How the newly-released CRAN package deadline metadata inspired multiple learning journeys of the latest Shiny features with one of your podcast hosts joining the ride, a fresh coat of frontend paint to the amazing R-Universe, and the innovations R brings to forensic analyses of handwriting.
Episode Links
Episode Links
- This week's curator: Ryo Nakagawara - @Rby[email protected] (Mastodon) & @RbyRyo) (X/Twitter)
- Expose CRAN deadlines and DOIs
- A fresh new look for R-universe!
- {handwriter} 3.1.1: Handwriting Analysis in R
- Entire issue available at rweekly.org/2024-W25
- Eric's pull request to fix the shinylive version of the CRAN deadlines app https://github.com/matt-dray/cran-deadlines/pull/3
- The handwriter package documentation site https://csafe-isu.github.io/handwriter/index.html
- Scraping the R-Weekly Highlights podcast https://github.com/iamYannC/r-podcast
- Simulations for 2024 Euro Cup and Copa America https://lukebenz.com/post/intlsoccer2024/
- Forecasting the UEFA Euro 2024 with a machine learning ensemble https://www.zeileis.org/news/euro2024/
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Acrophobia - Earthworm Jim - about:blank - https://ocremix.org/remix/OCR01568
- Cross-Examination - Phoenix Wright: Ace Attorney - PrototypeRaptor - https://ocremix.org/remix/OCR01846
[00:00:03]
Eric Nantz:
Hello, friends. We're at back of episode 169 of the R Weekly Highlights podcast. Yeah. We're coming at you slightly a little later this week because, real life never slows down for either Mike or myself, but I'm delighted you're here. My name is Eric Nansen as always. It's great fun to talk about all the greatest, highlights that we have in this week's our weekly issue on this very podcast.
[00:00:25] Mike Thomas:
And I never do this alone. I've got who's been on an adventure of his own, Mike Thomas. Mike, how are you doing today? Hanging in there, Eric. Hanging in there. We're, yeah, like you said, a little late this week because real life happens, but we're still trying to get it out there for the people.
[00:00:40] Eric Nantz:
Yes. We're getting it out there. And, yeah, we we've been taking some mild inspiration from a certain team in Canada that's now dragged the uncertainty from Florida to game 6 of the Stanley Cup finals. So if they can come from a 3 hole deficit, we can knock out another podcast today, I dare say. I like that analogy. Yes. Yeah. It it works for me today anyway. So what also works is our weekly itself is a project where we have a rotating set of curators for every single week. And this week, it was curated by Ryo Nakagorua, another one of the OG's of the Arruki project itself.
And as always, he had tremendous help from our fellow Arruki team members and contributors like all of you around the world with your awesome poll requests and certain suggestions. So we lead off with an issue that if you ever have released a package on CRAN, you are probably familiar with at one point or another. Whether it's your package or one that you depend on, is sometimes on the CRANS system, there are packages that may fail certain checks. Happens to all of us, and then there may be such a failure that the CRAN team says, okay. We've detected this, failure.
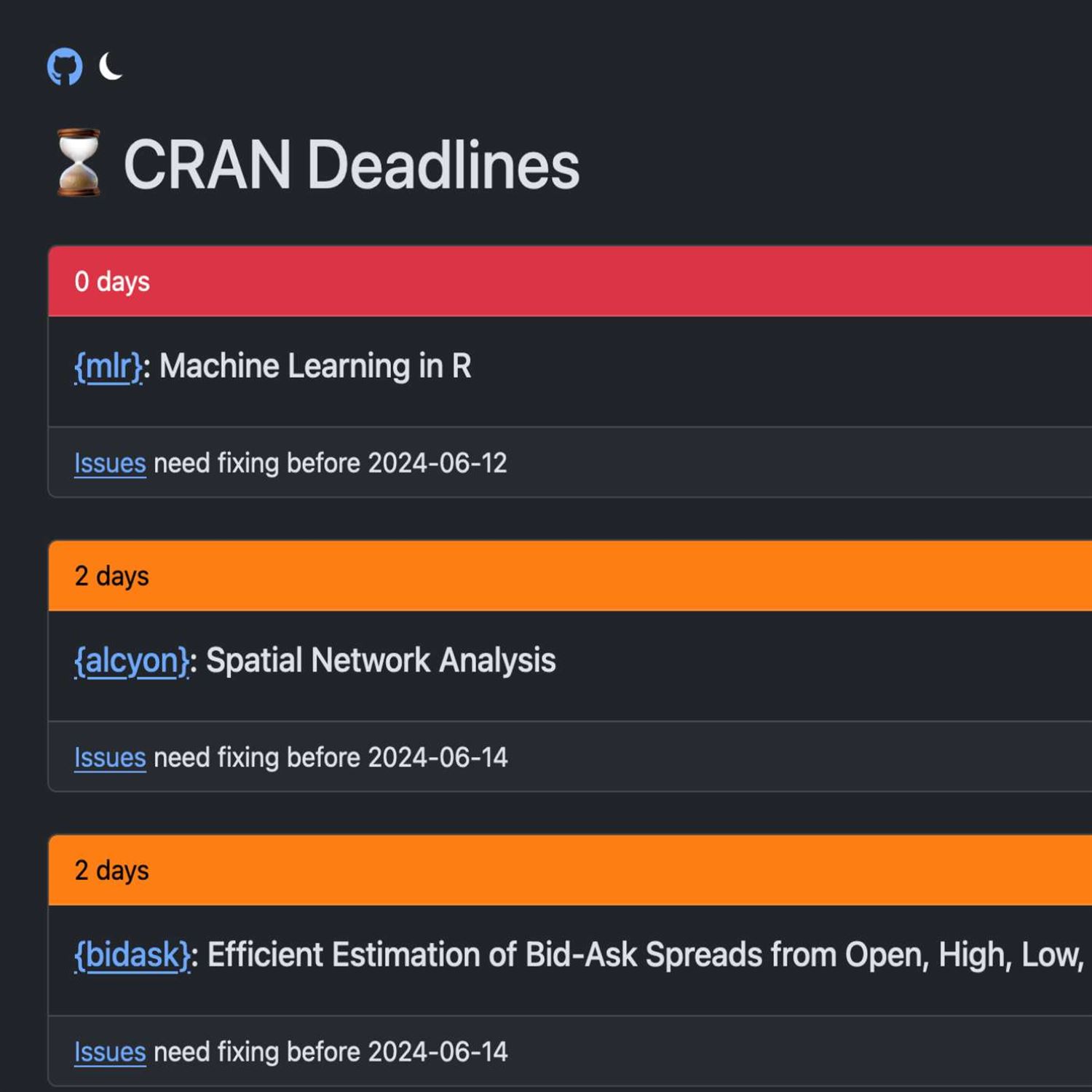
Now, you have until a certain amount of time to fix this. And that can be scary for a lot of people, myself included, especially if it's a package that is a very important part to my workflow or is a dependency of an important part of my workflow. But you may want to know just at a glance what is really happening in this landscape. And this first highlight covers that and another bonus feature to boot that's come into R recently where Matt Dre, another frequent contributor to Rwicky highlights in the past, has created 2 very neat interfaces.
And the first of which we're gonna talk about is this grand deadlines dashboard. This is very interesting, and the way this has been generated is that you may not know this, but in the base version of R, there is a handy function called crannpackagedb where this is literally grabbing an online source of data that the CRAN team maintains about package metadata. And you may be thinking to yourself, well, wait. Isn't this based on my current installation of r? No. No. No. This is a publicly available dataset that is updated regularly. Not quite sure the frequency of the updates, but there were 2 new fields that were introduced recently in this data frame. And in Matt's post, he shows first the typical metadata. You get, like, the package name, the version, and the maintainer, but there are 2 additional columns. The first of which is called deadline, and deadline is giving, as the name suggests, the date that the CRAN team has given that package author or that package itself to fix whatever issues have been flagged in their check system.
And you sure enough on the CRAN page, you could go to each package's website. You could then see the notes of these check failures on that package site itself on CRAN. But what Matt has done here is he took this opportunity to learn, become the latest and greatest in shiny development, which, of course, will please me in Mike's ears quite a bit. He has leveraged bslib and some pretty nifty ways of constructing the UI to create a very attractive looking, very fit for purpose deadline dashboard with individual cards as in the BSweb system that give at a high level the number of days remaining until that deadline, or, unfortunately, it could be the days that have passed since that deadline.
And you can see that very nicely. You have color coded boxes here, so you could quickly grok in the order. It goes from the ones that have they're running the longest in their update up until the ones that have more time. But you could scroll through this and see very quickly then which packages have been flagged, and it'll give you a direct link to the detailed check failures that you can navigate to directly from this page. Really nifty interface here, and he's not alone in this. Actually, Hadley Wickham himself has also built a similar report, albeit it's built with what it looks like an automated portal kind of GitHub action deployment, but it's got similar metadata associated with it. So you got 2 great sources for this information.
And I got wind of this not so much from Matt's post, but from a post he did on Mastodon as he was experimenting with this. And I pull up this interface, and I'm thinking to myself, oh, this is nifty. When I pulled up the interface, it was running on shiny apps. Io. It is a shiny app after all, but, immediately, in my head you wanna guess what was popping in my head, Mike, as I thought about what this could be good with?
[00:05:55] Mike Thomas:
Shiny Live WebR.
[00:05:57] Eric Nantz:
You got it. I'm on the the Shiny Live web train as you know from my recent efforts on the ER consortium pilot. So I wondered, I wonder what why maybe that wasn't done. Well, sure enough, it went to the GitHub repo, and I'd see that Matt did indeed attempt this, but it wasn't working. So this got me thinking here. You know what? I've been in the Shiny Live game for for a bit here with this other project. Maybe I could have my hand at trying to get to the bottom of this. Hence, my rabbit hole. So it's a little bonus, dev story time of Eric here. I pulled it up, cloned it on my local system, and I tried to look at the errors. And Matt did, have, like, a a general version of this error and an issue on his issue tracker on GitHub.
And I noticed that for whatever reason, the shawnee live app could not download that aforementioned CRAN database from that handy function inside of r. Why is that? This gets really interesting because, apparently, there are security controls in place in your web browser for accessing certain versions of URLs behind the scenes due to what's called the cores or the cross origin something or another. I'm not as in-depth with this, but I have seen posts from George Stagg in the past on, like, the WebR issue repository or the Shiny Live issue, tracker repository saying that you have to be careful about how you download files. And in fact, in web web r, you have to use the download that file function more often than not to actually download something, and you have to hope that the browser is able to access that URL because of these built in security protocols.
So I noticed that even I tried to download the file directly after I scanned the source of this, CRAN package DB function, I still couldn't get that RDS file. It just would not register. Then I went down another rabbit hole to figure out, I wonder if others have experienced this with RDS files. I wonder if it was just specific to that or, you know, just shooting throwing darts at a dartboard at that point. I stumbled upon another issue on the WebR repo where somebody put up a clever workaround to use this kind of openly available domain, like, referral service where you can transform a URL to meet these core security requirements.
It's kinda like when you have in, certain, you know, web lingo, you can put in a base URL, and then one of the query parameters is like the URL that you're actually interested in. There is such a thing as this that I stumbled upon in the issue tracker, and I'll put a link to my poll request in the show notes where you can get the the full details of this. But it's so I I plugged in this kind of more modified URL, and sure enough, I could get the RDS file from the CRAN site once I made this modified URL. So I thought, okay. I'm in business now. So in the in the source code of Matt's dashboard here, I now have a handy function to detect if the app is running in a web assembly process. And that's credit to Winston Chang from the WebR repo to basically detect if we're in what's called the web and scripting kind of functionality and web assembly. Again, I'm still learning all this, but it's kinda like a a simple true false if you're in it or not. So then if I'm in it, I know to use this custom function that I developed to modify the URL with download that file directly and then import that into r as a typical RDS file. Whereas if you're running this in a traditional r process, you can use that function that Matt shows in the post as is. No no big deal there.
And so so once I figured that out, I thought I'd solved everything then. But, no, there was one other kink here, Mike, and, you know, it never stops sometimes. WebR is currently still using our version 4 dot 3 dot 3. And Matt has, as he's actually covered, I believe, in one of his recent Mastodon posts, in version 4.4, now there is a handy function in BESAR that we've actually covered called sort underscore buy, where you can sort a day frame very quickly. It'll be very familiar to any of you that use the dply or arrange function. Well, guess what? In the web assembly version, that function doesn't exist because that's running 4 dot 3. So then I have another trick where if I'm running in web assembly mode, I use the more, you might call traditional order function in base r with the data frame referencing the variables directly.
Again, dusting off my, you might say, our development skills from pre 2015 on that, but, hey, Gradle was useful again. Right? So once you put both of those things in, then the web assembly version actually works.
[00:11:06] Mike Thomas:
So I felt I felt pretty vindicated, so I'm I'm geeked out. I'll send that PR to Matt. He merges it in. He recompiles the app, and now it's on Shiny Live. So woo hoo. Little dev fun with Eric there. That was that was a good time. Eric, that's awesome. I think, Matt, as he notes in his blog post, was super grateful for your help. I don't know when you sleep. I don't know how you do this stuff. I don't know how you figure it out and keep up with the shiny lab stuff, but, you are clearly leading in this space somewhat. If I remember correctly. You might even be giving a little bit of a talk at Pawsit Conferences here on this exact topic. So it sounds like you were the best the best man for for the job, so to speak, on this one. And, the the end result of this app that Matt has put together is is excellent. So I know he's grateful to you for that work that you put in and that pull request that I'm I'm taking a look at right now. It's it looks like it's full of rabbit holes that you went down. So Yeah. That that short narrative doesn't do it justice, but it was there. Every bullet point is like a a rabbit hole in terms of how I'm interpreting it. So that that's that's fantastic.
And the app is the app is great. It's really cool to see the the Shiny Live use case here. I know that that's something that Matt was trying to tackle here and was also trying to up skill a little bit on bslib. So the the app that came, out of it looks looks really nice. I think, you know, an alternate approach if you didn't care about, you know, going the the bslib route and the shiny live route would be you could potentially, have like a GitHub actions script, right, that would reach out to the the CRAN database that doesn't need, you know, Shiny Live or anything like that, you know, to be able to run and collect that data, maybe store it as an RDS file on a nightly basis that gets refreshed in the the repository
[00:12:54] Eric Nantz:
and then, you know, create a a GT table or a reactable table or or something like that. Right? And maybe that sounds sort of like what Hadley That put together. That's basically exactly what Hadley has done. Right? So it's it's great to see both of these approaches side by side, though. And and as Matt says, this is an awesome learning opportunity for him, and I, of all people, love going down rabbit holes for learning opportunities
[00:13:16] Mike Thomas:
in our ecosystem. Awesome learning opportunity for me as well just to read through this to be able to see the repository and see how it all came together. It's fantastic. And as you mentioned, one of those other columns that comes back from that, CRAN database, function in BaseR that we have is is DOI. And a DOI is a digital object identifier, and it sounds like CRAN has recently been tagging on these DOIs to, most, if not all, R packages that are on CRAN. I'll have to check if the package that I have on CRAN have a DOI right now.
[00:13:51] Eric Nantz:
Yeah. I haven't checked mine yet, and I'm not sure if they've gotten to everyone just yet. But, boy, I've seen a lot of excitement about this on on the social sphere, so to speak, with, being able to use this as a very important, you know, reference for somebody's, you know, development and research journey. It's it's terrific here. Absolutely terrific.
[00:14:11] Mike Thomas:
Yeah. And I imagine as, you know, I am not the expert on DOIs, citations, things like that. But I I think this is a way to be able to track, you know, how often this DOI gets used out there in the wild and and really that the purpose of that DOI is for citation purposes. Right? For someone else to someone else to be able to to not only, you know, cite your work in their paper but if they stick that DOI somewhere on the web, I believe that you'll be able to sort of track, where your work has been used. And it sounds like these DOIs can be either project specific or like blog specific, I think, or article specific, something like that, as well as perhaps, user specific, individual specific DOI. I'm not sure how you would, you know, essentially have a profile that that has multiple DOIs under it, right, for all the different articles that you have or different R packages in this case.
[00:15:07] Eric Nantz:
Yeah. I would love to hear from listeners because I know a lot of package authors will put what's called their ORCID identifier in the package manifest if they can link all this together somehow, but it's a fascinating time to as you said, I think this is a first step to getting some real tangible metrics on package usage, in in whatever domain people are interested in. And, what Matt's done here is really awesome because he has a handy little function, right, that called get cran DOI badge where, you know, basically, on your GitHub repos or in your readmes, you you often see these awesome little badges about, like, the version status or if it's on crayon or whatnot. Now you get a very attractive DOI badge free of charge, right, from this function. Really, really nice stuff here. Yes. The big shout out to Matt for making this very easy
[00:15:58] Mike Thomas:
for us, via his his Badger package to just stick that in our our readme and have, you know, another great badge to stick on top of our our packages. So that's that's awesome that he's made that so easy for us, and I'm excited to dive into the world of of DOIs, especially as it relates to the r packages that we have out there and see if I can add some badges this
[00:16:21] Eric Nantz:
week. Yeah. I've been, slowly getting on that badge craze, but I see some other prominent developers have, you know, quite a few of them. Like, how do you do that? Because it's all still kind of foreign to me. But, hey, this is this is, quite handy here. And, this is catching, you know, it's catching, you know, you know, a lot of momentum here because on on this particular feature alone, Dirk Edebutel, who, of course, is famed with RCPP development and are on Linux, he's created now a simple fetcher to his Littler script pipeline, which I use a lot of my Docker, files for installing our packages when they're using the rocker base images. Littler is kinda like a short COI like interface to r to say install a package from CRAN, install a package from GitHub. Apparently, he's also got now a way to fetch those DOI, information directly in Whitmer as well. And then another fun, you know, time is all together is that Mike FC, I'll be, also known as cool but useless on Mastodon and Twitter.
He's trying to make a list of all these kinda like CRAN metadata dashboard, you know, situations. And now Matt's positing, oh, wait. Maybe we need a a search that aggregates all these together. So it's like inception overload with all this metadata
[00:17:40] Mike Thomas:
scraping. But, hey, I'm here for it. This is this is terrific stuff here. Me too. Me too. Shout out, Matt. Great blog post, great walk through. I think this is a fantastic sort of I don't want to call it simplistic but it's a a pretty straightforward thing that he's trying to accomplish and and being able to to have this very straightforward use case for Shiny Live makes it it really consumable for me to understand what's going on.
[00:18:17] Eric Nantz:
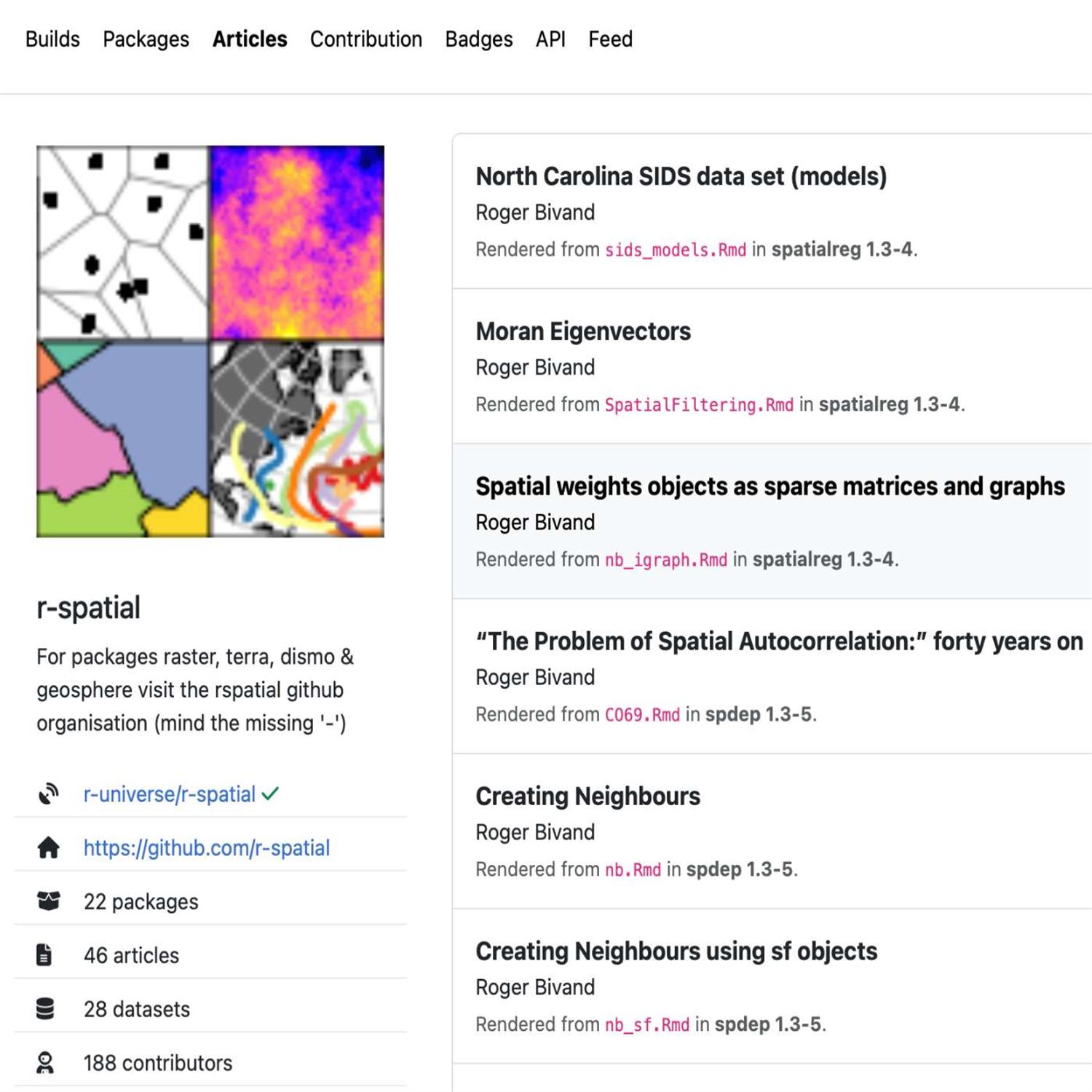
And we just mentioned, Mike, how yeah. What Matt's produces very aesthetically pleasing, and we're gonna go from simple to what is a very intricate system that just got a really big face lift to the end user perspective and a whole lot more. What we're speaking about here is the very influential and very powerful Our Universe project, which just got a very, you know, welcome revamp to its user interface and user facing functionality. So this next highlight comes from a blog post from the architect of our universe himself, your own oombs, who talks about, guess what? The web interface for our universe has a brand new front end, and this is not not a trivial front end by any means.
It's actually based in the express JavaScript framework with some server side rendering that, Jerome says has been greatly helpful to getting results appearing on the our universe page much more quickly, much more efficiently. I even did a little, GitHub investigation last night in this repo, and it's even using mongodb as well of all things. My goodness. Talk about supercharging your UI and back end processing. But, obviously, this is an audio podcast. We can't really show you over in this little chapter marker. I've got a, image of it, but we'll describe kinda what he is most excited about in these updates. And what I saw when I scanned this earlier is that now this the UI of it, it's gonna be very much optimized to multiple, you know, resolutions wherever you're looking at this on, like, a a phone screen or on a big monitor. He's done a lot of attention to detail to make the page very responsive, which we all kinda take for granted now when we build our shiny apps with bsweb or other frameworks like that. And as I mentioned, server side processing for a lot of these rendering results. So your client browser isn't having to do as much of the heavy lifting as it's pulling this information from the our universe services.
And he's also made a little bit of rearrangement to where you see the information on the owner going on the left sidebar now. And then, also, each package now gets a dedicated section to we just talked about earlier, citation information, which I'm sure the DOI, framer from CRAN may or may not play a role there. And also some handy contribution charts that are showing now proper time stamps and kinda capping out at 12 contributors in case you have a package that gets a boatload of contributors and not overwhelming the graph. But, he's also been able to optimize the table representation of package help pages.
He looks like the HTML of the help pages has been greatly enhanced as well, And he's also made some rendering of the vignettes inside a package look a little more native to a web browser and not just kind of, like, pasting in text from you can tell on different source. It all looks very cohesively constructed here. Really nice stuff. We invite you to check out the post for, obviously, links to the information. And he was very careful to keep backward compatibility here with the various URLs at different parts of our universe such as the packages, cards themselves, the articles.
You're gonna still get those same URLs. So don't fret if you're a package author on our universe. I'm wondering, oh, no. I passed this link to, like, my team or or in my, you know, Twitter or Mastodon, shout out to you. You'll still be able to use those same links. But, again, really, really polished interface here, and it just goes to show you that it seems like your own never stops on his our universe development adventures, but really really awesome UI enhancements here.
[00:22:17] Mike Thomas:
I couldn't agree more, Eric. You you know, when our universe originally came out that the UI to me that we now had around, you know, these individual package sites was like mind blowing that we had something like this now. Right? Instead of having to go to, I guess, GitHub and take a look at the the read me or or the package down site. Right? This our universe serves a lot more purposes than just that and thinking back to what the UI looks like before this facelift, this one no offense to the old UI but like because that blew me away, but this one has blown the other one away. So this is just much much cleaner. The navbar looks fantastic.
It looks like they have, you know, these different cards. Reminds me very much of like a bslib card type of situation that we have going on here that breaks out the section content with really nice headers as well as footers, which are are fantastic and and then it all the readmes, and the vignettes the way that they have rendered now I think everything is just a little bit cleaner which is fantastic. I'm looking at at one of my own for my package migrate and somehow, up here I have a link to my or Yaron has a link to my mastodon account next to my name. I'm not even sure I ever supplied that. I must have at one point in time because I imagine that he's not doing that by hand, but it's it's you have to see it for yourself and and take a look at the new Our Universe face lift, you know, search your favorite package, take a look at what the site looks like. I need to start installing packages from our universe. I need to to shift over there from some other package managers because I think there's a lot of advantages to this being sort of a one stop shop for, you you know, package installation in my local work, package installation for for web assembly purposes, right, as well. Yes.
So it's it's a pretty incredible resource that we have as as well as all the documentation, citation, you know, and all sorts different things that we have around all the different packages, that are now on the our universe. So incredible resource. He's another one where, like you, Eric, I I have no idea when your own sleeps but I'm very grateful for the work that he's done for the community.
[00:24:35] Eric Nantz:
Yeah. Like I said, I inspected the, GitHub repo for the new front end and my goodness. If I could under if I was able to understand even 10% of all the JavaScript magic he did there, I'd be a lucky lucky person. But, yeah, I was even pulling up the I now have 2 packages on our universe, albeit they're both related to the, podcasting 2.0 ecosystem. But, boy, those pages look fantastic. Like, man, my goodness. I I I feel good about passing this off to somebody and showing it off to to friends and stuff. This this is top notch. I love it. Just love it. Me too. Sometimes, I'll catch myself saying when I read maybe some terse documentation.
I'm not gonna say it's inspired by real life scenarios, but, you know, take that for what it's worth. And I'll kind of flippantly say to myself, who even wrote this stuff? Well, you know what? We're gonna answer that question literally in a much different context in our last highlight today because there is, of course, even in this advent of technology and most of us using a keyboard or a touch keyboard to write, you know, in the majority of our communication, there are still many instances where we are handwriting material. And there is a very important domain of research in forensics that are looking at more data driven approaches to helping identify potentially from a source of handwritten materials, maybe they're letters, maybe they're short notes, maybe they're whatever have you, I'm trying to use, you know, awesome algorithms to help link maybe certain writing sources to a particular author or a particular, you know, writer.
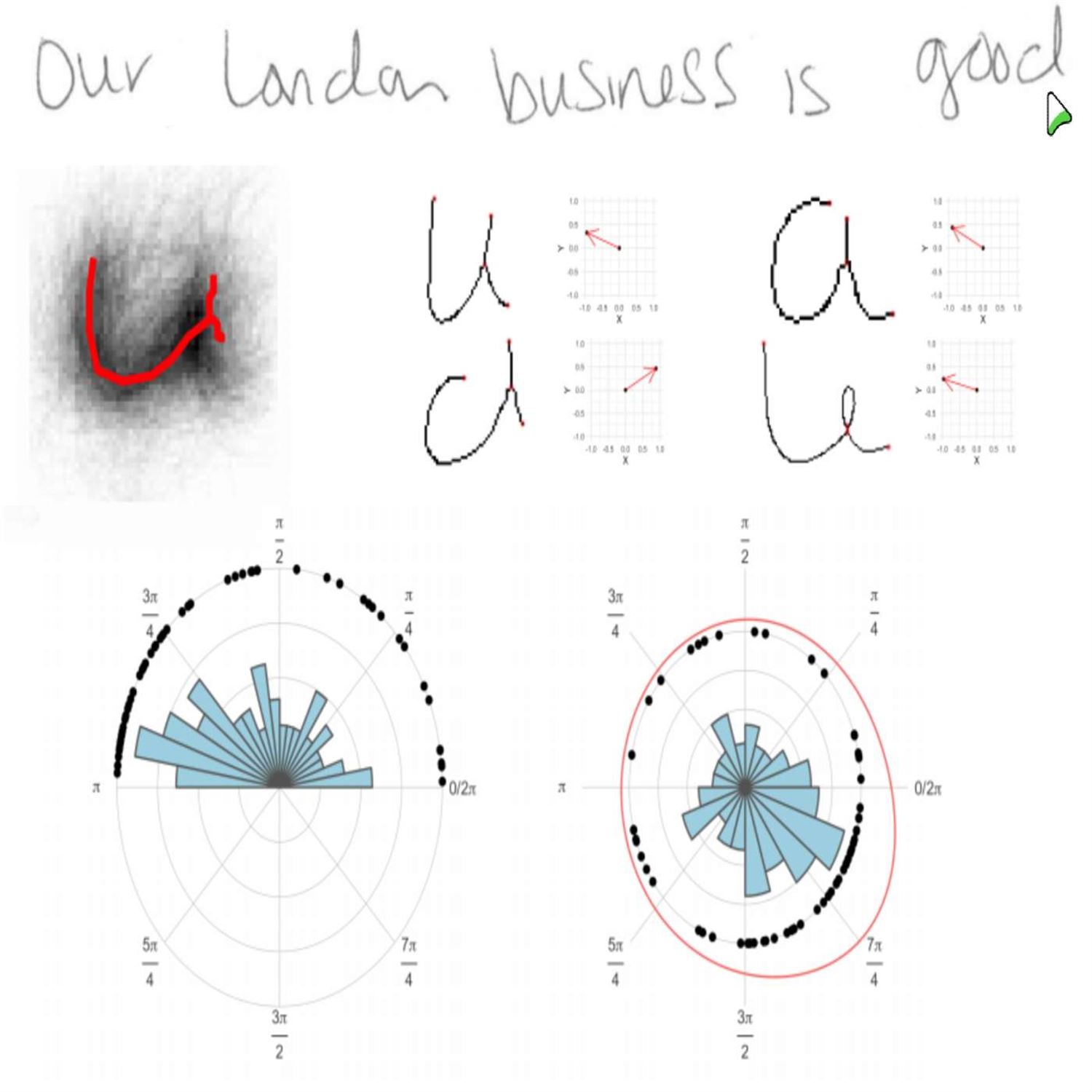
This last highlight is fascinating to me in a world that I definitely don't frequent in the world of forensics, but there is a major update to an r package called handwriter. This is maintained by Stephanie Reinders, and she is part of what I believe is the Iowa State University, the Center For Statistics and Application in Forensic Evidences or CSAE for short, mouthful, but they've been doing a lot of research in this space. And in particular, this r package that we're referencing here is a first step in a bigger pipeline that they are in the process of open sourcing, although they've got some manuscripts to show for it, where this package handwriter will take a PNG screen grab, if you will, of any handwritten content, and it's gonna apply some handy analysis methods to help identify certain features of this writing. And this is it's all about rabbit holes. I can only imagine how much research time is gonna spend into this, but I'll give a high level of the pipeline because there's no way we could do it all just this year, but it's got 4 major pieces of this pipeline.
First of which is that let's say you are scanning a handwriting reference that has colored ink or whatnot. It's going to turn that image into literally great black and white or gray scale first, and then it's gonna take, you know, the the stroke width of each of the writing. And there's, we have a link in the show notes to the package site itself where they have a good example using literally the word c safe written in cursive where they will take this reducing the width of each of those strokes to 1 pixel. That's fascinating too.
And then trying to detect, they call this the break phase next to compose it into small pieces, which in 2 of you might think are the individual letters in this writing. And they do this with a little graph theory to boot. They'll put nodes and edges that correspond to these different points in the in the detection of these units or breaks. And then they'll actually take measurements of the distances between these breaks, distances between the different letters to help figure out then, okay. Can we are there certain properties of this writing that then if they get additional sources, if they get similar writing style, you will see different versions of these or similar versions of these metrics as compared to, say, if you and I, Mike, wrote, like, the same, you know, same, like, short story on 1 page on a one piece of paper, it should detect our writing styles to be quite different. And I venture to say you probably have better handwriting than I do do because my handwriting's terrible. But, nonetheless, this package should be able to detect that if we gave 2 PNGs of our different sources that it would correctly identify us as being different riders.
So as I said, this is part of a larger, research pipeline that they also talk about in this, in this, package down site of how they integrate this with additional analytical tooling using some Bayesian methodology, some classical k means clustering to help really with a larger set of writing to be able to put this into distinct groups so that then you could link maybe potential sources to the same author. So as you can imagine, where this would really be important, especially in the world of forensics, is if there is an investigation and maybe one of the pieces of evidence is a writing that maybe a suspect had and then trying to link that maybe to that actual person as part of the evidence. I'm just speculating here because, again, not in my domain, but you could see how important this is in the role of forensics. So the fact that r itself is able to drive a significant part of this pipeline is absolutely fascinating to me. So when I pulled up this page the overnight, I I was I wasn't sure what to expect, but, boy, I can see that this is very important research.
And, again, I I started to think it analyzing my handwriting because I'm not sure maybe I'd break the system on my bad handwriting. But nonetheless, this is, a pretty fascinating domain and certainly a big credit to that team, at CICE for really, putting all this out there. And if you're interested in this space, yeah, I would definitely recommend checking out the handwriter package.
[00:31:19] Mike Thomas:
Well, Eric, I have seen your handwriting before and let's just say I am glad that we now have an r package for me to use to figure out what the heck you're saying.
[00:31:33] Eric Nantz:
Oh, that cuts deep, Mike. That cuts deep. I'm just kidding. I'm just kidding.
[00:31:39] Mike Thomas:
One thing that warms my heart more than anything else in the world is seeing universities use R to this extent and create R packages to just further, you know, the specific research that they're working on. The fact that this Center For Statistics and Applications in in Forensic Evidence, c safe at Iowa State University has clearly what I think, you know, chosen to leverage r as a as a tool to to push their research in their field forward, it it makes me so happy. And like you, Eric, this is a domain that I literally know nothing about. Probably my extent of learning anything about handwriting processing in R is the old MNIST dataset, where you're trying to classify, figure out which number someone wrote down. You have this 60,000 row dataset of all the that you you might use. So if you have done that before and taken a look at m MNIST, this is gonna blow your socks off, especially if you are in the space of doing any sort of image processing or handwriting analysis or or stuff like that. There's a great and maybe we can link to it in the show notes, The the documentation here is fantastic and it's all in a GitHub repository as well. It is a GitHub Pages site which is fantastic and it is, you know, well beyond any package downside, let's put it put it that way, that I have ever created.
So it's it's absolutely beautiful. I'm not even sure that they're necessarily using PackageDown. I know they've got some CSS, some custom CSS going on and things like that in a docs folder just sort of in the main branch, but it's it's an absolutely beautiful really informative site. It is a fantastic example of really, you know, including as as much documentation as there is functionality and and covering all your bases. There is a how to guide which I would recommend being maybe one of the first places that you can take a look at the functionality of this package, you know, in terms of word and then just a few quick functions to be able to process that image and and take a look at the results And the depth of the analysis that, you know, techniques that are encapsulated in this package is incredible. As you mentioned, Eric, it's, you know, plotting all sorts of different vectors and and directions as well as, you know, going all the way into to Bayesian analysis too, I think is included in this package. I saw some commits that that have stuff to do with Python support as well.
There's all sorts of documentation in here for whether you're working on a Windows, additional information for Mac users as well. So it's it's a fantastic resource. Again, it really warms my heart to see a university adopting R this hard and really putting a ton of best practices And
[00:35:03] Eric Nantz:
And we probably shouldn't be too surprised, this influential research is coming from such an esteemed institution as Iowa State because this is also the university that once had the esteemed Di Cook, presenting as a professor at the university and graduates such as the, the, the man that needs no introduction, Yway Siya, graduated from Iowa State. So, yeah, this is a a powerhouse in the world of our the art community and research. So credit to them for keeping innovation going.
[00:35:36] Mike Thomas:
I shoulda known.
[00:35:38] Eric Nantz:
The more you know, Mike. The more you know. And, speaking of the more you know, there's a lot more you can know by learning and reading the rest of this our weekly issue. There's another fantastic, roundup here that Rio has put together with awesome packages updated or brand new and awesome great blog posts and many others. We're gonna take a couple of minutes for our additional finds here, and we're gonna go meta on ourselves a little bit here, Mike, because what I teased about maybe a couple weeks ago, a listener got in touch with us, Yan Chohan, who has put together a GitHub repository of using R to scrape the metadata associated with this very podcast, rweekly highlights. And we'll put a link to that GitHub repo in the show notes, but it's a very clever use of scraping XML, which, of course, is the language behind the r Wiki highlights RSS feed just like any podcast.
And he's got a handy, little bit of repo set up there where you can see then a little screen grab of the plot of episode duration over time. It has a nice annotation apparently when I ramble quite a bit back in, sometime in in 2022 which, who would have thought that. Right? But it's a great little time course. And, again, using openly available data as part of our RSS spec. So it sounds like he's got a lot more planned in this. So, again, huge credit huge credit, to Yan for putting this together, And we'll definitely be watching this space because I always love it when people can use awesome, you know, uses of our to analyze things based on what we're actually producing. That's that's not that's top level stuff.
So, Mike, what do you think about that? I couldn't agree more. That's awesome.
[00:37:25] Mike Thomas:
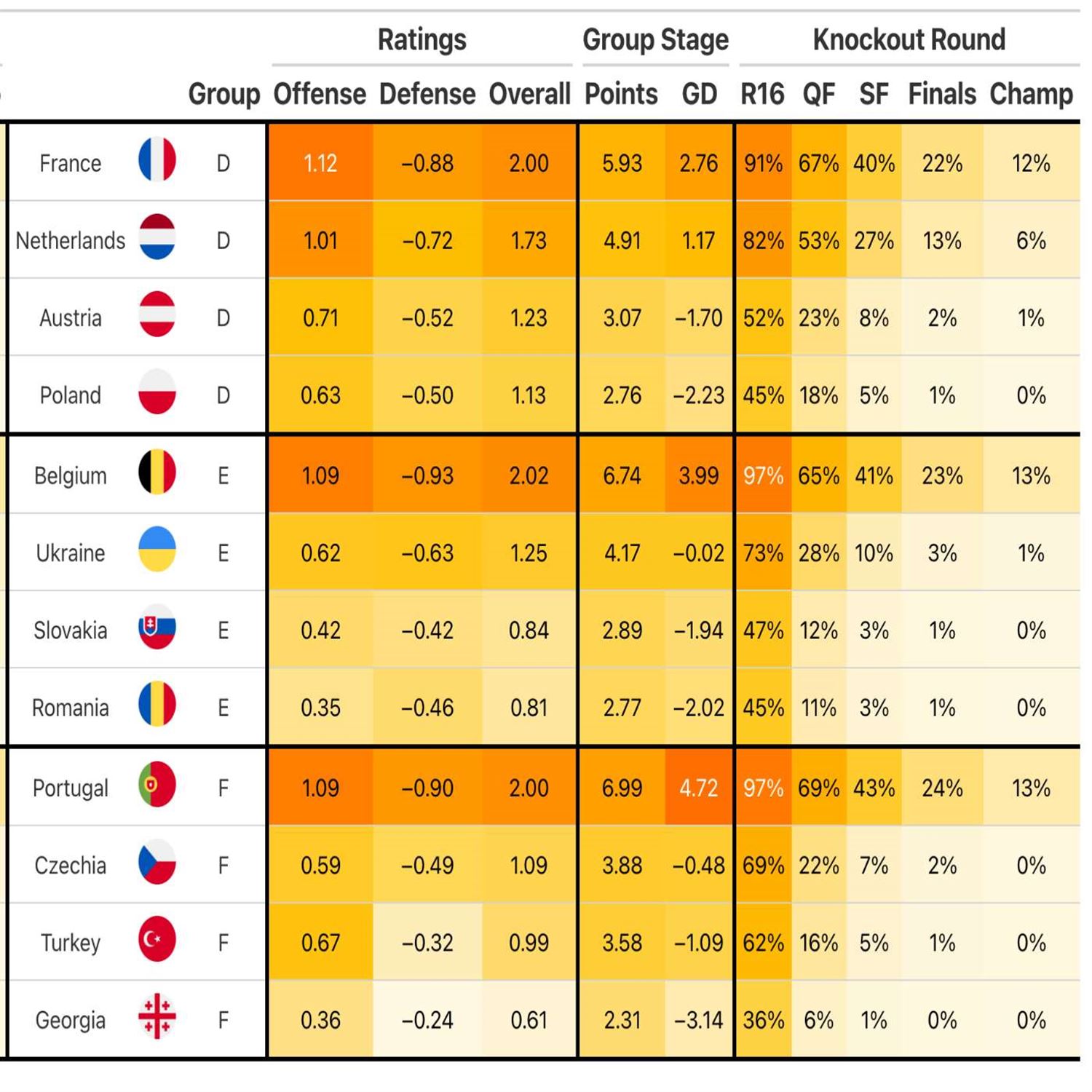
For his sake, I certainly hope that the XML is not too bad. I have been in situations where the XML structure is great and easy to parse, and I have been in situations where it's the complete opposite. So I I certainly hope, that it's it's nicely structured and really flattered, I guess, in a way. Appreciate the the work on that and excited to continue to watch, what he's able to to to come up with there. Absolutely. Any, football or soccer fans out there as we call it in the US, you may know that there's a couple big tournaments going on or at least at least one going on right now and and one starting up shortly. The the Euro Cup is going on right now and the Copa America starts very shortly. And Luke Benz has put together a really cool article, with a great what looks like GT table kind of heat map, of the expected, you know, probabilities of winning the tournament as well as some statistics like offense, defense, overall rating, things like that, for both the Euro 20 24 and the Copa America 20 24 tournaments, leveraging a a Bayesian bivariate Poisson model, I think, to model the likelihood of winning the tournament. So that is is really really cool work. I always enjoy sort of the sports analytics stuff. Sometimes that's the easiest way for me to learn new things because it's, you know, a use case that I have a lot of passion for. So, awesome write up. Appreciate Luke's work on that.
[00:38:53] Eric Nantz:
Yeah. I do spy. Like I said, a GT table front and center in in those, summaries, and it looks absolutely fantastic. I'm sure that would make the author of GT Ritchie own a very happy to see that. That is top level stuff. In fact, I don't know if, Luke, if you if you had a chance to submit that to the table contest, but that looks like a serious, you know, top contender entry my if I do say so myself, really. It's so much fun to use sports data to learn, you know, different techniques in the in the our ecosystem. So when I maybe get some more downtime again, I'm gonna get back to my world of hockey analytics and start turning loose because that was one of the very first types of data I analyzed way back in the early history of the art podcast as I was doing some fun stuff with ggplot2 and scraping some CSVs. There were some from a Google group of years gone by. Oh, I can't reminisce too much.
[00:39:49] Mike Thomas:
One of those days. But in any event, yeah, great great, great analysis of the, the world football, if I do say so myself. And if you can't get enough, you know, forecasting the the Euro 2024 tournament, there's another blog by Akeem Zales that's also on the highlights this week, and that is a machine learning ensemble approach. So if you wanna take another look at the same problem and a different approach to it, check that one out as well.
[00:40:13] Eric Nantz:
Oh, that is awesome. And, I shouldn't be too surprised that these made it because, Rio is a very, very big soccer fan, one of 2 huge soccer fans. I I should say 3 of yourself included on our our weekly team. So, yeah, representing Mike's representing that. You won't be able to see that on the screen, but I I see it. So awesome stuff. Awesome stuff. Well, yeah, we could go on and on, but we're gonna have to wrap up here as RealLife is calling us again. But we will leave you with, of course, how you can get in touch with us as well as the project itself. First of all, our weekly is driven by the community. We produce a Florida community, but we live off of your great poll request, your suggestions for additional resources to highlight on every issue. And that's all at our weekly dotorg, handy little poll request tab in the upper right corner, all marked down all the time. We dare say if you can't learn our markdown in 5 minutes, someone in the r community will give you $5.
I won't say I got that, but he he knows what he's talking about. We'll put it that way. And, also, if you wanna get in touch with us personally for this very show, you have a lot of ways to do that. We have a contact page in the episode show notes in your favorite podcasting player. And if you're on one of those modern podcast players like Podverse, Fountain, Cast O Matic, many others in this space, you can send us a fun little boost along the way and show us your appreciation there. And also, we are on the social media spheres. I am getting a little bit more on Mastodon these days, with at our podcast at podcast index.social.
You'll also see that I did a little, plug for a table submission I just have at the table contest. We'll see what happens. But in any event, it was a fun to put put my hat in the fray on that contest. Also, I'm on the Twitter x thing at at the r cast, and I'm on LinkedIn. Just search for my name. You will find me there. Mike, where can listeners get a hold of you?
[00:42:14] Mike Thomas:
You can find me on Mastodon as well at mike_thomas@fostodon dotorg, or you can find me on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k.
[00:42:27] Eric Nantz:
Very good. Awesome. Well, we we we powered through it. We're gonna hope for the best in our next adventures the rest of this week. But until then, it's been great fun to talk about all this great art content with all of you, and we will be back with another edition of our weekly highlights next week.
Hello, friends. We're at back of episode 169 of the R Weekly Highlights podcast. Yeah. We're coming at you slightly a little later this week because, real life never slows down for either Mike or myself, but I'm delighted you're here. My name is Eric Nansen as always. It's great fun to talk about all the greatest, highlights that we have in this week's our weekly issue on this very podcast.
[00:00:25] Mike Thomas:
And I never do this alone. I've got who's been on an adventure of his own, Mike Thomas. Mike, how are you doing today? Hanging in there, Eric. Hanging in there. We're, yeah, like you said, a little late this week because real life happens, but we're still trying to get it out there for the people.
[00:00:40] Eric Nantz:
Yes. We're getting it out there. And, yeah, we we've been taking some mild inspiration from a certain team in Canada that's now dragged the uncertainty from Florida to game 6 of the Stanley Cup finals. So if they can come from a 3 hole deficit, we can knock out another podcast today, I dare say. I like that analogy. Yes. Yeah. It it works for me today anyway. So what also works is our weekly itself is a project where we have a rotating set of curators for every single week. And this week, it was curated by Ryo Nakagorua, another one of the OG's of the Arruki project itself.
And as always, he had tremendous help from our fellow Arruki team members and contributors like all of you around the world with your awesome poll requests and certain suggestions. So we lead off with an issue that if you ever have released a package on CRAN, you are probably familiar with at one point or another. Whether it's your package or one that you depend on, is sometimes on the CRANS system, there are packages that may fail certain checks. Happens to all of us, and then there may be such a failure that the CRAN team says, okay. We've detected this, failure.
Now, you have until a certain amount of time to fix this. And that can be scary for a lot of people, myself included, especially if it's a package that is a very important part to my workflow or is a dependency of an important part of my workflow. But you may want to know just at a glance what is really happening in this landscape. And this first highlight covers that and another bonus feature to boot that's come into R recently where Matt Dre, another frequent contributor to Rwicky highlights in the past, has created 2 very neat interfaces.
And the first of which we're gonna talk about is this grand deadlines dashboard. This is very interesting, and the way this has been generated is that you may not know this, but in the base version of R, there is a handy function called crannpackagedb where this is literally grabbing an online source of data that the CRAN team maintains about package metadata. And you may be thinking to yourself, well, wait. Isn't this based on my current installation of r? No. No. No. This is a publicly available dataset that is updated regularly. Not quite sure the frequency of the updates, but there were 2 new fields that were introduced recently in this data frame. And in Matt's post, he shows first the typical metadata. You get, like, the package name, the version, and the maintainer, but there are 2 additional columns. The first of which is called deadline, and deadline is giving, as the name suggests, the date that the CRAN team has given that package author or that package itself to fix whatever issues have been flagged in their check system.
And you sure enough on the CRAN page, you could go to each package's website. You could then see the notes of these check failures on that package site itself on CRAN. But what Matt has done here is he took this opportunity to learn, become the latest and greatest in shiny development, which, of course, will please me in Mike's ears quite a bit. He has leveraged bslib and some pretty nifty ways of constructing the UI to create a very attractive looking, very fit for purpose deadline dashboard with individual cards as in the BSweb system that give at a high level the number of days remaining until that deadline, or, unfortunately, it could be the days that have passed since that deadline.
And you can see that very nicely. You have color coded boxes here, so you could quickly grok in the order. It goes from the ones that have they're running the longest in their update up until the ones that have more time. But you could scroll through this and see very quickly then which packages have been flagged, and it'll give you a direct link to the detailed check failures that you can navigate to directly from this page. Really nifty interface here, and he's not alone in this. Actually, Hadley Wickham himself has also built a similar report, albeit it's built with what it looks like an automated portal kind of GitHub action deployment, but it's got similar metadata associated with it. So you got 2 great sources for this information.
And I got wind of this not so much from Matt's post, but from a post he did on Mastodon as he was experimenting with this. And I pull up this interface, and I'm thinking to myself, oh, this is nifty. When I pulled up the interface, it was running on shiny apps. Io. It is a shiny app after all, but, immediately, in my head you wanna guess what was popping in my head, Mike, as I thought about what this could be good with?
[00:05:55] Mike Thomas:
Shiny Live WebR.
[00:05:57] Eric Nantz:
You got it. I'm on the the Shiny Live web train as you know from my recent efforts on the ER consortium pilot. So I wondered, I wonder what why maybe that wasn't done. Well, sure enough, it went to the GitHub repo, and I'd see that Matt did indeed attempt this, but it wasn't working. So this got me thinking here. You know what? I've been in the Shiny Live game for for a bit here with this other project. Maybe I could have my hand at trying to get to the bottom of this. Hence, my rabbit hole. So it's a little bonus, dev story time of Eric here. I pulled it up, cloned it on my local system, and I tried to look at the errors. And Matt did, have, like, a a general version of this error and an issue on his issue tracker on GitHub.
And I noticed that for whatever reason, the shawnee live app could not download that aforementioned CRAN database from that handy function inside of r. Why is that? This gets really interesting because, apparently, there are security controls in place in your web browser for accessing certain versions of URLs behind the scenes due to what's called the cores or the cross origin something or another. I'm not as in-depth with this, but I have seen posts from George Stagg in the past on, like, the WebR issue repository or the Shiny Live issue, tracker repository saying that you have to be careful about how you download files. And in fact, in web web r, you have to use the download that file function more often than not to actually download something, and you have to hope that the browser is able to access that URL because of these built in security protocols.
So I noticed that even I tried to download the file directly after I scanned the source of this, CRAN package DB function, I still couldn't get that RDS file. It just would not register. Then I went down another rabbit hole to figure out, I wonder if others have experienced this with RDS files. I wonder if it was just specific to that or, you know, just shooting throwing darts at a dartboard at that point. I stumbled upon another issue on the WebR repo where somebody put up a clever workaround to use this kind of openly available domain, like, referral service where you can transform a URL to meet these core security requirements.
It's kinda like when you have in, certain, you know, web lingo, you can put in a base URL, and then one of the query parameters is like the URL that you're actually interested in. There is such a thing as this that I stumbled upon in the issue tracker, and I'll put a link to my poll request in the show notes where you can get the the full details of this. But it's so I I plugged in this kind of more modified URL, and sure enough, I could get the RDS file from the CRAN site once I made this modified URL. So I thought, okay. I'm in business now. So in the in the source code of Matt's dashboard here, I now have a handy function to detect if the app is running in a web assembly process. And that's credit to Winston Chang from the WebR repo to basically detect if we're in what's called the web and scripting kind of functionality and web assembly. Again, I'm still learning all this, but it's kinda like a a simple true false if you're in it or not. So then if I'm in it, I know to use this custom function that I developed to modify the URL with download that file directly and then import that into r as a typical RDS file. Whereas if you're running this in a traditional r process, you can use that function that Matt shows in the post as is. No no big deal there.
And so so once I figured that out, I thought I'd solved everything then. But, no, there was one other kink here, Mike, and, you know, it never stops sometimes. WebR is currently still using our version 4 dot 3 dot 3. And Matt has, as he's actually covered, I believe, in one of his recent Mastodon posts, in version 4.4, now there is a handy function in BESAR that we've actually covered called sort underscore buy, where you can sort a day frame very quickly. It'll be very familiar to any of you that use the dply or arrange function. Well, guess what? In the web assembly version, that function doesn't exist because that's running 4 dot 3. So then I have another trick where if I'm running in web assembly mode, I use the more, you might call traditional order function in base r with the data frame referencing the variables directly.
Again, dusting off my, you might say, our development skills from pre 2015 on that, but, hey, Gradle was useful again. Right? So once you put both of those things in, then the web assembly version actually works.
[00:11:06] Mike Thomas:
So I felt I felt pretty vindicated, so I'm I'm geeked out. I'll send that PR to Matt. He merges it in. He recompiles the app, and now it's on Shiny Live. So woo hoo. Little dev fun with Eric there. That was that was a good time. Eric, that's awesome. I think, Matt, as he notes in his blog post, was super grateful for your help. I don't know when you sleep. I don't know how you do this stuff. I don't know how you figure it out and keep up with the shiny lab stuff, but, you are clearly leading in this space somewhat. If I remember correctly. You might even be giving a little bit of a talk at Pawsit Conferences here on this exact topic. So it sounds like you were the best the best man for for the job, so to speak, on this one. And, the the end result of this app that Matt has put together is is excellent. So I know he's grateful to you for that work that you put in and that pull request that I'm I'm taking a look at right now. It's it looks like it's full of rabbit holes that you went down. So Yeah. That that short narrative doesn't do it justice, but it was there. Every bullet point is like a a rabbit hole in terms of how I'm interpreting it. So that that's that's fantastic.
And the app is the app is great. It's really cool to see the the Shiny Live use case here. I know that that's something that Matt was trying to tackle here and was also trying to up skill a little bit on bslib. So the the app that came, out of it looks looks really nice. I think, you know, an alternate approach if you didn't care about, you know, going the the bslib route and the shiny live route would be you could potentially, have like a GitHub actions script, right, that would reach out to the the CRAN database that doesn't need, you know, Shiny Live or anything like that, you know, to be able to run and collect that data, maybe store it as an RDS file on a nightly basis that gets refreshed in the the repository
[00:12:54] Eric Nantz:
and then, you know, create a a GT table or a reactable table or or something like that. Right? And maybe that sounds sort of like what Hadley That put together. That's basically exactly what Hadley has done. Right? So it's it's great to see both of these approaches side by side, though. And and as Matt says, this is an awesome learning opportunity for him, and I, of all people, love going down rabbit holes for learning opportunities
[00:13:16] Mike Thomas:
in our ecosystem. Awesome learning opportunity for me as well just to read through this to be able to see the repository and see how it all came together. It's fantastic. And as you mentioned, one of those other columns that comes back from that, CRAN database, function in BaseR that we have is is DOI. And a DOI is a digital object identifier, and it sounds like CRAN has recently been tagging on these DOIs to, most, if not all, R packages that are on CRAN. I'll have to check if the package that I have on CRAN have a DOI right now.
[00:13:51] Eric Nantz:
Yeah. I haven't checked mine yet, and I'm not sure if they've gotten to everyone just yet. But, boy, I've seen a lot of excitement about this on on the social sphere, so to speak, with, being able to use this as a very important, you know, reference for somebody's, you know, development and research journey. It's it's terrific here. Absolutely terrific.
[00:14:11] Mike Thomas:
Yeah. And I imagine as, you know, I am not the expert on DOIs, citations, things like that. But I I think this is a way to be able to track, you know, how often this DOI gets used out there in the wild and and really that the purpose of that DOI is for citation purposes. Right? For someone else to someone else to be able to to not only, you know, cite your work in their paper but if they stick that DOI somewhere on the web, I believe that you'll be able to sort of track, where your work has been used. And it sounds like these DOIs can be either project specific or like blog specific, I think, or article specific, something like that, as well as perhaps, user specific, individual specific DOI. I'm not sure how you would, you know, essentially have a profile that that has multiple DOIs under it, right, for all the different articles that you have or different R packages in this case.
[00:15:07] Eric Nantz:
Yeah. I would love to hear from listeners because I know a lot of package authors will put what's called their ORCID identifier in the package manifest if they can link all this together somehow, but it's a fascinating time to as you said, I think this is a first step to getting some real tangible metrics on package usage, in in whatever domain people are interested in. And, what Matt's done here is really awesome because he has a handy little function, right, that called get cran DOI badge where, you know, basically, on your GitHub repos or in your readmes, you you often see these awesome little badges about, like, the version status or if it's on crayon or whatnot. Now you get a very attractive DOI badge free of charge, right, from this function. Really, really nice stuff here. Yes. The big shout out to Matt for making this very easy
[00:15:58] Mike Thomas:
for us, via his his Badger package to just stick that in our our readme and have, you know, another great badge to stick on top of our our packages. So that's that's awesome that he's made that so easy for us, and I'm excited to dive into the world of of DOIs, especially as it relates to the r packages that we have out there and see if I can add some badges this
[00:16:21] Eric Nantz:
week. Yeah. I've been, slowly getting on that badge craze, but I see some other prominent developers have, you know, quite a few of them. Like, how do you do that? Because it's all still kind of foreign to me. But, hey, this is this is, quite handy here. And, this is catching, you know, it's catching, you know, you know, a lot of momentum here because on on this particular feature alone, Dirk Edebutel, who, of course, is famed with RCPP development and are on Linux, he's created now a simple fetcher to his Littler script pipeline, which I use a lot of my Docker, files for installing our packages when they're using the rocker base images. Littler is kinda like a short COI like interface to r to say install a package from CRAN, install a package from GitHub. Apparently, he's also got now a way to fetch those DOI, information directly in Whitmer as well. And then another fun, you know, time is all together is that Mike FC, I'll be, also known as cool but useless on Mastodon and Twitter.
He's trying to make a list of all these kinda like CRAN metadata dashboard, you know, situations. And now Matt's positing, oh, wait. Maybe we need a a search that aggregates all these together. So it's like inception overload with all this metadata
[00:17:40] Mike Thomas:
scraping. But, hey, I'm here for it. This is this is terrific stuff here. Me too. Me too. Shout out, Matt. Great blog post, great walk through. I think this is a fantastic sort of I don't want to call it simplistic but it's a a pretty straightforward thing that he's trying to accomplish and and being able to to have this very straightforward use case for Shiny Live makes it it really consumable for me to understand what's going on.
[00:18:17] Eric Nantz:
And we just mentioned, Mike, how yeah. What Matt's produces very aesthetically pleasing, and we're gonna go from simple to what is a very intricate system that just got a really big face lift to the end user perspective and a whole lot more. What we're speaking about here is the very influential and very powerful Our Universe project, which just got a very, you know, welcome revamp to its user interface and user facing functionality. So this next highlight comes from a blog post from the architect of our universe himself, your own oombs, who talks about, guess what? The web interface for our universe has a brand new front end, and this is not not a trivial front end by any means.
It's actually based in the express JavaScript framework with some server side rendering that, Jerome says has been greatly helpful to getting results appearing on the our universe page much more quickly, much more efficiently. I even did a little, GitHub investigation last night in this repo, and it's even using mongodb as well of all things. My goodness. Talk about supercharging your UI and back end processing. But, obviously, this is an audio podcast. We can't really show you over in this little chapter marker. I've got a, image of it, but we'll describe kinda what he is most excited about in these updates. And what I saw when I scanned this earlier is that now this the UI of it, it's gonna be very much optimized to multiple, you know, resolutions wherever you're looking at this on, like, a a phone screen or on a big monitor. He's done a lot of attention to detail to make the page very responsive, which we all kinda take for granted now when we build our shiny apps with bsweb or other frameworks like that. And as I mentioned, server side processing for a lot of these rendering results. So your client browser isn't having to do as much of the heavy lifting as it's pulling this information from the our universe services.
And he's also made a little bit of rearrangement to where you see the information on the owner going on the left sidebar now. And then, also, each package now gets a dedicated section to we just talked about earlier, citation information, which I'm sure the DOI, framer from CRAN may or may not play a role there. And also some handy contribution charts that are showing now proper time stamps and kinda capping out at 12 contributors in case you have a package that gets a boatload of contributors and not overwhelming the graph. But, he's also been able to optimize the table representation of package help pages.
He looks like the HTML of the help pages has been greatly enhanced as well, And he's also made some rendering of the vignettes inside a package look a little more native to a web browser and not just kind of, like, pasting in text from you can tell on different source. It all looks very cohesively constructed here. Really nice stuff. We invite you to check out the post for, obviously, links to the information. And he was very careful to keep backward compatibility here with the various URLs at different parts of our universe such as the packages, cards themselves, the articles.
You're gonna still get those same URLs. So don't fret if you're a package author on our universe. I'm wondering, oh, no. I passed this link to, like, my team or or in my, you know, Twitter or Mastodon, shout out to you. You'll still be able to use those same links. But, again, really, really polished interface here, and it just goes to show you that it seems like your own never stops on his our universe development adventures, but really really awesome UI enhancements here.
[00:22:17] Mike Thomas:
I couldn't agree more, Eric. You you know, when our universe originally came out that the UI to me that we now had around, you know, these individual package sites was like mind blowing that we had something like this now. Right? Instead of having to go to, I guess, GitHub and take a look at the the read me or or the package down site. Right? This our universe serves a lot more purposes than just that and thinking back to what the UI looks like before this facelift, this one no offense to the old UI but like because that blew me away, but this one has blown the other one away. So this is just much much cleaner. The navbar looks fantastic.
It looks like they have, you know, these different cards. Reminds me very much of like a bslib card type of situation that we have going on here that breaks out the section content with really nice headers as well as footers, which are are fantastic and and then it all the readmes, and the vignettes the way that they have rendered now I think everything is just a little bit cleaner which is fantastic. I'm looking at at one of my own for my package migrate and somehow, up here I have a link to my or Yaron has a link to my mastodon account next to my name. I'm not even sure I ever supplied that. I must have at one point in time because I imagine that he's not doing that by hand, but it's it's you have to see it for yourself and and take a look at the new Our Universe face lift, you know, search your favorite package, take a look at what the site looks like. I need to start installing packages from our universe. I need to to shift over there from some other package managers because I think there's a lot of advantages to this being sort of a one stop shop for, you you know, package installation in my local work, package installation for for web assembly purposes, right, as well. Yes.
So it's it's a pretty incredible resource that we have as as well as all the documentation, citation, you know, and all sorts different things that we have around all the different packages, that are now on the our universe. So incredible resource. He's another one where, like you, Eric, I I have no idea when your own sleeps but I'm very grateful for the work that he's done for the community.
[00:24:35] Eric Nantz:
Yeah. Like I said, I inspected the, GitHub repo for the new front end and my goodness. If I could under if I was able to understand even 10% of all the JavaScript magic he did there, I'd be a lucky lucky person. But, yeah, I was even pulling up the I now have 2 packages on our universe, albeit they're both related to the, podcasting 2.0 ecosystem. But, boy, those pages look fantastic. Like, man, my goodness. I I I feel good about passing this off to somebody and showing it off to to friends and stuff. This this is top notch. I love it. Just love it. Me too. Sometimes, I'll catch myself saying when I read maybe some terse documentation.
I'm not gonna say it's inspired by real life scenarios, but, you know, take that for what it's worth. And I'll kind of flippantly say to myself, who even wrote this stuff? Well, you know what? We're gonna answer that question literally in a much different context in our last highlight today because there is, of course, even in this advent of technology and most of us using a keyboard or a touch keyboard to write, you know, in the majority of our communication, there are still many instances where we are handwriting material. And there is a very important domain of research in forensics that are looking at more data driven approaches to helping identify potentially from a source of handwritten materials, maybe they're letters, maybe they're short notes, maybe they're whatever have you, I'm trying to use, you know, awesome algorithms to help link maybe certain writing sources to a particular author or a particular, you know, writer.
This last highlight is fascinating to me in a world that I definitely don't frequent in the world of forensics, but there is a major update to an r package called handwriter. This is maintained by Stephanie Reinders, and she is part of what I believe is the Iowa State University, the Center For Statistics and Application in Forensic Evidences or CSAE for short, mouthful, but they've been doing a lot of research in this space. And in particular, this r package that we're referencing here is a first step in a bigger pipeline that they are in the process of open sourcing, although they've got some manuscripts to show for it, where this package handwriter will take a PNG screen grab, if you will, of any handwritten content, and it's gonna apply some handy analysis methods to help identify certain features of this writing. And this is it's all about rabbit holes. I can only imagine how much research time is gonna spend into this, but I'll give a high level of the pipeline because there's no way we could do it all just this year, but it's got 4 major pieces of this pipeline.
First of which is that let's say you are scanning a handwriting reference that has colored ink or whatnot. It's going to turn that image into literally great black and white or gray scale first, and then it's gonna take, you know, the the stroke width of each of the writing. And there's, we have a link in the show notes to the package site itself where they have a good example using literally the word c safe written in cursive where they will take this reducing the width of each of those strokes to 1 pixel. That's fascinating too.
And then trying to detect, they call this the break phase next to compose it into small pieces, which in 2 of you might think are the individual letters in this writing. And they do this with a little graph theory to boot. They'll put nodes and edges that correspond to these different points in the in the detection of these units or breaks. And then they'll actually take measurements of the distances between these breaks, distances between the different letters to help figure out then, okay. Can we are there certain properties of this writing that then if they get additional sources, if they get similar writing style, you will see different versions of these or similar versions of these metrics as compared to, say, if you and I, Mike, wrote, like, the same, you know, same, like, short story on 1 page on a one piece of paper, it should detect our writing styles to be quite different. And I venture to say you probably have better handwriting than I do do because my handwriting's terrible. But, nonetheless, this package should be able to detect that if we gave 2 PNGs of our different sources that it would correctly identify us as being different riders.
So as I said, this is part of a larger, research pipeline that they also talk about in this, in this, package down site of how they integrate this with additional analytical tooling using some Bayesian methodology, some classical k means clustering to help really with a larger set of writing to be able to put this into distinct groups so that then you could link maybe potential sources to the same author. So as you can imagine, where this would really be important, especially in the world of forensics, is if there is an investigation and maybe one of the pieces of evidence is a writing that maybe a suspect had and then trying to link that maybe to that actual person as part of the evidence. I'm just speculating here because, again, not in my domain, but you could see how important this is in the role of forensics. So the fact that r itself is able to drive a significant part of this pipeline is absolutely fascinating to me. So when I pulled up this page the overnight, I I was I wasn't sure what to expect, but, boy, I can see that this is very important research.
And, again, I I started to think it analyzing my handwriting because I'm not sure maybe I'd break the system on my bad handwriting. But nonetheless, this is, a pretty fascinating domain and certainly a big credit to that team, at CICE for really, putting all this out there. And if you're interested in this space, yeah, I would definitely recommend checking out the handwriter package.
[00:31:19] Mike Thomas:
Well, Eric, I have seen your handwriting before and let's just say I am glad that we now have an r package for me to use to figure out what the heck you're saying.
[00:31:33] Eric Nantz:
Oh, that cuts deep, Mike. That cuts deep. I'm just kidding. I'm just kidding.
[00:31:39] Mike Thomas:
One thing that warms my heart more than anything else in the world is seeing universities use R to this extent and create R packages to just further, you know, the specific research that they're working on. The fact that this Center For Statistics and Applications in in Forensic Evidence, c safe at Iowa State University has clearly what I think, you know, chosen to leverage r as a as a tool to to push their research in their field forward, it it makes me so happy. And like you, Eric, this is a domain that I literally know nothing about. Probably my extent of learning anything about handwriting processing in R is the old MNIST dataset, where you're trying to classify, figure out which number someone wrote down. You have this 60,000 row dataset of all the that you you might use. So if you have done that before and taken a look at m MNIST, this is gonna blow your socks off, especially if you are in the space of doing any sort of image processing or handwriting analysis or or stuff like that. There's a great and maybe we can link to it in the show notes, The the documentation here is fantastic and it's all in a GitHub repository as well. It is a GitHub Pages site which is fantastic and it is, you know, well beyond any package downside, let's put it put it that way, that I have ever created.
So it's it's absolutely beautiful. I'm not even sure that they're necessarily using PackageDown. I know they've got some CSS, some custom CSS going on and things like that in a docs folder just sort of in the main branch, but it's it's an absolutely beautiful really informative site. It is a fantastic example of really, you know, including as as much documentation as there is functionality and and covering all your bases. There is a how to guide which I would recommend being maybe one of the first places that you can take a look at the functionality of this package, you know, in terms of word and then just a few quick functions to be able to process that image and and take a look at the results And the depth of the analysis that, you know, techniques that are encapsulated in this package is incredible. As you mentioned, Eric, it's, you know, plotting all sorts of different vectors and and directions as well as, you know, going all the way into to Bayesian analysis too, I think is included in this package. I saw some commits that that have stuff to do with Python support as well.
There's all sorts of documentation in here for whether you're working on a Windows, additional information for Mac users as well. So it's it's a fantastic resource. Again, it really warms my heart to see a university adopting R this hard and really putting a ton of best practices And
[00:35:03] Eric Nantz:
And we probably shouldn't be too surprised, this influential research is coming from such an esteemed institution as Iowa State because this is also the university that once had the esteemed Di Cook, presenting as a professor at the university and graduates such as the, the, the man that needs no introduction, Yway Siya, graduated from Iowa State. So, yeah, this is a a powerhouse in the world of our the art community and research. So credit to them for keeping innovation going.
[00:35:36] Mike Thomas:
I shoulda known.
[00:35:38] Eric Nantz:
The more you know, Mike. The more you know. And, speaking of the more you know, there's a lot more you can know by learning and reading the rest of this our weekly issue. There's another fantastic, roundup here that Rio has put together with awesome packages updated or brand new and awesome great blog posts and many others. We're gonna take a couple of minutes for our additional finds here, and we're gonna go meta on ourselves a little bit here, Mike, because what I teased about maybe a couple weeks ago, a listener got in touch with us, Yan Chohan, who has put together a GitHub repository of using R to scrape the metadata associated with this very podcast, rweekly highlights. And we'll put a link to that GitHub repo in the show notes, but it's a very clever use of scraping XML, which, of course, is the language behind the r Wiki highlights RSS feed just like any podcast.
And he's got a handy, little bit of repo set up there where you can see then a little screen grab of the plot of episode duration over time. It has a nice annotation apparently when I ramble quite a bit back in, sometime in in 2022 which, who would have thought that. Right? But it's a great little time course. And, again, using openly available data as part of our RSS spec. So it sounds like he's got a lot more planned in this. So, again, huge credit huge credit, to Yan for putting this together, And we'll definitely be watching this space because I always love it when people can use awesome, you know, uses of our to analyze things based on what we're actually producing. That's that's not that's top level stuff.
So, Mike, what do you think about that? I couldn't agree more. That's awesome.
[00:37:25] Mike Thomas:
For his sake, I certainly hope that the XML is not too bad. I have been in situations where the XML structure is great and easy to parse, and I have been in situations where it's the complete opposite. So I I certainly hope, that it's it's nicely structured and really flattered, I guess, in a way. Appreciate the the work on that and excited to continue to watch, what he's able to to to come up with there. Absolutely. Any, football or soccer fans out there as we call it in the US, you may know that there's a couple big tournaments going on or at least at least one going on right now and and one starting up shortly. The the Euro Cup is going on right now and the Copa America starts very shortly. And Luke Benz has put together a really cool article, with a great what looks like GT table kind of heat map, of the expected, you know, probabilities of winning the tournament as well as some statistics like offense, defense, overall rating, things like that, for both the Euro 20 24 and the Copa America 20 24 tournaments, leveraging a a Bayesian bivariate Poisson model, I think, to model the likelihood of winning the tournament. So that is is really really cool work. I always enjoy sort of the sports analytics stuff. Sometimes that's the easiest way for me to learn new things because it's, you know, a use case that I have a lot of passion for. So, awesome write up. Appreciate Luke's work on that.
[00:38:53] Eric Nantz:
Yeah. I do spy. Like I said, a GT table front and center in in those, summaries, and it looks absolutely fantastic. I'm sure that would make the author of GT Ritchie own a very happy to see that. That is top level stuff. In fact, I don't know if, Luke, if you if you had a chance to submit that to the table contest, but that looks like a serious, you know, top contender entry my if I do say so myself, really. It's so much fun to use sports data to learn, you know, different techniques in the in the our ecosystem. So when I maybe get some more downtime again, I'm gonna get back to my world of hockey analytics and start turning loose because that was one of the very first types of data I analyzed way back in the early history of the art podcast as I was doing some fun stuff with ggplot2 and scraping some CSVs. There were some from a Google group of years gone by. Oh, I can't reminisce too much.
[00:39:49] Mike Thomas:
One of those days. But in any event, yeah, great great, great analysis of the, the world football, if I do say so myself. And if you can't get enough, you know, forecasting the the Euro 2024 tournament, there's another blog by Akeem Zales that's also on the highlights this week, and that is a machine learning ensemble approach. So if you wanna take another look at the same problem and a different approach to it, check that one out as well.
[00:40:13] Eric Nantz:
Oh, that is awesome. And, I shouldn't be too surprised that these made it because, Rio is a very, very big soccer fan, one of 2 huge soccer fans. I I should say 3 of yourself included on our our weekly team. So, yeah, representing Mike's representing that. You won't be able to see that on the screen, but I I see it. So awesome stuff. Awesome stuff. Well, yeah, we could go on and on, but we're gonna have to wrap up here as RealLife is calling us again. But we will leave you with, of course, how you can get in touch with us as well as the project itself. First of all, our weekly is driven by the community. We produce a Florida community, but we live off of your great poll request, your suggestions for additional resources to highlight on every issue. And that's all at our weekly dotorg, handy little poll request tab in the upper right corner, all marked down all the time. We dare say if you can't learn our markdown in 5 minutes, someone in the r community will give you $5.
I won't say I got that, but he he knows what he's talking about. We'll put it that way. And, also, if you wanna get in touch with us personally for this very show, you have a lot of ways to do that. We have a contact page in the episode show notes in your favorite podcasting player. And if you're on one of those modern podcast players like Podverse, Fountain, Cast O Matic, many others in this space, you can send us a fun little boost along the way and show us your appreciation there. And also, we are on the social media spheres. I am getting a little bit more on Mastodon these days, with at our podcast at podcast index.social.
You'll also see that I did a little, plug for a table submission I just have at the table contest. We'll see what happens. But in any event, it was a fun to put put my hat in the fray on that contest. Also, I'm on the Twitter x thing at at the r cast, and I'm on LinkedIn. Just search for my name. You will find me there. Mike, where can listeners get a hold of you?
[00:42:14] Mike Thomas:
You can find me on Mastodon as well at mike_thomas@fostodon dotorg, or you can find me on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k.
[00:42:27] Eric Nantz:
Very good. Awesome. Well, we we we powered through it. We're gonna hope for the best in our next adventures the rest of this week. But until then, it's been great fun to talk about all this great art content with all of you, and we will be back with another edition of our weekly highlights next week.