An aesthetically-pleasing journey through the history of R, another demonstration of DuckDB's power with analytics, and how webR with shinylive brings new learning life to the Pharmaverse TLG gallery.
Episode Links
Episode Links
- This week's curator: Sam Parmar - @[email protected] (Mastodon) & @parmsam_ (X/Twitter)
- The Aesthetics Wiki - an R Addendum
- R Dplyr vs. DuckDB - How to Enhance Your Data Processing Pipelines with R DuckDB
- TLG Catalog 🤝 WebR
- Entire issue available at rweekly.org/2024-W20
- Eric joins Adam Curry & Dave Jones on Podcasting 2.0 Episode 179! https://podverse.fm/clip/dYmaWGIOc
- DuckDB quacks Arrow: A zero-copy data integration between Apache Arrow and DuckDB https://duckdb.org/2021/12/03/duck-arrow.html
- Demo repository for creating a Quarto workflow with {quarto-webr} and {quarto-pyodide} https://github.com/coatless-quarto/quarto-webr-pyodide-demo
- What's new in ShinyProxy 3.1.0 https://hosting.analythium.io/what-is-new-in-shinyproxy-3-1-0/
- Use the contact page at https://rweekly.fireside.fm/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Green Glade Groove - Donkey Kong Country 2: Diddy's Kong Quest - TSori, dpMusicman, etc - https://ocremix.org/remix/OCR04437
- Gerudo Desert Party - The Legend of Zelda: Ocarina of Time - Reuben6 - https://ocremix.org/remix/OCR03720
[00:00:03]
Eric Nantz:
Hello, friends. We're back of episode 165 of the our weekly highlights podcast. If you're new to the show, this is the weekly podcast where we talk about the latest resources, innovations that we're seeing in the our community as documented in this week's our weekly issue. My name is Eric Nantz, and I'm delighted you join us wherever you are around the world and wherever you're listening to. And as always, I never do this alone. We're in the middle of May already. Time goes by fast, but I'm joined by my cohost,
[00:00:32] Mike Thomas:
Mike Thomas. Mike, where's the time gone, man? It's crazy. I don't know. It is crazy. And, yeah, we gotta do the stats on how many episodes we're at together now at this point, Eric, but it's it's gotta be a lot.
[00:00:44] Eric Nantz:
That's right. And now would never feel the same without you as is, I was thinking that you're sick of me. Not quite. Not quite. Not yet. You ought to you ought to give me more rants before that happens. But in any event, yep, we have a lot of great content to talk about. Before we get into the meat of it, I do wanna give a huge thank you to the, pod father himself, Adam Curry, and the pod stage, Dave Jones for having me on this past week's episode of podcasting 2.0, where I was able to geek out with them and, or as the chat was saying, nerd out, the, our language itself and the use of our end quartile to produce this fancy podcast index database dashboard. That was apparently more of a reality check than what Dave was expecting in terms of data quality of the podcast index database. But it was a ton of fun, And, apparently I've given him some things to follow-up on, which we may be touching on in one of our highlights here. But again, thanks to them for having me on, and I've been anointed the podcasting 2 point o data scientist. So I'm gonna take that and run with it. Pretty cool. Add that to your CV, Eric. I'm super stoked to listen to that episode. Today, I got a long car ride this afternoon and I will be tuning in. So,
[00:02:01] Mike Thomas:
very very excited to to hear about that.
[00:02:04] Eric Nantz:
Yes. And I'm actually gonna make sharing that even more efficient in this episode show notes. I will have a link not just to the episode itself, but to an actual clip of the episode with my segment on it. Again, one of these great features you can give in podcasting 2.0. So that's just a tip of the iceberg or some of the things that dev community is up to. But, nonetheless, we got some great art content to talk about here and our curator this week's for this week's issue was Sam Palmer, another great contributor we have in our our weekly team. And as always, he had tremendous help from our fellow our weekly team members world with your awesome poll requests and suggestions.
And, Mike, we're gonna I guess guess this first high is gonna be a kind of a trip down memory lane, but I'll be at a visual aspect of it in ways I totally did not expect until we did research for this show. Oh, yeah. Exactly. So our first highlight today is coming from the esteemed Matt Dre who has been a frequent contributor to our weekly and past issues. And in particular, he's been inspired by a resource that admittedly little old me did not know about until now, but is called the aesthetics Wiki, which in a nutshell, what this is is a Wiki portal, but it's a very visually themed Wiki portal where it's got a collection of images, colors, links to musics and videos that help give you a vibe, if you will, of a specific maybe time period or a specific feeling in mind. And I met when I looked at this and I was going coming through some of the, you you know, the top Wiki pages, there was one about the y two ks issue from way back. And, I could I could definitely got the memory triangle. I'm looking at that Wiki portal, but I'm also getting vibes. And so this is gonna date myself quite a bit, so bear with me here. But, yeah, I had cable TV growing up and one of the, guilty pleasures I had was on VH one watching the I love the eighties, and I love the nineties series because it was such a fun trip down memory lane for each of those years of those decades. And I will still stand on my soapbox here. And at the eighties nineties were the golden age of video games, so take that for what it's worth. But in any event, I I definitely got those same vibes here. And apparently, Matt was inspired to think, you know what? On this Wiki, there's something missing.
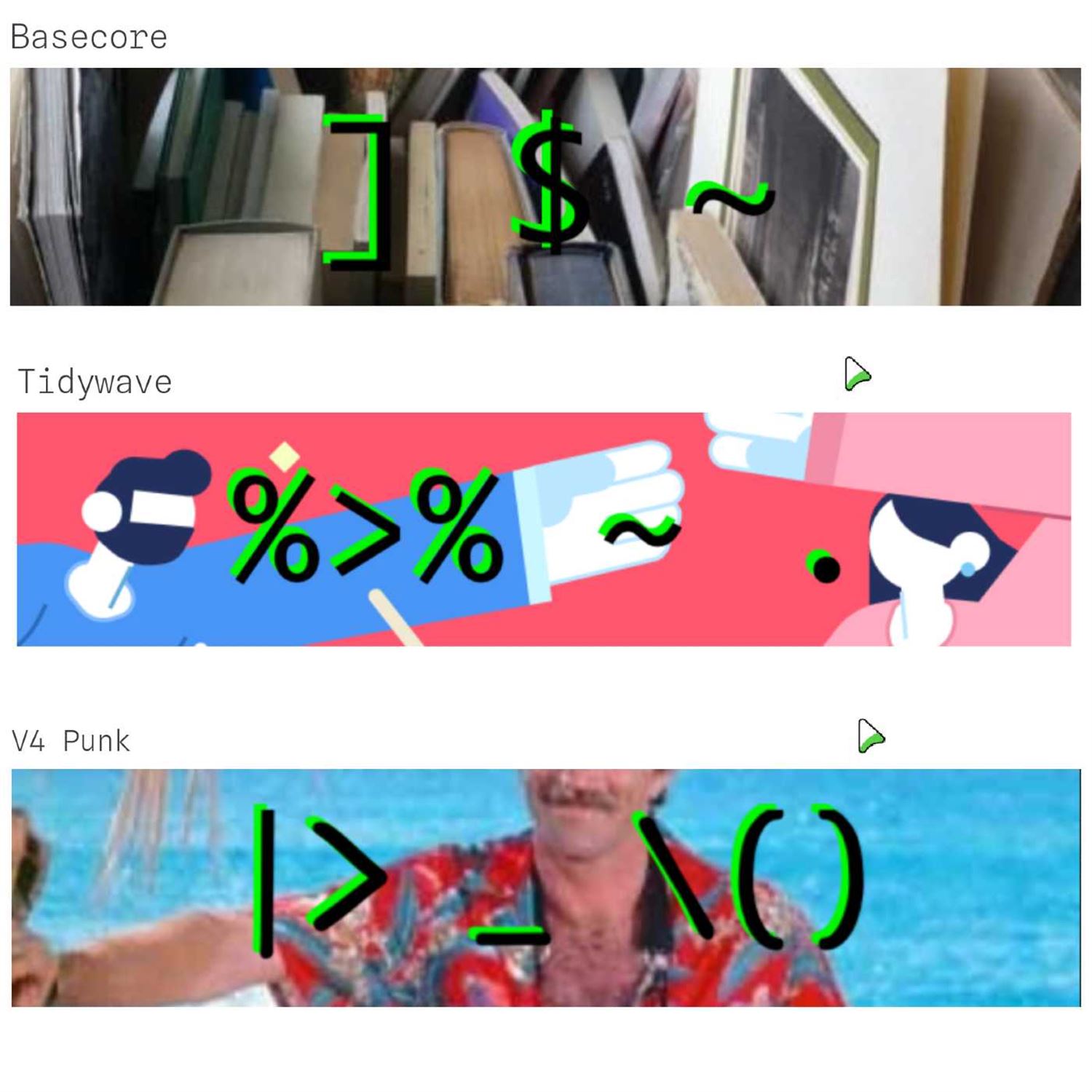
It's the R language, of course. What could we do to visually depict certain, I would say, major stages in the evolution of our, for respect to this kind of theme on the aesthetics Wiki. So I'm gonna lead off with probably the most appropriate given yours truly is the old timer on this show with the first period that Matt draws upon is called base core. And the picture on the blog post definitely, gives you some vibes of there's a lot going on under the hood with our, but it's, you know, kinda scattered around. It it's it's got a lot happening. And he talks about some of the bullet points that inspired the imaging here because of if you know your our history, it actually came in the mid nineties.
It was derived from the s language and then to our from Rasa Hakka and Robert gentleman and then base core as we know it was founded in the year 2000. And if you have old r code laying around from that time period, I eventually gonna have 3 major operators in there one way shape or form. Bracket notation for referencing rows or variables, dollar signs for referencing variables inside a data frame, and the tilde's for your linear regression model fits and whatnot. He also mentions that if he was gonna put this Wiki together, he would have a link to the, writing our extensions PDF, which I've combed through a few times in my early career, but it's, not for the faint of heart if you're if you're new to the world on that.
But, yeah, the the the vibe of it is very, you might say, utilitarian, kind of mundane a little bit here and there, but the potential is there. So I really like what he put together there. And of course, in the in the blog post, it's in our post after all. He's got a code snippet that looks straight out of my early r classes and graduate school where you've got the assignment operator referencing rows with the double equal sign in the brackets, the dollar sign for referencing variable names and FL's aggregate, you know, bay from base are, and then finally ordering it by height. In this case, it's a data set of star wars worlds and characters. And in the end, you get a nice data frame of the average heights for those living in Tatooine or Naboo and others.
So I feel seen when I see that because if I look back in my old land drive here in the basement, I have lots of code that looks just like this. But our many other developments have happened. And the next period that Matt talks about will be something that I think will look pretty familiar to most users now. He calls it the tidy wave, Mike, and I would say it's anything but mundane.
[00:07:28] Mike Thomas:
Yes. No, Eric. That was a great trip down, you know, the the late nineties, early 2000 of our the aesthetic or the fashion, that Matt matches to the the base core, time period is cardigans and a wired mouse with a ball in it. Man, if that doesn't sum up base score, I don't know what does. But on to the Tidy Wave as you'd say, he he talks about the history sort of starting in 2,008 and then later being popularized, mostly through the Tidyverse, sort of wrapping up a lot of, this different tidy functionality in 2016 when that was originally released.
The key visuals here are the mcgritter pipe, the data placeholder as a period or a dot, and then the tilde, not being used for formulas but being used for Lambda functions in this iteration here. The fashion choices are Rstudio, hex stickers, and rapid deprecation.
[00:08:33] Eric Nantz:
Where did you get that idea from?
[00:08:36] Mike Thomas:
Every package is experimental. I feel feel like, you know, with the the little badge that it has, during this particular time period, but a lot of fun. Right? Absolutely. And you can see that the code snippet that we have here is leveraging a lot of dplyr verbs like filter, select, left join, mutate, summarize, and arrange. And the code arguably is a little easier to understand what's going on from from top to bottom and left to right. Looks a little more SQL ish than what you got in the base core, time period. And that brings us to this last new period, Eric, which Matt is calling v4punk.
[00:09:17] Eric Nantz:
I love this because this is one of those situations where we are seeing another big evolution, but it's so fresh. May not fully grasp it yet. But the visuals of this have big roots into one of the most major developments in the our language itself of the last few years. And that is the introduction of the base pipe operator, which, again, one could argue that the tidy verse popularity you just summarized was a direct influence on this feature coming in alongside other languages having similar mechanisms. And in 2022, it was released fully, in support of our the the base pipe. So that is, of course, one of the key visuals here along with the underscore, which is not just for variable name separations between words, but as a data placeholder, similar to what you mentioned earlier with the period and the and the previous summary and a new notation for Lambda functions, which, admittedly, I'm still wrapping my head around, but it's the slash with the parenthesis afterwards. I admit, Mike, I have not actually written that one out yet. You're gonna have to pull the tilde for lambda functions out of my cold hands, so to speak, but I am warming up to it. It's just taking a while.
So the fashion here is this one's really funny. It's, you might call evil mustaches and posts on Fostodon and memes up the wazoo on various blogs. There there's a lot a lot going on here with the pallet being, you might say, very, you know, unified and pleasant, a rainbow pallet. And his nearest aesthetic that he finds on the Wiki that would correspond to it is and, again, I feel seen when I see this vacation dad core. Apparently, that's full of dad jokes and other visuals that those are kids probably put your kids through embarrassing moments or whatnot. Not that I've ever done that. But, the sample here is gonna look very similar to the sample you saw in the tidy verse sample above, but substituting for the base pipe, substituting for the new data placeholder and the new Lambda function notation.
But guess what? This is monumental, folks, because now, a very important feature in many languages is now in r itself. And who knows what the future holds here? But in any event, it's gonna be a wild time. I'm sure as more companies adopt new and later versions of r and say version 4 dot 1 and up going into production systems depending on your organization. But it is, a fast moving space and who knows what the rest of the future looks like. But, again, I can't stress how monumental it was for the r language to adopt this operator after this many years. It does show that the team is not resting on its laurels. It is definitely keeping up with the time, so to speak.
So it was this was this was a fun fun new take on the evolution of r itself, and, I can't wait to see what's next.
[00:12:24] Mike Thomas:
Yeah. Eric, it's pretty wild that in that last code snippet that uses entirely base r, looks so strikingly similar to the prior code snippet that was using all dplyr, verbs. It's it's pretty incredible, I guess, where we've come, you know. I don't know if this is a cherry picked example totally because, you know, you this works great until you get to a particular base art function that you wanna use that that maybe its first argument, right, isn't necessarily what's being piped into it. I know there's there's some placeholders to help you you get around that, but I do think that that maybe there's potential use cases that the Tidyverse can handle better than what we have access to in Base R, but, you know, there's also use cases here as Matt clearly demonstrates where you can just leverage what's straight out of Base R, and it's it's pretty wild. It's a pretty wild time to be in our developer.
[00:13:23] Eric Nantz:
Yeah. And even at the end of that last snippet, we see hot off the our version 4 dot forward presses the use of sort underscore by. And, again, we'll be very analogous. So we see in dplyr with the arrange function. So you're right, Mike. It is very mind blowing to me that after all these years, we have this capability that I think for those that are new to the language. And again, there will be opinions on this across the spectrum. So just take the Eric's opinion here. But when you look at the readability of this from a person new to the language, outlining all the steps that are happening in the state of manipulation, transformation of new variables, summarizing all that in a group format and calculating these derived statistics.
I know for those coming from other languages, certain ones with proprietary name to it. This syntax is gonna feel more at home than what we saw in the in the good old days. But then again, I still have that old cold for a reason. It's always fun to look back. That's right. And next on our highlights very, hot and much talked about duck DB format for databases and how that compares to what you may have done in the past in tidy verse pipelines within particular, the deep wire package. And this highlight today is coming from Dario Ridicic who is a senior data scientist at Neos, and he's published this on the Epsilon blog talking about how you can take advantage of DuckDV to enhance your data processing pipelines in your ecosystem.
We have we have definitely mentioned DuckDV before, but if you're new to it and in particular, I mentioned being on the podcast in 2 point o show on Friday, I offhandly mentioned duct d b as someone else looking at for some of the podcast database and I, I had, Dave, scratch in his head a little bit. I'm running, oh, I gotta follow-up on this. So, Dave, this is for you. If you and those also that have not heard of DuckDB before, but this is a database system, but there are there are definitely different classes of database systems. One of which is the more traditional, there's a client interacting with a server process somewhere. And this is where if you heard of MariaDB, MySQL, Postgres, sequel and others.
These are very prevalent in the industry, but they often have a pretty heavy footprint, yet they are quite valuable in in the industry sector and other sectors as well. And then you have what are called in process database systems. These are ones that you can run directly on your computer as a file format, so to speak with where the data stored. And then there's some layer in your system is gonna interact with that. And the most historical one that's had the most popularity and still does to this day is SQL light. And that's where you just have to install a compliant front end on your system, have a SQLite database file on your system. And then you're able to read that into your preferred language.
Duck DB is in that same space. So it does share some similarities of sequel light, but there are some interesting differences that may be worth your time to look at as you're thinking about, you know, database evaluations for different formats is that DuckDb is designed for data analysis, and the abbreviation here is OLAP for online analytical processing. This is massive if you're gonna have situations where in your database, it's not just querying for the existence of particular rows or existence of things. It's actually performing analytics on the fly much like we do in the tidyverse pipelines a lot where we're gonna aggregate by groups. Gonna derive mean values or or or medians or other statistics.
And probably have to do that with complex, you know, indexing as well. DuckDV is tailor made for those situations. And so the other selling point of DuckDV these days that it is first completely open source, and that's of course a win for us and the data science community. And it is relatively dependency free, which means that it can be run on a variety of systems and architectures, including web assembly, which is some I'm very intrigued to buy for sure. Now it's not all roses and unicorns. There is some mention of disadvantages for DuckDV.
I think it's more limited depending on your use case here. It's probably not the best for constant writing to the database file. But for most of my needs, I'm not usually writing a lot concurrently like I would say for an IoT device device or other digital device that might be hammering an endpoint multiple times per second. Most of the time in my day job, I'm analyzing these data from source and doing more complex operations. And you're not gonna get, like, the distributor set up like you would with a client server model for, say, postgres or Spark or other ways that you can have a database layer that's networked across multiple nodes on, say, a a VPS provider.
But, again, you're in a different use case already in that point. So and the upper part that is to keep in mind, it is still a fairly new project. They certainly had a lot of progress, but it doesn't have quite the maturity at a sequel light. But with that said, there is a lot of advancements happening in the community here, and I do think DuckDV, especially the integrations, what we can do with web assembly technology and other systems, even as lower scale as a Raspberry Pi, I think are really thought provoking on what you can do with this. But as an r user, you may be thinking yourself, I'm very comfortable with dplyr. What's in it for me to move to DuckDb?
[00:19:48] Mike Thomas:
Yeah. So in this benchmarking that that Damien, puts together here between dplyr and DuckDb. I believe he used, tried to aggregate about 38,000,000 rows that was spread across 12 different parquet files. And if you're not familiar with the parquet file format, we've talked about it a lot on this podcast. It is, in my opinion, sort of the new CSV. It's it's columnar storage that makes analytics, very efficient. It compresses the data in a way that makes your files, these parquet files, much smaller than if you were storing them as something more traditional like a text file or a CSV, but we have plenty of other other links and episodes that that discuss that. So Damon used the, taxi data, the the very famous yellow taxi, the dataset, to be able to create sort of this large 38,000,000 row dataset in 19 columns, that takes a a little less than 1 gig of disk space, I think 630 meg, he said.
And that's, you know, quite large for trying to do some analytics on natively. So one thing that he was able to do with with dplyr was to be able to, create this dplyr pipeline just using, 3 verbs here, 3 or 4 verbs. It looks like mutate, where he's creating a couple different date type columns, the ride date and the ride year, using lubridate to be able to parse those things, from a date time column. He's filtering, for only ride years in the year 2023, And then he he's grouping by these particular dates and taking a look at a few different median statistics, like the median distance, median fair amount, and median tip, as well as the the ride count, which is just a simple count. And he reproduces that same exact logic, using dplyr verbs again, but the second time it's against this this dplyr table connection, that connects via duckdb, the the DB connect, DuckDb driver, against these parquet files. Again, you're able to just have DuckDb sort of sit on top of and interact with these parquet files as opposed to DuckDV, being the database itself. You do have both options similar to SQLite. You can actually create a DuckDV database file if you would like. But you can also just use the DuckDB engine to operate against parquet files, which is what is going on here, and I think is is probably what you'll see more common out there in the wild these days and act in terms of, data storage as opposed to actually storing, you know, your your data itself as the stuck DB database.
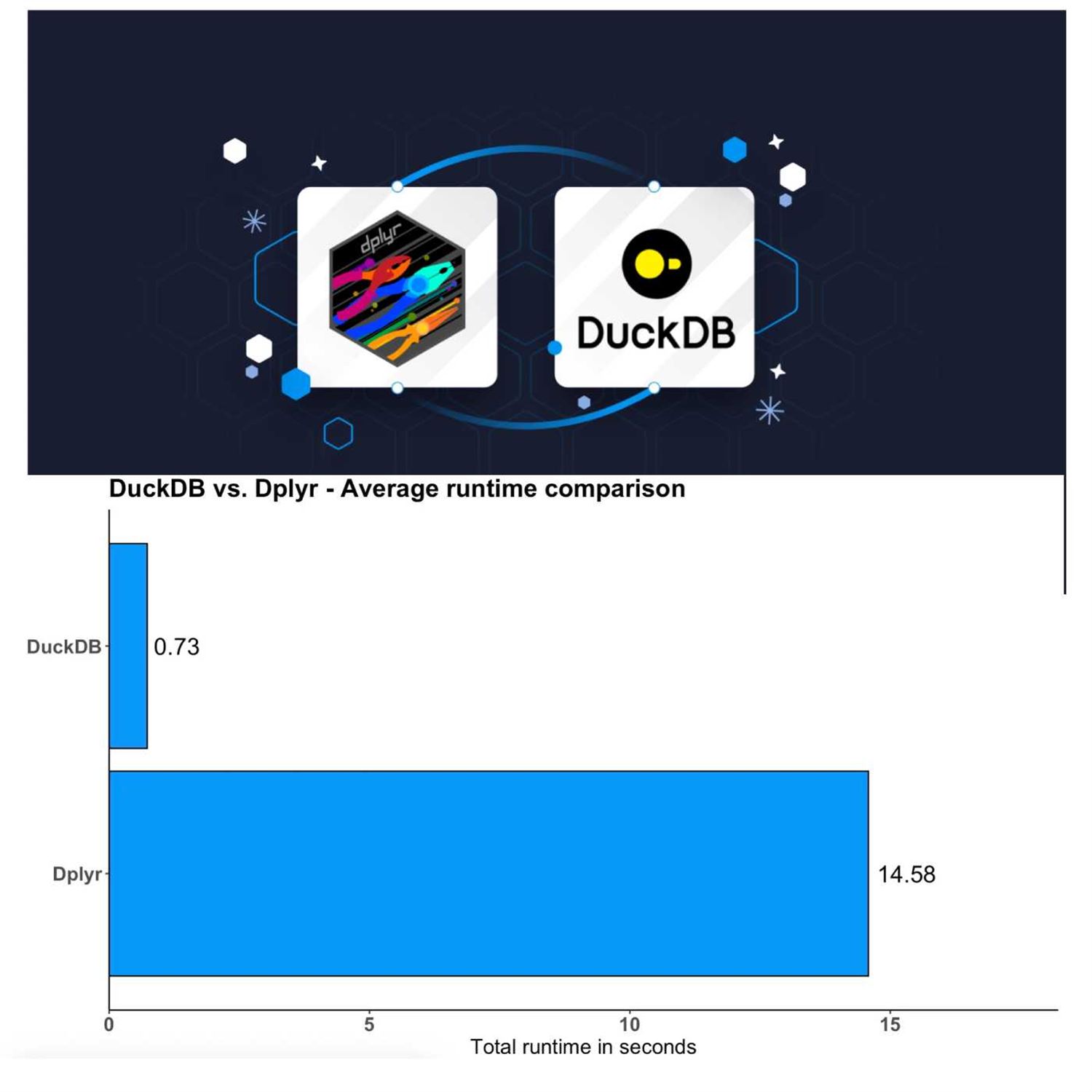
He also demonstrates that you can if you didn't wanna write the dplyr code, you could write, an entire SQL statement that does this exact same thing, within the DB GetQuery function, from the DuckDb, package which would allow you to, you know, express your logic, all the CTL logic in SQL as opposed to dplyr. But now here's sort of the big results here. We're trying to look at this this little dplyr chain and how it performs, in in Raw dplyr as opposed to using the DuckDV engine under the hood. The dplyr approach takes almost 15 seconds to do this aggregation, which results in a data frame that I think is, they're they're showing about 16 different, observations here, 16 rows across these, 4 different, statistical columns that get computed, and then the DuckD b, as opposed to the 15 seconds that it takes in deep prior, the DuckD b approach takes less than one second.
So it's it's pretty incredible. Damien knows that they have, triple checked this statistic and that the numbers are correct, and DuckDb here is almost 20 times faster than dplyr, which is is pretty incredible and right that, you know, a lot of times when especially, you know, in the context of, Eric, a lot of what you and I work on in terms of Shiny apps and trying to make those UXs as seamless, frictionless as possible, you know, moving some of that ETL from something like, you know, raw dplyr or base our code, to leveraging, you know, DuckDB or Arrow can create these these drastic orders of magnitude gains inefficiency that that really make that user experience, tremendously better than it would be otherwise. You're not having to have people, you know, continue to wait around for something to happen for these ETL chains to run.
So this is a great great walk through, great use case. I would also recommend maybe a couple other, functions out there and some pieces of documentation out there. I think there's actually a function from the arrow package called to_duckdv, which allows you to sort of start with an Arrow object, but leverage the DuckDB engine, on top of Arrow to make that pipeline even faster and to allow Arrow and DuckDV to integrate seamlessly together, which is is fantastic. There's also a blog post sort of on that same, vein on the DuckDV website. I just realized it's from from 2021, but it had been, you know, getting shared around on on Twitter recently, which is called DuckDV Quacks Aero, a 0 copy data integration between Apache Arrow and DuckDb. So maybe I can share that in the show notes as well.
But it certainly seems like, you know, this is sort of the way of the future in terms of ETL. It's certainly the way that we're doing a lot of stuff at Catchbook right now for our ETL pipelines, and it's it's making a huge difference for us. So it's a really exciting time to be able to leverage and see all of these, really nice ETL data processing improvements and tools that we have now.
[00:25:40] Eric Nantz:
Yeah. And there was a situation actually came up at at the day job last week when, there was a user that thought that was Deepfire just having really bad performance on a certain situation. And, of course, they tried to get more details because we don't wanna just vague request like that. But, apparently, they were analyzing a 7,000,000 row dataset, which, yeah, if you're just gonna ingest that in native our sessions without a helper like duct DB or even SQL life for that matter, it's going to be a long time to produce aggregations and summaries on that kind of set. And it didn't help that this set was in SaaS format, but that's another story for another day. But in any event, imagine if that dataset is getting split up into parquet files or intelligently by groups, And then you take the same kind of code that was demonstrated by Damien over here and to be able to run that very efficiently or Dario should back. Try that again. And imagine if you take the same code that Dario puts together in this post with those parquet files again, like you said, correct me. My I feel is that the new CSV, There's a reason I linked to those as extract downloads in my podcast index dashboard. I didn't wanna do CSVs anymore trying to push this as the other communities as well to look into this. But you are gonna get tremendous gains in these situations with with DuckDV on the back end. And one addendum that I would be interested in trying on, maybe I will when I get some spare moments, is it was, what, a week or 2 ago on this very podcast, we had covered the release of the Duck plier package, which again is a very similar vein to what Duck DB package itself is doing here, but it is a even more of a direct one to one replacement for dplyr.
It is still newer, so we're keeping an eye on its development. But you could probably leverage the majority of that same code into a duct flyer pipeline, and I would venture to say you're gonna get those same performance benchmarks because it's all Duck DB under the hood anyway. But we'll definitely have a link to Duck plier as an additional thing to explore here. But I see, again, massive potential in the spaces that you and I operate on in both of my day job efforts. But now, as I mentioned in my open source efforts of this podcast database, my portal dashboard kind of takes a quote unquote easy way out where I've through GitHub actions, I'm doing all the processing outside the dashboard and the dashboard is simply referencing them directly via RDS files that are being downloaded on the fly.
I am waiting for the day where I can swift flip that up to do web assembly, DuckDV in inside that, and then I can do the real time querying, so to speak, in that dashboard as a Shiny Live app instead. It's coming, Mike. It's coming. I just need the time to do it.
[00:28:44] Mike Thomas:
And speaking of WebAssembly, we have one last highlight to wrap up the week that I think might just be on that topic.
[00:28:51] Eric Nantz:
So, yeah, it's not only on that topic. It is literally in my same industry about ways that I've been envisioning for ever since I've heard about this technology, where I think the potential is, and we are seeing that here. And in particular, this last highlight is coming from the pharmaverse blog and authored by Paolo Rucci, who is a data scientist developer at Roche. And for those unfamiliar, the pharma verse, if you're in the r community, you've like you heard of things like the tidy verse and whatnot. Well, this is a collection of packages that are helping make clinical pipeline analyses, data processing that we routinely do in life sciences much easier to do in the our ecosystem as ours now taking a much, stronger footprint in the life sciences industry.
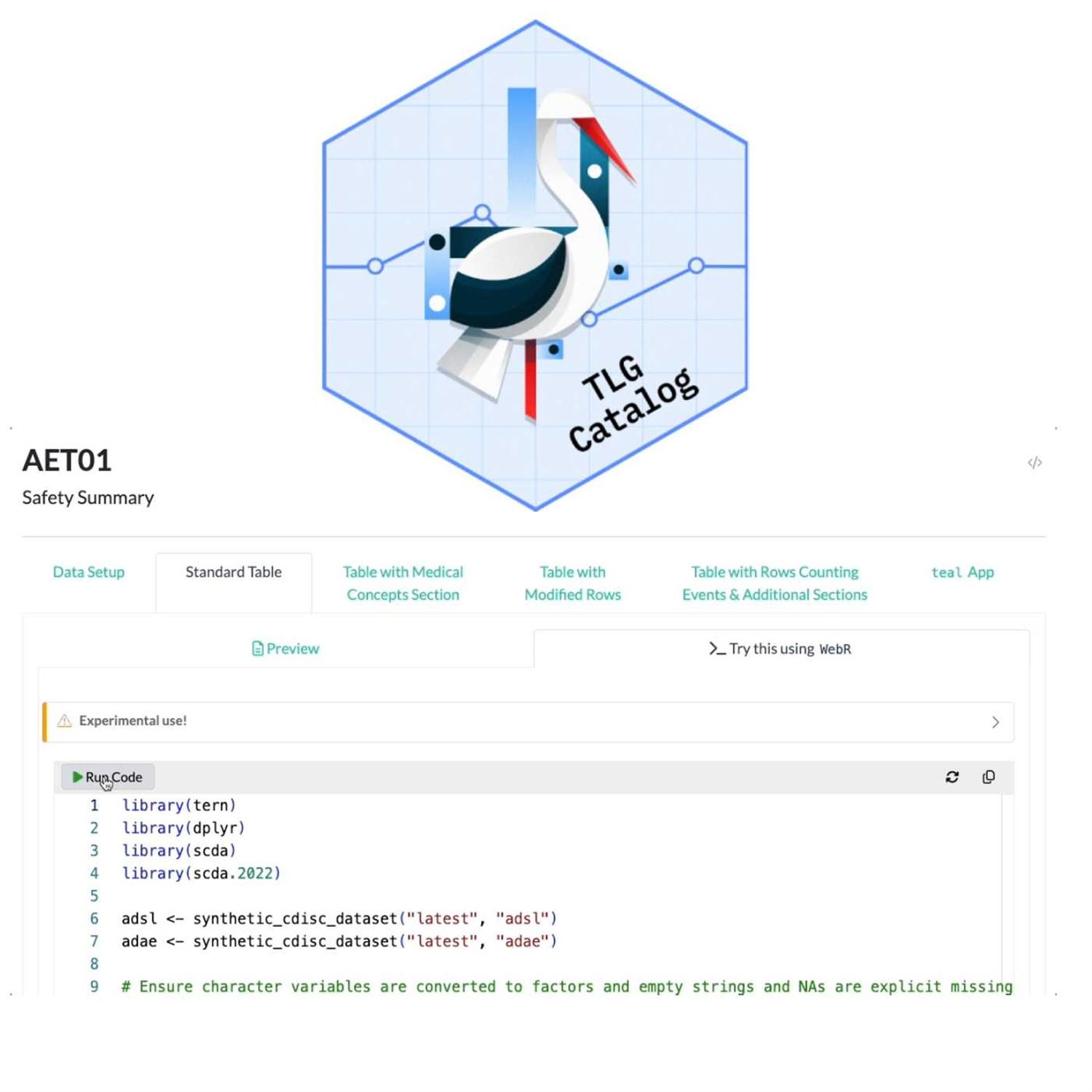
Well, one of the suites of packages and the pharma versus, you know, getting popular is the nest packages and others to help produce what one might consider the backbone of what we call a clinical submission to regulators for a given study, and that is the production of tables, listings, or graphs or TLGs for short. Traditionally, these have been done in a certain proprietary language, but that's not we're gonna talk about here because r has made tremendous strides in this space. And as a way to get new users or to show off the potential of what's possible with the pharmaverse in this in this, part of the pipeline, The pharmaverse has produced for a while now the TLG catalog, which has been a snippet for the common table listings and graph types that we often do in submissions, but with the r code to actually produce those and a snapshot of the output.
Well, what, Paulo was talking about in this post is they have now integrated WebR, hence WebAssembly, into this portal site to not only show the code, but to let the users run the code themselves, change things on the fly, experiment with the existing syntax. My goodness. This is just a massive win for learning in this space. I am geeked out about this already. They had me there, but as the game shows will say, but wait, there's more because another popular part of the pharmaverse has been the teal framework, which is a way to bring interactive data exploration with these common summaries into a Shiny application with a set of reusable modules and packages to help with different analytical types, different parts of the processing, but teal is a great way to ingest these clinical data for review in your given systems to explore for new insights and whatnot.
Well, guess what? With the advent of shiny live, Powell is also plugged in a way to run a teal application tailor made for each of these table summaries inside that same website, folks. This is massive. I cannot underscore how enthusiastic I am about this because think of the doors this is opening. Right? Is that there will be, many in life sciences that are new or newish to our for a lot of these clinical analyses. Anything, and I mean anything we can do to make this easier for them to transition, we need to take that and run with it as fast as we possibly can. This TLG catalog, I think, is amazing first step in this vision. So I whoever you're in the pharma industry or not, just take the ideas from this. Think about how this could be used in your use cases for whether you're teaching new users of r or you're trying to demonstrate to your leaders what is possible when you mirror the technologies of open source and web assembly together. This t o g catalog is a massive vision. I or a demonstration of this vision that I think can be applicable to many people. And, yeah, when I saw this, I'm like, I'm IMing some people at work. I'm like, you need to see this folks. This is amazing. So I'm definitely gonna be pursuing this very closely. But, again, what an excellent showcase of WebAssembly, quarto, and the pharmaverse all in one place. Absolutely massive, Mike. Can you tell I'm excited?
[00:33:15] Mike Thomas:
I can tell you're excited, and it's hard to do it all justice, on audio format, but there's some great gifts as well that Pavel has, included and implemented into this blog post that really demonstrate exactly what's going on. And I don't know if the users sort of caught it, Eric, but what this means and what's being showcased here is not only the ability to create this this sort of shiny app, right, using web assembly and web are sort of in the browser, But also allowing users to be able to edit the source code for this app and actually change the underlying, you know, structure of this app within the browser itself, and actually see the changes in that app underneath the code immediately, which is fantastic.
No needing to install any dependencies on your machine. You don't even need to have R installed or Rstudio installed. This is all taking place in the browser, which is is absolutely incredible. I think, you know, again, it it just lends itself to, less friction for those trying to get started with our easy learning, the language language and adoption of the language. Hopefully, for those coming from from different languages to be able to to get started and and go from sort of 0 to 1 with the only requirement being an internet connection that they need, which is really incredible.
The other thing that I would say is, you know, what this this whole, sort of WebR framework and WebAssembly framework where it has sort of my head spinning now at this point which is something that we talked about, I think, on recent episodes but I don't think it is quite fully implemented yet is the idea for, you know, packages that we develop and these pack beautiful package downsides that we create with them, for the examples that we have for the different functions, in the reference section of our packages to be able to to actually be run-in the browser instead of users having to install that package and run those examples, you know, within their own our session.
What I saw recently, and I can't remember if it's the most recent version of quarto that got released or if it's the most recent version of our that got released that had these capabilities, but you can now use quarto or QMD files to create package vignettes, which is probably sounds like a very subtle thing, but my hope is that now that we're able to to leverage quarto for authoring, packaged vignettes which I'm super excited to move to just because I love quarto. My hope is that maybe that leads the way or blazes the trail for the integration of of WebR into these vignettes as well backed by maybe the shiny live quarto extension and allowing us the ability to to do what I just described So, you know, like you said, Eric, and like we've brainstormed, the possibilities here are endless with all these advancements in in WebR and WebAssembly.
And you and I I'm not sure if you had met him before but but at least I was fortunate enough to meet Pavel at, Shiny Conf last year and and maybe he'll be there again this year, but, a brilliant data scientist and a very, very well done blog post from him and a great way to wrap up the week.
[00:36:36] Eric Nantz:
Yeah. We we were able to connect as well at that same conference, and I've I've you know, I've had multiple conversations thinking about potential of this new technology, and that's why I'm so excited to be part of this space right now with my, our consortium effort with that pilot, Shiny app submission and WebAssembly. I think we're on to something here and, that that indeed what you mentioned with quarto, it is in as of quarto version 1.4 is indeed the version Atlanta support for package vignettes, and I cannot wait to try that. Even if it's a internal package, if I can pull that off, yes, that again is a massive win for learning.
Even as something as I'm gonna call trivial, it's not so trivial. I have an internal package to import SAS data sets into our bet backed by Haven, but with little syntactic stuff on top. Imagine just having a a a vignette powered by quartile to help demonstrate what that code looks like and some of the post processing functions I have in store. But, yes, I think in in our industry, we we are ready to embrace technology like this. Admittedly, we still have a long ways to go to see where this impacts, like, actual submission pieces, hence what I'm exploring in this pilot.
But when you put this in front of people, I don't know how you can't be excited about the potential of this. And like I said, no matter what industry you're in, I hope you take some inspiration from parts of this because this is this is the time to try things out. I think this is that evolution in history that we're gonna look back on maybe 5, 10 years down the road and wonder how did we live without this.
[00:38:16] Mike Thomas:
I hear you. I agree.
[00:38:19] Eric Nantz:
You know what else is hard to live about is our weekly itself. Right? I mean, if our week had been around when I was learning our oh, I would have learned so much faster. But we can't turn back time. But at least you can start with the present and check out the rest of the issue that Sam has put together of more excellent resources. So it'll take a couple of minutes for our additional finds here. And, yes, I am very, you know, much a fan of the web assembly frame, but I haven't forgotten about my explorations with container environments. And that's where this another mind blowing moment for me from this issue is that James Balamuda, who goes by the cultless professor on the various social handles, he has been the pioneer of that web r extension for quartile and whatnot, but he has put a spectacular demonstration on his GitHub organ profile here that has a, custom dev container setup, which for those aren't aware of dev containers are a way for you to bootstrap a container environment in versus code or get hub code spaces.
And he's got one that's actually 2 of them that are tailor made for both building portal documents and with newer extensions such as the web r extension and the pile died extension if you're doing Python based, web assembly products. But also these dev container features have one that works in the traditional GitHub code space, which will look like Versus code in your browser. Again, you as a user don't have to install anything with this on your system. It's all in the cloud. And wait for it. There is a dev container feature for Rstudio server.
Let me say that again. There is a dev container feature for Rstudio server. If you recall maybe a year or so ago, I was exploring my workflow for these dev container environments for all my our projects, and I would spin up RStudio container via custom Docker file. And I would, okay, get from the rocker project, add these dependencies, add these packages and whatnot. And, yeah, it quote, unquote works, but it is a bit of, manual setup nonetheless, even if you clone my repo. Oh my goodness. Do you know how much easier this is now with just one line in that devcontainer JSON file he can have in our studio environment in the browser, not on your system, all powered by the GitHub Codespaces.
Oh my goodness. I am playing with this as soon as I can.
[00:40:54] Mike Thomas:
That is super exciting, Eric. I can't wait to play with it as well. You you know, I I don't need to say it again that I have been bitten, hard by the dev container bug, and we do all projects now on our team, within dev container environments just makes collaboration and and sharing that much easier. So this is a great great blog post, touching on that subject again. I can't get enough of that content, so that's a great shout out as well. Another thing that we do a lot of, so this spoke to me quite a bit, was that there is a new release of ShinyProxy, version 3.one.0.
And for those who aren't familiar, ShinyProxy is a platform for hosting Shiny applications. It's it's clear fully open source, but you you host these Shiny applications, heavily via Docker such that each user, when they click on an app on your your ShinyProxy platform, it spins up a separate Docker container for that user, and that allows you to to leverage things like Kubernetes fairly easily, and it does allow for some, you know, additional security. You're able to deploy your Shiny apps, as as Docker images, which is is really nice in terms of reproducibility as well. But, you know, ShinyProxy is something that that we leverage pretty heavily both internally and for our clients. This was exciting to me and I know that there's some other folks out there that, leverage this project as well as it's it's one of, the the multiple Shiny hosting options that you could have. And the new features in ShinyProxy, 3.1 are, as opposed to what I just said, you know, when a user clicks on an app, it spins up a a brand new separate container for them. In 3.1.0, we have the option for some pre initialization of that container or sharing of that container across multiple users. So, sometimes when a Docker container sort of is is spinning up depending on how large that image is, it can take some time to spin up and users may have to wait, you know, 5, 10, 15 seconds, something like that, for that container to spin up and for them to actually be able to see their application. So 3.1.0 provides some opportunities for pre initialization of those containers and actually sharing, containers across users such that an already running container can be leveraged, by a second user.
The other, big update is that, you know, up to now, ShinyProxy supported 3 different container back ends. That was Docker, Docker Swarm, and Kubernetes. Now there is a brand new back end, AWS ECS, which is pretty exciting. I think AWS ECS, allows you to or or maybe, they take care of some of the server setup, and scaling that you might have to have rolled your own, if you're using Docker, Docker Swarm, or Kubernetes. So it's nice that that abstracts it away from you. But as Peter Salomos notes in his, hosting data apps blog that that recaps this 3.1. O release. You know, one downside of of AWS ECS is that in most cases, it takes more time to start the container compared to other back ends. But now that we do have this this pre initialization and container sharing capabilities in 3.1.0, we might be able to reduce that startup time to something that's that's even less than a second, if we are able to take advantage of those new features. So, there's some additional stuff in there, but but really exciting, for myself and maybe those others in the community that that leverage ShinyProxy.
[00:44:28] Eric Nantz:
Yeah. These are fantastic updates, and I can underscore the importance of that pre initialization feature because sometimes with whoever you're, you know, sending this to, you might have to, have to think about, okay, what are the best ways to enhance user experience. Right? And loading times is unfortunately one of them for better or worse. So be able to have that ready on the fly, I think, is massive. And for all the DevOps engineers out there that may have been, you know, what we call an r admin that's administering shiny proxy or maybe working with IT to support that. What I really appreciate, as you mentioned, Mike, with the ECS, you know, new back end implemented, If you're wondering how that might fit for some of the automation, like deployment pipelines, they linked to in this post a, a repo that has an example for Terraform, which is a very popular dev ops, you know, system configuration platform for automation. So I I I have a few HPC admins in my day job that would appreciate seeing that because that's Terraform all the things with Chef. So this might be something that if we do shiny proxy in the future, I'll be sending this their way. But, yeah, really, really exciting to see these updates for sure.
[00:45:43] Mike Thomas:
I have somebody on my team who's big into Terraform. It's not something that I've stepped into yet, but it seems pretty awesome for sort of just writing maybe kind of like a a Docker file of your pipeline in terms of your entire setup. You know it's fairly easy to read, easy ish to read, and it's sort of just listing out the instructions of the infrastructure that you wanna set up. It's pretty cool.
[00:46:06] Eric Nantz:
Yeah. There's a lot in this space that I've been, you know, trying to learn up on on my time. I've gone kinda far, but I've been learning up on Chef and Ansible and a little bit of Terraform, but, there's only so much time in the day. But, nonetheless, there is so much more we could talk about in this issue, but we would be here all day if we did. So we'll just invite you to check out the rest of the issue at rnp.org along with all the other resources that we mentioned in this episode as well. It's all gonna be in the show notes. And by the way, if you are listening to this show on one of those more modern podcast apps like pavers or found, you may have noticed we've actually upped the production quality to show quite a bit where now you get not only the chapters, which we've always done, we've got chapter image, images that will directly link to each of the highlights that we talk about. So I think that's pretty cool if you're taking advantage of the modern tooling here and also a big win for accessibility, each episode now has a transcript directly generated into the show, which, ironically, even Apple has adopted recently. So you should be able to get that in many of the podcast apps that you listen to this very show. And, we love hearing from you and the audience as well. But, of course, the art weekly project itself goes with the community. It's powered by the community.
So if you see a great resource you wanna share with the rest of the art community, we're just a pull request away. It's all at rwiki.org and click in the upper right for that little GitHub icon, and you'll be taken to the next week's issue draft where you can put in your link. And our curator of the week will be glad to merge that in after a review. And, also, we'd love to hear from you as well directly. There are many ways to do that. The fun way, of course, is if you're on one of those aforementioned podcast app, you can send us a fun little boost along the way, and we'll be able to read it directly on the show. And, it was fun to be on the Friday show because I I did get a few boosts sent my way because I was part of what they called the valued split at that point for that segment. So lots of fun shout outs about the r language and whatnot and are nerding out on that side of it. But, also, you can contact us on the various social media handles.
I am mostly on Mastodon these days with at our podcast at podcast index dot social. I'm also sporadically on x Twitter, whatever you wanna call it, with at the r cast and also on LinkedIn. Just search for my name, Eric Nance, and you will find me there. Mike, where can the listeners get a hold of you? Sure. You can find me on mastodon@[email protected].
[00:48:38] Mike Thomas:
If you search for my name on LinkedIn, you will probably find way too many Mike Thomases and not be able to find me. So, you can see what I'm up to if you search Catchbrook Analytics instead. That's ketchb r o o k.
[00:48:53] Eric Nantz:
Very nice. And, yeah. That will wrap up the episode 100 and 65. We had lots of fun talking about these highlights of all of you, and we definitely invite you to come back again next week to hear us talk about yet more our community goodness of our weekly. So until then, happy rest of your day wherever you are, and we will see you right back here next week.
Hello, friends. We're back of episode 165 of the our weekly highlights podcast. If you're new to the show, this is the weekly podcast where we talk about the latest resources, innovations that we're seeing in the our community as documented in this week's our weekly issue. My name is Eric Nantz, and I'm delighted you join us wherever you are around the world and wherever you're listening to. And as always, I never do this alone. We're in the middle of May already. Time goes by fast, but I'm joined by my cohost,
[00:00:32] Mike Thomas:
Mike Thomas. Mike, where's the time gone, man? It's crazy. I don't know. It is crazy. And, yeah, we gotta do the stats on how many episodes we're at together now at this point, Eric, but it's it's gotta be a lot.
[00:00:44] Eric Nantz:
That's right. And now would never feel the same without you as is, I was thinking that you're sick of me. Not quite. Not quite. Not yet. You ought to you ought to give me more rants before that happens. But in any event, yep, we have a lot of great content to talk about. Before we get into the meat of it, I do wanna give a huge thank you to the, pod father himself, Adam Curry, and the pod stage, Dave Jones for having me on this past week's episode of podcasting 2.0, where I was able to geek out with them and, or as the chat was saying, nerd out, the, our language itself and the use of our end quartile to produce this fancy podcast index database dashboard. That was apparently more of a reality check than what Dave was expecting in terms of data quality of the podcast index database. But it was a ton of fun, And, apparently I've given him some things to follow-up on, which we may be touching on in one of our highlights here. But again, thanks to them for having me on, and I've been anointed the podcasting 2 point o data scientist. So I'm gonna take that and run with it. Pretty cool. Add that to your CV, Eric. I'm super stoked to listen to that episode. Today, I got a long car ride this afternoon and I will be tuning in. So,
[00:02:01] Mike Thomas:
very very excited to to hear about that.
[00:02:04] Eric Nantz:
Yes. And I'm actually gonna make sharing that even more efficient in this episode show notes. I will have a link not just to the episode itself, but to an actual clip of the episode with my segment on it. Again, one of these great features you can give in podcasting 2.0. So that's just a tip of the iceberg or some of the things that dev community is up to. But, nonetheless, we got some great art content to talk about here and our curator this week's for this week's issue was Sam Palmer, another great contributor we have in our our weekly team. And as always, he had tremendous help from our fellow our weekly team members world with your awesome poll requests and suggestions.
And, Mike, we're gonna I guess guess this first high is gonna be a kind of a trip down memory lane, but I'll be at a visual aspect of it in ways I totally did not expect until we did research for this show. Oh, yeah. Exactly. So our first highlight today is coming from the esteemed Matt Dre who has been a frequent contributor to our weekly and past issues. And in particular, he's been inspired by a resource that admittedly little old me did not know about until now, but is called the aesthetics Wiki, which in a nutshell, what this is is a Wiki portal, but it's a very visually themed Wiki portal where it's got a collection of images, colors, links to musics and videos that help give you a vibe, if you will, of a specific maybe time period or a specific feeling in mind. And I met when I looked at this and I was going coming through some of the, you you know, the top Wiki pages, there was one about the y two ks issue from way back. And, I could I could definitely got the memory triangle. I'm looking at that Wiki portal, but I'm also getting vibes. And so this is gonna date myself quite a bit, so bear with me here. But, yeah, I had cable TV growing up and one of the, guilty pleasures I had was on VH one watching the I love the eighties, and I love the nineties series because it was such a fun trip down memory lane for each of those years of those decades. And I will still stand on my soapbox here. And at the eighties nineties were the golden age of video games, so take that for what it's worth. But in any event, I I definitely got those same vibes here. And apparently, Matt was inspired to think, you know what? On this Wiki, there's something missing.
It's the R language, of course. What could we do to visually depict certain, I would say, major stages in the evolution of our, for respect to this kind of theme on the aesthetics Wiki. So I'm gonna lead off with probably the most appropriate given yours truly is the old timer on this show with the first period that Matt draws upon is called base core. And the picture on the blog post definitely, gives you some vibes of there's a lot going on under the hood with our, but it's, you know, kinda scattered around. It it's it's got a lot happening. And he talks about some of the bullet points that inspired the imaging here because of if you know your our history, it actually came in the mid nineties.
It was derived from the s language and then to our from Rasa Hakka and Robert gentleman and then base core as we know it was founded in the year 2000. And if you have old r code laying around from that time period, I eventually gonna have 3 major operators in there one way shape or form. Bracket notation for referencing rows or variables, dollar signs for referencing variables inside a data frame, and the tilde's for your linear regression model fits and whatnot. He also mentions that if he was gonna put this Wiki together, he would have a link to the, writing our extensions PDF, which I've combed through a few times in my early career, but it's, not for the faint of heart if you're if you're new to the world on that.
But, yeah, the the the vibe of it is very, you might say, utilitarian, kind of mundane a little bit here and there, but the potential is there. So I really like what he put together there. And of course, in the in the blog post, it's in our post after all. He's got a code snippet that looks straight out of my early r classes and graduate school where you've got the assignment operator referencing rows with the double equal sign in the brackets, the dollar sign for referencing variable names and FL's aggregate, you know, bay from base are, and then finally ordering it by height. In this case, it's a data set of star wars worlds and characters. And in the end, you get a nice data frame of the average heights for those living in Tatooine or Naboo and others.
So I feel seen when I see that because if I look back in my old land drive here in the basement, I have lots of code that looks just like this. But our many other developments have happened. And the next period that Matt talks about will be something that I think will look pretty familiar to most users now. He calls it the tidy wave, Mike, and I would say it's anything but mundane.
[00:07:28] Mike Thomas:
Yes. No, Eric. That was a great trip down, you know, the the late nineties, early 2000 of our the aesthetic or the fashion, that Matt matches to the the base core, time period is cardigans and a wired mouse with a ball in it. Man, if that doesn't sum up base score, I don't know what does. But on to the Tidy Wave as you'd say, he he talks about the history sort of starting in 2,008 and then later being popularized, mostly through the Tidyverse, sort of wrapping up a lot of, this different tidy functionality in 2016 when that was originally released.
The key visuals here are the mcgritter pipe, the data placeholder as a period or a dot, and then the tilde, not being used for formulas but being used for Lambda functions in this iteration here. The fashion choices are Rstudio, hex stickers, and rapid deprecation.
[00:08:33] Eric Nantz:
Where did you get that idea from?
[00:08:36] Mike Thomas:
Every package is experimental. I feel feel like, you know, with the the little badge that it has, during this particular time period, but a lot of fun. Right? Absolutely. And you can see that the code snippet that we have here is leveraging a lot of dplyr verbs like filter, select, left join, mutate, summarize, and arrange. And the code arguably is a little easier to understand what's going on from from top to bottom and left to right. Looks a little more SQL ish than what you got in the base core, time period. And that brings us to this last new period, Eric, which Matt is calling v4punk.
[00:09:17] Eric Nantz:
I love this because this is one of those situations where we are seeing another big evolution, but it's so fresh. May not fully grasp it yet. But the visuals of this have big roots into one of the most major developments in the our language itself of the last few years. And that is the introduction of the base pipe operator, which, again, one could argue that the tidy verse popularity you just summarized was a direct influence on this feature coming in alongside other languages having similar mechanisms. And in 2022, it was released fully, in support of our the the base pipe. So that is, of course, one of the key visuals here along with the underscore, which is not just for variable name separations between words, but as a data placeholder, similar to what you mentioned earlier with the period and the and the previous summary and a new notation for Lambda functions, which, admittedly, I'm still wrapping my head around, but it's the slash with the parenthesis afterwards. I admit, Mike, I have not actually written that one out yet. You're gonna have to pull the tilde for lambda functions out of my cold hands, so to speak, but I am warming up to it. It's just taking a while.
So the fashion here is this one's really funny. It's, you might call evil mustaches and posts on Fostodon and memes up the wazoo on various blogs. There there's a lot a lot going on here with the pallet being, you might say, very, you know, unified and pleasant, a rainbow pallet. And his nearest aesthetic that he finds on the Wiki that would correspond to it is and, again, I feel seen when I see this vacation dad core. Apparently, that's full of dad jokes and other visuals that those are kids probably put your kids through embarrassing moments or whatnot. Not that I've ever done that. But, the sample here is gonna look very similar to the sample you saw in the tidy verse sample above, but substituting for the base pipe, substituting for the new data placeholder and the new Lambda function notation.
But guess what? This is monumental, folks, because now, a very important feature in many languages is now in r itself. And who knows what the future holds here? But in any event, it's gonna be a wild time. I'm sure as more companies adopt new and later versions of r and say version 4 dot 1 and up going into production systems depending on your organization. But it is, a fast moving space and who knows what the rest of the future looks like. But, again, I can't stress how monumental it was for the r language to adopt this operator after this many years. It does show that the team is not resting on its laurels. It is definitely keeping up with the time, so to speak.
So it was this was this was a fun fun new take on the evolution of r itself, and, I can't wait to see what's next.
[00:12:24] Mike Thomas:
Yeah. Eric, it's pretty wild that in that last code snippet that uses entirely base r, looks so strikingly similar to the prior code snippet that was using all dplyr, verbs. It's it's pretty incredible, I guess, where we've come, you know. I don't know if this is a cherry picked example totally because, you know, you this works great until you get to a particular base art function that you wanna use that that maybe its first argument, right, isn't necessarily what's being piped into it. I know there's there's some placeholders to help you you get around that, but I do think that that maybe there's potential use cases that the Tidyverse can handle better than what we have access to in Base R, but, you know, there's also use cases here as Matt clearly demonstrates where you can just leverage what's straight out of Base R, and it's it's pretty wild. It's a pretty wild time to be in our developer.
[00:13:23] Eric Nantz:
Yeah. And even at the end of that last snippet, we see hot off the our version 4 dot forward presses the use of sort underscore by. And, again, we'll be very analogous. So we see in dplyr with the arrange function. So you're right, Mike. It is very mind blowing to me that after all these years, we have this capability that I think for those that are new to the language. And again, there will be opinions on this across the spectrum. So just take the Eric's opinion here. But when you look at the readability of this from a person new to the language, outlining all the steps that are happening in the state of manipulation, transformation of new variables, summarizing all that in a group format and calculating these derived statistics.
I know for those coming from other languages, certain ones with proprietary name to it. This syntax is gonna feel more at home than what we saw in the in the good old days. But then again, I still have that old cold for a reason. It's always fun to look back. That's right. And next on our highlights very, hot and much talked about duck DB format for databases and how that compares to what you may have done in the past in tidy verse pipelines within particular, the deep wire package. And this highlight today is coming from Dario Ridicic who is a senior data scientist at Neos, and he's published this on the Epsilon blog talking about how you can take advantage of DuckDV to enhance your data processing pipelines in your ecosystem.
We have we have definitely mentioned DuckDV before, but if you're new to it and in particular, I mentioned being on the podcast in 2 point o show on Friday, I offhandly mentioned duct d b as someone else looking at for some of the podcast database and I, I had, Dave, scratch in his head a little bit. I'm running, oh, I gotta follow-up on this. So, Dave, this is for you. If you and those also that have not heard of DuckDB before, but this is a database system, but there are there are definitely different classes of database systems. One of which is the more traditional, there's a client interacting with a server process somewhere. And this is where if you heard of MariaDB, MySQL, Postgres, sequel and others.
These are very prevalent in the industry, but they often have a pretty heavy footprint, yet they are quite valuable in in the industry sector and other sectors as well. And then you have what are called in process database systems. These are ones that you can run directly on your computer as a file format, so to speak with where the data stored. And then there's some layer in your system is gonna interact with that. And the most historical one that's had the most popularity and still does to this day is SQL light. And that's where you just have to install a compliant front end on your system, have a SQLite database file on your system. And then you're able to read that into your preferred language.
Duck DB is in that same space. So it does share some similarities of sequel light, but there are some interesting differences that may be worth your time to look at as you're thinking about, you know, database evaluations for different formats is that DuckDb is designed for data analysis, and the abbreviation here is OLAP for online analytical processing. This is massive if you're gonna have situations where in your database, it's not just querying for the existence of particular rows or existence of things. It's actually performing analytics on the fly much like we do in the tidyverse pipelines a lot where we're gonna aggregate by groups. Gonna derive mean values or or or medians or other statistics.
And probably have to do that with complex, you know, indexing as well. DuckDV is tailor made for those situations. And so the other selling point of DuckDV these days that it is first completely open source, and that's of course a win for us and the data science community. And it is relatively dependency free, which means that it can be run on a variety of systems and architectures, including web assembly, which is some I'm very intrigued to buy for sure. Now it's not all roses and unicorns. There is some mention of disadvantages for DuckDV.
I think it's more limited depending on your use case here. It's probably not the best for constant writing to the database file. But for most of my needs, I'm not usually writing a lot concurrently like I would say for an IoT device device or other digital device that might be hammering an endpoint multiple times per second. Most of the time in my day job, I'm analyzing these data from source and doing more complex operations. And you're not gonna get, like, the distributor set up like you would with a client server model for, say, postgres or Spark or other ways that you can have a database layer that's networked across multiple nodes on, say, a a VPS provider.
But, again, you're in a different use case already in that point. So and the upper part that is to keep in mind, it is still a fairly new project. They certainly had a lot of progress, but it doesn't have quite the maturity at a sequel light. But with that said, there is a lot of advancements happening in the community here, and I do think DuckDV, especially the integrations, what we can do with web assembly technology and other systems, even as lower scale as a Raspberry Pi, I think are really thought provoking on what you can do with this. But as an r user, you may be thinking yourself, I'm very comfortable with dplyr. What's in it for me to move to DuckDb?
[00:19:48] Mike Thomas:
Yeah. So in this benchmarking that that Damien, puts together here between dplyr and DuckDb. I believe he used, tried to aggregate about 38,000,000 rows that was spread across 12 different parquet files. And if you're not familiar with the parquet file format, we've talked about it a lot on this podcast. It is, in my opinion, sort of the new CSV. It's it's columnar storage that makes analytics, very efficient. It compresses the data in a way that makes your files, these parquet files, much smaller than if you were storing them as something more traditional like a text file or a CSV, but we have plenty of other other links and episodes that that discuss that. So Damon used the, taxi data, the the very famous yellow taxi, the dataset, to be able to create sort of this large 38,000,000 row dataset in 19 columns, that takes a a little less than 1 gig of disk space, I think 630 meg, he said.
And that's, you know, quite large for trying to do some analytics on natively. So one thing that he was able to do with with dplyr was to be able to, create this dplyr pipeline just using, 3 verbs here, 3 or 4 verbs. It looks like mutate, where he's creating a couple different date type columns, the ride date and the ride year, using lubridate to be able to parse those things, from a date time column. He's filtering, for only ride years in the year 2023, And then he he's grouping by these particular dates and taking a look at a few different median statistics, like the median distance, median fair amount, and median tip, as well as the the ride count, which is just a simple count. And he reproduces that same exact logic, using dplyr verbs again, but the second time it's against this this dplyr table connection, that connects via duckdb, the the DB connect, DuckDb driver, against these parquet files. Again, you're able to just have DuckDb sort of sit on top of and interact with these parquet files as opposed to DuckDV, being the database itself. You do have both options similar to SQLite. You can actually create a DuckDV database file if you would like. But you can also just use the DuckDB engine to operate against parquet files, which is what is going on here, and I think is is probably what you'll see more common out there in the wild these days and act in terms of, data storage as opposed to actually storing, you know, your your data itself as the stuck DB database.
He also demonstrates that you can if you didn't wanna write the dplyr code, you could write, an entire SQL statement that does this exact same thing, within the DB GetQuery function, from the DuckDb, package which would allow you to, you know, express your logic, all the CTL logic in SQL as opposed to dplyr. But now here's sort of the big results here. We're trying to look at this this little dplyr chain and how it performs, in in Raw dplyr as opposed to using the DuckDV engine under the hood. The dplyr approach takes almost 15 seconds to do this aggregation, which results in a data frame that I think is, they're they're showing about 16 different, observations here, 16 rows across these, 4 different, statistical columns that get computed, and then the DuckD b, as opposed to the 15 seconds that it takes in deep prior, the DuckD b approach takes less than one second.
So it's it's pretty incredible. Damien knows that they have, triple checked this statistic and that the numbers are correct, and DuckDb here is almost 20 times faster than dplyr, which is is pretty incredible and right that, you know, a lot of times when especially, you know, in the context of, Eric, a lot of what you and I work on in terms of Shiny apps and trying to make those UXs as seamless, frictionless as possible, you know, moving some of that ETL from something like, you know, raw dplyr or base our code, to leveraging, you know, DuckDB or Arrow can create these these drastic orders of magnitude gains inefficiency that that really make that user experience, tremendously better than it would be otherwise. You're not having to have people, you know, continue to wait around for something to happen for these ETL chains to run.
So this is a great great walk through, great use case. I would also recommend maybe a couple other, functions out there and some pieces of documentation out there. I think there's actually a function from the arrow package called to_duckdv, which allows you to sort of start with an Arrow object, but leverage the DuckDB engine, on top of Arrow to make that pipeline even faster and to allow Arrow and DuckDV to integrate seamlessly together, which is is fantastic. There's also a blog post sort of on that same, vein on the DuckDV website. I just realized it's from from 2021, but it had been, you know, getting shared around on on Twitter recently, which is called DuckDV Quacks Aero, a 0 copy data integration between Apache Arrow and DuckDb. So maybe I can share that in the show notes as well.
But it certainly seems like, you know, this is sort of the way of the future in terms of ETL. It's certainly the way that we're doing a lot of stuff at Catchbook right now for our ETL pipelines, and it's it's making a huge difference for us. So it's a really exciting time to be able to leverage and see all of these, really nice ETL data processing improvements and tools that we have now.
[00:25:40] Eric Nantz:
Yeah. And there was a situation actually came up at at the day job last week when, there was a user that thought that was Deepfire just having really bad performance on a certain situation. And, of course, they tried to get more details because we don't wanna just vague request like that. But, apparently, they were analyzing a 7,000,000 row dataset, which, yeah, if you're just gonna ingest that in native our sessions without a helper like duct DB or even SQL life for that matter, it's going to be a long time to produce aggregations and summaries on that kind of set. And it didn't help that this set was in SaaS format, but that's another story for another day. But in any event, imagine if that dataset is getting split up into parquet files or intelligently by groups, And then you take the same kind of code that was demonstrated by Damien over here and to be able to run that very efficiently or Dario should back. Try that again. And imagine if you take the same code that Dario puts together in this post with those parquet files again, like you said, correct me. My I feel is that the new CSV, There's a reason I linked to those as extract downloads in my podcast index dashboard. I didn't wanna do CSVs anymore trying to push this as the other communities as well to look into this. But you are gonna get tremendous gains in these situations with with DuckDV on the back end. And one addendum that I would be interested in trying on, maybe I will when I get some spare moments, is it was, what, a week or 2 ago on this very podcast, we had covered the release of the Duck plier package, which again is a very similar vein to what Duck DB package itself is doing here, but it is a even more of a direct one to one replacement for dplyr.
It is still newer, so we're keeping an eye on its development. But you could probably leverage the majority of that same code into a duct flyer pipeline, and I would venture to say you're gonna get those same performance benchmarks because it's all Duck DB under the hood anyway. But we'll definitely have a link to Duck plier as an additional thing to explore here. But I see, again, massive potential in the spaces that you and I operate on in both of my day job efforts. But now, as I mentioned in my open source efforts of this podcast database, my portal dashboard kind of takes a quote unquote easy way out where I've through GitHub actions, I'm doing all the processing outside the dashboard and the dashboard is simply referencing them directly via RDS files that are being downloaded on the fly.
I am waiting for the day where I can swift flip that up to do web assembly, DuckDV in inside that, and then I can do the real time querying, so to speak, in that dashboard as a Shiny Live app instead. It's coming, Mike. It's coming. I just need the time to do it.
[00:28:44] Mike Thomas:
And speaking of WebAssembly, we have one last highlight to wrap up the week that I think might just be on that topic.
[00:28:51] Eric Nantz:
So, yeah, it's not only on that topic. It is literally in my same industry about ways that I've been envisioning for ever since I've heard about this technology, where I think the potential is, and we are seeing that here. And in particular, this last highlight is coming from the pharmaverse blog and authored by Paolo Rucci, who is a data scientist developer at Roche. And for those unfamiliar, the pharma verse, if you're in the r community, you've like you heard of things like the tidy verse and whatnot. Well, this is a collection of packages that are helping make clinical pipeline analyses, data processing that we routinely do in life sciences much easier to do in the our ecosystem as ours now taking a much, stronger footprint in the life sciences industry.
Well, one of the suites of packages and the pharma versus, you know, getting popular is the nest packages and others to help produce what one might consider the backbone of what we call a clinical submission to regulators for a given study, and that is the production of tables, listings, or graphs or TLGs for short. Traditionally, these have been done in a certain proprietary language, but that's not we're gonna talk about here because r has made tremendous strides in this space. And as a way to get new users or to show off the potential of what's possible with the pharmaverse in this in this, part of the pipeline, The pharmaverse has produced for a while now the TLG catalog, which has been a snippet for the common table listings and graph types that we often do in submissions, but with the r code to actually produce those and a snapshot of the output.
Well, what, Paulo was talking about in this post is they have now integrated WebR, hence WebAssembly, into this portal site to not only show the code, but to let the users run the code themselves, change things on the fly, experiment with the existing syntax. My goodness. This is just a massive win for learning in this space. I am geeked out about this already. They had me there, but as the game shows will say, but wait, there's more because another popular part of the pharmaverse has been the teal framework, which is a way to bring interactive data exploration with these common summaries into a Shiny application with a set of reusable modules and packages to help with different analytical types, different parts of the processing, but teal is a great way to ingest these clinical data for review in your given systems to explore for new insights and whatnot.
Well, guess what? With the advent of shiny live, Powell is also plugged in a way to run a teal application tailor made for each of these table summaries inside that same website, folks. This is massive. I cannot underscore how enthusiastic I am about this because think of the doors this is opening. Right? Is that there will be, many in life sciences that are new or newish to our for a lot of these clinical analyses. Anything, and I mean anything we can do to make this easier for them to transition, we need to take that and run with it as fast as we possibly can. This TLG catalog, I think, is amazing first step in this vision. So I whoever you're in the pharma industry or not, just take the ideas from this. Think about how this could be used in your use cases for whether you're teaching new users of r or you're trying to demonstrate to your leaders what is possible when you mirror the technologies of open source and web assembly together. This t o g catalog is a massive vision. I or a demonstration of this vision that I think can be applicable to many people. And, yeah, when I saw this, I'm like, I'm IMing some people at work. I'm like, you need to see this folks. This is amazing. So I'm definitely gonna be pursuing this very closely. But, again, what an excellent showcase of WebAssembly, quarto, and the pharmaverse all in one place. Absolutely massive, Mike. Can you tell I'm excited?
[00:33:15] Mike Thomas:
I can tell you're excited, and it's hard to do it all justice, on audio format, but there's some great gifts as well that Pavel has, included and implemented into this blog post that really demonstrate exactly what's going on. And I don't know if the users sort of caught it, Eric, but what this means and what's being showcased here is not only the ability to create this this sort of shiny app, right, using web assembly and web are sort of in the browser, But also allowing users to be able to edit the source code for this app and actually change the underlying, you know, structure of this app within the browser itself, and actually see the changes in that app underneath the code immediately, which is fantastic.
No needing to install any dependencies on your machine. You don't even need to have R installed or Rstudio installed. This is all taking place in the browser, which is is absolutely incredible. I think, you know, again, it it just lends itself to, less friction for those trying to get started with our easy learning, the language language and adoption of the language. Hopefully, for those coming from from different languages to be able to to get started and and go from sort of 0 to 1 with the only requirement being an internet connection that they need, which is really incredible.
The other thing that I would say is, you know, what this this whole, sort of WebR framework and WebAssembly framework where it has sort of my head spinning now at this point which is something that we talked about, I think, on recent episodes but I don't think it is quite fully implemented yet is the idea for, you know, packages that we develop and these pack beautiful package downsides that we create with them, for the examples that we have for the different functions, in the reference section of our packages to be able to to actually be run-in the browser instead of users having to install that package and run those examples, you know, within their own our session.
What I saw recently, and I can't remember if it's the most recent version of quarto that got released or if it's the most recent version of our that got released that had these capabilities, but you can now use quarto or QMD files to create package vignettes, which is probably sounds like a very subtle thing, but my hope is that now that we're able to to leverage quarto for authoring, packaged vignettes which I'm super excited to move to just because I love quarto. My hope is that maybe that leads the way or blazes the trail for the integration of of WebR into these vignettes as well backed by maybe the shiny live quarto extension and allowing us the ability to to do what I just described So, you know, like you said, Eric, and like we've brainstormed, the possibilities here are endless with all these advancements in in WebR and WebAssembly.
And you and I I'm not sure if you had met him before but but at least I was fortunate enough to meet Pavel at, Shiny Conf last year and and maybe he'll be there again this year, but, a brilliant data scientist and a very, very well done blog post from him and a great way to wrap up the week.
[00:36:36] Eric Nantz:
Yeah. We we were able to connect as well at that same conference, and I've I've you know, I've had multiple conversations thinking about potential of this new technology, and that's why I'm so excited to be part of this space right now with my, our consortium effort with that pilot, Shiny app submission and WebAssembly. I think we're on to something here and, that that indeed what you mentioned with quarto, it is in as of quarto version 1.4 is indeed the version Atlanta support for package vignettes, and I cannot wait to try that. Even if it's a internal package, if I can pull that off, yes, that again is a massive win for learning.
Even as something as I'm gonna call trivial, it's not so trivial. I have an internal package to import SAS data sets into our bet backed by Haven, but with little syntactic stuff on top. Imagine just having a a a vignette powered by quartile to help demonstrate what that code looks like and some of the post processing functions I have in store. But, yes, I think in in our industry, we we are ready to embrace technology like this. Admittedly, we still have a long ways to go to see where this impacts, like, actual submission pieces, hence what I'm exploring in this pilot.
But when you put this in front of people, I don't know how you can't be excited about the potential of this. And like I said, no matter what industry you're in, I hope you take some inspiration from parts of this because this is this is the time to try things out. I think this is that evolution in history that we're gonna look back on maybe 5, 10 years down the road and wonder how did we live without this.
[00:38:16] Mike Thomas:
I hear you. I agree.
[00:38:19] Eric Nantz:
You know what else is hard to live about is our weekly itself. Right? I mean, if our week had been around when I was learning our oh, I would have learned so much faster. But we can't turn back time. But at least you can start with the present and check out the rest of the issue that Sam has put together of more excellent resources. So it'll take a couple of minutes for our additional finds here. And, yes, I am very, you know, much a fan of the web assembly frame, but I haven't forgotten about my explorations with container environments. And that's where this another mind blowing moment for me from this issue is that James Balamuda, who goes by the cultless professor on the various social handles, he has been the pioneer of that web r extension for quartile and whatnot, but he has put a spectacular demonstration on his GitHub organ profile here that has a, custom dev container setup, which for those aren't aware of dev containers are a way for you to bootstrap a container environment in versus code or get hub code spaces.
And he's got one that's actually 2 of them that are tailor made for both building portal documents and with newer extensions such as the web r extension and the pile died extension if you're doing Python based, web assembly products. But also these dev container features have one that works in the traditional GitHub code space, which will look like Versus code in your browser. Again, you as a user don't have to install anything with this on your system. It's all in the cloud. And wait for it. There is a dev container feature for Rstudio server.
Let me say that again. There is a dev container feature for Rstudio server. If you recall maybe a year or so ago, I was exploring my workflow for these dev container environments for all my our projects, and I would spin up RStudio container via custom Docker file. And I would, okay, get from the rocker project, add these dependencies, add these packages and whatnot. And, yeah, it quote, unquote works, but it is a bit of, manual setup nonetheless, even if you clone my repo. Oh my goodness. Do you know how much easier this is now with just one line in that devcontainer JSON file he can have in our studio environment in the browser, not on your system, all powered by the GitHub Codespaces.
Oh my goodness. I am playing with this as soon as I can.
[00:40:54] Mike Thomas:
That is super exciting, Eric. I can't wait to play with it as well. You you know, I I don't need to say it again that I have been bitten, hard by the dev container bug, and we do all projects now on our team, within dev container environments just makes collaboration and and sharing that much easier. So this is a great great blog post, touching on that subject again. I can't get enough of that content, so that's a great shout out as well. Another thing that we do a lot of, so this spoke to me quite a bit, was that there is a new release of ShinyProxy, version 3.one.0.
And for those who aren't familiar, ShinyProxy is a platform for hosting Shiny applications. It's it's clear fully open source, but you you host these Shiny applications, heavily via Docker such that each user, when they click on an app on your your ShinyProxy platform, it spins up a separate Docker container for that user, and that allows you to to leverage things like Kubernetes fairly easily, and it does allow for some, you know, additional security. You're able to deploy your Shiny apps, as as Docker images, which is is really nice in terms of reproducibility as well. But, you know, ShinyProxy is something that that we leverage pretty heavily both internally and for our clients. This was exciting to me and I know that there's some other folks out there that, leverage this project as well as it's it's one of, the the multiple Shiny hosting options that you could have. And the new features in ShinyProxy, 3.1 are, as opposed to what I just said, you know, when a user clicks on an app, it spins up a a brand new separate container for them. In 3.1.0, we have the option for some pre initialization of that container or sharing of that container across multiple users. So, sometimes when a Docker container sort of is is spinning up depending on how large that image is, it can take some time to spin up and users may have to wait, you know, 5, 10, 15 seconds, something like that, for that container to spin up and for them to actually be able to see their application. So 3.1.0 provides some opportunities for pre initialization of those containers and actually sharing, containers across users such that an already running container can be leveraged, by a second user.
The other, big update is that, you know, up to now, ShinyProxy supported 3 different container back ends. That was Docker, Docker Swarm, and Kubernetes. Now there is a brand new back end, AWS ECS, which is pretty exciting. I think AWS ECS, allows you to or or maybe, they take care of some of the server setup, and scaling that you might have to have rolled your own, if you're using Docker, Docker Swarm, or Kubernetes. So it's nice that that abstracts it away from you. But as Peter Salomos notes in his, hosting data apps blog that that recaps this 3.1. O release. You know, one downside of of AWS ECS is that in most cases, it takes more time to start the container compared to other back ends. But now that we do have this this pre initialization and container sharing capabilities in 3.1.0, we might be able to reduce that startup time to something that's that's even less than a second, if we are able to take advantage of those new features. So, there's some additional stuff in there, but but really exciting, for myself and maybe those others in the community that that leverage ShinyProxy.
[00:44:28] Eric Nantz:
Yeah. These are fantastic updates, and I can underscore the importance of that pre initialization feature because sometimes with whoever you're, you know, sending this to, you might have to, have to think about, okay, what are the best ways to enhance user experience. Right? And loading times is unfortunately one of them for better or worse. So be able to have that ready on the fly, I think, is massive. And for all the DevOps engineers out there that may have been, you know, what we call an r admin that's administering shiny proxy or maybe working with IT to support that. What I really appreciate, as you mentioned, Mike, with the ECS, you know, new back end implemented, If you're wondering how that might fit for some of the automation, like deployment pipelines, they linked to in this post a, a repo that has an example for Terraform, which is a very popular dev ops, you know, system configuration platform for automation. So I I I have a few HPC admins in my day job that would appreciate seeing that because that's Terraform all the things with Chef. So this might be something that if we do shiny proxy in the future, I'll be sending this their way. But, yeah, really, really exciting to see these updates for sure.
[00:45:43] Mike Thomas:
I have somebody on my team who's big into Terraform. It's not something that I've stepped into yet, but it seems pretty awesome for sort of just writing maybe kind of like a a Docker file of your pipeline in terms of your entire setup. You know it's fairly easy to read, easy ish to read, and it's sort of just listing out the instructions of the infrastructure that you wanna set up. It's pretty cool.
[00:46:06] Eric Nantz:
Yeah. There's a lot in this space that I've been, you know, trying to learn up on on my time. I've gone kinda far, but I've been learning up on Chef and Ansible and a little bit of Terraform, but, there's only so much time in the day. But, nonetheless, there is so much more we could talk about in this issue, but we would be here all day if we did. So we'll just invite you to check out the rest of the issue at rnp.org along with all the other resources that we mentioned in this episode as well. It's all gonna be in the show notes. And by the way, if you are listening to this show on one of those more modern podcast apps like pavers or found, you may have noticed we've actually upped the production quality to show quite a bit where now you get not only the chapters, which we've always done, we've got chapter image, images that will directly link to each of the highlights that we talk about. So I think that's pretty cool if you're taking advantage of the modern tooling here and also a big win for accessibility, each episode now has a transcript directly generated into the show, which, ironically, even Apple has adopted recently. So you should be able to get that in many of the podcast apps that you listen to this very show. And, we love hearing from you and the audience as well. But, of course, the art weekly project itself goes with the community. It's powered by the community.
So if you see a great resource you wanna share with the rest of the art community, we're just a pull request away. It's all at rwiki.org and click in the upper right for that little GitHub icon, and you'll be taken to the next week's issue draft where you can put in your link. And our curator of the week will be glad to merge that in after a review. And, also, we'd love to hear from you as well directly. There are many ways to do that. The fun way, of course, is if you're on one of those aforementioned podcast app, you can send us a fun little boost along the way, and we'll be able to read it directly on the show. And, it was fun to be on the Friday show because I I did get a few boosts sent my way because I was part of what they called the valued split at that point for that segment. So lots of fun shout outs about the r language and whatnot and are nerding out on that side of it. But, also, you can contact us on the various social media handles.
I am mostly on Mastodon these days with at our podcast at podcast index dot social. I'm also sporadically on x Twitter, whatever you wanna call it, with at the r cast and also on LinkedIn. Just search for my name, Eric Nance, and you will find me there. Mike, where can the listeners get a hold of you? Sure. You can find me on mastodon@[email protected].
[00:48:38] Mike Thomas:
If you search for my name on LinkedIn, you will probably find way too many Mike Thomases and not be able to find me. So, you can see what I'm up to if you search Catchbrook Analytics instead. That's ketchb r o o k.
[00:48:53] Eric Nantz:
Very nice. And, yeah. That will wrap up the episode 100 and 65. We had lots of fun talking about these highlights of all of you, and we definitely invite you to come back again next week to hear us talk about yet more our community goodness of our weekly. So until then, happy rest of your day wherever you are, and we will see you right back here next week.