The recent patches in R that pave the way for a future object-oriented-programming framework to accompany S3 and S4, a treasure-trove of open spatial data ready for your mapping visualization adventures, and a collection of tips for the next time you refactor your testing scripts.
Episode Links
Episode Links
- This week's curator: Jon Carroll - @jonocarroll@fosstodon.org (Mastodon) & @carroll_jono (X/Twitter)
- Generalizing Support for Functional OOP in R
- Getting and visualizing Overture Maps buildings data in R
- What I edit when refactoring a test file
- Entire issue available at rweekly.org/2024-W22
- Overture Maps https://overturemaps.org
- Shiny Developer Series Episode 30 - The Connecticut COVID-19 Test Spotter App (Part 1) https://shinydevseries.com/interview/ep030/
- Introduction to vvcanvas https://vusaverse.github.io/posts/vvcanvas.html
- How to Split a Number into Digits in R Using gsub() and strsplit() https://www.spsanderson.com/steveondata/posts/2024-05-22/
- Get a Free New Logo for Your R Package in Our Hex Design Contest - https://www.appsilon.com/post/hex-contest
- op3r - R client to the Open Podcast Prefix Project https://rpodcast.github.io/op3r/
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @rpodcast@podcastindex.social (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mikethomas@fosstodon.org (Mastodon) and @mikeketchbrook (X/Twitter)
- Liquid Puzzles - Baba Is You - Gaspode - https://ocremix.org/remix/OCR04582
- Bar Hopping - Streets of Rage 2 - Jaxx - https://ocremix.org/remix/OCR00437
[00:00:03]
Eric Nantz:
Hello, friends. We're back with episode 166 of the R Weekly highlights podcast. If you're new to the show, this is where we talk about the latest happenings at our weekly every single weeki highlights podcast. If you're new to the show, this is where we talk about the latest happenings at our weekly every single week with, take on the latest highlights and other other great finds that are in the issue. My name is Eric Nantz, and I usually say every week as we usually do it. But, the universe kinda gave us a sign last week that maybe it was time for us to take a little week off. So I think I think we're better for it. But in any event, we are back this week, but I'm never alone on this. I am joined by my awesome cohost, Mike Thomas. Mike, how are you doing today?
[00:00:38] Mike Thomas:
I'm doing well, Eric. Yep. We did, record a great or we did, I shouldn't say record. We have a great episode last week. We just we just missed, the record in case you can't tell. But this week, we have pushed the button, so let's hope that it makes it out there to the universe.
[00:00:56] Eric Nantz:
Yes. And, as Mike can attest to, when he and I connected this morning, this was the very first thing yours truly did. So sometimes, yeah, the universe says may have gotten too comfortable before. So, you
[00:01:10] Mike Thomas:
know, the the bots can't automate everything. Mike, AI can't automate all this either, unfortunately. So Nope. That's right. Just add it to the collection of lost episodes out there. Highly Yeah. Valuable.
[00:01:20] Eric Nantz:
Luckily, it's still single digits, and we hope to keep it that way.
[00:01:24] Mike Thomas:
That's right.
[00:01:26] Eric Nantz:
But, you know, it's not lost. We got another fantastic issue to talk about today, and our curator this week was our another longtime member of the rweekly team, Jonathan Carroll. And as always, yeah, tremendous help from our fellow rweekly team members and contributors like all of you around the world with your poll request and other suggestions. And it's fun when you can lead off with, you might say, straight from the source, if you will, because we have a blog post straight from the r development blog itself on some of the latest patches and enhancements that have been made into base r to support a new frontier of object oriented programming systems.
And if you're coming into base r, you may have noticed that there are 2 built in object oriented programming systems right off the bat with no additional packages needed. These are called s 3 and s 4. They both accomplish similar things, albeit they go about it a bit differently. But you will find that, for instance, a lot of the tidyverse packages have been built upon s 3, whereas other packages in your ecosystem, especially those around the bioconductor side of things, have links to s 4. And we've covered in previous episodes of benefits and trade offs of each of those. But ever since about a year and a half ago, there has been a new effort, a joint effort, I should say, between the Arcore team as well as developers of, say, the tidyverse and other community related packages on a new object oriented programming system that is now called s 7, which right now is available as a standalone package that you can import into r.
But with the advent of s 7, it has provided the R Core team a time to reflect, if you will, on how to maybe help out packages like s 7 in the future become part of the base r installation. And they've identified a few key gaps, if you will, of ways to make this journey of incorporating into base r a bit easier. And this blog post in particular talks about a set of 4 different patches that have been landed ever since our version 4.3.0 that are going to pave the way for an easier onramp of s 7 and perhaps other packages in the future to take advantage of some of these principles that have been built into R for quite some time, but to help give a more friendly interface around these.
We'll do a quick recap of each of these 4, but we're gonna, you know, buckle up a little bit. We're gonna get pretty technical here. The first one, probably the most technical here, is the concept of how dispatch works with respect to different object types and different operators. If you don't know what dispatch means in this context, it is really the concept ascending a generic, which is another word for function that's supposed to have, like, one name such as plot or summary, but take different actions depending on the type of object being fed into it. And so it'll say, hey. If I wanna do a summary of a data frame, it's gonna do, like, a quick five number summary of each, you know, variable in your data frame versus for a model object. It's gonna give you those model fit convergence statistics, those likelihood statistics, and other information.
And typically for s 3, a generic will use the first argument that is passed into that that that that method call to help determine where it dispatches. S 4 kinda takes a more general approach. It could be any number of arguments in that call that help determine which method gets dispatched to. S 7 is somewhere in between. It has this intricate kinda double dispatch system And even I'm not quite sure how that part works, but, luckily, for the rest Even I'm not quite sure how that part works, but, luckily, for the rest of this explanation, we really need to know that because now since version 4.3, they are now helping the situation where it's not always just like a summary or, you know, other function like that. A lot of the operator functions in r, such as like the plus or the multiplication or many of these others, actually are built on 2 arguments. Right? You don't see it, but the left hand and the right hand side of these operators are like the 2 arguments to the actual function itself.
Well, before this patch, it would always if there was ever a mismatch in the types of arguments that are in these kinda operator type methods, r would warn you, hey. These aren't the same type, and it wouldn't dispatch anything that was based on those. Now since 4 dot 3, there's a new function built in the base r called choose ops method which is gonna let an object type declare that they are in fact based on a combination of different methods for that argument pair, not just one method. Where this is really gonna come into play is the situation where you have a pretty complex method that wants to do, like, these operator methods that is meant to do a unique thing, but be able to take an account that these argument types going in could be more than one type.
And they use an example from reticulate in this piece, which I think is quite interesting here. But for those aren't aware, Reticulate is the RPAC is a interfaces with Python under the hood, and, hence, it's going to find a way for your r code to go to the appropriate Python method. But especially in the space of machine learning and other methods like that, sometimes these operators, they might wanna build a custom, you know, method on. They're gonna have different things inside each of the left and right side, if you will. So in the example they have in the post, it's based on TensorFlow where you might have an interesting object that's based on a tensor, tensor itself, which is a Python object, but you might wanna add to that, like, a simple array in Python or whatever.
Whereas in for for r4.3, it wouldn't know what to do because these are 2 different object types. But now with this choose ops method, reticulate can say, okay. For this unique type of combination of an array and a tensor object, dispatch to this particular method. Now you may never really encounter this in your day to day development, but as a package author dealing with some more novel and more intricate class systems, this is going to be a big win for many people. So it's going to pave the way for more flexibility in these situations of building your own method on these, what you may call classical operator type functions.
And speaking of those classical operator type functions, there has been one that's kinda had a unique, you might say, history and where it's invoked. And that, in particular, is the multiplication surrounded by percent signs. If you've done any, like, math in r or maybe in your graduate school or over class training, you probably use this when you had to multiply matrices together if you're learning the ropes of linear algebra and the whatnot. Prior to our version 4.3, this only worked with either s 4 objects or base r objects. Well, guess what? Now that in 4.3, there is a way to have now a new generic category called matrix ops where it's gonna have this built in operator as one of its first citizens of it, so to speak.
But package authors and developers of new object class systems could help put in new methods into this. And they say in the future, within base r, they're going to fold in the cross prod and the t cross prod, functions into this family. So they do admit this is meant for backward compatibility, but it's also intending this to let other packages have to do with operations that are more unique in this situation such as s 7 in the future, be able to do the appropriate classification of these methods. And, yeah, we're we're not quite done yet. We got 2 more to go. One of these is also filling a need that can be inconvenient or maybe it was a bit difficult in the past of trying to figure out for an object type what class it inherits from.
There is a function in base r called inherits where you put in as the first argument the object itself, and the second argument of the name of the class that is meant to check if it inherits from. Well, a lot of these class names that for an s three standpoint were kind of built in as an attribute and not really meant for human consumption. It was not meant to be very syntactically, you know, very easy to understand, apparently. Well, now in the inherits function ever since version 4 dot 3, you can now have arbitrary objects as that second argument that you're gonna use the check for inheritance of that first argument, which means you don't have to memorize or go in source code to figure out what is that name of that s 3 object type that you're or class type that you're checking from.
You can now feed in a logical name of this or an object itself. So the example they have in s 7 where they define a class called class x, they give an object called class x of that new class, and then you can now use that as a second argument instead of a string trying to guess what that class type is. So that's also meant for use of s 7 to get into base r eventually, but there's no reason other packages can't inherit that same idea. Again, similar to the Python side of it where you might have in your reticulate package, build down reticulate, maybe a new class name that can be a lot easier to type for the user.
Last but certainly not least, if you're familiar with s 4, if you ever explore that, the way to get into what we call slots of these objects in your creative s 4 has been the at sign. It's kind of been like the dollar sign to me when you would use that in, like, your data frame, dollar sign, name a variable. In s 4, it's been quite similar. You would have your object that was built in s 4, use the at sign, and then you would start typing in, like, the name of either the method or the slot that you want to get more information on. Well, this never worked for anything besides s 4.
Well, now, ever since 4.3, now that can be used with s 3 dispatching as well. I still don't quite know in my day to day when I would would actually use this, but they do give justification for this by saying that s 7 is taking bits of s 4, albeit these more formal definitions of slots and other formals that are going into these class types. And now, if you have that muscle memory of using s4 and this at sign to get into these different slots, you're going to be able to use this of s 3 and s 7 now as well. Again, not sure when I'll use that day to day, but, again, many of these changes are paving the way for an eventual future state of s 7 becoming part of the base r installation.
So I think it's one of those things we're gonna see the fruits of this labor more down the road. But if you ever had questions on what our our core project is doing to get this state ready. This blog post is definitely for you, especially if you want a primer on how these are gonna make your life at developing a new object oriented programming system or building a a PONCE S3 or the new S7.
[00:14:16] Mike Thomas:
These are definitely, features that you wanna keep your eye on as you're developing your source code for that. Yeah, Eric. This is this is pretty exciting stuff and it's interesting to me to see how Posit and the RCCOR team are coming together on this initiative as well as some others, you know. It's really cool to have that, collaboration out there between, you know, the brightest minds in the some of the brightest minds in the R ecosystem. And if I understand it correctly, I think the the road map here is that this new framework is currently out there as an R package called s7 for developers to, today if you want to, download, install, and kick the tires on it for a while.
And then once the team feels that the package is stable across a wide variety of use cases, I believe the idea is to bring s 7 into base r. And I don't know if there's any specific timeline on that that we saw in the blog post. Not not yet. It looks like it's still got some work to do. Yeah. So I I would imagine that it's gonna be a function of how much use this s seven r package gets, and how many folks out there can download it and and try it out, and how many edge cases, they can find before they they finally feel that, s 7 is is stable enough to bring into base r. But, this is all, you know, I think extremely exciting stuff for those who are trying to, you know, sort of push the boundaries of what R can do. I I think, a lot of the power behind, this object oriented programming approaches is actually in making sort of the the end user's life easier and making the UX for, you know, our users that maybe don't necessarily need to know or care about, you know, methods, classes, object oriented programming, make, you know, their day to day jobs easier. Just like you said, Eric, we have these these generic functions, you know, summary. You can call that against a a data frame and get your your quantiles for each column, or you can call it against the model object. And each, you know, for for most authors of of our packages that contain predictive modeling frameworks, they all typically implement their own sort of summary generic or or print generic as well against the model objects that those packages offer. And the ability to sort of do that and custom tailor what the end user is going to see on screen is is really cool. It's really powerful. And for those of us in our early in our our journey or even, you know, intermediate in our our journey, the fact that we just sort of get that nice functionality for free, is is fantastic. And it it makes everybody's life easier. I think it contributes to some of the reasons why R can be a friendlier language for some folks to pick up. So, you know, the fact that we're getting some additional, you know, extension functionality, you know, beyond s 3, what s 3 can do in this new s seven implementation, you know, particularly with with sort of that second argument idea, I think is going to go a long way to continuing, to help, you know, those hardcore r developers make, everybody everybody else's life a lot easier. So we're very appreciative of that.
[00:17:27] Eric Nantz:
Yep. Exactly. And I'll admit my journey in OOP systems right now has been on a package, r 6, because I'm doing some shiny extensions as we speak. But it has been on my bucket list, so so to speak, to get into s 7. And our our good friend, John Harmon, has been doing some work of s 7 as well and some of his package development exploration. So it's it's on my to do list. But as you know, Mike, there's only so much time in the day.
[00:17:52] Mike Thomas:
I'm in the same boat, Eric. I have some grandiose ideas still sort of on the s3 object oriented side, but, we have this this credit scorecard package that leverages traditionally just a a GLM, a logistic regression model, but it's very possible to stick these scorecard models or wrap them around, other modeling types like XGBoost and something black box. But the methodology for for doing so, is is quite a bit different. So I'd have to to stand up a lot of different, I guess, object oriented approaches to ensuring that these generics that we've written, you know, fire correctly. So I have lots of ideas and plans as well, but it's only so much time as you said.
[00:18:46] Eric Nantz:
You know me, I love it when we have more open resources for both developers and users to kinda test their visualization muscle on, so to speak, and really generate some awesome insights. And our second highlight is highlighting just that. It comes from Kyle Walker who is a director of research for a winyan, if I'm pronouncing that right, as well as he has, apparently, his own consulting company for data science. And he highlights area that I did not know about until I read this post. So, again, I'm always learning when I read these. But, there is a project out there called the overture maps datasets initiative, which is a project not just from 1, not 2, but multiple big tech giants in the tech sector such as Microsoft, Amazon, and Meta, along with others to help produce both open and standardized geospatial datasets.
My goodness. Oh, this this looks really fun, and it's meant for developers to be able to use in the applications that they develop. Well, of course, nothing wrong of using this in r as well. Now how will we pull this off on the r side of things? Guess what? These datasets are written in what format, Mike?
[00:20:06] Mike Thomas:
My favorite format, Eric, parquet.
[00:20:13] Eric Nantz:
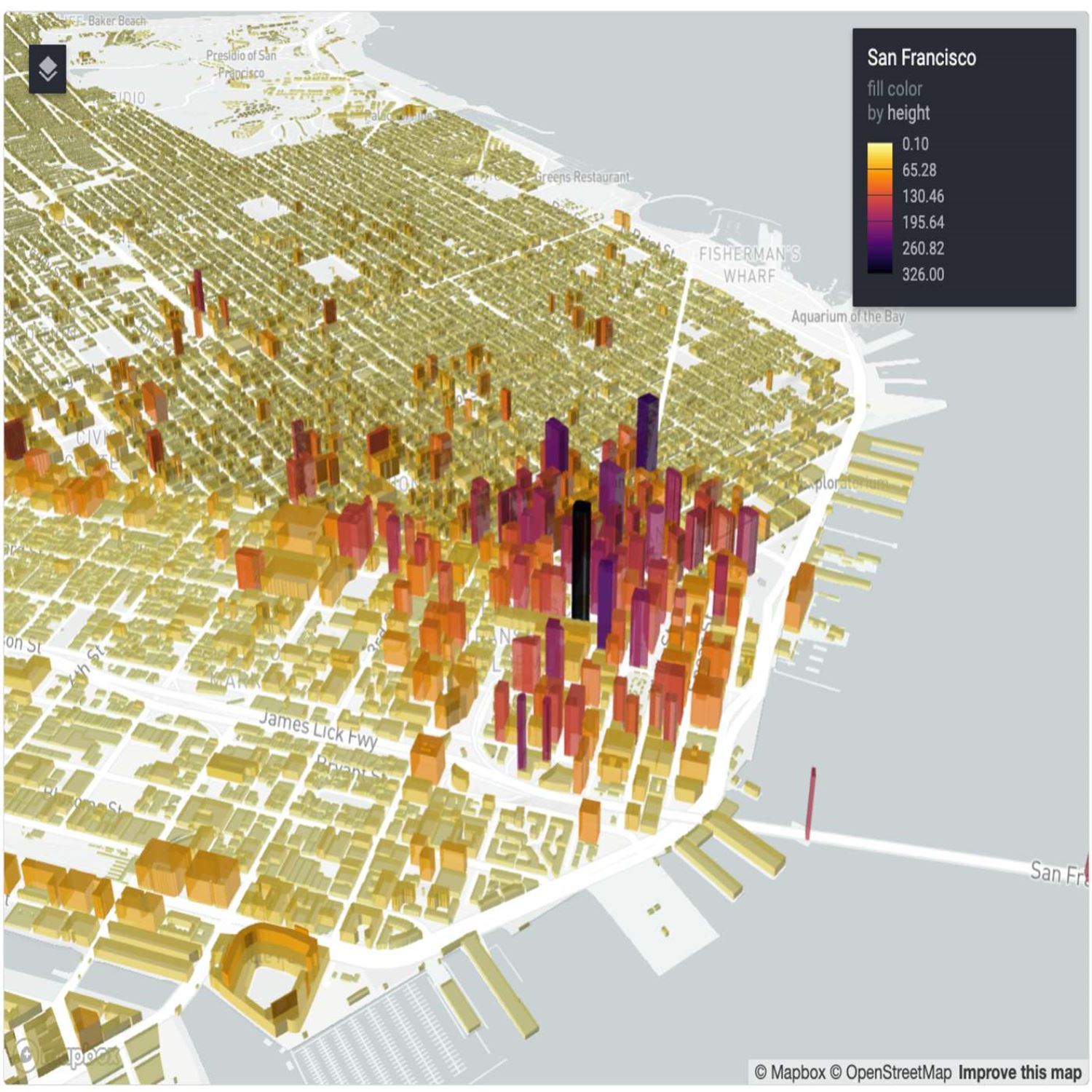
Exactly. We've been harping on parquet for many months now on this show, but these datasets have been shared as objects and s 3 storage on AWS for public consumption with parquet. And just how can you import these into r itself? Guess what? The arrow package is your friend here because the arrow package will be able to import not just these parquet files that are stored locally on your disk. They can read from remote locations as well, such as these s three locations and not just read from them. It's not like you're, you know, behind the scenes, like, downloading in some temp area and then somehow importing all this into your system. No. No. No. No. These are kept remote, and this is really important example that Kyle outlines here because he found a unique data set with respect to building coordinates or topologies, and this data set has, get this, over 2,350,000,000 That's a b. Building footprints around the world. Mike, have you ever had your hands on a data set this large?
[00:21:22] Mike Thomas:
How how big is the New York taxi dataset?
[00:21:25] Eric Nantz:
Probably not that big. I don't think it's that big. Yeah. I think that's in the millions, but, boy, we're talking about 1,000,000,000 here. So you can imagine if you put that in your system, yeah, it's gonna probably blow up and smoke fire or whatever in your laptop or PC of choice. So you don't want that in your home memory. Guess what? IRL comes compatible with dplyr functionality, so you can use this to query for just the parts of data you need. And in particular, in the example that Kyle walks through here, he has an example of filtering the coordinates based on San Francisco, I e the state of California where he was able to grab the actual coordinates, from, I believe, another package to get the coordinates, right, the bounding boxes.
And then once you have that well, of course, we're visual. Right? We wanna see what this looks like. The the package called rdeck, which is a wrapper on deck GL, gives you a way to have a 3 d based visualization of these buildings. And in the post, the code itself, really and really straightforward. Really not too much going on here other than setting your initial view and centering the coordinates, doing some zooming parameters, and then adding the layer, I. E, the Polygon layer for based on that data, the building topology from San Francisco and then being able to basically feed in variables for the various attributes, much like ggplot2 in a sense. And lo and behold, if you're looking at this in your modern podcast app, you'll see in the chapter image marker, you got a really nice looking topology layout of San Francisco that looks pretty darn cool if I dare say so myself.
And so Kyle was curious. It looks like the u United States portion of this data has a little more fleshed out, building data, so to speak. He thought, what's it look like in the rest of the world just to kind of test that, you know, hypothesis out? He did the same kind of code, but instead of going to the US, he went to Sydney, Australia to see what kind of topology he would see here. And you do see that there's only maybe looks like about 15 or 20 buildings that are represented here, which obviously we know Sydney is a big city. Right? So there's gotta be a lot more to it. But this just goes to show this iterative nature or might say the early stages of this initiative. So perhaps there will be others in the community that start contributing more data to the Australia side of things or other parts of the world. But in any event, you've got access to this really innovative set of data.
You do not have to blow up your hour session and import it in. Parquet is, again, we've been harping on this before. It's opening up a ton of possibilities for you as an R developer and R user to be able to do some really great insights without having side of side of things later on, this data set this set of data looks like a great source to draw upon. Yeah. Eric, I couldn't be more excited about this project. In the past, I've
[00:24:45] Mike Thomas:
leveraged typically the Google suite of APIs for geolocation types of of activities. Think if you remember my Connecticut, COVID 19 at home test spotter shiny app that I I shared on the shiny dev series, we use the Google Places API to allow users to search for particular places, in in the US and have, you know, that autocomplete that you're familiar with seeing, if you're ever been on Google Maps and ensure that the the particular place they selected is is a recognized location in Google's giant database. And it's a fantastic API, but there there can be some cost associated with that depending on your volume. And this new project, that's, as you mentioned called called Overture which is this collaboration between these powerhouses, Microsoft, Amazon, and Meta to open source these large geospatial datasets is is really exciting. And I I there talk about 5 different, particular geospatial datasets out there. One being administrative boundaries.
2, land and water features, building footprints and roof prints, and then points of interest which I think are are like that places dataset that I was talking about, places API. And then last is transportation rare layers, like roads and public transit ways. One other feature that I hadn't, seen before is this deck.gl, library which is a relatively new, I think, framework for visualizing these very large datasets. And as you can see in the blog post, the output of, the deck dot gl maps is is beautiful. They have great visuals there, very modern looking, really really cool. And that rdeck package is just this great wrapper for the API that, as you said, the code here is is quite minimal. It's pretty incredible. There's some data prep work that goes on to to grab counties and to filter down, the buildings within a particular bounding box coordinates that we we care about, using, you know, the dplyr and arrow combination as well as the the sf package.
And then there's this one call, a few lines. I think it's 1, 2 arguments really, to the rdeck package in order to sort of build that base map and then leverage this add polygon layer function on top of that to, really stick your polygons on top of there that are going to draw, the the different shapes on the map that you're looking for, all these different buildings and their their heights and the gradients and scales and things like that. And and that's about it. It's it's pretty incredible. It should feel pretty straightforward and and familiar to those who have done any geospatial analysis before. So the fact that we just continue to get these higher and higher performance tools for all of our data science work is super exciting.
A great blog post, great walk through. I used, you know, you you we've talked about this a 1000000 times on the the podcast before and my love for Parquet k as well as the arrow package. I recently used DuckDV for the first time last week finally. I had a 25,000,000 by 50 column SQL Server table that I wasn't about to to try to write summary queries against because I I tried to do that once and it it did not end well. Let's just put it that way. So I was able to to write that out to parquet using a a chunked approach, and the new I think, ADBC, that database connection for, for the Arrow framework and wrote that out to Parquet, and then I use DuckDV to query this this parquet file that ended up being, you know, I think around 1 gig for these 25,000,000 rows by 50 columns sequel server table, and the the queries that I was running with DuckDV were taking like less than a second.
It was it was insane. It was incredible. So I can't I can't sort of recommend these frameworks enough for, you know, high performance, data analysis. And this is a fantastic use case of bringing a few different tools together, in terms of some of the Tidyverse ecosystem, the Arrow project, some of these other data visualization libraries, and then this new deck dotgl library, which is incredibly exciting. And, like I said, sort of the outputs here are are really visually appealing and nice. So it's a fantastic blog post, to to have out there. So thanks to Kyle.
[00:29:07] Eric Nantz:
Yeah. Absolutely. In fact, I've even just thought of a a use case for this myself in a rather geeky project where I'm starting to interface more with some interesting podcast metadata, and some of it is the location where downloads are occurring from. You know? Maybe I could use this to map out the downloads of our weekly highlights on a nice little map, so to speak. So I'm, you know, cover me intrigued then, and I I still think parquet is becoming the new CSV in a lot of our data science circles, and this is just yet more more credence to that. So, yeah, really, really fun to learn about the innovations in this space as well. And last but certainly not least on our highlights section today, we, in this, quote unquote loss episode last week, we we had a great discussion on ways that have been explored to help automate some refactoring of tests.
Well, we're gonna make good on it because we have part 2 of that series here. We're gonna talk about the highlights here, and this comes to us from Al Salmon who, of course, was a former contributor here at rweekly and now is a research software engineer with rOpenSci and rhub and synchro as well. And this is part 2 of her quest to refactor test files in one of her packages. And, again, last in her her post last week, which, again, is on last week's our weekly issue, she had a fantastic, albeit quite in-depth system of using a combination of parsing our code and XML representation of code to find calls to certain expectation functions and be able to swap them on the fly by how having to do the infamous control f find and replace for all these hover instances. Well, we're we're getting a little bit more, human readable here, so to speak, in terms of automation versus, you know, some principles that I think on paper they make complete sense.
But, again, you got to put it into practice. Right? And, I already have one project where I put maybe half of these in practice, and I'm gonna go back and put the rest in practice. We'll kind of hit these 1 by 1 here, but a lot of these are gonna relate to not just test, but also your base r code as well for your package or other routine. Make variable names that actually make sense, and this also applies to your test suite as well because it may be tempting if you're, like, doing a similar expectation by just varying, like, 1 or 2 things, kinda reuse those variable names over and over again.
No. No. No. No. No. Don't do that. It'll make the bugging a lot worse, especially if most of those expectations pass except for one thing here and there. So having variable names that make make more sense to you when you read it, don't be afraid to make them verbose. I like long variable names if it helps my cognitive function. And so don't worry about, you know, trying to be with that. Again, you are probably the one that's gonna read this the most. So be nice to future you on this. And speaking of variable names, you, again, may be tempted to use the same ones across different tests if they're all doing the similar type thing.
You know, you might wanna change those up a little bit. So in her example here, she's got a function that has, like, 3 different modes of complexity, and she changes those inputs going into the expectations based on that mode, if you will. Easy, medium, and hard versus, like, x x x for all of them. So, again, tailor it to the way you as a developer can help move your debugging when these expectations are not passing. And then as you're developing these expectations, you may think about, oh, when I wrote this package, I had, like, all my objects created above, and then I put them, like, my processing functions below that or whatnot.
Maybe for testing, you don't wanna do that. Maybe you wanna put the the objects you're creating related to the expectation that it's testing with and put those groups together instead of, like, all your objects in one part and then all your expectations in another part. Again, some of this is subjective, but, again, when you're debugging things, it may be much more straightforward to have these logical groupings of the object and expectation with each other instead of, like, everything in the preamble of your test and then every expectations all below it. So, again, these are all nice enhancements, but she's not done there. She's got a lot more here, Mike, that I think you could definitely relate to as a as a developer as well.
[00:34:06] Mike Thomas:
Yeah. Unit testing is a a funny thing, Eric, because some of the sort of best practices that you might think of in terms of how we like to author our code, can sometimes go by the wayside or or not necessarily make as much sense within a unit testing framework. And, you know, her her last sort of section here that she talks about or as you were discussing before is maybe not, you know, create all those different objects and then run your sort of expectations, you know, against those different objects that you previously created, but keep everything sort of logically together. So if you're about to execute a test using, you know, expect, equal or expect greater than or something like that, you should have the object that you're using in that test or objects that you're using in that test as close to that as possible.
And and I think that that makes a lot of sense. You know, when I'm reading some source code of developers that I, you know, admire and and try to mimic, I think that that's something that I see, you know, quite often in their their unit tests within their test that folder is that everything is is sort of chunked up nicely into different sort of logical sections where they they have a per very particular thing that they are trying to test and, you know, they have that that very much segmented in one location. However, you know, sometimes you're trying not to recreate the wheel all the time as well and there may be opportunities maybe at the header of that file before you start executing any of your unit tests to create a particular particular object that you're going to actually pass and leverage in a lot of the different tests that you're running. So there's some trade offs here.
A lot to think about. I I again, I say this I feel like every time I'll author a blog post but I feel like these topics aren't something that's talked about very often. So it's it's really nice to have someone out there who is talking about, her opinions and best practices, you know, most of which I I sincerely relate to. But these are a lot of things that I've had to learn the hard way, sort of, by trial and error, over the years and not necessarily had a lot of content out there to follow. So very grateful for Mel for for putting this together. And and maybe the last, point that she puts out is is try to use a a bug summary and not just maybe the issue number that you're solving as your test name. You know, if you go back and take a look at a test, you know, where sort of your test that, first argument there is just the string that says, you know, bug number 666 is fixed as Mel uses for an example.
She certainly prefers that you you write that string to say something like, you know, my awesome function does not remove the ordering. You know, sort of, maybe providing the summary of that issue as opposed to just the issue number itself. So that when folks are going back to to understand it and look at the tests that have been written, It's very easy for them to be able to see exactly what's taking place in these tests, what has been solved, what maybe still is open and needs to test around that. And she recommends, you know, use that summary as that string, that first argument to your test that call, but but maybe you can have a comment within that that has a link, to the particular bug report or that git GitHub issue, so you have sort of the best of both worlds there. So a great great, blog post here again by Maelle. I really appreciate her covering a a topic that I think doesn't get enough attention, and I definitely learned a lot here. Yeah. Me as well. And I've been actually,
[00:37:48] Eric Nantz:
in the past couple weeks, I've been bolting on some really interesting unit tests for a shiny app I'm about to put in production. But guess what? As much as it may seem like a paradox, Mike, 90% of those tests have nothing to do with shiny. It's about the business logic, which again is a pattern that may not be as obvious as a Shiny developer. But guess what? Because the business logic is just based our code if your summaries or visualizations or over, you know, in this case, some Bayesian modeling. These are all things that we can take principles that Miles outlined here and as well as her previous posts on developing best practices. So I have her blog on one tab. I have the r packages tab on or open on another tab. The r packages book by Hadley Wickham and Jenny Brian. And so these have been greatly helpful. And, yes, there is some shiny test to match. I got the end there for what I call a more end to end user focused view of it.
But, boy, if I have confidence in the business logic and I organize these tests such that I know exactly where to go if something fails. And sure enough, I had some failures with a survival object outcome where I was like, wait. Why didn't it work for binomial and continuous? Why not for survival? Sure enough. I was doing a dumb thing in one of the inputs and the processing functions. But the expectation covered it, and I knew exactly where to go. So it does help future you. You've just gotta try it once. I promise.
[00:39:13] Mike Thomas:
I couldn't agree more, Eric. Please please please write unit test for your business logic. It's the most important place to have them.
[00:39:20] Eric Nantz:
Exactly. So I've got, members of of our developer team helping with some of those business logic. I gotta kinda help with the summary and visualization side of it. But in the end, we've got over 40 of these tests, and right now they're all passing. So yay for now. Hooray. You know you know what passes, though, as well. It passes the, the r curiosity test, if you will, is the rest of the rweekly issue because we got a lot of great content for you to continue your learning journey on with new packages, new blog posts, great new resources for you to dive into. So as usual, we'll take a couple of minutes to talk about our additional finds here.
Speaking of learning, this is definitely gonna be relatable to those who have children here in the US have started their summer breaks. Right? They're, they're not using their, their course web pages now to get homework and whatnot. But most of those schools here in the US build their learning systems on something called canvas. It's a learning management system. Mike, you're gonna know about this in a few years. Trust me on this. And most of their most of the teachers will use this to help bring out assignments or, you know, get in touch with their students, add resources, and whatnot.
Well, if you are a maybe teaching a, who knows, maybe a stat or math course, and you wanna use r in it, but you wanna help use r to help automate some of your management of these resources, well, there is a package for you. This package is called vv canvas. This is a package to automate tasks in the Canvas LMS, and this has been authored by Ewin Tomer. And this is actually part of what was new to me, a verse of package is called the Vusa verse, which is a collection of our packages tailored to student analytics with respect to teachers using these in their courses and and other systems.
So this package basically builds upon the Canvas API If you wanna use r to help automate certain tasks, like creating, you know, assignments or finding metadata of assignments and whatnot. Looks really interesting if you're using this system with respect to your teaching. And as usual, as I say to many people, if there's an idea, there's typically a package for that. Well, little did I know there will be a package for the campus learning management system. So that was a new one to me. So maybe if you're one of these teachers that are on your quote unquote summer break and you wanna supercharge your, learning pipeline for administering your course and you use R, maybe this is for you. I have no idea.
Unfortunately, as a parent, I can't leverage this API. They don't give me the keys for that. But, hey, if I was ever teaching, I would. I
[00:42:10] Mike Thomas:
have heard of Canvas before. You're right, Eric. I'm not quite there yet, but I am sure that sooner rather than later, if Canvas is is still around, I will be engrossed in it, once my daughter gets to gets to school. So very good to know. Very, very good highlight. I've got a couple for us. I will wanna shout out Stephen Paul Sanderson who has a bunch of little bite sized, posts which are are just fantastic little nuggets. One is called how to remove specific elements from a vector in r. He walks through, approaches using baser, d player, and, data dot table, I think. He has a a little, blog post how to split a, number into digits in r, which is fantastic. It's actually a use case that I had with with DuckDV, which has fantastic, function to be able to do so to split a a particular value by a delimiter into an array.
And then it has a second function for picking the element of the array that you want but that's just a a tangent, based upon some rabbit holes that I had to dive down recently. So I want to shout out, Steve Sanderson for these great bite sized posts. Then I also wanted to shout out Epsilon for this contest that they are having, to win a, I believe, professionally designed HEX logo for your r package. You have until May 31st to sign up for this. So you have a couple more days left. You have to provide some details about your r package, package, name, purpose, functionality, and some links and, briefly describe the design that you're looking for, design concept, any preferences that you have for the logo, and you could win a professionally designed hex logo for your r package. And if you've seen any of Absalon's, I think newly sort of rebranded or redone, hex logos, I'm thinking about the tapper package which is, I believe is that on the Shiny for Python side? That's their Yep. Rhino That's their kind of rhino like wrapper. Yes. For building modularized, Shiny for Python applications.
These HEX logos look super clean, super modern, really really cool. So if you did win this, I have no doubt that that the design that your R package would get for its hex logo would be be very fresh, and would be, you know, sort of way ahead of of most of the competition in the R ecosystem. So very exciting stuff and and thanks to Absalon for running that contest.
[00:44:38] Eric Nantz:
Yeah. Because, Mike is designed a hex logo easy for you.
[00:44:43] Mike Thomas:
Not necessarily. I spend way more time than I need to spend but it's it's maybe not necessarily, the time that it takes to actually do the work, but maybe the the finickiness that I have trying to get, you know, what I want in my head, sorted out.
[00:45:03] Eric Nantz:
Yeah. Exactly. And so I've I've massive respect for anybody that it can have such, you know, in, you know, such amazing design skills. When I look at these examples on the blog post here. Yeah. I, I got absolutely nothing on that on that route. So all my internal packages do have a HEX logo. They take me a long time to get across, and then in the end, they just well, you won't see them, so you'll never know. But, basically, I just find some random open source image. I use column phase hex make shiny app to throw it on there with a little metadata, and then I'm done. I'm like, you know what? It's an internal package, so be it. But, yeah, if you are, as as Mike you said, a package author and looking to have a great HEX logo, yeah, this contest is definitely for you. So you got a couple days left to sign up for that. But what won't have a deadline here is our weekly itself. It does not stop. Right? I mean, we are continuing, you know, hopefully for a very long time with sharing these great resources for you. And, certainly, when, your trusty hosts here know how to hit magic buttons, we come with a new episode for you every single week. But, of course, we love we love hearing from all of you too. So one of the best ways to get help with the project, first of all, it would be looking at r o q dot o r g. Looking in the upper right, there's a little poll request button right there for the upcoming issue draft. So if you see a great new package or great new blog post that you think should be highlighted or or be part of the next issue, It's just all markdown text. Very simple. Just give the hyperlink.
We give a nice little contributor guideline there right in the in the template so you can, you know, fill out that information. Again, very straightforward. If you know Markdown, you know how to contribute our weekly. It is just that simple. And as well, we'd love to hear from you as well. There are many ways to do that. We have a somewhat new contact page because yours truly forgot that we moved to a new host that my previous contact page was gonna be null and void. So I've got a new one up. The link has been updated in the show notes, so you'll get to that right there. That's actually some custom HTML in that, by the way.
I'll be found a template online to do it, but credit to our podcast our podcast host called Pod Home for giving me the keys to be able to do that. So that was kinda cool in any event. You can fill out that as well as if you're on a modern podcast app, such as PowVerse, Fountain, Cast O Matic. There are many others out there. You can send us a fun little boost along the way right directly in your app itself, and these modern apps are gonna be where do you get to see those fancy chapter image markers on top of the chapters themselves so you can kinda get a little visual cue every time we dive into another topic.
But, of course, we are also available on these social medias. I am, Mastodon mostly these days with atrpodcast@podcastindex.social. And my quest to bring r to the world of podcasting 2 point o just hit another milestone recently. I have now open sourced a new package called 0p3r, which is a front end to the OP 3 API service by John Spurlock that gives open podcast metrics. And, yes, now I can visualize our weekly highlights metrics with my same package with a little deep fire magic. So more to come on that as I dive into to more on this, escapade that I'm on. So, that was, that was from my interview, podcasting 2 point o. Adam Curry himself said, yeah. Yeah. It'd be nice if we did that OP 3 stuff in your dashboard. I'm like, duly noted. So new package as a result. Boardroom driven development nonetheless.
But I'm also on Twitter, x, whatever you wanna call it with that the r cast sporadically, and I'm also on LinkedIn. Just search for your my name and you'll find me there.
[00:48:54] Mike Thomas:
Mike, where can the listeners get a hold of you? Eric, that is super exciting about your OP 3R package. Congratulations. I'm excited to to check it out and then install it, from GitHub and see what I can play around with. And it's a it's an API wrapper? API wrapper. Once again, I'm in the world of APIs now. Gotta love it. Gotta love it. I'm excited to to see how you went about, wrapping an API and and learning a little bit more about that because I know there's a few different ways to that folks go about doing that, some best practices out there and now that we have h t t r 2 and things like that. So, it looks like the thumbs up sounds like that's that's sort of the approach that you That's exactly what I built it upon. I've got some APIs. Very wild. Got some APIs I need to wrap. So, I will be taking a hard look at your repository. Thank you for your work there.
For folks looking to get in touch with me, you can do so on mastodon@mike_thomas@phostodon.org Or you can reach out, on LinkedIn if you search for Catchbrook Analytics, k e t c h b r o o k. You can see what I'm up to lately.
[00:49:58] Eric Nantz:
Very good. Very good. And, yep. So luckily, all things considered, I think we've got one in the can here. We're gonna hope so anyway. But, thank you so much for joining us wherever you are, and we will be back for another edition of ROV highlights next week.
Hello, friends. We're back with episode 166 of the R Weekly highlights podcast. If you're new to the show, this is where we talk about the latest happenings at our weekly every single weeki highlights podcast. If you're new to the show, this is where we talk about the latest happenings at our weekly every single week with, take on the latest highlights and other other great finds that are in the issue. My name is Eric Nantz, and I usually say every week as we usually do it. But, the universe kinda gave us a sign last week that maybe it was time for us to take a little week off. So I think I think we're better for it. But in any event, we are back this week, but I'm never alone on this. I am joined by my awesome cohost, Mike Thomas. Mike, how are you doing today?
[00:00:38] Mike Thomas:
I'm doing well, Eric. Yep. We did, record a great or we did, I shouldn't say record. We have a great episode last week. We just we just missed, the record in case you can't tell. But this week, we have pushed the button, so let's hope that it makes it out there to the universe.
[00:00:56] Eric Nantz:
Yes. And, as Mike can attest to, when he and I connected this morning, this was the very first thing yours truly did. So sometimes, yeah, the universe says may have gotten too comfortable before. So, you
[00:01:10] Mike Thomas:
know, the the bots can't automate everything. Mike, AI can't automate all this either, unfortunately. So Nope. That's right. Just add it to the collection of lost episodes out there. Highly Yeah. Valuable.
[00:01:20] Eric Nantz:
Luckily, it's still single digits, and we hope to keep it that way.
[00:01:24] Mike Thomas:
That's right.
[00:01:26] Eric Nantz:
But, you know, it's not lost. We got another fantastic issue to talk about today, and our curator this week was our another longtime member of the rweekly team, Jonathan Carroll. And as always, yeah, tremendous help from our fellow rweekly team members and contributors like all of you around the world with your poll request and other suggestions. And it's fun when you can lead off with, you might say, straight from the source, if you will, because we have a blog post straight from the r development blog itself on some of the latest patches and enhancements that have been made into base r to support a new frontier of object oriented programming systems.
And if you're coming into base r, you may have noticed that there are 2 built in object oriented programming systems right off the bat with no additional packages needed. These are called s 3 and s 4. They both accomplish similar things, albeit they go about it a bit differently. But you will find that, for instance, a lot of the tidyverse packages have been built upon s 3, whereas other packages in your ecosystem, especially those around the bioconductor side of things, have links to s 4. And we've covered in previous episodes of benefits and trade offs of each of those. But ever since about a year and a half ago, there has been a new effort, a joint effort, I should say, between the Arcore team as well as developers of, say, the tidyverse and other community related packages on a new object oriented programming system that is now called s 7, which right now is available as a standalone package that you can import into r.
But with the advent of s 7, it has provided the R Core team a time to reflect, if you will, on how to maybe help out packages like s 7 in the future become part of the base r installation. And they've identified a few key gaps, if you will, of ways to make this journey of incorporating into base r a bit easier. And this blog post in particular talks about a set of 4 different patches that have been landed ever since our version 4.3.0 that are going to pave the way for an easier onramp of s 7 and perhaps other packages in the future to take advantage of some of these principles that have been built into R for quite some time, but to help give a more friendly interface around these.
We'll do a quick recap of each of these 4, but we're gonna, you know, buckle up a little bit. We're gonna get pretty technical here. The first one, probably the most technical here, is the concept of how dispatch works with respect to different object types and different operators. If you don't know what dispatch means in this context, it is really the concept ascending a generic, which is another word for function that's supposed to have, like, one name such as plot or summary, but take different actions depending on the type of object being fed into it. And so it'll say, hey. If I wanna do a summary of a data frame, it's gonna do, like, a quick five number summary of each, you know, variable in your data frame versus for a model object. It's gonna give you those model fit convergence statistics, those likelihood statistics, and other information.
And typically for s 3, a generic will use the first argument that is passed into that that that that method call to help determine where it dispatches. S 4 kinda takes a more general approach. It could be any number of arguments in that call that help determine which method gets dispatched to. S 7 is somewhere in between. It has this intricate kinda double dispatch system And even I'm not quite sure how that part works, but, luckily, for the rest Even I'm not quite sure how that part works, but, luckily, for the rest of this explanation, we really need to know that because now since version 4.3, they are now helping the situation where it's not always just like a summary or, you know, other function like that. A lot of the operator functions in r, such as like the plus or the multiplication or many of these others, actually are built on 2 arguments. Right? You don't see it, but the left hand and the right hand side of these operators are like the 2 arguments to the actual function itself.
Well, before this patch, it would always if there was ever a mismatch in the types of arguments that are in these kinda operator type methods, r would warn you, hey. These aren't the same type, and it wouldn't dispatch anything that was based on those. Now since 4 dot 3, there's a new function built in the base r called choose ops method which is gonna let an object type declare that they are in fact based on a combination of different methods for that argument pair, not just one method. Where this is really gonna come into play is the situation where you have a pretty complex method that wants to do, like, these operator methods that is meant to do a unique thing, but be able to take an account that these argument types going in could be more than one type.
And they use an example from reticulate in this piece, which I think is quite interesting here. But for those aren't aware, Reticulate is the RPAC is a interfaces with Python under the hood, and, hence, it's going to find a way for your r code to go to the appropriate Python method. But especially in the space of machine learning and other methods like that, sometimes these operators, they might wanna build a custom, you know, method on. They're gonna have different things inside each of the left and right side, if you will. So in the example they have in the post, it's based on TensorFlow where you might have an interesting object that's based on a tensor, tensor itself, which is a Python object, but you might wanna add to that, like, a simple array in Python or whatever.
Whereas in for for r4.3, it wouldn't know what to do because these are 2 different object types. But now with this choose ops method, reticulate can say, okay. For this unique type of combination of an array and a tensor object, dispatch to this particular method. Now you may never really encounter this in your day to day development, but as a package author dealing with some more novel and more intricate class systems, this is going to be a big win for many people. So it's going to pave the way for more flexibility in these situations of building your own method on these, what you may call classical operator type functions.
And speaking of those classical operator type functions, there has been one that's kinda had a unique, you might say, history and where it's invoked. And that, in particular, is the multiplication surrounded by percent signs. If you've done any, like, math in r or maybe in your graduate school or over class training, you probably use this when you had to multiply matrices together if you're learning the ropes of linear algebra and the whatnot. Prior to our version 4.3, this only worked with either s 4 objects or base r objects. Well, guess what? Now that in 4.3, there is a way to have now a new generic category called matrix ops where it's gonna have this built in operator as one of its first citizens of it, so to speak.
But package authors and developers of new object class systems could help put in new methods into this. And they say in the future, within base r, they're going to fold in the cross prod and the t cross prod, functions into this family. So they do admit this is meant for backward compatibility, but it's also intending this to let other packages have to do with operations that are more unique in this situation such as s 7 in the future, be able to do the appropriate classification of these methods. And, yeah, we're we're not quite done yet. We got 2 more to go. One of these is also filling a need that can be inconvenient or maybe it was a bit difficult in the past of trying to figure out for an object type what class it inherits from.
There is a function in base r called inherits where you put in as the first argument the object itself, and the second argument of the name of the class that is meant to check if it inherits from. Well, a lot of these class names that for an s three standpoint were kind of built in as an attribute and not really meant for human consumption. It was not meant to be very syntactically, you know, very easy to understand, apparently. Well, now in the inherits function ever since version 4 dot 3, you can now have arbitrary objects as that second argument that you're gonna use the check for inheritance of that first argument, which means you don't have to memorize or go in source code to figure out what is that name of that s 3 object type that you're or class type that you're checking from.
You can now feed in a logical name of this or an object itself. So the example they have in s 7 where they define a class called class x, they give an object called class x of that new class, and then you can now use that as a second argument instead of a string trying to guess what that class type is. So that's also meant for use of s 7 to get into base r eventually, but there's no reason other packages can't inherit that same idea. Again, similar to the Python side of it where you might have in your reticulate package, build down reticulate, maybe a new class name that can be a lot easier to type for the user.
Last but certainly not least, if you're familiar with s 4, if you ever explore that, the way to get into what we call slots of these objects in your creative s 4 has been the at sign. It's kind of been like the dollar sign to me when you would use that in, like, your data frame, dollar sign, name a variable. In s 4, it's been quite similar. You would have your object that was built in s 4, use the at sign, and then you would start typing in, like, the name of either the method or the slot that you want to get more information on. Well, this never worked for anything besides s 4.
Well, now, ever since 4.3, now that can be used with s 3 dispatching as well. I still don't quite know in my day to day when I would would actually use this, but they do give justification for this by saying that s 7 is taking bits of s 4, albeit these more formal definitions of slots and other formals that are going into these class types. And now, if you have that muscle memory of using s4 and this at sign to get into these different slots, you're going to be able to use this of s 3 and s 7 now as well. Again, not sure when I'll use that day to day, but, again, many of these changes are paving the way for an eventual future state of s 7 becoming part of the base r installation.
So I think it's one of those things we're gonna see the fruits of this labor more down the road. But if you ever had questions on what our our core project is doing to get this state ready. This blog post is definitely for you, especially if you want a primer on how these are gonna make your life at developing a new object oriented programming system or building a a PONCE S3 or the new S7.
[00:14:16] Mike Thomas:
These are definitely, features that you wanna keep your eye on as you're developing your source code for that. Yeah, Eric. This is this is pretty exciting stuff and it's interesting to me to see how Posit and the RCCOR team are coming together on this initiative as well as some others, you know. It's really cool to have that, collaboration out there between, you know, the brightest minds in the some of the brightest minds in the R ecosystem. And if I understand it correctly, I think the the road map here is that this new framework is currently out there as an R package called s7 for developers to, today if you want to, download, install, and kick the tires on it for a while.
And then once the team feels that the package is stable across a wide variety of use cases, I believe the idea is to bring s 7 into base r. And I don't know if there's any specific timeline on that that we saw in the blog post. Not not yet. It looks like it's still got some work to do. Yeah. So I I would imagine that it's gonna be a function of how much use this s seven r package gets, and how many folks out there can download it and and try it out, and how many edge cases, they can find before they they finally feel that, s 7 is is stable enough to bring into base r. But, this is all, you know, I think extremely exciting stuff for those who are trying to, you know, sort of push the boundaries of what R can do. I I think, a lot of the power behind, this object oriented programming approaches is actually in making sort of the the end user's life easier and making the UX for, you know, our users that maybe don't necessarily need to know or care about, you know, methods, classes, object oriented programming, make, you know, their day to day jobs easier. Just like you said, Eric, we have these these generic functions, you know, summary. You can call that against a a data frame and get your your quantiles for each column, or you can call it against the model object. And each, you know, for for most authors of of our packages that contain predictive modeling frameworks, they all typically implement their own sort of summary generic or or print generic as well against the model objects that those packages offer. And the ability to sort of do that and custom tailor what the end user is going to see on screen is is really cool. It's really powerful. And for those of us in our early in our our journey or even, you know, intermediate in our our journey, the fact that we just sort of get that nice functionality for free, is is fantastic. And it it makes everybody's life easier. I think it contributes to some of the reasons why R can be a friendlier language for some folks to pick up. So, you know, the fact that we're getting some additional, you know, extension functionality, you know, beyond s 3, what s 3 can do in this new s seven implementation, you know, particularly with with sort of that second argument idea, I think is going to go a long way to continuing, to help, you know, those hardcore r developers make, everybody everybody else's life a lot easier. So we're very appreciative of that.
[00:17:27] Eric Nantz:
Yep. Exactly. And I'll admit my journey in OOP systems right now has been on a package, r 6, because I'm doing some shiny extensions as we speak. But it has been on my bucket list, so so to speak, to get into s 7. And our our good friend, John Harmon, has been doing some work of s 7 as well and some of his package development exploration. So it's it's on my to do list. But as you know, Mike, there's only so much time in the day.
[00:17:52] Mike Thomas:
I'm in the same boat, Eric. I have some grandiose ideas still sort of on the s3 object oriented side, but, we have this this credit scorecard package that leverages traditionally just a a GLM, a logistic regression model, but it's very possible to stick these scorecard models or wrap them around, other modeling types like XGBoost and something black box. But the methodology for for doing so, is is quite a bit different. So I'd have to to stand up a lot of different, I guess, object oriented approaches to ensuring that these generics that we've written, you know, fire correctly. So I have lots of ideas and plans as well, but it's only so much time as you said.
[00:18:46] Eric Nantz:
You know me, I love it when we have more open resources for both developers and users to kinda test their visualization muscle on, so to speak, and really generate some awesome insights. And our second highlight is highlighting just that. It comes from Kyle Walker who is a director of research for a winyan, if I'm pronouncing that right, as well as he has, apparently, his own consulting company for data science. And he highlights area that I did not know about until I read this post. So, again, I'm always learning when I read these. But, there is a project out there called the overture maps datasets initiative, which is a project not just from 1, not 2, but multiple big tech giants in the tech sector such as Microsoft, Amazon, and Meta, along with others to help produce both open and standardized geospatial datasets.
My goodness. Oh, this this looks really fun, and it's meant for developers to be able to use in the applications that they develop. Well, of course, nothing wrong of using this in r as well. Now how will we pull this off on the r side of things? Guess what? These datasets are written in what format, Mike?
[00:20:06] Mike Thomas:
My favorite format, Eric, parquet.
[00:20:13] Eric Nantz:
Exactly. We've been harping on parquet for many months now on this show, but these datasets have been shared as objects and s 3 storage on AWS for public consumption with parquet. And just how can you import these into r itself? Guess what? The arrow package is your friend here because the arrow package will be able to import not just these parquet files that are stored locally on your disk. They can read from remote locations as well, such as these s three locations and not just read from them. It's not like you're, you know, behind the scenes, like, downloading in some temp area and then somehow importing all this into your system. No. No. No. No. These are kept remote, and this is really important example that Kyle outlines here because he found a unique data set with respect to building coordinates or topologies, and this data set has, get this, over 2,350,000,000 That's a b. Building footprints around the world. Mike, have you ever had your hands on a data set this large?
[00:21:22] Mike Thomas:
How how big is the New York taxi dataset?
[00:21:25] Eric Nantz:
Probably not that big. I don't think it's that big. Yeah. I think that's in the millions, but, boy, we're talking about 1,000,000,000 here. So you can imagine if you put that in your system, yeah, it's gonna probably blow up and smoke fire or whatever in your laptop or PC of choice. So you don't want that in your home memory. Guess what? IRL comes compatible with dplyr functionality, so you can use this to query for just the parts of data you need. And in particular, in the example that Kyle walks through here, he has an example of filtering the coordinates based on San Francisco, I e the state of California where he was able to grab the actual coordinates, from, I believe, another package to get the coordinates, right, the bounding boxes.
And then once you have that well, of course, we're visual. Right? We wanna see what this looks like. The the package called rdeck, which is a wrapper on deck GL, gives you a way to have a 3 d based visualization of these buildings. And in the post, the code itself, really and really straightforward. Really not too much going on here other than setting your initial view and centering the coordinates, doing some zooming parameters, and then adding the layer, I. E, the Polygon layer for based on that data, the building topology from San Francisco and then being able to basically feed in variables for the various attributes, much like ggplot2 in a sense. And lo and behold, if you're looking at this in your modern podcast app, you'll see in the chapter image marker, you got a really nice looking topology layout of San Francisco that looks pretty darn cool if I dare say so myself.
And so Kyle was curious. It looks like the u United States portion of this data has a little more fleshed out, building data, so to speak. He thought, what's it look like in the rest of the world just to kind of test that, you know, hypothesis out? He did the same kind of code, but instead of going to the US, he went to Sydney, Australia to see what kind of topology he would see here. And you do see that there's only maybe looks like about 15 or 20 buildings that are represented here, which obviously we know Sydney is a big city. Right? So there's gotta be a lot more to it. But this just goes to show this iterative nature or might say the early stages of this initiative. So perhaps there will be others in the community that start contributing more data to the Australia side of things or other parts of the world. But in any event, you've got access to this really innovative set of data.
You do not have to blow up your hour session and import it in. Parquet is, again, we've been harping on this before. It's opening up a ton of possibilities for you as an R developer and R user to be able to do some really great insights without having side of side of things later on, this data set this set of data looks like a great source to draw upon. Yeah. Eric, I couldn't be more excited about this project. In the past, I've
[00:24:45] Mike Thomas:
leveraged typically the Google suite of APIs for geolocation types of of activities. Think if you remember my Connecticut, COVID 19 at home test spotter shiny app that I I shared on the shiny dev series, we use the Google Places API to allow users to search for particular places, in in the US and have, you know, that autocomplete that you're familiar with seeing, if you're ever been on Google Maps and ensure that the the particular place they selected is is a recognized location in Google's giant database. And it's a fantastic API, but there there can be some cost associated with that depending on your volume. And this new project, that's, as you mentioned called called Overture which is this collaboration between these powerhouses, Microsoft, Amazon, and Meta to open source these large geospatial datasets is is really exciting. And I I there talk about 5 different, particular geospatial datasets out there. One being administrative boundaries.
2, land and water features, building footprints and roof prints, and then points of interest which I think are are like that places dataset that I was talking about, places API. And then last is transportation rare layers, like roads and public transit ways. One other feature that I hadn't, seen before is this deck.gl, library which is a relatively new, I think, framework for visualizing these very large datasets. And as you can see in the blog post, the output of, the deck dot gl maps is is beautiful. They have great visuals there, very modern looking, really really cool. And that rdeck package is just this great wrapper for the API that, as you said, the code here is is quite minimal. It's pretty incredible. There's some data prep work that goes on to to grab counties and to filter down, the buildings within a particular bounding box coordinates that we we care about, using, you know, the dplyr and arrow combination as well as the the sf package.
And then there's this one call, a few lines. I think it's 1, 2 arguments really, to the rdeck package in order to sort of build that base map and then leverage this add polygon layer function on top of that to, really stick your polygons on top of there that are going to draw, the the different shapes on the map that you're looking for, all these different buildings and their their heights and the gradients and scales and things like that. And and that's about it. It's it's pretty incredible. It should feel pretty straightforward and and familiar to those who have done any geospatial analysis before. So the fact that we just continue to get these higher and higher performance tools for all of our data science work is super exciting.
A great blog post, great walk through. I used, you know, you you we've talked about this a 1000000 times on the the podcast before and my love for Parquet k as well as the arrow package. I recently used DuckDV for the first time last week finally. I had a 25,000,000 by 50 column SQL Server table that I wasn't about to to try to write summary queries against because I I tried to do that once and it it did not end well. Let's just put it that way. So I was able to to write that out to parquet using a a chunked approach, and the new I think, ADBC, that database connection for, for the Arrow framework and wrote that out to Parquet, and then I use DuckDV to query this this parquet file that ended up being, you know, I think around 1 gig for these 25,000,000 rows by 50 columns sequel server table, and the the queries that I was running with DuckDV were taking like less than a second.
It was it was insane. It was incredible. So I can't I can't sort of recommend these frameworks enough for, you know, high performance, data analysis. And this is a fantastic use case of bringing a few different tools together, in terms of some of the Tidyverse ecosystem, the Arrow project, some of these other data visualization libraries, and then this new deck dotgl library, which is incredibly exciting. And, like I said, sort of the outputs here are are really visually appealing and nice. So it's a fantastic blog post, to to have out there. So thanks to Kyle.
[00:29:07] Eric Nantz:
Yeah. Absolutely. In fact, I've even just thought of a a use case for this myself in a rather geeky project where I'm starting to interface more with some interesting podcast metadata, and some of it is the location where downloads are occurring from. You know? Maybe I could use this to map out the downloads of our weekly highlights on a nice little map, so to speak. So I'm, you know, cover me intrigued then, and I I still think parquet is becoming the new CSV in a lot of our data science circles, and this is just yet more more credence to that. So, yeah, really, really fun to learn about the innovations in this space as well. And last but certainly not least on our highlights section today, we, in this, quote unquote loss episode last week, we we had a great discussion on ways that have been explored to help automate some refactoring of tests.
Well, we're gonna make good on it because we have part 2 of that series here. We're gonna talk about the highlights here, and this comes to us from Al Salmon who, of course, was a former contributor here at rweekly and now is a research software engineer with rOpenSci and rhub and synchro as well. And this is part 2 of her quest to refactor test files in one of her packages. And, again, last in her her post last week, which, again, is on last week's our weekly issue, she had a fantastic, albeit quite in-depth system of using a combination of parsing our code and XML representation of code to find calls to certain expectation functions and be able to swap them on the fly by how having to do the infamous control f find and replace for all these hover instances. Well, we're we're getting a little bit more, human readable here, so to speak, in terms of automation versus, you know, some principles that I think on paper they make complete sense.
But, again, you got to put it into practice. Right? And, I already have one project where I put maybe half of these in practice, and I'm gonna go back and put the rest in practice. We'll kind of hit these 1 by 1 here, but a lot of these are gonna relate to not just test, but also your base r code as well for your package or other routine. Make variable names that actually make sense, and this also applies to your test suite as well because it may be tempting if you're, like, doing a similar expectation by just varying, like, 1 or 2 things, kinda reuse those variable names over and over again.
No. No. No. No. No. Don't do that. It'll make the bugging a lot worse, especially if most of those expectations pass except for one thing here and there. So having variable names that make make more sense to you when you read it, don't be afraid to make them verbose. I like long variable names if it helps my cognitive function. And so don't worry about, you know, trying to be with that. Again, you are probably the one that's gonna read this the most. So be nice to future you on this. And speaking of variable names, you, again, may be tempted to use the same ones across different tests if they're all doing the similar type thing.
You know, you might wanna change those up a little bit. So in her example here, she's got a function that has, like, 3 different modes of complexity, and she changes those inputs going into the expectations based on that mode, if you will. Easy, medium, and hard versus, like, x x x for all of them. So, again, tailor it to the way you as a developer can help move your debugging when these expectations are not passing. And then as you're developing these expectations, you may think about, oh, when I wrote this package, I had, like, all my objects created above, and then I put them, like, my processing functions below that or whatnot.
Maybe for testing, you don't wanna do that. Maybe you wanna put the the objects you're creating related to the expectation that it's testing with and put those groups together instead of, like, all your objects in one part and then all your expectations in another part. Again, some of this is subjective, but, again, when you're debugging things, it may be much more straightforward to have these logical groupings of the object and expectation with each other instead of, like, everything in the preamble of your test and then every expectations all below it. So, again, these are all nice enhancements, but she's not done there. She's got a lot more here, Mike, that I think you could definitely relate to as a as a developer as well.
[00:34:06] Mike Thomas:
Yeah. Unit testing is a a funny thing, Eric, because some of the sort of best practices that you might think of in terms of how we like to author our code, can sometimes go by the wayside or or not necessarily make as much sense within a unit testing framework. And, you know, her her last sort of section here that she talks about or as you were discussing before is maybe not, you know, create all those different objects and then run your sort of expectations, you know, against those different objects that you previously created, but keep everything sort of logically together. So if you're about to execute a test using, you know, expect, equal or expect greater than or something like that, you should have the object that you're using in that test or objects that you're using in that test as close to that as possible.
And and I think that that makes a lot of sense. You know, when I'm reading some source code of developers that I, you know, admire and and try to mimic, I think that that's something that I see, you know, quite often in their their unit tests within their test that folder is that everything is is sort of chunked up nicely into different sort of logical sections where they they have a per very particular thing that they are trying to test and, you know, they have that that very much segmented in one location. However, you know, sometimes you're trying not to recreate the wheel all the time as well and there may be opportunities maybe at the header of that file before you start executing any of your unit tests to create a particular particular object that you're going to actually pass and leverage in a lot of the different tests that you're running. So there's some trade offs here.
A lot to think about. I I again, I say this I feel like every time I'll author a blog post but I feel like these topics aren't something that's talked about very often. So it's it's really nice to have someone out there who is talking about, her opinions and best practices, you know, most of which I I sincerely relate to. But these are a lot of things that I've had to learn the hard way, sort of, by trial and error, over the years and not necessarily had a lot of content out there to follow. So very grateful for Mel for for putting this together. And and maybe the last, point that she puts out is is try to use a a bug summary and not just maybe the issue number that you're solving as your test name. You know, if you go back and take a look at a test, you know, where sort of your test that, first argument there is just the string that says, you know, bug number 666 is fixed as Mel uses for an example.
She certainly prefers that you you write that string to say something like, you know, my awesome function does not remove the ordering. You know, sort of, maybe providing the summary of that issue as opposed to just the issue number itself. So that when folks are going back to to understand it and look at the tests that have been written, It's very easy for them to be able to see exactly what's taking place in these tests, what has been solved, what maybe still is open and needs to test around that. And she recommends, you know, use that summary as that string, that first argument to your test that call, but but maybe you can have a comment within that that has a link, to the particular bug report or that git GitHub issue, so you have sort of the best of both worlds there. So a great great, blog post here again by Maelle. I really appreciate her covering a a topic that I think doesn't get enough attention, and I definitely learned a lot here. Yeah. Me as well. And I've been actually,
[00:37:48] Eric Nantz:
in the past couple weeks, I've been bolting on some really interesting unit tests for a shiny app I'm about to put in production. But guess what? As much as it may seem like a paradox, Mike, 90% of those tests have nothing to do with shiny. It's about the business logic, which again is a pattern that may not be as obvious as a Shiny developer. But guess what? Because the business logic is just based our code if your summaries or visualizations or over, you know, in this case, some Bayesian modeling. These are all things that we can take principles that Miles outlined here and as well as her previous posts on developing best practices. So I have her blog on one tab. I have the r packages tab on or open on another tab. The r packages book by Hadley Wickham and Jenny Brian. And so these have been greatly helpful. And, yes, there is some shiny test to match. I got the end there for what I call a more end to end user focused view of it.
But, boy, if I have confidence in the business logic and I organize these tests such that I know exactly where to go if something fails. And sure enough, I had some failures with a survival object outcome where I was like, wait. Why didn't it work for binomial and continuous? Why not for survival? Sure enough. I was doing a dumb thing in one of the inputs and the processing functions. But the expectation covered it, and I knew exactly where to go. So it does help future you. You've just gotta try it once. I promise.
[00:39:13] Mike Thomas:
I couldn't agree more, Eric. Please please please write unit test for your business logic. It's the most important place to have them.
[00:39:20] Eric Nantz:
Exactly. So I've got, members of of our developer team helping with some of those business logic. I gotta kinda help with the summary and visualization side of it. But in the end, we've got over 40 of these tests, and right now they're all passing. So yay for now. Hooray. You know you know what passes, though, as well. It passes the, the r curiosity test, if you will, is the rest of the rweekly issue because we got a lot of great content for you to continue your learning journey on with new packages, new blog posts, great new resources for you to dive into. So as usual, we'll take a couple of minutes to talk about our additional finds here.
Speaking of learning, this is definitely gonna be relatable to those who have children here in the US have started their summer breaks. Right? They're, they're not using their, their course web pages now to get homework and whatnot. But most of those schools here in the US build their learning systems on something called canvas. It's a learning management system. Mike, you're gonna know about this in a few years. Trust me on this. And most of their most of the teachers will use this to help bring out assignments or, you know, get in touch with their students, add resources, and whatnot.
Well, if you are a maybe teaching a, who knows, maybe a stat or math course, and you wanna use r in it, but you wanna help use r to help automate some of your management of these resources, well, there is a package for you. This package is called vv canvas. This is a package to automate tasks in the Canvas LMS, and this has been authored by Ewin Tomer. And this is actually part of what was new to me, a verse of package is called the Vusa verse, which is a collection of our packages tailored to student analytics with respect to teachers using these in their courses and and other systems.
So this package basically builds upon the Canvas API If you wanna use r to help automate certain tasks, like creating, you know, assignments or finding metadata of assignments and whatnot. Looks really interesting if you're using this system with respect to your teaching. And as usual, as I say to many people, if there's an idea, there's typically a package for that. Well, little did I know there will be a package for the campus learning management system. So that was a new one to me. So maybe if you're one of these teachers that are on your quote unquote summer break and you wanna supercharge your, learning pipeline for administering your course and you use R, maybe this is for you. I have no idea.
Unfortunately, as a parent, I can't leverage this API. They don't give me the keys for that. But, hey, if I was ever teaching, I would. I
[00:42:10] Mike Thomas:
have heard of Canvas before. You're right, Eric. I'm not quite there yet, but I am sure that sooner rather than later, if Canvas is is still around, I will be engrossed in it, once my daughter gets to gets to school. So very good to know. Very, very good highlight. I've got a couple for us. I will wanna shout out Stephen Paul Sanderson who has a bunch of little bite sized, posts which are are just fantastic little nuggets. One is called how to remove specific elements from a vector in r. He walks through, approaches using baser, d player, and, data dot table, I think. He has a a little, blog post how to split a, number into digits in r, which is fantastic. It's actually a use case that I had with with DuckDV, which has fantastic, function to be able to do so to split a a particular value by a delimiter into an array.
And then it has a second function for picking the element of the array that you want but that's just a a tangent, based upon some rabbit holes that I had to dive down recently. So I want to shout out, Steve Sanderson for these great bite sized posts. Then I also wanted to shout out Epsilon for this contest that they are having, to win a, I believe, professionally designed HEX logo for your r package. You have until May 31st to sign up for this. So you have a couple more days left. You have to provide some details about your r package, package, name, purpose, functionality, and some links and, briefly describe the design that you're looking for, design concept, any preferences that you have for the logo, and you could win a professionally designed hex logo for your r package. And if you've seen any of Absalon's, I think newly sort of rebranded or redone, hex logos, I'm thinking about the tapper package which is, I believe is that on the Shiny for Python side? That's their Yep. Rhino That's their kind of rhino like wrapper. Yes. For building modularized, Shiny for Python applications.
These HEX logos look super clean, super modern, really really cool. So if you did win this, I have no doubt that that the design that your R package would get for its hex logo would be be very fresh, and would be, you know, sort of way ahead of of most of the competition in the R ecosystem. So very exciting stuff and and thanks to Absalon for running that contest.
[00:44:38] Eric Nantz:
Yeah. Because, Mike is designed a hex logo easy for you.
[00:44:43] Mike Thomas:
Not necessarily. I spend way more time than I need to spend but it's it's maybe not necessarily, the time that it takes to actually do the work, but maybe the the finickiness that I have trying to get, you know, what I want in my head, sorted out.
[00:45:03] Eric Nantz:
Yeah. Exactly. And so I've I've massive respect for anybody that it can have such, you know, in, you know, such amazing design skills. When I look at these examples on the blog post here. Yeah. I, I got absolutely nothing on that on that route. So all my internal packages do have a HEX logo. They take me a long time to get across, and then in the end, they just well, you won't see them, so you'll never know. But, basically, I just find some random open source image. I use column phase hex make shiny app to throw it on there with a little metadata, and then I'm done. I'm like, you know what? It's an internal package, so be it. But, yeah, if you are, as as Mike you said, a package author and looking to have a great HEX logo, yeah, this contest is definitely for you. So you got a couple days left to sign up for that. But what won't have a deadline here is our weekly itself. It does not stop. Right? I mean, we are continuing, you know, hopefully for a very long time with sharing these great resources for you. And, certainly, when, your trusty hosts here know how to hit magic buttons, we come with a new episode for you every single week. But, of course, we love we love hearing from all of you too. So one of the best ways to get help with the project, first of all, it would be looking at r o q dot o r g. Looking in the upper right, there's a little poll request button right there for the upcoming issue draft. So if you see a great new package or great new blog post that you think should be highlighted or or be part of the next issue, It's just all markdown text. Very simple. Just give the hyperlink.
We give a nice little contributor guideline there right in the in the template so you can, you know, fill out that information. Again, very straightforward. If you know Markdown, you know how to contribute our weekly. It is just that simple. And as well, we'd love to hear from you as well. There are many ways to do that. We have a somewhat new contact page because yours truly forgot that we moved to a new host that my previous contact page was gonna be null and void. So I've got a new one up. The link has been updated in the show notes, so you'll get to that right there. That's actually some custom HTML in that, by the way.
I'll be found a template online to do it, but credit to our podcast our podcast host called Pod Home for giving me the keys to be able to do that. So that was kinda cool in any event. You can fill out that as well as if you're on a modern podcast app, such as PowVerse, Fountain, Cast O Matic. There are many others out there. You can send us a fun little boost along the way right directly in your app itself, and these modern apps are gonna be where do you get to see those fancy chapter image markers on top of the chapters themselves so you can kinda get a little visual cue every time we dive into another topic.
But, of course, we are also available on these social medias. I am, Mastodon mostly these days with atrpodcast@podcastindex.social. And my quest to bring r to the world of podcasting 2 point o just hit another milestone recently. I have now open sourced a new package called 0p3r, which is a front end to the OP 3 API service by John Spurlock that gives open podcast metrics. And, yes, now I can visualize our weekly highlights metrics with my same package with a little deep fire magic. So more to come on that as I dive into to more on this, escapade that I'm on. So, that was, that was from my interview, podcasting 2 point o. Adam Curry himself said, yeah. Yeah. It'd be nice if we did that OP 3 stuff in your dashboard. I'm like, duly noted. So new package as a result. Boardroom driven development nonetheless.
But I'm also on Twitter, x, whatever you wanna call it with that the r cast sporadically, and I'm also on LinkedIn. Just search for your my name and you'll find me there.
[00:48:54] Mike Thomas:
Mike, where can the listeners get a hold of you? Eric, that is super exciting about your OP 3R package. Congratulations. I'm excited to to check it out and then install it, from GitHub and see what I can play around with. And it's a it's an API wrapper? API wrapper. Once again, I'm in the world of APIs now. Gotta love it. Gotta love it. I'm excited to to see how you went about, wrapping an API and and learning a little bit more about that because I know there's a few different ways to that folks go about doing that, some best practices out there and now that we have h t t r 2 and things like that. So, it looks like the thumbs up sounds like that's that's sort of the approach that you That's exactly what I built it upon. I've got some APIs. Very wild. Got some APIs I need to wrap. So, I will be taking a hard look at your repository. Thank you for your work there.
For folks looking to get in touch with me, you can do so on mastodon@mike_thomas@phostodon.org Or you can reach out, on LinkedIn if you search for Catchbrook Analytics, k e t c h b r o o k. You can see what I'm up to lately.
[00:49:58] Eric Nantz:
Very good. Very good. And, yep. So luckily, all things considered, I think we've got one in the can here. We're gonna hope so anyway. But, thank you so much for joining us wherever you are, and we will be back for another edition of ROV highlights next week.