
A thoughtful perspective on why it's not an either/or situation with popular data processing paradigms in R, another case of being kind to future you with your Git commit messages, and satisfying the need for speed in the evolving geospatial space.
Episode Links
Episode Links
- This week's curator: Tony Elhabr - @[email protected] (Mastodon) & @TonyElHabr (X/Twitter)
- Two Roads Diverged: Opinions on "dialects" in R
- Why you need small, informative Git commits
- Making a Ridiculously Fast™ API Client
- Entire issue available at rweekly.org/2024-W24
- Welcome to the {data.table} ecosystem project! https://rdatatable-community.github.io/The-Raft/posts/2023-10-15-introtogrant-toby_hocking/
- Pinball machines per capita https://www.sumsar.net/blog/pinball-machines-per-capita/
- New York R Conference Retrospective Panel https://www.youtube.com/watch?v=L8Ec4ZktjJQ
- igraph 2.0 https://igraph.org/2024/05/21/rigraph-2.0.0.html
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- DevilSLAB - Final Fantasy VI - MkVaff - https://ocremix.org/remix/OCR00250
- Ice Cap Zone (Pulse Mix) - Sonic the Hedgehog 3 - MkVaff - https://ocremix.org/remix/OCR04400
[00:00:03]
Eric Nantz:
Hello, friends. We are back with episode 168 of the R Weekly Highlights podcast. We're so glad you're here listening from wherever you are around the world. And this is the show if you are new to this podcast. This is the show where we talk about the terrific resources that have been highlighted in this week's our weekly issue, all available at rweekly.org. My name is Eric Nantz. As always, I'm delighted that you've joined us wherever you are. We have a lot of fun things to talk about, but this is a team effort after all. And I got my partner in our related crime here, so to speak. Mike Thomas is here. Join me at the hip. How are you doing today, Mike?
[00:00:40] Mike Thomas:
Doing pretty well, Eric. Not to violate any HIPAA laws and knock on wood. I am currently trying to dodge pink eye in our household so far. So good, but, I've I've heard that it's it's not fun. This is our first go around with it. So please pray for me. But We, we we have you in our thoughts for sure as somebody who's had a whole smorgasbord of
[00:01:03] Eric Nantz:
illnesses, viruses, things, and that and the kiddos, daycare days. Yeah. You,
[00:01:10] Mike Thomas:
keep strong, my friend. Thank you very much. But, Eric, how was your weekend?
[00:01:15] Eric Nantz:
Yeah. You know what? It's been a while since we did this. We're gonna dust off a segment I used to do in my in my live streams. Who's ready for story time with our
[00:01:25] Mike Thomas:
podcast? Beybey.
[00:01:30] Eric Nantz:
So it's story time with Eric now. So let's, buckle up for a few minutes here. So Friday night, I get a little opportunity to do a little, you know, open source development work on some of this podcasting database stuff. I've been pitching in with a podcasting 2 point o project. And recently, Dave Jones, who helps spearheads a lot of that effort, gave me access to some more lower level JSON files and object storage to help analyze some of the the data that's going into their database as kind of a more real time access of it. And these are these are actually massive JSON files. In fact, one of them is over 200 gigs worth. So I figured, okay. You know what? To help, you know, minimize the bandwidth cost just for once, I'm gonna download a snapshot of those locally on my, you know, somewhat beefy network storage down in the basement where I have, like, a group of 4 hard drives networked together, and that's where I do all my backup. So I figured, you know what? I'm just gonna throw it on there. That way, I can, you know, work with them in a prototyping way like any good citizen would do with bandwidth and everything like that.
So that was like, earlier in the week, and then Friday night rolls around. I'm gonna do a little hacking on it again, just kinda get to know those files a bit. Go to the path. My, laptop mounts. This is like a Samba share. But I I go to and it's run Linux, but Samba is the protocol. So in any event, I go to grab one of these files or always read it into R. It's kind of like a prototyping. And then I get a path file not found. And I'm thinking, what's this about? I know I downloaded earlier in the week, and it's alongside a bunch of my other kinda our open source, like big file stuff. And I go into the SSH session to my network storage that's running Linux. And I navigate to that area, directory not found.
Oh, no. Oh, boy. So I do a little poking around, and I realize that's not the only thing that I found. I am now not able to see some very, and I mean very important family media files, which if you guess are pictures and videos that I've recorded over the years. No. No. No. No. No. No. No. No. No. No. No. No. Now now I when I set this up many years ago, I did put in a couple backup strategies, one of which was to send my pictures over to Google Drive, albeit in an encrypted way so that I didn't feel like I was feeding their machine learning algorithms for image recognition and whatnot.
And so I quickly dust off my notes on how to interact with that. I was using a service called Duplicate to get that. And luckily enough, I did get the majority of my pictures back, albeit they stopped working after 2023, which was odd because I didn't get an alert on that. So that's one downside. But what was not on that cloud backup were the videos. So back to this internal setup, I have what's called a pooled file system of all these drives put together. And then there was an weekly job I would run that was kinda like RAID. If you ever heard of, like, how network drives are backed up in, like, a mirrored way, RAID is one way to do it. This is a different take called SnapRAID where it would, every week, funnel everything into what's called a parity drive.
And that way, if the worst happened, I could restore from that parity drive and get everything back. So I figured, oh, yes. I I did run that job. Right? Now I go to where that file would be stored. It's like this big compressed file. But then my heart sank because the last run of that, apparently, was in 2020, and I didn't know that. I still ran the restore anyway just to see what happens. And sure enough, I've got videos and pictures and other important files up to that point. So I am missing now 3 almost 4 years' worth of important content. So, of course, now I investigate, can I mount this drive somewhere else?
Can I just take it out of this network storage and put it into, like, an enclosure, connect it to my laptop, see if I can somehow salvage the files from there? That's when I realized there's the problem. The hard drive is making this sequential kind of buzzing kind of sound and cannot be recognized by any OS. That screams hardware failure. So I have now sent this to a drive recovery vendor. I'm waiting to hear back for the evaluation if they can get everything back. But if they are able to get it back, I hate to say it's not gonna be cheap to get it back. But this is a very harsh lesson, folks. If you have a backup strategy, make sure to check that it's actually working.
If you learn nothing else from this 5 minute diatribe, look at your backup strategy. Make as many notes as you can because future self will need it when you absolutely positively least expect it like little old me here.
[00:06:55] Mike Thomas:
Eric, I'm so sorry. For our dear listeners out there, I asked Eric how his weekend was, and he would not tell me because he wanted to get my live reaction during the recording. And my live reaction is is despair, but I am almost, also not entirely surprised because I feel like story time with Eric probably sways a little, towards the the bad as opposed to the good if we're taking a look at the distribution of sort of sentiment around story time with their stories. I am sorry to hear that. I hope that that hardware vendor can can help you out some way somehow and it's not super expensive but, yes, that is, I think something we all struggle with is is backing up and and storage of especially, like, family media and stuff like that. I don't have a good strategy for it. Yeah. Oh, that that hurts my heart. That hurts my heart because I know how much work you've invested into building out, you know, your your hardware and software infrastructure in in the best ways possible and using the the best practices. So,
[00:08:03] Eric Nantz:
I'm so sorry to hear that. Oh, I I appreciate that. But life is so ironic. Right? Of all the drives to fail, the one that has a majority of these family files, files, that had to be the one. I've got other nonsense on there that I could live without. It's just out of convenience, but it had to be that one. So on top of, yeah, this vendor crossing my fingers, I will not say who they are because I'm not sure if it's gonna work or not. So I'm not giving any free advertising here. I hope this vendor actually pulls it off. But the other lesson is I was kinda living on borrowed time with some of the infrastructure around this. So I am building as we speak. The parts are coming in the next couple weeks. A brand new server that's gonna have a much better strategy around it. So there you go. That'll be some rabbit holes.
I does not surprise me at all. Best of luck with that. Yes. Thank you, sir. And, you know, one way or another, I'll I'll, share my learnings. They're they're this machine will double purpose. It will not just be a storage piece. This may be a piece where I can do some local Weaver machine learning stuff, AI stuff, or whatnot because I'm gonna I'm gonna spec it out pretty well for those workflows and media production. So it'll be a fun journey nonetheless. Just not one I was quite ready to do until Sure. This, certain event. Well, once you, install the Microsoft operating system and and turn the the Microsoft recall switch on, you'll never have to, you'll never have to worry about backing up anything ever again because it'll just watch you all the time. You know what? Yeah. What better peace of mind than to send that over to whatever they're training on? Oh, my goodness. For those of you who aren't aware of what we're talking about, that, Microsoft kinda got in a bit of a kerfuffle when they announced this feature, if you wanna call it that, where they would have a background process on your win Windows installation literally every, what, I don't know, 30 seconds.
[00:10:02] Mike Thomas:
Oh, no. I think it's less than that. I think it's, like, every second or every other second. It's gonna take a picture of what's on your your laptop screen.
[00:10:11] Eric Nantz:
I wow. I mean, just wow. It is is hopefully, some of you may think, yeah, that might have some disasters associated with it and many reasons. So they are rolling it back a little bit in terms of how they're rolling it out. But, nonetheless, the the cat's out of the bag, as they say, of what they've been planning for for this. So I think, more to come on this side of it. But, yeah, of all the things I did not expect to see, that announcement was one of them.
[00:10:40] Mike Thomas:
Likewise. Likewise. It just makes me wanna install Linux instead.
[00:10:44] Eric Nantz:
No. You're not alone. There's a lot of people making the switch after that kind of news, and Apple hasn't quite done themselves any favors either with some of their decisions. But Onto the r stuff. Yeah. Yeah. We've, digressed enough. But, in any event, we don't have hardware failures to talk about in these highlights. Thank goodness. And they have been curated this week by Tony Elharbor, another one of our awesome, curators on the rweekly team. He's been around for quite a couple of years now. And as always, he had tremendous help from our fellow rweekly team members and contributors like all of you around the world with your awesome poll requests and suggestions.
And we lead off the show with really a testament and a glimpse into the vast variety that's available to us with the nature of open source and especially some of the fundamental issues that can occur, not just from a development perspective, but also from a social and other type perspective as well. And this blog post and our first highlight comes from Kelly Baldwin, who is a assistant professor of statistics at Cal PIE, That is California Polytechnic State University for those that are outside of the US and may not know where that is. But in any event, she leads off with framing this discussion on 2 paths, if you might say, in the R community with respect to a lot of the ways that we handle data manipulation, data processing, and what has been perceived to be these separate roads traveled, so to speak. So she frames this post in light of Robert Frost, the road west traveled story.
And she also is upfront that this definitely has some opinions. Hey, Mike and our full opinions on this show too. But I, as we go through this, I definitely see exactly where she's coming from, and I think it's definitely an important discussion to have. What we're talking about here are 2 major frameworks that have kind of, over time, become pretty mainstream in terms of the art community's efforts for data manipulation. 1 is the tidy verse, which is well known by this point. Of course, the development of the tidy verse has been led by Hadley Wickham and his team of engineers at Posit.
And then we have data dot table. Data dot table was around well before the tidy verse. Data dot table, for those that aren't aware, had its first major release in 2008. Yeah. That's, got a dozen in the history books on this, And it was originally released by the core developer, Matt Dowell. And there's a link in the county's post for a nice video of what inspired they are dot table in the first place. And it you know, from near the beginning, they do that table has been so influential for many in the industry and academia, all walks of the life, so to speak, in the r community for respect to its very great performance and importing large data files.
It's got its own, you might call, DSL or domain specific language for how you conduct queries and whatnot and how you do, like, group summaries or filtering or creating new variables. It's got a syntax that is unique to it. And once you learn the ins and outs of it, it can be extremely powerful. And then fast forward about 6 years later, dplyr, the one of the cornerstones of what became the tidy verse, was released in 2014, again, authored by Hadley Wickham. And this, a lot of people point to this as the start of the tidy verse because of this new, at least new to many people at the time, way of performing these, you know, fit for purpose functions that use the data frame as, like, the main input such that you could combine this with the Magritter pipe and do all these nice kind of flowing analyses of data manipulation, you know, new variables, summarizations, group processing, and whatnot.
So with this, you now have, you know, at at this is Kelly Podsits here, about 3 major choices for your data processing. You could stick with base r. Of course, base r, it's got, you know, plenty of ways to do these type of summaries, data dot table, and dplyr. And they're all going to look quite different from each other. There has been a bit of a misconception over the years that data dot table is almost directly linked to base are. That's not quite the perception over the years that it was so perception over the years that it was so tightly coupled with base are that it was somehow going hand in hand with that. No. No. No. That's that's definitely not the case. It's got its own, you know, framework. It's got its own syntax. It's got its own paradigms.
And again, in my opinion, choice is great in this pay in this space. Now, sometimes the kinds of choices, well, which one do I go with? Well, we're not going to always use a cliche, it depends, but a lot of it does actually depend on what you want out of your data processing pipeline. But this shouldn't be a situation where you feel like you have to pick 1 and stick with it forever. Just like any project, you should have the ability to choose the right framework for your requirements or for your job, so to speak, and what's important to you.
But it's one she also talks in this post is that, yeah, sometimes people feel like they have to be loyal to a certain package through and through no matter what. No. We all greatly respect developers, but in the end, the choice is ours for what we choose in our data processing needs in this case. And you shouldn't feel bad about going from, like, a little bit of base r to, like, data dot table or maybe the tidy verse and kinda as you wish to be able to mix these together. You're not confined to one framework or the other all the time. This is entirely driven by choice here. And so she recommends that let's be pragmatic about this. Let's not try to get into these, you know, you might call camps or tribalism of having to really be gung ho about one framework and you're gonna fit this, you know, use this hammer on every job, so to speak, no matter what. Let's be pragmatic about it.
But then she gets to the rest of the the next part of the post where she talks about kind of what's the reason that this is coming about, that she wants to, you know, put this out in the universe, so to speak. Well, in 2018, Mike, there was a certain event on our well, at the time was one of the leading spaces for kind of social type discussions in the art community on Twitter back when it was called Twitter. There was what she calls the great Twitter war of 2018, and take that for whatever irony you wanna read with that. But, Mike, just what in the heck for those that weren't around? What was this all about here?
[00:18:17] Mike Thomas:
Yeah. There were some, accounts on on Twitter and some folks that I guess decided to for whatever reason at that point in time get get fired up about whether or not you should be using data dot table or dplyr. It actually led as as Kelly, I believe, points out, to some positive conversations, between some of the the cooler heads and actually maybe the the more important folks on both sides of the fence including Matt Dowell and Hadley Wickham, I believe to the, development of the dtplyr package which is sort of the best of both worlds where you're allowed to write dplyr syntax that actually translates and executes data dot table code under the hood. So you you get your dplyr syntax, but you get your data dot table performance, which was was pretty cool. But, you know, 2018 on Twitter was a little bit of a different time.
Your timeline was actually relevant to the people that you followed and the type of content that you wanted to see as opposed to nowadays. I don't think, I see any posts from any of my followers on there but I I guess I'll I'll digress. It it was, I would like to say, a better time for the data science in our community and it was a nice place to to come together as opposed to now. We have a few disparate places to to try to do that, Macedon being being one of those places. But for whatever reason, you know, most of the discourse, most of the time was great. And in 2018, a a few people decided to start, you know, throwing stones from the data dot table and tidyverse sides of the fence at each other, for some reason. But I I I think most of the the cooler heads out there either either stayed away and and just sort of watched with their popcorn and how silly everybody was being, or, you know, tried to, try to add their their 2¢ and make the conversation a little little more productive as I think some folks did.
But, you know, that's that's social media, I guess, for you. And,
[00:20:21] Eric Nantz:
for better or worse, Mike, for better or worse.
[00:20:24] Mike Thomas:
Exactly. I think there was a lot of better, but that was one case of it it being worse. And, yeah, you know, I love the approach that that Kelly took to this blog post and I couldn't agree more. To me, not to draw too much of a parallel to, like, like, politics, but you don't always have to be in necessarily one camp or the other and just, you know, blindly believe and and associate with one side or the other. From a project to to project basis, data dot table may make more sense for your project in one project and then the next one that you go to tidyverse may make a whole lot more sense to use and that is okay.
Everyone listen. That is totally okay. You know, now DuckDV maybe, you know, the better solution than either one of those for your next project. Who knows? Like the thing that we love and that Kelly loves about the ecosystem is that we have choices and and that's incredible. And you should use whatever choice you feel makes the most sense to you, at the time and for the particular project that you're working on. So, in my opinion, you know, this is a great reflection. Very happy to hear that, there's been some grant funding towards the data dot table project that's going to allow that open source project to progress. That's something that we don't see a lot of the time where open source developers and community actually get get funding for their work and and for all the hard work that has gone into this project because, you know, if you take a look at the history of data dot table and what we're going on going on 15 year or yeah. Something like that. Right? Going on 15, 16 years of the data dot table project.
There's been an incredible amount of work that has has gone into it and helped it evolve and get to the place it is now. So it's it's fantastic to see a piece of software have that type of longevity and, you know, it it looks like that's only going to continue.
[00:22:21] Eric Nantz:
Absolutely. And, Kelly, we'll be talking a lot about this topic more in-depth at both the USAR conference coming up in July as well as PASIT conference. So I have a talk about these themes. And what's interesting here is, as you mentioned, there is funding for this recent effort and, well, through, you know, a a coincidental, situation. I was able to hear more from Kelly herself in a recent meeting, but this funding is coming from a National Science Foundation grant, that was carried out, I believe, ill, back in 2023. In fact, we may have covered parts of this in our weekly highlights way back when the launch of what they call the data dot table Ecosystem Project.
And this is being headed by Toby Hocking as well as Kelly's involved with this as well. We'll have a link to this in the supplements of the show notes here. But this is meant to not just look at data dot table from literally just the source code perspective, but to help fund the ecosystem around it, which is both technical and infrastructure and social and making sure that it is sustainable for the long term. Certainly, Kelly is gonna be speaking about these themes in her upcoming talks, but there is one huge difference. And when you look at the history of data dot table as opposed to the history of tidyverse, is that let's be real here.
Who's funding the tidyverse? It is a dedicated vendor, ieposit, helping to pay engineers full time, open source engineers to work on this. Data. Table does not have that. It is enthusiastic But like many projects in open source, it is built on the community to help drive that innovation, drive that continued development. So I know part of the motivation of this grant is to help make sure that that ethos is sustainable for such an important piece of many, and I do mean many in the community that rely on data dot table for all sorts of uses. I mean, I just spoke of a couple of them, but I always scratch the surface.
And I've had, like I said, great success with certain pieces of it in my workflows, and I don't feel ashamed about that. Like, Mike, you said, Mike, I wanna choose what's best for the job. And by golly, I'm not gonna have any regret because in the end, I gotta get my stuff done. Right?
[00:24:55] Mike Thomas:
Exactly. Exactly. And it's like, I can't say enough. It's amazing that we have these choices. It's amazing that these choices are so robust and so powerful, and so well supported. So, you know, hats off to sort of a great perspective, I think, hereby Kelly. Fortunate enough to I believe have met Kelly at last posit conference. I think she was in our our shiny workshop which is really cool. That's right. So she she is absolutely awesome and I'm very happy to see this blog post from her.
[00:25:33] Eric Nantz:
Well, we're gonna go back to the development side, Mike, a little bit because our next post is gonna talk about ways that you can at least help future you even more even when you're already buying into proper version control. And what we're talking about here is a latest post from Al Salmon who, of course, has been a frequent contributor to our weekly both as a curator and now contributor to many great highlights in this podcast. And she speaks about why you should invest in not just doing version control, but helping future you by making what she calls small and informative get commits.
Because I don't know about you, Mike, especially even now, sometimes when I'm in a tight bind and I realize, oh my goodness, I have about 10 files that I've gotta get committed now because the time's running out. I, I've I fall to temptation, hit all the checkboxes, hit stage, just say, get this a prod in my commit and be done with it. Yes. It still happens. Yes. I know better. And that's why this post is gonna help you figure out why what I did was such a big mistake. Because let's say you get to a point in time and you're either doing a code review, maybe a colleague's doing a code review for for example, and they see a line in your code.
And they're thinking, well, Eric, why did you do that? Like, what was the motivation for that line? You don't have a comment around it because at the time, you're just trying to fix maybe fix an issue or something in your head, and then you didn't put it into prosperity and via commit or a comment. Well, of course, we get you can go back and look at the history of your commits. Right? And in fact, there is a concept in Git. They call it Git blame, but I I'm with my I'll hear. I hate that terminology. It's really not blaming anybody, but it's better to be called git explain. I like the way she phrases that because then in a platform such as GitHub, you could have the view of the code itself, I. E, the file, but then next to it, see which commit message related to that change.
And you might see in that example that I gave that this mysterious line was part of like this massive 10 file commit and you just have something that says, get the prod or just get it done, get out of my hair or whatever you wanna call it. Well, that's not gonna help very much. But had you done small informative commit messages where you do, like, one file at a time or maybe a set of related changes even if they're spread across multiple files. That get blame methodology can be very helpful for you to go back in time and figure out what were you trying to fix. Were you trying to add a new feature? What was the motivation for that? A bit of like a a way to get a lens into your development journey of what happened there.
So, again, if you do what I said was a bad thing to do and just put all these files in one big commit, you're not gonna get any real benefit out of that. But like I said, had you done a small informative message of that particular change, and again, it might be one file, it might be related files, it's gonna make it so much easier for both you and collaborators to figure out just what was your motivation for that. So that's one reason to do it. But there is another reason, especially if you realize that over time, maybe it's only like a month later, maybe it's a long time later, Something is not working, and you've got to figure out just where it started to not work.
That's where Mike Sheehyah takes us onto another concept and get that I don't do enough of, but I can definitely say if you're behind on certain situations. Why don't you take us through that? Yeah. So my Elle talks about this tool that I admittedly
[00:29:42] Mike Thomas:
do not use, this this function I guess you might call it that get offers us called git bisect. And what git bisect allows you to do is to try to identify the particular commit in history where your software was was working. And it it'll make you try some commits to help pinpoint, you know, which commit exactly introduced the bug that you're now observing and it sort of breaks your code, into 2 sections sort of before, everything was working and then after sort of everything fell apart. And it will assume that all commits are up to that particular commit that you're bisecting on were good, and it's gonna make you sort of explore, commit by commit the the the following ones to to figure out exactly, what introduced the breaking change. And it's it's a really nice feature that sort of allows us to I don't know. It almost feels like the debugger in a way in in R where you're able to sort of go commit by commit very slowly and figure out exactly which one is the one that introduced that that breaking change. And and hopefully, if you made small commits, we're able to identify that git commit that that broke things as, you know, this small diff that that in Mel's example shows, you know, 2 changed files with 3 additions and 2 deletions.
If we're very unlucky, it's going to have a message like one of those that Eric writes occasionally and I have never certainly ever ever written a commit like that that says, you know, commit a bunch of files and it's at, you know, 6 o'clock on a Friday and the the diff shows a 145 change files with 2,600 editions and 22100 deletions. We we certainly hope that's not the case but but maybe it is. But GetBisect can help you get to that point. You know, one nice additional thing that we have, in our ecosystem now is is both unit testing and and services like GitHub Actions and and formerly Travis to when you do make a new commit, you can test, you know, you can execute your unit test to make sure that everything continues to work, after that new commit has been introduced and and this is certainly something that I I think everybody that uses Git can be guilty of is is not making small enough commits. I have sort of this long standing issue where I know that I need to make multiple changes to the same file, and I will make the first change and forget to just sort of commit that small change and I will make 3 different like conceptual changes within the same file.
And now I either am at the mercy of, you know, trying to undo those particular, you know, changes number 23 and just revert back to to change 1 and and make my commit message small and and related to that. Or try to write some 3 part commit message, that, you know, sort of tries to explain that the 3 different changes that took place but it's it's not good in either way is is really ideal or easy. So the best thing that I could possibly do is to stop after I make that first change to the file, make my commit, and move on to the second change. But but sometimes, you know, when you're in the zone, it's hard. It's hard to stop and and lift your fingers up off the keyboard and and remember to do that instead of just knocking everything out at the same time. But Git blame is and it should be called Git explain. I agree as well. I think it's a fantastic tool when we do have to go back and, you know, try to figure out sort of sort of what went wrong, what is the the status of, our our software at the point in time that that things went wrong, what what does our repository look like, and how can we sort of pinpoint where things went wrong and and what led to that. I think GitLab is a fantastic tool. I admittedly don't use it enough, but I do know the people that do use it and rave about it, and find it very helpful to their workflows. So it's it's one that I think my Elle is, inspiring me to dive a little bit deeper into and to start using a little bit more. So I I certainly appreciate the overview here. I I appreciate, the introduction and to get bisect as well because I think that that is gonna be a new handy tool that I'll be able to use in these, you know, tricky, situations where where something breaks and it's not trivial to pinpoint where it took place.
[00:34:19] Eric Nantz:
I really like your your relation earlier to the concept of a good bicep and debugging your code because it made me think of a debugging technique that Bicep kinda mirrors a little bit in that if you have a long r script, wherever it's a Shiny module or any any data processing thing, for example, and you know there's an error somewhere, maybe it's a function or whatnot, but you just don't quite know where it is, A lot of times, what people will do is they will comment out or start putting the browser at, like, a halfway point, and then they'll see, oh, wait. Is the error happening before this or after this? And if it's happening after somewhere, then you know that the rest of the code above it is working. And you kinda go in this I don't know what the proper term is, but you kinda go half by half or a certain percentage.
And that's where get by site kinda starts you off with is you're gonna find that known point, at least that your conjecture is, and then you tell it, okay. Oh, yeah. This one works. I'm going to go to the next part, the next part, the next part. But none of this none of this is going to help you if you don't follow the advice from the start on these fit for purpose, you know, you know, targeted commit messages. And, again, yeah, Mike, I you've you've always been a pro with this. Like, you you don't need any advice here. But little old me, I I did some shortcuts even this year that I'm not proud of. So myel gives me a reality check that, you know, sometimes I need from time to time because I'm not perfect. What can I say? But if you wanna practice some of this in the confines of r, Nael has made an r package, which I'm going to butcher the name once again, of superlipopet or something to that effect where you can practice get concepts in r, albeit with your get client at hand to practice things like BISEC. Practice things like, you know, commit messaging or restoring or branching and things like that. So if this is all novel concepts too and you're wondering what's an easy way to kind of practice this about risking the destruction of a production code base, I recommend her pack as superwhippulpit.
That's the best I can do. But that's a that's a great package nonetheless.
[00:36:39] Mike Thomas:
That's the best I could do as well. And that it's my first time taking a look at that package, and it's incredible. It's fantastic. Allows you to to practice all sorts of git commands including git bisect, which is is really really cool. I think that's really powerful because it's very difficult to practice Git in a in a sandbox, I guess, unless you're spinning up a brand new a brand new project, but then you don't really have any history to play with. So this is a great great reference here.
[00:37:06] Eric Nantz:
Yeah. And there's one other tidbit that I've seen both her mention, although be a not so much mentioned specifically, but then I see others in the community that I follow follow this trend as well is that at the beginning of a commit, they'll have a short phrase, maybe a one word phrase that describes the intent of that particular commit. It may be fix or feature or chore or things like this. I'm trying to opt into that a bit more because that's a handy way if you're looking at your history of your commit messages to isolate very quickly to distinguish between a new feature type of commit versus a bug fix commit versus, oh, I gotta rerun that r oxygen documentation again, regenerate the man pages as like a chore kinda commit because it's a chore to do. I guess that's where that naming comes from, Mike. But, have you have you done any of that in your commit messages?
[00:37:59] Mike Thomas:
I haven't. We have some folks on my team who are are just fantastic developers who I have noticed recently do that, very much so in in all of their commits and are very consistent about it and it's, sort of a practice that I'm still maybe getting used to reading and and trying to decide whether that is something that we should try to adopt globally across the team, or not. You know, I think the idea of of creating issues and branches that reference those specific issues and, you know, obviously, your commit messages are are on that particular branch sort of lets me know exactly what is being accomplished here with maybe up without perhaps needing, all the way down to sort of the commit message level of granularity, letting me know sort of what's being worked on.
But I I think on some particular projects, especially, maybe where it's not as clear cut of an issue branching workflow and maybe we're we're making commits to a particular branch that are across a wide variety of, of types and use cases, you know, both development work, bug fixes, chores, things like that. I think that that might be possibly a great idea. So, it is something that I have have seen. I'm just not sure if I am all in on it yet, but I don't see any drawbacks to it.
[00:39:22] Eric Nantz:
Yeah. I've I've been seeing it enough where it's like I'm gonna start paying attention to it. And maybe for my next project, I'll give it a shot. But like anything I get, it's not just the the the mechanisms of doing it. It's the discipline to keep doing it. And, again, if nothing else to take away from this, be kind to future you, be kind to future collaborators, Small fit for purpose commit messages will help you. Even if it takes a while to get used to, you'll thank yourself later. And, yeah, that goes with testing as well. Don't ask me why I think testing is a good thing because I've I've been bit by that too. I'll be a nut with hardware failures.
[00:40:01] Mike Thomas:
When AI does finally get good enough, I will try to create a Mael hologramrubber duck on my desk that can just yell at me when I'm I'm doing the the wrong software development practice because I need this advice constantly and I'm very grateful to all these blog posts that she puts together to to remind me to, stay the course and continue to incorporate those best practices.
[00:40:28] Eric Nantz:
Unlike some other things in AI, that is one that I would welcome to have next to me monitoring me through many points in my dev journey.
[00:40:36] Mike Thomas:
Me too.
[00:40:53] Eric Nantz:
I'm rounding out our highlights today, at the risk of dating myself with a reference here. I feel the need for something, Mike. You know what I feel the need of? The need for speed because it doesn't just apply to one aspect of data processing. It also applies to the way we consume data coming from these robust APIs and combining that with the very vast evolving ecosystem of geospatial data and performance. Our next highlight has the intersection of all these and definitely made me do a few double takes in terms of the metrics that we're about to talk about here. In particular, we're talking about this post that comes from Josiah Perry who has been a long time member of the r community, and his tagline lately is helping r be built and used better in production.
And his blog post here is his journey on making what he calls a ridiculously fast API client in r. And his day job is working for a company called called Esris, who is specializing in putting on these certain services to query geospatial data from many different development frameworks. I believe they have some host of services as well. Well, as I'm guessing as part of his daytime responsibilities, Josiah has released a new r package called arc just geocode, all one word, the big name here, which is an r binding and our interface to what they call the ArcGIS world decoder service.
And he says that this looks like an official package from his organization, Esri, in this space. And in his knowledge, up to this point, he's got some metrics to prove it. He claims that this is the fastest geocoding library available in the entire our ecosystem. In fact, he's claims that our just geocode is about 17 times faster when you do what's called a single address geocoding and almost 40 times faster when doing a reverse geocoding lookup as compared to other packages in the community already in this space. So let's dive into this a bit more.
His first reason for why this is important is that some I took for granted until a recent project, I talked about the onset with some of this podcast metadata JSON data is that parsing JSON data is not always fast, my friend. Not always. Many of us are using JSON Lite, the, you know, almost tried and true package offered by your own ooms for, consuming and writing JSON data in r. And it's it's it's been a huge help to me. Don't get me wrong. But it does have some performance issues, especially when dealing with long text strings in your JSON data and then bringing that conversion back to an r object and the other way around.
Well, guess what? Another language that starts of r comes at a rescue in in Josiah's initiative because there is a rust crate, that's kind of their term for packages, called SERDAY or SERD, I'm not sure if I'm saying it right, that handles both the serialization and deserialization of structures and rust. And guess what? It is very tailor made to JSON data too. It just expects you at the onset to help specify for your given JSON type data you want inside your your session, the specific attributes of each variable or each field. So in his example, he's got an address structure, if you call it, with all the different fields that would come out of this JSON data.
And most of them, big surprise, are strings, but it'll give you the ability and rust to really determine what's supposed to be a string, what's supposed to be an integer, different types of integers. You can go, you know, really specific on all these needs. Now that's great and all, but how does that help with r? Well, there is the package called extender, which is kinda like the RCPP, if you will, of Rust to r. We'll let you tap into a Rust crate and bring that into r and be able to go back and forth with our functions to basically call out to these lower level Rust parts of the paradigm. So this, Serde JSON crate is a massive speed improvement in general for importing JSON data, serializing JSON data over the community counterparts as he attests to in this post.
But that's not the only part. The other part is a feature that I should have known about in my research in HDR 2, but it just went over my head until this post, is that we often use HDR, HDR 2, and this is the regeneration of that, if you will, by Hadley Wickham to help in r perform these, you know, requests to API services. I get request, post request, and whatnot. And, usually, I do these requests kind of 1 at a time, if you will. Like, there's a get request. I'm gonna do that with specific set of config parameters, bring it back down and whatnot.
Well, how in the world did I not know about this function, Mike? Rec perform parallel,
[00:46:29] Mike Thomas:
which lets you do it in more than one time. Oh my gosh. Where have I been, Mike? Did you know about this? Neither did I, Eric. I had no idea that this was part of the h t t r two package now, that we have the ability to send, I guess, paralyzed request to an API pretty easily and maybe point that function towards a connection pool or a few different nodes, few different workers, to be handling requests concurrently. This makes me think of, I don't know, potential integration with the crew package or something like that. Perhaps this is something that you could do on your your own machine and and leverage, you know, the the ability to parallelize your own machine and and send out a few different requests, at the same time which is is pretty incredible.
And there's this Twitter thread that Josiah puts, earlier on in the blog post where he's, you know, he's he's showing off the fact that he was able to geocode, 2.6 1,000 addresses in in 3 and a half seconds. And and somebody asked, in as a reply to that particular screenshot that he put up, they said, isn't geocoding always bottlenecks by the server? And, that is true. But I guess when you have multiple servers to span the job across and we have this beautiful function request perform parallel that I imagine brings it all back together at the end.
That's that's a fantastic utility to be able to, you know, speed up, significantly and and this is something that I've dealt with in the past as well, geocoding. It takes time because you're typically going address by address and, you know, a lot of projects you'll you'll want to be geocoding your entire data frame which could get, you know, could get particularly long you know thousands tens of thousands hundreds of thousands of observations that you need to geocode so it's really interesting to me that we have the ability, you know, not only to leverage the speed of Rust, for this serializing and deserializing of JSON objects which is time intensive, but also, being able to just break the job out into across a few different, nodes here which is is pretty incredible, something that I didn't know about. Obviously, Josiah says that you need to be a little bit careful when you are doing anything like this especially when you're sending sort of paralyzed paralyzed requests at a different service that you don't perform, an accidental denial of service attack, you know, which is where you you make way too many requests all at once to the service and bring that down. So you don't wanna be the person that does that. So so certainly be be careful and perhaps, you know, use a small number of workers.
If you're just geocoding a couple thousand addresses, you don't need to spin up a few hundred workers or something like that to be able to do that just just spin up a couple and and maybe wait those extra few seconds that it's going to take, to be patient between, you know, spinning up a few workers and and many many workers. But it's really interesting because you will get, you know, these this great sort of orders of magnitude returns in performance, when you do add compute to the problem here as well as, you know, leveraging Rust for that that quick deserialization, of of JSON data. One thing that I will also shout out just because I was curious about this and, you know, we're finding all of these new, faster programming, software utilities out there when it comes to to data.
And there is a DuckDb extension as well for handling JSON data and reading JSON data and so I would be interested to see how that compares to what Rust can do for parsing JSON data as well.
[00:50:16] Eric Nantz:
But both very fast, I'm sure. Yeah. They are. I'm experimenting that a little bit too actually in my DuckDV adventures and I'll definitely come back with my findings as I get that more polish. I'll be at the hardware catastrophe, put a stop on that for a bit. But, nonetheless, I'm really intrigued by the concepts that, Josiah, parts in this post here. And then at the end, he recommends additional packages in the community that if you're still not quite ready for the plunge to Rust for some of these efforts, if you're not ready to build, like, an internal JSON parser that depends on Rust, There are some additional JSON related packages in the r community that definitely take a look at. He recommends the RCPP SIMD JSON package as a great way for parsing data as well as the y y JSON package that comes from the affectionately known cool but useless on the our community. He's got a great package called y y JSON and also JSONify, which I don't have as much experience with. But you might wanna take a look at each of those too and see it for your parsing needs or writing serialization needs. If that just gets you good enough without while being able to stay in the confines of of R directly.
But, nonetheless, this is great learning for me personally as I'm starting to deal with JSON data more and more in my open source work as well as my internal day job stuff where we just built an API binding package. But we're running this in the day to day use with, patient level data set where there's, like, multiple visits, multiple, obviously, patients in a treatment group, and it's basically doing these get requests to this custom service 1 at a time for each of these calls. My goodness. I could do the rec perform parallel and probably speed that up a bit. So I'm gonna have to take a look at this and hopefully not make my IT admins angry when I start to paralyze this.
[00:52:14] Mike Thomas:
Definitely do it on a, development cluster to start. That would be my recommendation.
[00:52:19] Eric Nantz:
Yes. Because, yeah. That that was another, story time from years ago when when I, was too greedy with multi cores, and I took down an entire HPC cluster. Don't be that person, everybody. Just don't be that person. I remember that story. Yes. Who lives in infamy. But, what lives in good ways, of course, is the rest of the our weekly issue itself. Tony's done a terrific job as always he does with the rest of the issue. We got so much we could talk about, but we're gonna have to wrap up here with our additional fines over this issue. And, Mike knows and many of you know I am a retro gamer at heart, not just with retro games, but also I have fond memories of going to the local arcade and putting some quarters on those awesome pinball machines that waste a lot of hours on that. Well, there is a fun post that combines things like, geospatial data, API calls, and some handy visualizations from Rasmus Bath. He calls this the public pinball machines per capita looking at where pinball machines are most distributed around the world.
And and as post surprise, surprise, the United States is in the lead with this, but Europe is not far behind in some of their visualizations. But his post goes into how he attained this data, loading the packages. And guess what? It's coming from an API just like everything else. He's got some, you know, really elegant code to do this. Really modern code here. They was using HTR 2 as well and some great handy visualizations built in ggplot for the distribution of these, pinball locations and some word clouds too. So really, really fun stuff here. And, yeah, it makes me get the itch to get some quarters out and find that retro arcade to, you know, knock out some pinball action. So that was fun. But, Mike, what did you find? Very cool, Eric. I found an oldie but a goodie. I think at the the recent,
[00:54:21] Mike Thomas:
our conference that's held in New York by that under Lander Analytics hosts, there was a panel discussion about your favorite R package. And I believe it was, who's the author of the data science Venn diagram there? Drew Conway. He was being asked what his favorite R package was and and I think it was one, it was called iGraph and I think it's one that's been around for a long long time, for doing, I believe, network analysis type stuff in, r. And I saw on the highlights this week that r igraph has crossed the 2.0 threshold.
So it's it sounds like, you know, similar to data dot table that this is another package that has had quite a life to it, continues to be very very well maintained, and it's it's just awesome to see a package like that be able to have the longevity it has.
[00:55:13] Eric Nantz:
Yeah. IGraff, I have tremendous respect for. It is the engine behind many, and I do mean many, of the r packages that provide some kind of network visualization or processing. My exposure to this has been using some custom eye graph bindings inside a widget called Viz Network, which I have a kind of a love hate relationship with, but I've done enough customization to wrangle it to my particular needs. But, yeah, iGRAS been around a long time, and it is prevalent in additional languages as well. But, yeah, huge congrats to that team for the 2 point o release. And I know, yeah, my whole biograph stays around for a long time because it is a fundamental pillar in these, network visualizations. So awesome
[00:56:01] Mike Thomas:
awesome call out there. I grabbed 0.1 released in 2006. Even older than the data that table.
[00:56:08] Eric Nantz:
My goodness. Yeah. As if I didn't feel old enough in this post. Good grief. What are you what are you doing to me, man? I I I need to get a youth injection or something. But what makes me feel youthful is just seeing what's happening in this community. Again, really great developments happening. Really great showcases of data science, you know, providing good to everybody involved. So where can you see this all? Where we've been talking about here, so many of our great wings are available at rw.org. Many additional findings here, many additional developments of packages.
We need to touch on all the newer packages out there. There's so much happening in these spaces, but we invite you to bookmark that site if you haven't already to check it out on a weekly basis. And also, we love hearing from you in the community. There are many ways to get in touch with us. You can send us a contact or message on our contact page, which is in the episode show notes. So, again, keep those comments coming. We love to hear from you. You can also, in the modern podcast app, such as PowVerse, Fountain, Cast O Matic, Curio Castor, there's a whole bunch out there. You can send us a fun little boost along the way if you want to send us a message without any middle thing in between. And no harbor failures on that one either.
But and the other way you can contact us is on social media as well. I am mostly on Mastodon these days with at our podcast and podcast index on social. I am also on LinkedIn. Just search for my name there. You'll find me there and sporadically on the weapon x thing with FDR cast and a special little shot. I didn't get to it in my stories time. But I had the great pleasure of having a, little dinner with, the author of GT, Rich Yone, who was in town for a local conference. So great fun talking with him, all things are, and someone he's up to. So, Rich, if you're listening, thanks for coming into town even for a brief couple of days. A lot of fun learning from you. But, Mike, we're gonna listen to get a hold of you. That is awesome. I am so excited for POSIT conferences here to be able to see some see some community faces. But, folks, until then, can get a hold of me on mastodon@mike_thomasat
[00:58:20] Mike Thomas:
fostodon.org or on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k, you can see what I'm up
[00:58:28] Eric Nantz:
to. Yes. And, hopefully, I don't see any messages about any failures in your infrastructure. Let's call it that. Let's keep keep our fingers crossed. But, yeah, just don't do what I did. That's the best advice for today. But in any event, we thank you so much for joining us wherever you are and wherever you are in your our journey. We hope that we're a little bit of a help along the way. And one of the best ways also to help us out is just share the word. You know? If you got value out of this podcast, we'd love for you to share it around, tell your friends, and always great to expand our audience for those that are getting started with our we think our weekly is one of the best resources for anybody in this community. Am I biased? Absolutely. Yes. But, hey, I speak I speak the truth here, I think, in any event. We're gonna close-up shop here, and we'll be back with another edition of our weekly highlights next week.
Hello, friends. We are back with episode 168 of the R Weekly Highlights podcast. We're so glad you're here listening from wherever you are around the world. And this is the show if you are new to this podcast. This is the show where we talk about the terrific resources that have been highlighted in this week's our weekly issue, all available at rweekly.org. My name is Eric Nantz. As always, I'm delighted that you've joined us wherever you are. We have a lot of fun things to talk about, but this is a team effort after all. And I got my partner in our related crime here, so to speak. Mike Thomas is here. Join me at the hip. How are you doing today, Mike?
[00:00:40] Mike Thomas:
Doing pretty well, Eric. Not to violate any HIPAA laws and knock on wood. I am currently trying to dodge pink eye in our household so far. So good, but, I've I've heard that it's it's not fun. This is our first go around with it. So please pray for me. But We, we we have you in our thoughts for sure as somebody who's had a whole smorgasbord of
[00:01:03] Eric Nantz:
illnesses, viruses, things, and that and the kiddos, daycare days. Yeah. You,
[00:01:10] Mike Thomas:
keep strong, my friend. Thank you very much. But, Eric, how was your weekend?
[00:01:15] Eric Nantz:
Yeah. You know what? It's been a while since we did this. We're gonna dust off a segment I used to do in my in my live streams. Who's ready for story time with our
[00:01:25] Mike Thomas:
podcast? Beybey.
[00:01:30] Eric Nantz:
So it's story time with Eric now. So let's, buckle up for a few minutes here. So Friday night, I get a little opportunity to do a little, you know, open source development work on some of this podcasting database stuff. I've been pitching in with a podcasting 2 point o project. And recently, Dave Jones, who helps spearheads a lot of that effort, gave me access to some more lower level JSON files and object storage to help analyze some of the the data that's going into their database as kind of a more real time access of it. And these are these are actually massive JSON files. In fact, one of them is over 200 gigs worth. So I figured, okay. You know what? To help, you know, minimize the bandwidth cost just for once, I'm gonna download a snapshot of those locally on my, you know, somewhat beefy network storage down in the basement where I have, like, a group of 4 hard drives networked together, and that's where I do all my backup. So I figured, you know what? I'm just gonna throw it on there. That way, I can, you know, work with them in a prototyping way like any good citizen would do with bandwidth and everything like that.
So that was like, earlier in the week, and then Friday night rolls around. I'm gonna do a little hacking on it again, just kinda get to know those files a bit. Go to the path. My, laptop mounts. This is like a Samba share. But I I go to and it's run Linux, but Samba is the protocol. So in any event, I go to grab one of these files or always read it into R. It's kind of like a prototyping. And then I get a path file not found. And I'm thinking, what's this about? I know I downloaded earlier in the week, and it's alongside a bunch of my other kinda our open source, like big file stuff. And I go into the SSH session to my network storage that's running Linux. And I navigate to that area, directory not found.
Oh, no. Oh, boy. So I do a little poking around, and I realize that's not the only thing that I found. I am now not able to see some very, and I mean very important family media files, which if you guess are pictures and videos that I've recorded over the years. No. No. No. No. No. No. No. No. No. No. No. No. Now now I when I set this up many years ago, I did put in a couple backup strategies, one of which was to send my pictures over to Google Drive, albeit in an encrypted way so that I didn't feel like I was feeding their machine learning algorithms for image recognition and whatnot.
And so I quickly dust off my notes on how to interact with that. I was using a service called Duplicate to get that. And luckily enough, I did get the majority of my pictures back, albeit they stopped working after 2023, which was odd because I didn't get an alert on that. So that's one downside. But what was not on that cloud backup were the videos. So back to this internal setup, I have what's called a pooled file system of all these drives put together. And then there was an weekly job I would run that was kinda like RAID. If you ever heard of, like, how network drives are backed up in, like, a mirrored way, RAID is one way to do it. This is a different take called SnapRAID where it would, every week, funnel everything into what's called a parity drive.
And that way, if the worst happened, I could restore from that parity drive and get everything back. So I figured, oh, yes. I I did run that job. Right? Now I go to where that file would be stored. It's like this big compressed file. But then my heart sank because the last run of that, apparently, was in 2020, and I didn't know that. I still ran the restore anyway just to see what happens. And sure enough, I've got videos and pictures and other important files up to that point. So I am missing now 3 almost 4 years' worth of important content. So, of course, now I investigate, can I mount this drive somewhere else?
Can I just take it out of this network storage and put it into, like, an enclosure, connect it to my laptop, see if I can somehow salvage the files from there? That's when I realized there's the problem. The hard drive is making this sequential kind of buzzing kind of sound and cannot be recognized by any OS. That screams hardware failure. So I have now sent this to a drive recovery vendor. I'm waiting to hear back for the evaluation if they can get everything back. But if they are able to get it back, I hate to say it's not gonna be cheap to get it back. But this is a very harsh lesson, folks. If you have a backup strategy, make sure to check that it's actually working.
If you learn nothing else from this 5 minute diatribe, look at your backup strategy. Make as many notes as you can because future self will need it when you absolutely positively least expect it like little old me here.
[00:06:55] Mike Thomas:
Eric, I'm so sorry. For our dear listeners out there, I asked Eric how his weekend was, and he would not tell me because he wanted to get my live reaction during the recording. And my live reaction is is despair, but I am almost, also not entirely surprised because I feel like story time with Eric probably sways a little, towards the the bad as opposed to the good if we're taking a look at the distribution of sort of sentiment around story time with their stories. I am sorry to hear that. I hope that that hardware vendor can can help you out some way somehow and it's not super expensive but, yes, that is, I think something we all struggle with is is backing up and and storage of especially, like, family media and stuff like that. I don't have a good strategy for it. Yeah. Oh, that that hurts my heart. That hurts my heart because I know how much work you've invested into building out, you know, your your hardware and software infrastructure in in the best ways possible and using the the best practices. So,
[00:08:03] Eric Nantz:
I'm so sorry to hear that. Oh, I I appreciate that. But life is so ironic. Right? Of all the drives to fail, the one that has a majority of these family files, files, that had to be the one. I've got other nonsense on there that I could live without. It's just out of convenience, but it had to be that one. So on top of, yeah, this vendor crossing my fingers, I will not say who they are because I'm not sure if it's gonna work or not. So I'm not giving any free advertising here. I hope this vendor actually pulls it off. But the other lesson is I was kinda living on borrowed time with some of the infrastructure around this. So I am building as we speak. The parts are coming in the next couple weeks. A brand new server that's gonna have a much better strategy around it. So there you go. That'll be some rabbit holes.
I does not surprise me at all. Best of luck with that. Yes. Thank you, sir. And, you know, one way or another, I'll I'll, share my learnings. They're they're this machine will double purpose. It will not just be a storage piece. This may be a piece where I can do some local Weaver machine learning stuff, AI stuff, or whatnot because I'm gonna I'm gonna spec it out pretty well for those workflows and media production. So it'll be a fun journey nonetheless. Just not one I was quite ready to do until Sure. This, certain event. Well, once you, install the Microsoft operating system and and turn the the Microsoft recall switch on, you'll never have to, you'll never have to worry about backing up anything ever again because it'll just watch you all the time. You know what? Yeah. What better peace of mind than to send that over to whatever they're training on? Oh, my goodness. For those of you who aren't aware of what we're talking about, that, Microsoft kinda got in a bit of a kerfuffle when they announced this feature, if you wanna call it that, where they would have a background process on your win Windows installation literally every, what, I don't know, 30 seconds.
[00:10:02] Mike Thomas:
Oh, no. I think it's less than that. I think it's, like, every second or every other second. It's gonna take a picture of what's on your your laptop screen.
[00:10:11] Eric Nantz:
I wow. I mean, just wow. It is is hopefully, some of you may think, yeah, that might have some disasters associated with it and many reasons. So they are rolling it back a little bit in terms of how they're rolling it out. But, nonetheless, the the cat's out of the bag, as they say, of what they've been planning for for this. So I think, more to come on this side of it. But, yeah, of all the things I did not expect to see, that announcement was one of them.
[00:10:40] Mike Thomas:
Likewise. Likewise. It just makes me wanna install Linux instead.
[00:10:44] Eric Nantz:
No. You're not alone. There's a lot of people making the switch after that kind of news, and Apple hasn't quite done themselves any favors either with some of their decisions. But Onto the r stuff. Yeah. Yeah. We've, digressed enough. But, in any event, we don't have hardware failures to talk about in these highlights. Thank goodness. And they have been curated this week by Tony Elharbor, another one of our awesome, curators on the rweekly team. He's been around for quite a couple of years now. And as always, he had tremendous help from our fellow rweekly team members and contributors like all of you around the world with your awesome poll requests and suggestions.
And we lead off the show with really a testament and a glimpse into the vast variety that's available to us with the nature of open source and especially some of the fundamental issues that can occur, not just from a development perspective, but also from a social and other type perspective as well. And this blog post and our first highlight comes from Kelly Baldwin, who is a assistant professor of statistics at Cal PIE, That is California Polytechnic State University for those that are outside of the US and may not know where that is. But in any event, she leads off with framing this discussion on 2 paths, if you might say, in the R community with respect to a lot of the ways that we handle data manipulation, data processing, and what has been perceived to be these separate roads traveled, so to speak. So she frames this post in light of Robert Frost, the road west traveled story.
And she also is upfront that this definitely has some opinions. Hey, Mike and our full opinions on this show too. But I, as we go through this, I definitely see exactly where she's coming from, and I think it's definitely an important discussion to have. What we're talking about here are 2 major frameworks that have kind of, over time, become pretty mainstream in terms of the art community's efforts for data manipulation. 1 is the tidy verse, which is well known by this point. Of course, the development of the tidy verse has been led by Hadley Wickham and his team of engineers at Posit.
And then we have data dot table. Data dot table was around well before the tidy verse. Data dot table, for those that aren't aware, had its first major release in 2008. Yeah. That's, got a dozen in the history books on this, And it was originally released by the core developer, Matt Dowell. And there's a link in the county's post for a nice video of what inspired they are dot table in the first place. And it you know, from near the beginning, they do that table has been so influential for many in the industry and academia, all walks of the life, so to speak, in the r community for respect to its very great performance and importing large data files.
It's got its own, you might call, DSL or domain specific language for how you conduct queries and whatnot and how you do, like, group summaries or filtering or creating new variables. It's got a syntax that is unique to it. And once you learn the ins and outs of it, it can be extremely powerful. And then fast forward about 6 years later, dplyr, the one of the cornerstones of what became the tidy verse, was released in 2014, again, authored by Hadley Wickham. And this, a lot of people point to this as the start of the tidy verse because of this new, at least new to many people at the time, way of performing these, you know, fit for purpose functions that use the data frame as, like, the main input such that you could combine this with the Magritter pipe and do all these nice kind of flowing analyses of data manipulation, you know, new variables, summarizations, group processing, and whatnot.
So with this, you now have, you know, at at this is Kelly Podsits here, about 3 major choices for your data processing. You could stick with base r. Of course, base r, it's got, you know, plenty of ways to do these type of summaries, data dot table, and dplyr. And they're all going to look quite different from each other. There has been a bit of a misconception over the years that data dot table is almost directly linked to base are. That's not quite the perception over the years that it was so perception over the years that it was so tightly coupled with base are that it was somehow going hand in hand with that. No. No. No. That's that's definitely not the case. It's got its own, you know, framework. It's got its own syntax. It's got its own paradigms.
And again, in my opinion, choice is great in this pay in this space. Now, sometimes the kinds of choices, well, which one do I go with? Well, we're not going to always use a cliche, it depends, but a lot of it does actually depend on what you want out of your data processing pipeline. But this shouldn't be a situation where you feel like you have to pick 1 and stick with it forever. Just like any project, you should have the ability to choose the right framework for your requirements or for your job, so to speak, and what's important to you.
But it's one she also talks in this post is that, yeah, sometimes people feel like they have to be loyal to a certain package through and through no matter what. No. We all greatly respect developers, but in the end, the choice is ours for what we choose in our data processing needs in this case. And you shouldn't feel bad about going from, like, a little bit of base r to, like, data dot table or maybe the tidy verse and kinda as you wish to be able to mix these together. You're not confined to one framework or the other all the time. This is entirely driven by choice here. And so she recommends that let's be pragmatic about this. Let's not try to get into these, you know, you might call camps or tribalism of having to really be gung ho about one framework and you're gonna fit this, you know, use this hammer on every job, so to speak, no matter what. Let's be pragmatic about it.
But then she gets to the rest of the the next part of the post where she talks about kind of what's the reason that this is coming about, that she wants to, you know, put this out in the universe, so to speak. Well, in 2018, Mike, there was a certain event on our well, at the time was one of the leading spaces for kind of social type discussions in the art community on Twitter back when it was called Twitter. There was what she calls the great Twitter war of 2018, and take that for whatever irony you wanna read with that. But, Mike, just what in the heck for those that weren't around? What was this all about here?
[00:18:17] Mike Thomas:
Yeah. There were some, accounts on on Twitter and some folks that I guess decided to for whatever reason at that point in time get get fired up about whether or not you should be using data dot table or dplyr. It actually led as as Kelly, I believe, points out, to some positive conversations, between some of the the cooler heads and actually maybe the the more important folks on both sides of the fence including Matt Dowell and Hadley Wickham, I believe to the, development of the dtplyr package which is sort of the best of both worlds where you're allowed to write dplyr syntax that actually translates and executes data dot table code under the hood. So you you get your dplyr syntax, but you get your data dot table performance, which was was pretty cool. But, you know, 2018 on Twitter was a little bit of a different time.
Your timeline was actually relevant to the people that you followed and the type of content that you wanted to see as opposed to nowadays. I don't think, I see any posts from any of my followers on there but I I guess I'll I'll digress. It it was, I would like to say, a better time for the data science in our community and it was a nice place to to come together as opposed to now. We have a few disparate places to to try to do that, Macedon being being one of those places. But for whatever reason, you know, most of the discourse, most of the time was great. And in 2018, a a few people decided to start, you know, throwing stones from the data dot table and tidyverse sides of the fence at each other, for some reason. But I I I think most of the the cooler heads out there either either stayed away and and just sort of watched with their popcorn and how silly everybody was being, or, you know, tried to, try to add their their 2¢ and make the conversation a little little more productive as I think some folks did.
But, you know, that's that's social media, I guess, for you. And,
[00:20:21] Eric Nantz:
for better or worse, Mike, for better or worse.
[00:20:24] Mike Thomas:
Exactly. I think there was a lot of better, but that was one case of it it being worse. And, yeah, you know, I love the approach that that Kelly took to this blog post and I couldn't agree more. To me, not to draw too much of a parallel to, like, like, politics, but you don't always have to be in necessarily one camp or the other and just, you know, blindly believe and and associate with one side or the other. From a project to to project basis, data dot table may make more sense for your project in one project and then the next one that you go to tidyverse may make a whole lot more sense to use and that is okay.
Everyone listen. That is totally okay. You know, now DuckDV maybe, you know, the better solution than either one of those for your next project. Who knows? Like the thing that we love and that Kelly loves about the ecosystem is that we have choices and and that's incredible. And you should use whatever choice you feel makes the most sense to you, at the time and for the particular project that you're working on. So, in my opinion, you know, this is a great reflection. Very happy to hear that, there's been some grant funding towards the data dot table project that's going to allow that open source project to progress. That's something that we don't see a lot of the time where open source developers and community actually get get funding for their work and and for all the hard work that has gone into this project because, you know, if you take a look at the history of data dot table and what we're going on going on 15 year or yeah. Something like that. Right? Going on 15, 16 years of the data dot table project.
There's been an incredible amount of work that has has gone into it and helped it evolve and get to the place it is now. So it's it's fantastic to see a piece of software have that type of longevity and, you know, it it looks like that's only going to continue.
[00:22:21] Eric Nantz:
Absolutely. And, Kelly, we'll be talking a lot about this topic more in-depth at both the USAR conference coming up in July as well as PASIT conference. So I have a talk about these themes. And what's interesting here is, as you mentioned, there is funding for this recent effort and, well, through, you know, a a coincidental, situation. I was able to hear more from Kelly herself in a recent meeting, but this funding is coming from a National Science Foundation grant, that was carried out, I believe, ill, back in 2023. In fact, we may have covered parts of this in our weekly highlights way back when the launch of what they call the data dot table Ecosystem Project.
And this is being headed by Toby Hocking as well as Kelly's involved with this as well. We'll have a link to this in the supplements of the show notes here. But this is meant to not just look at data dot table from literally just the source code perspective, but to help fund the ecosystem around it, which is both technical and infrastructure and social and making sure that it is sustainable for the long term. Certainly, Kelly is gonna be speaking about these themes in her upcoming talks, but there is one huge difference. And when you look at the history of data dot table as opposed to the history of tidyverse, is that let's be real here.
Who's funding the tidyverse? It is a dedicated vendor, ieposit, helping to pay engineers full time, open source engineers to work on this. Data. Table does not have that. It is enthusiastic But like many projects in open source, it is built on the community to help drive that innovation, drive that continued development. So I know part of the motivation of this grant is to help make sure that that ethos is sustainable for such an important piece of many, and I do mean many in the community that rely on data dot table for all sorts of uses. I mean, I just spoke of a couple of them, but I always scratch the surface.
And I've had, like I said, great success with certain pieces of it in my workflows, and I don't feel ashamed about that. Like, Mike, you said, Mike, I wanna choose what's best for the job. And by golly, I'm not gonna have any regret because in the end, I gotta get my stuff done. Right?
[00:24:55] Mike Thomas:
Exactly. Exactly. And it's like, I can't say enough. It's amazing that we have these choices. It's amazing that these choices are so robust and so powerful, and so well supported. So, you know, hats off to sort of a great perspective, I think, hereby Kelly. Fortunate enough to I believe have met Kelly at last posit conference. I think she was in our our shiny workshop which is really cool. That's right. So she she is absolutely awesome and I'm very happy to see this blog post from her.
[00:25:33] Eric Nantz:
Well, we're gonna go back to the development side, Mike, a little bit because our next post is gonna talk about ways that you can at least help future you even more even when you're already buying into proper version control. And what we're talking about here is a latest post from Al Salmon who, of course, has been a frequent contributor to our weekly both as a curator and now contributor to many great highlights in this podcast. And she speaks about why you should invest in not just doing version control, but helping future you by making what she calls small and informative get commits.
Because I don't know about you, Mike, especially even now, sometimes when I'm in a tight bind and I realize, oh my goodness, I have about 10 files that I've gotta get committed now because the time's running out. I, I've I fall to temptation, hit all the checkboxes, hit stage, just say, get this a prod in my commit and be done with it. Yes. It still happens. Yes. I know better. And that's why this post is gonna help you figure out why what I did was such a big mistake. Because let's say you get to a point in time and you're either doing a code review, maybe a colleague's doing a code review for for example, and they see a line in your code.
And they're thinking, well, Eric, why did you do that? Like, what was the motivation for that line? You don't have a comment around it because at the time, you're just trying to fix maybe fix an issue or something in your head, and then you didn't put it into prosperity and via commit or a comment. Well, of course, we get you can go back and look at the history of your commits. Right? And in fact, there is a concept in Git. They call it Git blame, but I I'm with my I'll hear. I hate that terminology. It's really not blaming anybody, but it's better to be called git explain. I like the way she phrases that because then in a platform such as GitHub, you could have the view of the code itself, I. E, the file, but then next to it, see which commit message related to that change.
And you might see in that example that I gave that this mysterious line was part of like this massive 10 file commit and you just have something that says, get the prod or just get it done, get out of my hair or whatever you wanna call it. Well, that's not gonna help very much. But had you done small informative commit messages where you do, like, one file at a time or maybe a set of related changes even if they're spread across multiple files. That get blame methodology can be very helpful for you to go back in time and figure out what were you trying to fix. Were you trying to add a new feature? What was the motivation for that? A bit of like a a way to get a lens into your development journey of what happened there.
So, again, if you do what I said was a bad thing to do and just put all these files in one big commit, you're not gonna get any real benefit out of that. But like I said, had you done a small informative message of that particular change, and again, it might be one file, it might be related files, it's gonna make it so much easier for both you and collaborators to figure out just what was your motivation for that. So that's one reason to do it. But there is another reason, especially if you realize that over time, maybe it's only like a month later, maybe it's a long time later, Something is not working, and you've got to figure out just where it started to not work.
That's where Mike Sheehyah takes us onto another concept and get that I don't do enough of, but I can definitely say if you're behind on certain situations. Why don't you take us through that? Yeah. So my Elle talks about this tool that I admittedly
[00:29:42] Mike Thomas:
do not use, this this function I guess you might call it that get offers us called git bisect. And what git bisect allows you to do is to try to identify the particular commit in history where your software was was working. And it it'll make you try some commits to help pinpoint, you know, which commit exactly introduced the bug that you're now observing and it sort of breaks your code, into 2 sections sort of before, everything was working and then after sort of everything fell apart. And it will assume that all commits are up to that particular commit that you're bisecting on were good, and it's gonna make you sort of explore, commit by commit the the the following ones to to figure out exactly, what introduced the breaking change. And it's it's a really nice feature that sort of allows us to I don't know. It almost feels like the debugger in a way in in R where you're able to sort of go commit by commit very slowly and figure out exactly which one is the one that introduced that that breaking change. And and hopefully, if you made small commits, we're able to identify that git commit that that broke things as, you know, this small diff that that in Mel's example shows, you know, 2 changed files with 3 additions and 2 deletions.
If we're very unlucky, it's going to have a message like one of those that Eric writes occasionally and I have never certainly ever ever written a commit like that that says, you know, commit a bunch of files and it's at, you know, 6 o'clock on a Friday and the the diff shows a 145 change files with 2,600 editions and 22100 deletions. We we certainly hope that's not the case but but maybe it is. But GetBisect can help you get to that point. You know, one nice additional thing that we have, in our ecosystem now is is both unit testing and and services like GitHub Actions and and formerly Travis to when you do make a new commit, you can test, you know, you can execute your unit test to make sure that everything continues to work, after that new commit has been introduced and and this is certainly something that I I think everybody that uses Git can be guilty of is is not making small enough commits. I have sort of this long standing issue where I know that I need to make multiple changes to the same file, and I will make the first change and forget to just sort of commit that small change and I will make 3 different like conceptual changes within the same file.
And now I either am at the mercy of, you know, trying to undo those particular, you know, changes number 23 and just revert back to to change 1 and and make my commit message small and and related to that. Or try to write some 3 part commit message, that, you know, sort of tries to explain that the 3 different changes that took place but it's it's not good in either way is is really ideal or easy. So the best thing that I could possibly do is to stop after I make that first change to the file, make my commit, and move on to the second change. But but sometimes, you know, when you're in the zone, it's hard. It's hard to stop and and lift your fingers up off the keyboard and and remember to do that instead of just knocking everything out at the same time. But Git blame is and it should be called Git explain. I agree as well. I think it's a fantastic tool when we do have to go back and, you know, try to figure out sort of sort of what went wrong, what is the the status of, our our software at the point in time that that things went wrong, what what does our repository look like, and how can we sort of pinpoint where things went wrong and and what led to that. I think GitLab is a fantastic tool. I admittedly don't use it enough, but I do know the people that do use it and rave about it, and find it very helpful to their workflows. So it's it's one that I think my Elle is, inspiring me to dive a little bit deeper into and to start using a little bit more. So I I certainly appreciate the overview here. I I appreciate, the introduction and to get bisect as well because I think that that is gonna be a new handy tool that I'll be able to use in these, you know, tricky, situations where where something breaks and it's not trivial to pinpoint where it took place.
[00:34:19] Eric Nantz:
I really like your your relation earlier to the concept of a good bicep and debugging your code because it made me think of a debugging technique that Bicep kinda mirrors a little bit in that if you have a long r script, wherever it's a Shiny module or any any data processing thing, for example, and you know there's an error somewhere, maybe it's a function or whatnot, but you just don't quite know where it is, A lot of times, what people will do is they will comment out or start putting the browser at, like, a halfway point, and then they'll see, oh, wait. Is the error happening before this or after this? And if it's happening after somewhere, then you know that the rest of the code above it is working. And you kinda go in this I don't know what the proper term is, but you kinda go half by half or a certain percentage.
And that's where get by site kinda starts you off with is you're gonna find that known point, at least that your conjecture is, and then you tell it, okay. Oh, yeah. This one works. I'm going to go to the next part, the next part, the next part. But none of this none of this is going to help you if you don't follow the advice from the start on these fit for purpose, you know, you know, targeted commit messages. And, again, yeah, Mike, I you've you've always been a pro with this. Like, you you don't need any advice here. But little old me, I I did some shortcuts even this year that I'm not proud of. So myel gives me a reality check that, you know, sometimes I need from time to time because I'm not perfect. What can I say? But if you wanna practice some of this in the confines of r, Nael has made an r package, which I'm going to butcher the name once again, of superlipopet or something to that effect where you can practice get concepts in r, albeit with your get client at hand to practice things like BISEC. Practice things like, you know, commit messaging or restoring or branching and things like that. So if this is all novel concepts too and you're wondering what's an easy way to kind of practice this about risking the destruction of a production code base, I recommend her pack as superwhippulpit.
That's the best I can do. But that's a that's a great package nonetheless.
[00:36:39] Mike Thomas:
That's the best I could do as well. And that it's my first time taking a look at that package, and it's incredible. It's fantastic. Allows you to to practice all sorts of git commands including git bisect, which is is really really cool. I think that's really powerful because it's very difficult to practice Git in a in a sandbox, I guess, unless you're spinning up a brand new a brand new project, but then you don't really have any history to play with. So this is a great great reference here.
[00:37:06] Eric Nantz:
Yeah. And there's one other tidbit that I've seen both her mention, although be a not so much mentioned specifically, but then I see others in the community that I follow follow this trend as well is that at the beginning of a commit, they'll have a short phrase, maybe a one word phrase that describes the intent of that particular commit. It may be fix or feature or chore or things like this. I'm trying to opt into that a bit more because that's a handy way if you're looking at your history of your commit messages to isolate very quickly to distinguish between a new feature type of commit versus a bug fix commit versus, oh, I gotta rerun that r oxygen documentation again, regenerate the man pages as like a chore kinda commit because it's a chore to do. I guess that's where that naming comes from, Mike. But, have you have you done any of that in your commit messages?
[00:37:59] Mike Thomas:
I haven't. We have some folks on my team who are are just fantastic developers who I have noticed recently do that, very much so in in all of their commits and are very consistent about it and it's, sort of a practice that I'm still maybe getting used to reading and and trying to decide whether that is something that we should try to adopt globally across the team, or not. You know, I think the idea of of creating issues and branches that reference those specific issues and, you know, obviously, your commit messages are are on that particular branch sort of lets me know exactly what is being accomplished here with maybe up without perhaps needing, all the way down to sort of the commit message level of granularity, letting me know sort of what's being worked on.
But I I think on some particular projects, especially, maybe where it's not as clear cut of an issue branching workflow and maybe we're we're making commits to a particular branch that are across a wide variety of, of types and use cases, you know, both development work, bug fixes, chores, things like that. I think that that might be possibly a great idea. So, it is something that I have have seen. I'm just not sure if I am all in on it yet, but I don't see any drawbacks to it.
[00:39:22] Eric Nantz:
Yeah. I've I've been seeing it enough where it's like I'm gonna start paying attention to it. And maybe for my next project, I'll give it a shot. But like anything I get, it's not just the the the mechanisms of doing it. It's the discipline to keep doing it. And, again, if nothing else to take away from this, be kind to future you, be kind to future collaborators, Small fit for purpose commit messages will help you. Even if it takes a while to get used to, you'll thank yourself later. And, yeah, that goes with testing as well. Don't ask me why I think testing is a good thing because I've I've been bit by that too. I'll be a nut with hardware failures.
[00:40:01] Mike Thomas:
When AI does finally get good enough, I will try to create a Mael hologramrubber duck on my desk that can just yell at me when I'm I'm doing the the wrong software development practice because I need this advice constantly and I'm very grateful to all these blog posts that she puts together to to remind me to, stay the course and continue to incorporate those best practices.
[00:40:28] Eric Nantz:
Unlike some other things in AI, that is one that I would welcome to have next to me monitoring me through many points in my dev journey.
[00:40:36] Mike Thomas:
Me too.
[00:40:53] Eric Nantz:
I'm rounding out our highlights today, at the risk of dating myself with a reference here. I feel the need for something, Mike. You know what I feel the need of? The need for speed because it doesn't just apply to one aspect of data processing. It also applies to the way we consume data coming from these robust APIs and combining that with the very vast evolving ecosystem of geospatial data and performance. Our next highlight has the intersection of all these and definitely made me do a few double takes in terms of the metrics that we're about to talk about here. In particular, we're talking about this post that comes from Josiah Perry who has been a long time member of the r community, and his tagline lately is helping r be built and used better in production.
And his blog post here is his journey on making what he calls a ridiculously fast API client in r. And his day job is working for a company called called Esris, who is specializing in putting on these certain services to query geospatial data from many different development frameworks. I believe they have some host of services as well. Well, as I'm guessing as part of his daytime responsibilities, Josiah has released a new r package called arc just geocode, all one word, the big name here, which is an r binding and our interface to what they call the ArcGIS world decoder service.
And he says that this looks like an official package from his organization, Esri, in this space. And in his knowledge, up to this point, he's got some metrics to prove it. He claims that this is the fastest geocoding library available in the entire our ecosystem. In fact, he's claims that our just geocode is about 17 times faster when you do what's called a single address geocoding and almost 40 times faster when doing a reverse geocoding lookup as compared to other packages in the community already in this space. So let's dive into this a bit more.
His first reason for why this is important is that some I took for granted until a recent project, I talked about the onset with some of this podcast metadata JSON data is that parsing JSON data is not always fast, my friend. Not always. Many of us are using JSON Lite, the, you know, almost tried and true package offered by your own ooms for, consuming and writing JSON data in r. And it's it's it's been a huge help to me. Don't get me wrong. But it does have some performance issues, especially when dealing with long text strings in your JSON data and then bringing that conversion back to an r object and the other way around.
Well, guess what? Another language that starts of r comes at a rescue in in Josiah's initiative because there is a rust crate, that's kind of their term for packages, called SERDAY or SERD, I'm not sure if I'm saying it right, that handles both the serialization and deserialization of structures and rust. And guess what? It is very tailor made to JSON data too. It just expects you at the onset to help specify for your given JSON type data you want inside your your session, the specific attributes of each variable or each field. So in his example, he's got an address structure, if you call it, with all the different fields that would come out of this JSON data.
And most of them, big surprise, are strings, but it'll give you the ability and rust to really determine what's supposed to be a string, what's supposed to be an integer, different types of integers. You can go, you know, really specific on all these needs. Now that's great and all, but how does that help with r? Well, there is the package called extender, which is kinda like the RCPP, if you will, of Rust to r. We'll let you tap into a Rust crate and bring that into r and be able to go back and forth with our functions to basically call out to these lower level Rust parts of the paradigm. So this, Serde JSON crate is a massive speed improvement in general for importing JSON data, serializing JSON data over the community counterparts as he attests to in this post.
But that's not the only part. The other part is a feature that I should have known about in my research in HDR 2, but it just went over my head until this post, is that we often use HDR, HDR 2, and this is the regeneration of that, if you will, by Hadley Wickham to help in r perform these, you know, requests to API services. I get request, post request, and whatnot. And, usually, I do these requests kind of 1 at a time, if you will. Like, there's a get request. I'm gonna do that with specific set of config parameters, bring it back down and whatnot.
Well, how in the world did I not know about this function, Mike? Rec perform parallel,
[00:46:29] Mike Thomas:
which lets you do it in more than one time. Oh my gosh. Where have I been, Mike? Did you know about this? Neither did I, Eric. I had no idea that this was part of the h t t r two package now, that we have the ability to send, I guess, paralyzed request to an API pretty easily and maybe point that function towards a connection pool or a few different nodes, few different workers, to be handling requests concurrently. This makes me think of, I don't know, potential integration with the crew package or something like that. Perhaps this is something that you could do on your your own machine and and leverage, you know, the the ability to parallelize your own machine and and send out a few different requests, at the same time which is is pretty incredible.
And there's this Twitter thread that Josiah puts, earlier on in the blog post where he's, you know, he's he's showing off the fact that he was able to geocode, 2.6 1,000 addresses in in 3 and a half seconds. And and somebody asked, in as a reply to that particular screenshot that he put up, they said, isn't geocoding always bottlenecks by the server? And, that is true. But I guess when you have multiple servers to span the job across and we have this beautiful function request perform parallel that I imagine brings it all back together at the end.
That's that's a fantastic utility to be able to, you know, speed up, significantly and and this is something that I've dealt with in the past as well, geocoding. It takes time because you're typically going address by address and, you know, a lot of projects you'll you'll want to be geocoding your entire data frame which could get, you know, could get particularly long you know thousands tens of thousands hundreds of thousands of observations that you need to geocode so it's really interesting to me that we have the ability, you know, not only to leverage the speed of Rust, for this serializing and deserializing of JSON objects which is time intensive, but also, being able to just break the job out into across a few different, nodes here which is is pretty incredible, something that I didn't know about. Obviously, Josiah says that you need to be a little bit careful when you are doing anything like this especially when you're sending sort of paralyzed paralyzed requests at a different service that you don't perform, an accidental denial of service attack, you know, which is where you you make way too many requests all at once to the service and bring that down. So you don't wanna be the person that does that. So so certainly be be careful and perhaps, you know, use a small number of workers.
If you're just geocoding a couple thousand addresses, you don't need to spin up a few hundred workers or something like that to be able to do that just just spin up a couple and and maybe wait those extra few seconds that it's going to take, to be patient between, you know, spinning up a few workers and and many many workers. But it's really interesting because you will get, you know, these this great sort of orders of magnitude returns in performance, when you do add compute to the problem here as well as, you know, leveraging Rust for that that quick deserialization, of of JSON data. One thing that I will also shout out just because I was curious about this and, you know, we're finding all of these new, faster programming, software utilities out there when it comes to to data.
And there is a DuckDb extension as well for handling JSON data and reading JSON data and so I would be interested to see how that compares to what Rust can do for parsing JSON data as well.
[00:50:16] Eric Nantz:
But both very fast, I'm sure. Yeah. They are. I'm experimenting that a little bit too actually in my DuckDV adventures and I'll definitely come back with my findings as I get that more polish. I'll be at the hardware catastrophe, put a stop on that for a bit. But, nonetheless, I'm really intrigued by the concepts that, Josiah, parts in this post here. And then at the end, he recommends additional packages in the community that if you're still not quite ready for the plunge to Rust for some of these efforts, if you're not ready to build, like, an internal JSON parser that depends on Rust, There are some additional JSON related packages in the r community that definitely take a look at. He recommends the RCPP SIMD JSON package as a great way for parsing data as well as the y y JSON package that comes from the affectionately known cool but useless on the our community. He's got a great package called y y JSON and also JSONify, which I don't have as much experience with. But you might wanna take a look at each of those too and see it for your parsing needs or writing serialization needs. If that just gets you good enough without while being able to stay in the confines of of R directly.
But, nonetheless, this is great learning for me personally as I'm starting to deal with JSON data more and more in my open source work as well as my internal day job stuff where we just built an API binding package. But we're running this in the day to day use with, patient level data set where there's, like, multiple visits, multiple, obviously, patients in a treatment group, and it's basically doing these get requests to this custom service 1 at a time for each of these calls. My goodness. I could do the rec perform parallel and probably speed that up a bit. So I'm gonna have to take a look at this and hopefully not make my IT admins angry when I start to paralyze this.
[00:52:14] Mike Thomas:
Definitely do it on a, development cluster to start. That would be my recommendation.
[00:52:19] Eric Nantz:
Yes. Because, yeah. That that was another, story time from years ago when when I, was too greedy with multi cores, and I took down an entire HPC cluster. Don't be that person, everybody. Just don't be that person. I remember that story. Yes. Who lives in infamy. But, what lives in good ways, of course, is the rest of the our weekly issue itself. Tony's done a terrific job as always he does with the rest of the issue. We got so much we could talk about, but we're gonna have to wrap up here with our additional fines over this issue. And, Mike knows and many of you know I am a retro gamer at heart, not just with retro games, but also I have fond memories of going to the local arcade and putting some quarters on those awesome pinball machines that waste a lot of hours on that. Well, there is a fun post that combines things like, geospatial data, API calls, and some handy visualizations from Rasmus Bath. He calls this the public pinball machines per capita looking at where pinball machines are most distributed around the world.
And and as post surprise, surprise, the United States is in the lead with this, but Europe is not far behind in some of their visualizations. But his post goes into how he attained this data, loading the packages. And guess what? It's coming from an API just like everything else. He's got some, you know, really elegant code to do this. Really modern code here. They was using HTR 2 as well and some great handy visualizations built in ggplot for the distribution of these, pinball locations and some word clouds too. So really, really fun stuff here. And, yeah, it makes me get the itch to get some quarters out and find that retro arcade to, you know, knock out some pinball action. So that was fun. But, Mike, what did you find? Very cool, Eric. I found an oldie but a goodie. I think at the the recent,
[00:54:21] Mike Thomas:
our conference that's held in New York by that under Lander Analytics hosts, there was a panel discussion about your favorite R package. And I believe it was, who's the author of the data science Venn diagram there? Drew Conway. He was being asked what his favorite R package was and and I think it was one, it was called iGraph and I think it's one that's been around for a long long time, for doing, I believe, network analysis type stuff in, r. And I saw on the highlights this week that r igraph has crossed the 2.0 threshold.
So it's it sounds like, you know, similar to data dot table that this is another package that has had quite a life to it, continues to be very very well maintained, and it's it's just awesome to see a package like that be able to have the longevity it has.
[00:55:13] Eric Nantz:
Yeah. IGraff, I have tremendous respect for. It is the engine behind many, and I do mean many, of the r packages that provide some kind of network visualization or processing. My exposure to this has been using some custom eye graph bindings inside a widget called Viz Network, which I have a kind of a love hate relationship with, but I've done enough customization to wrangle it to my particular needs. But, yeah, iGRAS been around a long time, and it is prevalent in additional languages as well. But, yeah, huge congrats to that team for the 2 point o release. And I know, yeah, my whole biograph stays around for a long time because it is a fundamental pillar in these, network visualizations. So awesome
[00:56:01] Mike Thomas:
awesome call out there. I grabbed 0.1 released in 2006. Even older than the data that table.
[00:56:08] Eric Nantz:
My goodness. Yeah. As if I didn't feel old enough in this post. Good grief. What are you what are you doing to me, man? I I I need to get a youth injection or something. But what makes me feel youthful is just seeing what's happening in this community. Again, really great developments happening. Really great showcases of data science, you know, providing good to everybody involved. So where can you see this all? Where we've been talking about here, so many of our great wings are available at rw.org. Many additional findings here, many additional developments of packages.
We need to touch on all the newer packages out there. There's so much happening in these spaces, but we invite you to bookmark that site if you haven't already to check it out on a weekly basis. And also, we love hearing from you in the community. There are many ways to get in touch with us. You can send us a contact or message on our contact page, which is in the episode show notes. So, again, keep those comments coming. We love to hear from you. You can also, in the modern podcast app, such as PowVerse, Fountain, Cast O Matic, Curio Castor, there's a whole bunch out there. You can send us a fun little boost along the way if you want to send us a message without any middle thing in between. And no harbor failures on that one either.
But and the other way you can contact us is on social media as well. I am mostly on Mastodon these days with at our podcast and podcast index on social. I am also on LinkedIn. Just search for my name there. You'll find me there and sporadically on the weapon x thing with FDR cast and a special little shot. I didn't get to it in my stories time. But I had the great pleasure of having a, little dinner with, the author of GT, Rich Yone, who was in town for a local conference. So great fun talking with him, all things are, and someone he's up to. So, Rich, if you're listening, thanks for coming into town even for a brief couple of days. A lot of fun learning from you. But, Mike, we're gonna listen to get a hold of you. That is awesome. I am so excited for POSIT conferences here to be able to see some see some community faces. But, folks, until then, can get a hold of me on mastodon@mike_thomasat
[00:58:20] Mike Thomas:
fostodon.org or on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k, you can see what I'm up
[00:58:28] Eric Nantz:
to. Yes. And, hopefully, I don't see any messages about any failures in your infrastructure. Let's call it that. Let's keep keep our fingers crossed. But, yeah, just don't do what I did. That's the best advice for today. But in any event, we thank you so much for joining us wherever you are and wherever you are in your our journey. We hope that we're a little bit of a help along the way. And one of the best ways also to help us out is just share the word. You know? If you got value out of this podcast, we'd love for you to share it around, tell your friends, and always great to expand our audience for those that are getting started with our we think our weekly is one of the best resources for anybody in this community. Am I biased? Absolutely. Yes. But, hey, I speak I speak the truth here, I think, in any event. We're gonna close-up shop here, and we'll be back with another edition of our weekly highlights next week.


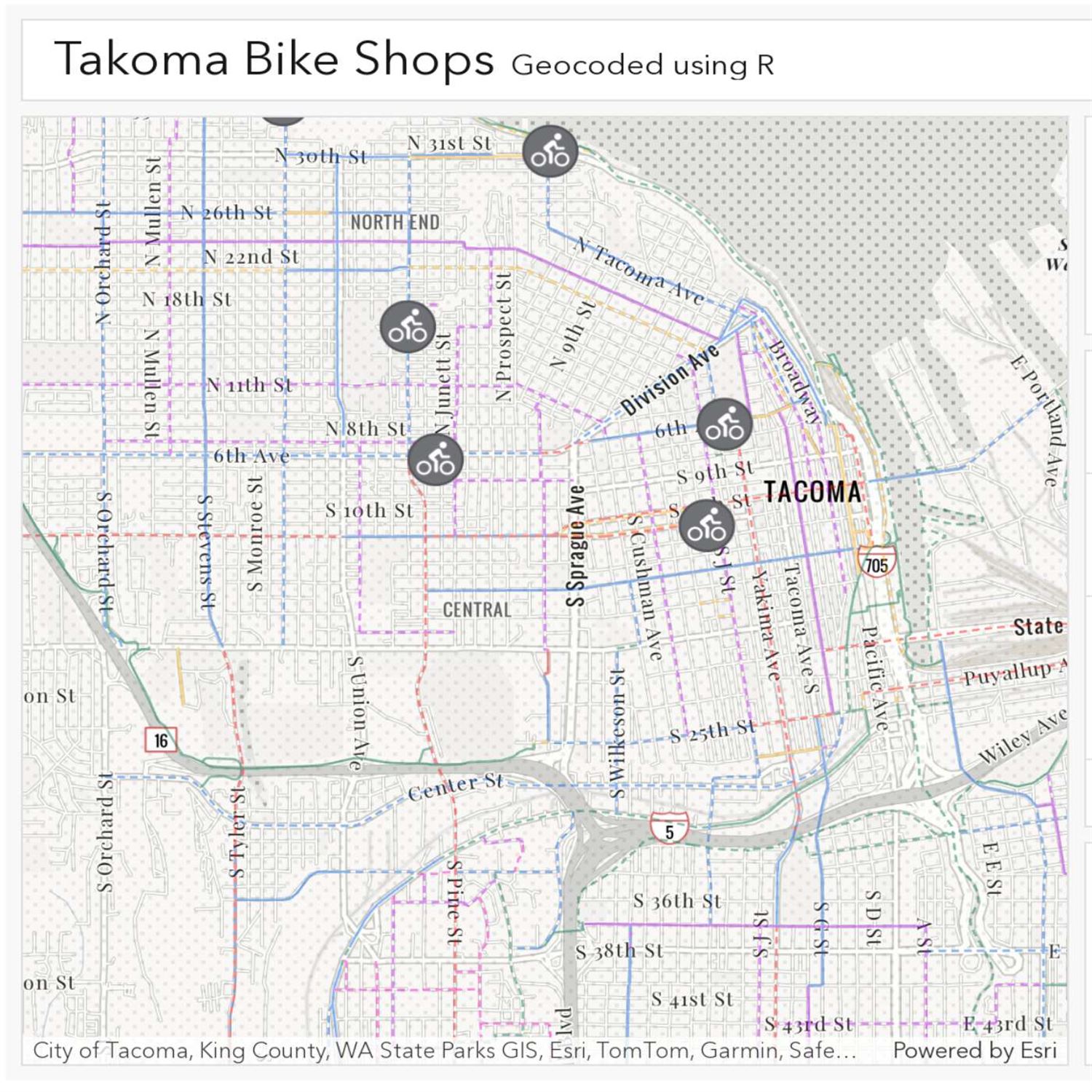
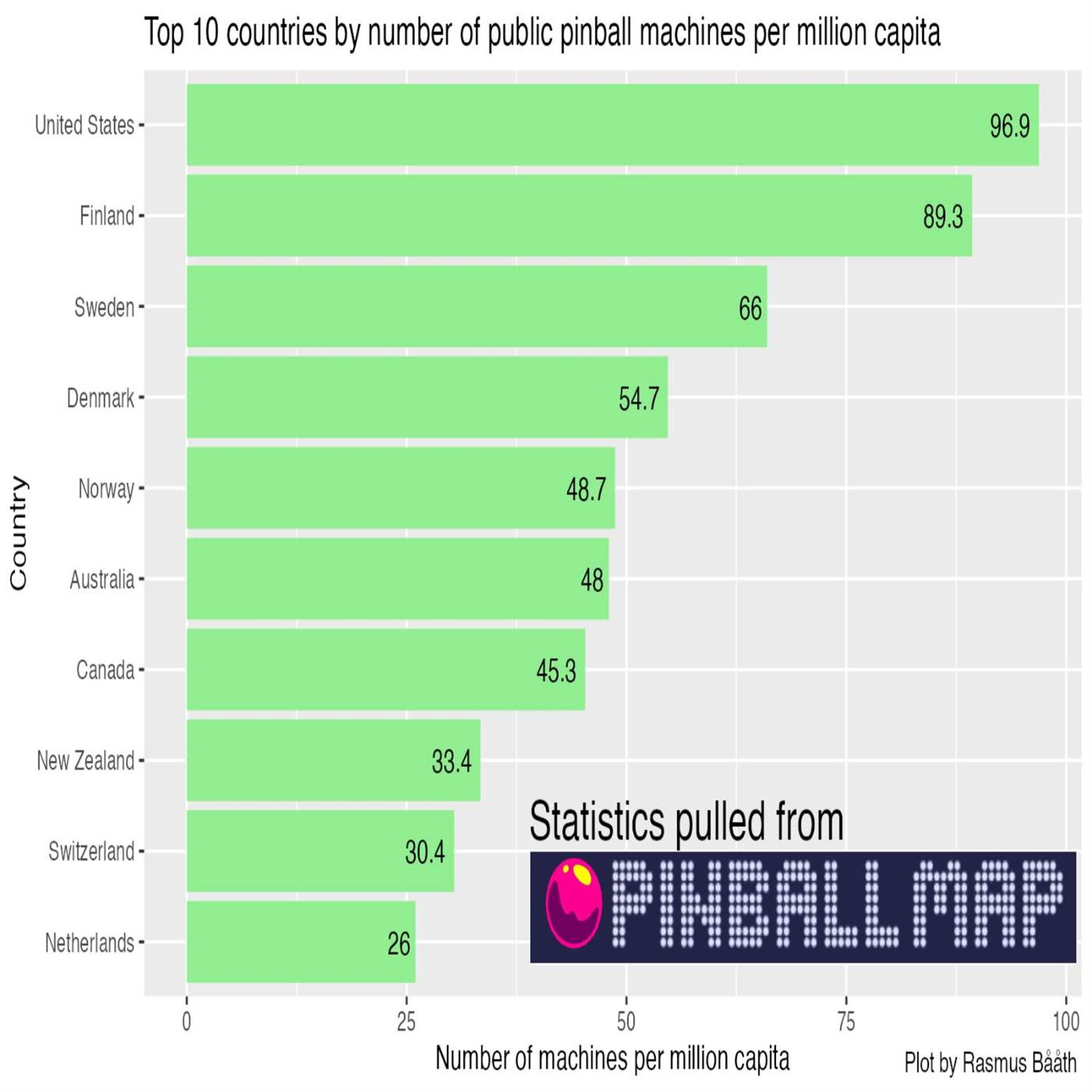
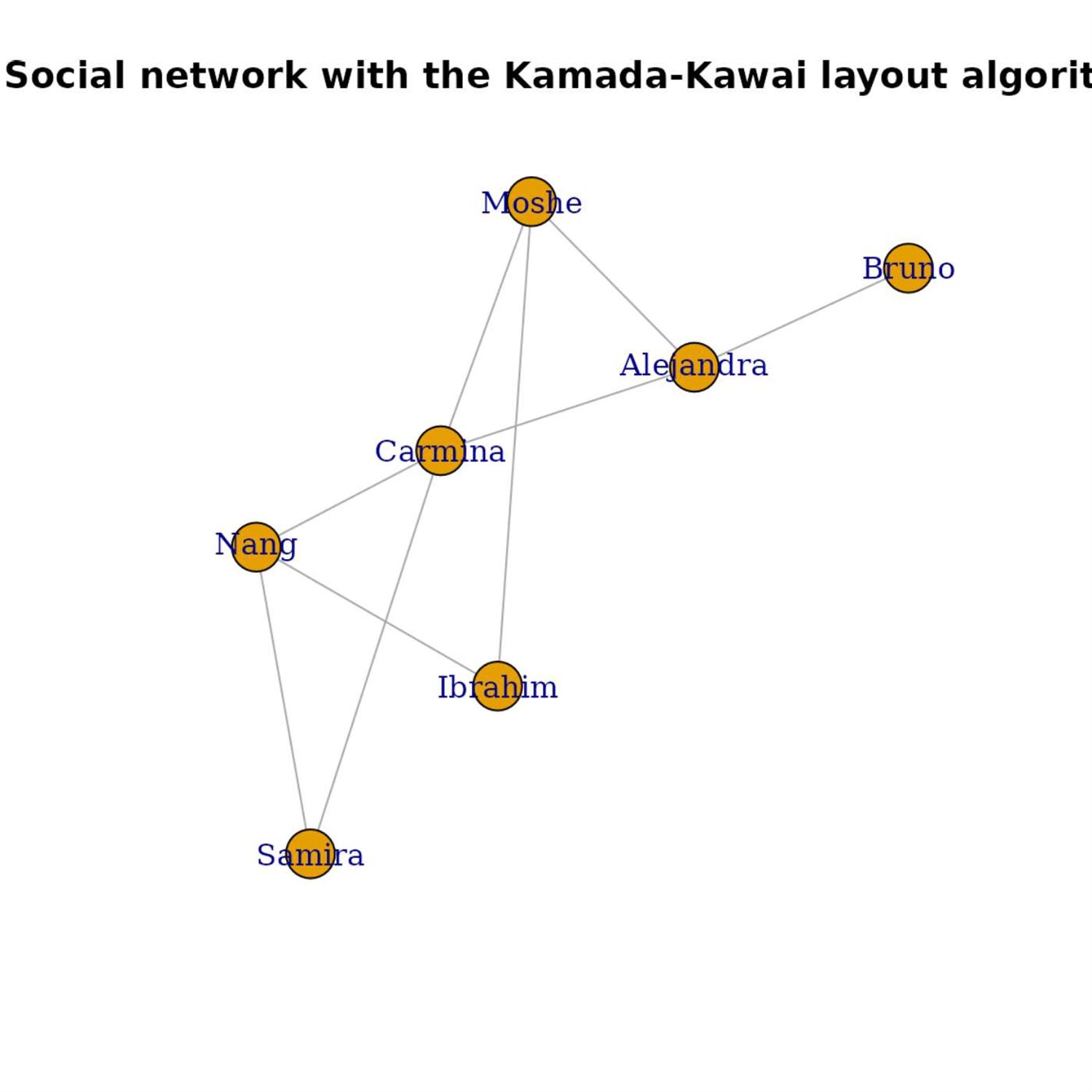
Episode wrapup
