when everything is done. This takes a bit of bookkeeping to set up, but there is one important assumption to make here. If there are more than 3 users, let's say a 4th user goes to this app, the first three users are able to launch their task when they hit that button in parallel.
But that 4th user, oh, no. Sad panda face. They have to wait because everything is blocked because that meant there were 4 future sessions launched in 3 sessions, and when those sessions are busy that other users gotta wait. So there could be improvements in this, and yes, there are. There is a wrapper combining these two concepts of future and promise called future underscore promise is that you can now launch this asynchronous type processing, get a queue going, and then as these, sessions finish, it can then launch new ones that come as soon as one of those workers become available instead of all the workers being available.
That's a nuance there, and he's got a nice illustration to show this in action along with the revised code to to launch this. So, again, the setup looks pretty similar. You're just swapping in, future underscore promise instead of future. This is working better. But there but, again, that 4th user will still have to wait a little bit until at least one of those three tasks finishes from the previous three users. But there is a new paradigm, something we've covered on our wiki highlights a while back this year, the extended task function that now comes native since shiny version 1.8.1, which is giving you an r six class to provide native asynchronous support without a lot of the what I'll affectionately call somewhat odd setup that the future and promises, package and a shiny or a combination and a shiny app required you to do. You will see the example when you read the post, but it was never quite intuitive to me.
Extended task is in the right direction. I would say to make things a bit easier because you're creating a new task with an r six object, putting in your future promise, where, again, some of that boilerplate still in there. But this is going to help the user experience quite a bit because you get some nice helpers with this as well, such as having a button in your Shiny app that can be automatically relabeled on the spot when the user clicks it to give them an indication that something is happening. So you get a little processing message on that button when they hit the button so this is again a great improvement to help unify things a bit more and extended tasks has some really nice documentation that we'll link in the show notes as well.
So when I saw this post, of course, I love seeing, you know, very, you know, detailed, you know, overviews of asynchronous programming because it is such an important concept in Shiny development. But I did have another thing in mind that could be put in this same paradigm, but I'm gonna flip the script a little bit. Colin is coming at this from multiple users, accessing an application at the same time. That's not always the case. I have situations, and I know many others in it in the in the industry do, where it's not so much many users hitting the app at once, but one user, their experience of running the app, they may want to launch something that's gonna take a while, but yet do other things in the app without the whole session being blocked. So what's I call within session, asynchronous programming is desired.
And for this, yes, extended tasks can be used in this as well, but I do dare say that the combination of Will Landau's crew package with Charlie Gao's MirrorEye package can be a really attractive paradigm for you as a shiny developer. If you know there are gonna be tasks launched in your shiny app that could be as simple or extremely complex, crew with MirrorEye is gonna give you an elegant way to launch these workers without really knowing ahead of time how many to launch per se. It's gonna kind of adapt to it. It's got some defaults that you can tweak, but the example that I'll link to in the show notes is from the vignette of KRU where they have a shiny app where you can hit a button and and simulate basically 1,000 coin flips.
The default version of this, the output of, like, the heads, tails, and the number of flips is very laggy, the update, because everything's kind of being done in one overall process. But with crew and MirrorEye, when you hit that button, it's like looking at a a speedometer, and it just continuously increases faster, and you could be able to type the the numbers. It is amazing to watch. So I would say if you're in this paradigm of within session trying to optimize the performance as best as possible, KRU and Mirai is a combination you definitely want to look at. And the good news is that Will and Charlie have also talked to Joe Cheng about this, and he's been playing with it too. So there may be more integrations between these two paradigms of shiny's extended task and Mirai and Krue in the near future.
Nonetheless, a terrific post by Colin on what can be an extremely difficult concept to master as a shiny developer for many many different reasons, but this is a great way to get started and I invite you to check out these terrific resources in the blog post as well as Will's and Charlie's crew and Mirai package respectively. Oh, there's that time of year wherever you're, you know, getting some much needed time off from the day job, spending time with family or friends or whatnot. You might get a little downtime once in a while, and you wanna, you know, maybe do something interesting and challenging for yourself.
There's definitely an appetite to look at different, you know, various puzzles, especially with coding, which we'll get to in a little bit. But there are some really interesting ways to challenge yourself yourself from very, you know, historical yet very interesting publications from centuries ago. And our next highlight here is giving you a little brain teaser to work on, and, yes, you can use R to help out with it. Data scientist Nina Zumo, who is a consultant for the WinVector consultancy firm, she has a new post on the Rworks blog, which, by the way, I wanna give kudos to R Works because I don't think we've talked about very specifically on this on the show.
This is kind of the spiritual successor to Joe Rickert's immensely successful and highly acclaimed our views blog posts that you would have from his days of revolutions computing in that posit as well. But this is kind of like the next generation of that, and Joe is one of the editors of this along with Isabel Velasquez, but they give you the opportunity to put posts on their blog if you if you wish to contribute. It looks like Nina took them up on this offer multiple times. Nonetheless, what Nina's talking about here is a a great brain cheeser with mathematics that you can, you know, you actually use r to help solve, and this is rooted into the 4 weights problem, which has a long history in it itself.
This was from a article author by Henry Dunanese, from The Strand Magazine back in December of 1908. That's over a 100 years ago, folks. But, yes, this has all been digitally archived, so we can learn from this too. And the basic premise of what it's called the 4 weights problem, think of having a scale that can be bound a weighing scale that has, you know, two sides left and right, and the object is to find 4 weights. They all can't be the same of 4, say, weighted objects that in the integer range of 1 to 40 can be put on these two levers of the weighted scale and still be balanced together.
That sounds it already sounds complicated to me. I mean, this would take me a few maybe a few hours, if not longer, to sit down and do. But you want to be able to find what are the best ways to get to this solution. So you one thing is just find the values that could work that could, you know, add up to the value of 40 without going over. But then how do you balance that together? So so the fundamental paradigm behind a teaser, a brain teaser like this, if you will, is that this is kind of based on a a different type of arithmetic, maybe, than what you may be doing in your day to day because, you know, that she she introduces that there are weights of 1, 3, 9, and 27 that could satisfy this, but you have to figure out then what this unknown quantity x to make sure that on one side of the scale that we can distribute these weights so that the scale actually balances. And, yes, that is somewhat contrived because you wouldn't have to weigh everything if you already know it ahead of time, but this is rooted into modular arithmetic for how you can solve this.
So she starts with kinda, you know, figuring out the best way to kind of change our thinking of this with this unknown quantity x, and how do we shift our lens of this to a base n type representation. This is where it'll get, you know, a little complicated to summarize in audio. But the idea is that you have this you want to represent a non negative integer with up to m digits and binary representation. And if you recall, binary digits can be represented by any number in a range from 0 to some arbitrary m of 2 to the power n minus 1. So there's some pseudo code here to look at the different ways we can transform this x into base 2 notation, and in the end get to a trinary representation of this that can satisfy these requirements. And, yes, there is some neat r code.
To do this, she's got a handy function called basen that will convert that x to it's a base end representation. And it's got a, you know, a simple while loop that based on certain conditions trying to figure out the the best way to represent that. And we can see then that when we want to convert 13 to binary, we can use this function feed in 13 as a verse parameter, and then the base of this notation is usually 2 by default and the number of digits for maximum. And in the end for this example of 13 we get the result of 1, 1, 9, and 1 and then that can be converted to what's called a ternary representation with another function that she has constructed called 2 decimal, where we're gonna feed in the the number of digits to put in that, and hence we get 9,298 as the result to convert that to 18.
So now that that gives us ground in for it to come into base functions. Going back to that 4 weights problem, we've got to now figure out with an equation that she writes here these for the for the x these different kind of coefficients, if you will, in front of these 4 weights and figuring out what are the the the coefficients that we can put in front of that. So, again, some nice r code to kind of loop through this with a a function that she wraps. She calls it way to take this x. And, again, we got, you know, bounded by 40 or or or less. Otherwise, it'll be out of the range. She's got some arithmetic to figure this out, as well as scaling the notation as well, which can be helpful to get that trinary representation in that. And then she gives some examples of trying these functions out, and you can see that we've got a few few different options here.
And in the end, the answer that she comes up with is on one side of the weight scale. You put 1 and 3, weights of 1 and 3, and then the other side is just gonna be the the leftover of x. So there's a well, a few different ways that they carry this out. She's got multiple examples here. But, in the end, I think this is something you're gonna have to sit down with it a bit and maybe, again, try to challenge yourself in some of these other puzzles that could be found in publications like this. But it goes to show you that with basic arithmetic, yeah, R can do just as well as any other programming language to convert, you know, the the pseudo code that you're kind of going through in your head as you come up with an algorithm to fit for purpose functions that can tease this out. And we'll have a link in the show notes as well to Nino's, first Nino's, first blog post about this. It gives more background on kind of the the other ways you could tackle this.
But, yeah, very good brain teaser. I didn't do it justice in audio, but you're invited to check it out if you wanna challenge yourself a bit when you get some downtime this, holiday season. And speaking of challenging yourself, I did allude to a bit earlier, this is also a very popular time of year to challenge yourself with some coding puzzles, too. And the one, you know, area that gets, gets spun up almost every holiday season for the past many years has been the advent of code, where for every day in this advent calendar, a new coding puzzle is released, and you're invited to use whatever language suits your fancy to solve these these challenging problems.
I admit it's on my bucket list to be able to do this someday. I just haven't had as much time yet to do it, but maybe someday I will, maybe in retirement or whatever. But that's not that's not soon for sure. Nonetheless, there is there is some great opportunities to leverage your favorite data science language, such as R, to handle this. And, of course, within R itself, there are many different ways to tackle this too with various packages and whatnot. And so our our last highlight today is authored by Kelly Baldwin, who is a assistant professor of statistics at the California Polytechnic Unif State University, and she's actually authoring this on the data dot table blog, the our data table community blog, to be specific, because she wanted to challenge herself.
She's, again, always been, you know, very happy about the Advent or Code series of puzzles, and she wanted to see, you know what? Just see what it takes to use data dot table and some of these puzzles. So that is really awesome. This blog post has actually been updated with with a couple solutions here based on the puzzles that started on December 1st. And so the first puzzle in this advent of code for this year is a bit of a warm up if you will where you have 2 lists. You might say 2 columns of numbers, and the goal is to compute the distance between the adjacent elements of these lists. But you want to do it from the least, you know, the smallest number first and one list and then the smallest number on the right list. And then kind of keep, you know, sorting accordingly to figure this out in the most elegant way that you can. And so with data. Table, Kelly shows that this can be a pretty straightforward operation where you're just simply using its, sort function to basically mutate in place, if you will, or change the variable in place after reading this text file, and then create a new variable called diff, which is again the absolute value between those two numbers, and then computing the sum of that at the end.
That was pretty straightforward. Basically, four lines of code with data dot table, you know, not too challenging there. And then part 2 is a a little bit different because you can do things a little because in part 2 in part 2, she is now looking at the kind of distance or similarity, if you will, between these these two these different types of distances that have been computed. And sure enough, that's yet another variable that you can assign in data dot table as the sum of the previous of the variable where the or the sum when the value in the first column is equal to the the the various values in the second column only when they're equal, multiply that by the other variable variable one value itself, but then grouping it by those unique values in the first list and then summing up that similarity calculation.
Again, two lines of code for that one. So, again, pretty pretty straightforward once you open that text file to solve that with data dot table. And then there is yet another puzzle that has multiple parts to this as well from December 2nd, where the background of this this puzzle is there are certain reports that basically can be represented, by one line in a in a matrix, and that the report is a list of numbers called levels, which are basically the columns. So in the example that I will link to in the in the show notes or, I should say, the problem in the show notes has 5 levels, 5 columns for each report list, but the goal is to, quote unquote, find when these variable reports are safe, which basically means that the levels are either all increasing or all decreasing, and any 2 adjacent levels differ by at least 1 and at most 3.
So those are 2 constraints to keep in mind. So this this could be a bit of a challenge. Right? So again, what can data dot table do here? So after importing this, this, set of data, Kelly defines a function called check report, where it's gonna determine if these this vector of numbers, in this case kind of like the list in that report vector, if they have negative or positive integers, and then be able to figure out then for whether it's too big or whether it's increasing or decreasing, an indicator for that, and then returning whether that was increasing or decreasing, and if it's not too big. So basically, the report will the check report function will return true if those conditions are met and false otherwise.
So she takes this report, the dataset, transposes it first, and then with data dot table basically computes then for the different, for the different deltas between these different columns in in the dataset applying wherever it works in a check report fashion. So it's kind of doing column wise, but applying that with the apply function on each of these and sure enough she was able to determine that those are those are working well. And then in part 2, she has a function of testing all this to make sure that this is working as well, and sure enough it it is as well. So she wasn't very happy about using the apply function for some of this, so she wanted to, you know, make see if there's another way to do it. And, yes, in data dot table, there is yet another way, another way to do it with data dot table itself where she's using the call sums function.
You know, I should say the call sums function wrapping those, those various calls or those indicators that you can use after you compute those deltas. And, again, very very similar. And she hasn't done anything with data dot table yet for December 3rd or 7th, but we'll check back on the blog as as we progress in Advent of Code to see where this shakes out. So, again, Advent of Code, fun little puzzles to entertain yourself, you know, with some fun challenging exercises. I heard I believe they get harder as as the as the time goes on. But again, there's no nothing's too easy here, so to speak. So great way to challenge your challenge your, skills here and use a little r and your favorite package like data dot table in the process.
And, of course, there's a lot more in this terrific issue of rweekly that Colin Faye has curated for us this week. So I'll take another minute here for my additional find that I wanna talk about here in this issue. And you know me, I always like to see a really great showcase of data science in action with analysis and visualization, and there is a wonderful dashboard that has been contributed to this issue called the Lime bike analysis. This has been authored by Nils Indetrin. And if I had to guess, yes, indeed, my spider senses are correct. This is actually actually a flex dashboard.
Retro, so to speak, with our markdown. But when you look at this, it looks absolutely terrific. And that what a Lime bike actually is, It's an electric bike and scooter sharing company, and they have, you know, they are in various cities around the world. And so they're look this dashboard is looking at from a single Lime bike account in London the different total distances by month and day of week that have been traveled, a nice little set of dashboard icons at the top, and an interactive map looking at the concentration of the trip start and end locations, and another tab for estimated costs.
And boy oh boy, these charts are powered by e charts for r and high charter and leaflet for the math visualization. Really elegant looking dashboard. Lots of great ideas that you could take everyone is stick with flex dashboard or even use this with quartile dashboards as well. Just love the interactivities. These plots just look amazing here, like, interactive clicking. I'm playing with it right now as I speak. Really fun to explore here. So credit to Niles for creating this terrific dashboard. And, again, there's no shiny involved here. This is rendered, if I had to guess, via either GitHub actions or just rendered on the spot when he committed this on on the repo. But lots of lots of great ideas to take from the source code here, so I invite you to check that out as well as the rest of the r weekly issue. We've got a lot of terrific content here for you to look at, but also it is getting near the end of the year, and we may have one issue left for the rest of the year, but we could always use your help for helping with the project, and that can be through your great blog post that you've either authored or you found online, maybe a great new package that has been very helpful to your workflows, or even other great content out there in the art community.
We'd love to hear about it, so you can send us a poll request at r wiki.org. There's a little Octocat icon at the top that'll take you to this week's current issue draft where you can get a template going when you submit a poll request. We have a nice set of pre filled, you know, notes that you can use to figure out which category your contribution goes in, but our curator, Faric, will be glad to merge that in for you. And, also, we love hearing from you on this podcast. We have a lot of a few different ways to do that. You can get in touch with us via the contact page and the episode show notes on your favorite podcast player here. It'll be directly linked there.
You can also send us a fun little boost along the way if you're listening on a modern podcast app like Podverse or Fountain, Cast O Matic. There's a whole bunch out there. You have all details in in the show notes as well. And you can find me on social media these days. I am mostly on Mastodon. I am with the handle at our podcast at podcast index.social. You can also find me on Blue Sky recently, or I'm at our podcast dot bsky dot social, I believe. Either way, it's in the show notes. I just haven't memorized it yet. You can also find me on LinkedIn. You can search my name, and you'll find me there. And just a little programming note, this may be the last episode of 2024 because my, my 2 little ones are not so little anymore, but their time off of school is starting later this week, and we want to spend some good quality time together. So I'll probably be not doing as much technology things and won't have as much focus time to do an episode. But, nonetheless, I definitely thank each and every one of you that have stuck with us throughout the year and have enjoyed our weekly and contributed to the project and contributed your kudos to this podcast.
Again, we love hearing from you. It always is a a great pick me up when we see these great comments, whether it's Blue Sky or her Mastodon or LinkedIn or whatever. We we enjoy the feedback. So with that, I'm gonna close-up shop here. I I fly solo today, and it probably showed, but I did the best I could nonetheless. But, again, hope you all have a wonderful rest of your year in 2024 with however you wanna celebrate holidays, time with family and friends. Enjoy it. Hopefully, you get some good rest and recharge with next year. But, nonetheless, that's gonna close-up shop here for episode 190 of our weekly highlights, and we'll be back with a new episode of our weekly highlights in 2025.