Our take on the important conversations spurred by the recent R deserialization CVE, how simulations may save you from cracking open that probability textbook, and recapping the exciting 2024 Shiny Conference.
Episode Links
Episode Links
- This week's curator: Colin Fay - @[email protected] & [@ColinFay]](https://twitter.com/ColinFay) (X/Twitter)
- Everything you never wanted to know about the R vulnerability, but shouldn't be afraid to ask
- Calculating birthday probabilities with R instead of math
- Highlights from ShinyConf 2024
- Entire issue available at rweekly.org/2024-W19
- R-bitrary Code Execution: Vulnerability in R’s Deserialization https://hiddenlayer.com/research/r-bitrary-code-execution/
- CVE-2024-27322 Should Never Have Been Assigned And R Data Files Are Still Super Risky Even In R 4.4.0 https://rud.is/b/2024/05/03/cve-2024-27322-should-never-have-been-assigned-and-r-data-files-are-still-super-risky-even-in-r-4-4-0/
- Safety Radar for RDA Files https://github.com/hrbrmstr/rdaradar
- R's new exploit: how it works & other ways you're vulnerable (Josiah Parry) https://www.youtube.com/watch?v=WGvXEi4nG5k
- Bogus CVE follow-ups https://daniel.haxx.se/blog/2023/09/05/bogus-cve-follow-ups/
- Data serialisation in R https://blog.djnavarro.net/posts/2021-11-15_serialisation-with-rds/
- Tapyr https://connect.appsilon.com/tapyr-docs/
- Podcast Index Database Dashboard (built with R and Quarto) https://rpodcast.github.io/pod-db-dash/
- Eric will be a guest on the Podcasting 2.0 show this Friday! (10-May-2024 1:30 PM EDT) https://podcastindex.org/podcast/920666
- Use the contact page at https://rweekly.fireside.fm/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Green Glade Groove - Donkey Kong Country 2: Diddy's Kong Quest - TSori, dpMusicman, etc - https://ocremix.org/remix/OCR04437
- Salut Voisin! - Final Fantasy IV - colorado weeks, Aeroprism - https://ocremix.org/remix/OCR04553
[00:00:03]
Eric Nantz:
Hello, friends. We are back with episode 164 of the Our Week of Highlights podcast. This is the weekly show where we showcase the latest highlights and awesome resources that you can see every single week and the Our Weekly issue at rweekly.org. My name is Eric Nanson. Yeah. I'm on demand. I'm sounding a bit more like my normal self. So thanks to all of you for persevering through that last week if you're listening to that. But we have a lot to discuss today, and I'm not going to do this alone. And there's no way I could do it alone today because I have my awesome cohost with me, as always, Mike Thomas. Mike, are you ready for a jam packed episode?
[00:00:38] Mike Thomas:
I'm ready, Eric. The highlights are heating up. It's it's heating up here on the East Coast.
[00:00:43] Eric Nantz:
And I don't know if you wanna hear this or not, but my Boston Bruins are heating up as well. Yeah. You know. Yeah. Yeah. At that point, you know, when you get to game sevens, they're a coin flip. But, yeah, once they got through that pesky, Toronto Maple Leafs, now they're gonna they're gonna give those, dreaded Panthers a run for their money, it looks like. So fun times ahead for you. We'll see. We'll see. Well, revenge in action because last year, they, they got a rude awakening and 7 games from them. So maybe the revenge factor strikes again like it does in pro sports. But, yep. But we don't have any revenge to conduct against each other. We're good friends as always. But, of course, this issue is, of course, not built by us. It is built by the R weekly team. And in particular, this issue was curated by the esteemed Colin Fay, of course, the architect of all things GOLM and many of our shiny awesome packages.
But, of course, he had tremendous help from our OurWeekly team members and contributors like all all of you around the world. Well, if you had to guess where we're gonna start, it's probably not so much a mystery because this has been making the waves for the past about 2 weeks now in the R community and even other tech sectors outside of R itself. We are, of course, talking about the recently disclosed critical vulnerability exploit or CVE that was disclosed with respect to the serialization of particular r data types with the RDS format. And we had a little bit of a mention of this last week because it was literally late breaking as we're recording in last week's episode. But if you're not familiar what we're talking about here, it was about, about near the end of April, April 29th, to be exact.
A vendor called Hiddenware, who I've not heard of before this particular story, had this had disclosed the vulnerability called CVE 202427322. I don't expect you to memorize that, but all the links are in the show notes. But this is describing that an exploit that you can utilize in previous versions of R up to version 4.4, where apparently this has been patched, where you can inject arbitrary code to be executed into an RDS serialized file through means of clever uses of the headers inside that file and taking advantage of concepts like PROMISE for evaluation and the like.
We won't read that post verbatim here. You can look in the show notes for it. But as I expected, when this broke, I thought there would be some additional either fallout slash follow-up from the community, especially for those that are in tune with both the intersections of data science and infosec or information security. And this first highlight is one of those responses we're gonna dive into along with a bunch of related resources. And this post comes from Ivan Krivlov, who I believe has been featured in previous highlights. And his post succinctly titled, everything you never want to know about the r vulnerability, but shouldn't be afraid to ask. I think that's an awesome title because this is really going to break it down piece by piece in terms of what this practically means in terms of our day to day for the usage of R and just what is going on under the hood.
One thing that we're going to say right off the bat is that this specific instance in this CVE is just one example of how potentially, and I do mean potentially, someone could exploit certain features of the R language to, you know, do malicious things on a on a somebody's system and whatnot. But these are features of the language itself, and R is most definitely not alone in having these features in place. We'll get to that in a little bit. But in essence, Ivan starts off the post with kind of some background on the RDS and R data file formats. Where they are, their job is to directly represent the state of an art type of object.
And I mean really represent it. In essence, serialize it such that it can be completely reproduced on another system or another installation of R via the loading functions for that particular object. Now these objects do, by nature, often contain code that needs to be executed on the system related to R itself. A good example that he calls out here is a lot of those model fit objects that you might pass around based on a linear regression fit or whatnot. It's gonna contain code VSA s three methods or others under the hood to do certain things with, say, the data that was supplied in that model fit, looking at model assumption, you know, model metrics and whatnot, that's by design, folks. That's always been there.
So, yes, what this vulnerability really is is just finding clever ways to inject additional execution of code in these places, in these serialized objects so that you could take advantage of it. But if you really wanna get really deep it, it's not that easy. He does have examples talking about the anatomy of a particular vulnerability like this, of how you might have to get into the source of R itself and how it serializes objects and try to interject things in between if you want to do something really nefarious.
But in the end, this is all things that have happened in other languages as well. And that's where he leads off with, at the end, you know, our friends in the Python community, this is something they've been dealing with for years with respect to an arbitrary serialized object called pickle, often used in machine learning model fits, prediction modeling in general. There's nothing stopping a nefarious person from injecting Python code. He got somewhat hidden in that object where if you don't know to look for it, you might miss it. But I'm going to take a step back here and think about an example that I've been telling people as they've been asking me about this.
We live in this era of digital communication. Right? And what is the most you know, one of the most direct means of communication these days is the good old email message. Right? You often have text and email, but you might also have something else with it called attachments. And I know in my organization, they put us through very rigorous training to say, did you get an attachment with someone you trust? If not, you might wanna think twice about opening that up on your system. And that's where I think the CV is bringing the light maybe something that I don't know if glossed over is the right word, just hasn't been talked about much, is that these serialized data objects have always had this capability.
The question is, do you trust the process that's building it and who is sending that to you? And with that, on top of Ivan's post, we've got other terrific resources here that I'll put in the show notes that really dive into the practicalities of what the CV really means. In particular, Bob Rudis has an excellent post on his blog, and he is very, opinionated on this. Although, frankly, I share his opinion. This probably never should have been a CVE in the first place. Again, this is not a unique problem to R. This is the language operating as, quote, unquote, its design.
It doesn't take away our responsibility as end users to be, you know, critical of when we're receiving these data objects, verifying the source. And in particular, he's got a proof of concept in his GitHub repository that will let you scan these data objects to look for potential vulnerabilities or potential nefarious code injections inside. That's just one example. And another great example linked to is Josiah Perry just has a very brief or to the point video on his YouTube channel about how you can take advantage of these exploits as well, again, using fundamental features of the language that are not gonna go away anytime soon, nor they should of you know, executing arbitrary code in s 3 methods and other, you know, methods that you get when you load a data object into your memory.
And then a couple other things before I, well, glide down here is that the concept of CVEs in general, while, of course, I acknowledge they are hugely important in the realm of security, there's always more than meets the eye about this. So I found this great interesting post from Daniel Stenberg who has a interesting take on the CVE process and some of the nuances behind it in light of disclosures back a few years ago with respect the curl utility and other frameworks. Just something to have in the back of your mind as you see this reported in the general tech sector of these outlets that aren't really going really deep into this story. And that's what we're trying to do here. We want you to give you the resources to do more follow-up on your own and make your own call about what this means to you. We're just sharing what it means to us.
And then lastly, if this whole data serialization topic is new to you, like it was to me even just a year or so ago. Another link I'll throw in the show notes is Daniel Navarro has an awesome blog blog post, easy for me to say, about how data serialization and r really works, in particular, the RDS format. So you can kinda see the nuts and bolts of how this works. So my takeaway is I think this v CVE, while I don't really agree with how it was disclosed and highlighting a feature of a language itself that's not in and itself a vulnerability. I am at least you know, happy is probably not the right word, but I am glad that it's bringing to light the the discussion that we've had internally in my company, but also others in the community about really being responsible about how we're using these data that's supplied to us or being built by these other processes.
So I think that's good that's good discussion to have. I've seen it on Mastodon. I've seen it on LinkedIn and other places. So maybe it is that wake up call that the community needed that the art language has grown enough in popularity
[00:11:20] Mike Thomas:
that now we really have to think critically about these methods that could potentially be used again for nefarious means. But, Mike, I've rambled enough. What's your take on all this? No. Eric, I share a lot of the same thoughts, and it's I'm glad that you pointed out Danielle's, blog post there because that was one that came across my mind when I was reading, you know, all the different blog posts around this topic because really what underlies the issue here is, you know, serialization and deserialization of of our objects and how that works. And I think a large, you know, sort of, point to projects like the the Parquet project was to try to get away from some of that serialization and deserialization of language agnostic or or yeah, language specific, I should say, you know, formatted objects like RDS files, like pickle files, and to try to be able to store data in more of an agnostic way, that doesn't involve serialization that allows users, to be able to to to work with that data no matter, what language they're in. But obviously, we don't have something like that when it comes to something like a model object, right, or storing, you know, pretty much anything else, you know, in an RDS file or and I believe on the Python side in a pickle file, you can pretty much store anything you want in those files, which is incredibly useful, when it comes to doing things like machine learning and and having to, you know, deploy a machine learning model. Right? You want don't wanna have to retrain that model, as part of your production process. You wanna train that model, store it as a some sort of single object that makes it very easy to make predictions, to load and make predictions against. And that's where a lot of the times we'll use RDS files or or pickle files on the Python side.
But, you know, I certainly share your sentiment that if nothing else this CVE brings to light, you know, the point that you need to trust the sources of your RDS or your pickle files, completely. And, you know, if someone I I thought of this this sort of use case here that I think I've seen before, you know, in, like, a GitHub gist, you're you're trying to solve a problem. You're you're diving deep into to GitHub and to Stack Overflow, places like that, and you finally, you know, see somebody who has a reproducible example with some code, but in order to run that code, right, they they've also attached a file. There could be a CSV, could be an RDS file, a pickle file, something like that. And you you need to have that file to be able to run their code. Right? They weren't able to create, like, a full reproducible example for for whatever reason just based out of code where they they sort of simulated that data. You they're providing you this file that you're going to need to run that gist or run that example.
And maybe in the past, you know, depending on where that file was was located, depending on, you know, who the author is of that that gist. If it's a repository of someone, you know, well known that you trust, maybe it's in the Pandas project or the DeepLiar project and it's posted by, you know, somebody from somebody from Posit or or Wes McKinney or something like that, maybe you're you're likely to trust that file and to download it and run it against that code. But if it's, you know, that that gets into a very sticky situation. And I think it's just a good time maybe to remind your team in situations like that that they need to exercise extreme caution when opening and opening any file. Right? And and the the open source community, I think relies on a lot of trust for better or for worse. Right?
And, you know, I guess this is just a good time for us to sort of step back and remember that, you know, there there could be bad actors out there and that we we have to deal with a lot of skepticism, in order to ensure the safety of the data products that we're creating and deploying to production. So, you know, like I said, if nothing else, you know, this is maybe a good time to to do that step back and to think twice. You know, admittedly, when this came out, you know, the the fact that that NIST, which I believe is, like, the government, entity, National Institute, Institute National Vulnerability Database is the NVD, place where this got posted to. And NIST is the big, you know, cybersecurity risk management, you government entity out there. So whenever you see something come across NIST, you know, and I'm thinking of, like, you know, a lot of the organizations constantly watching what NIST is publishing.
So if this came across their desk and, you know, NIST is sort of blasting this this new R vulnerability, It's something that we need to pay attention to and we need to engage in communication with those stakeholders to to really bring all sides of, you know, the the discussion to the table so that we can sort of understand, you know, exactly how this impacts us, what what's the messaging that needs to take place, What are any changes, if any, you know, that need to take place? And, you know, I think, again, sort of some of the the blog posts from from Bob's, sort of some of the blog posts here that we're we're reading from Ivan, you know, may just reiterate the the need that the the messaging, and the conversations, and the reinforcement of, you know, best security practices is is maybe more important here than actually making any changes to your R infrastructure.
So admittedly, you know, when I I did see this initial blog post come across from Hidden Layers and, you know, this new entry in the national vulnerability database come across, it was, you know, it was sort of big scary news a little bit. I put out a LinkedIn post, you know, talking about that we're we're sort of advising our clients to up to to our 4.4.0 for new projects that they have and just to exercise that caution on RDS files or RDA files or any sort of, you know, pickle type file that, you know, you don't know exactly where it originated from. I I think those two pieces of advice are are still, you know, solid pieces of advice But in terms of, like, going backwards and and blowing up any processes that you had in place that maybe don't have anything to do with with the RDS or RDA files or something like that. I I don't think there's a need for that, at all. But obviously, a lot of opinions on this subject. I'm glad that we're getting a lot of opinions on this subject and folks are taking the time to really dig in here, but but this is sort of a a great blog post from Ivan to provide that perspective. It comes with a lot of links, a lot of citations, and I sincerely appreciate his work on this post.
[00:18:16] Eric Nantz:
Likewise. And, yeah, there's been there's been a a few others as well, and Bob's been quick to acknowledge others in his blog posts that have really been looking at these issues, you know, for a long term. But now ever since this came out, they were looking at even more. So Conrad Rudolph's another one. I call Davydov is another one if I'm saying it correctly. They've been on Mastodon looking at different proof proof of concepts of how this exploit could be utilized. But, again, the message is is that the language itself is still doing what it expected, that that it it hinges on this type of feature in terms of, you know, serializing data objects as efficient ways of transferring and whatnot.
But I do like your your callout about other formats that are taking shape in the community, such as parquet and the like. And with respect to putting on my life sciences hat for a second, there was questions I would get about, what does this mean in terms of if we use r for clinical submissions and whatnot? Well, guess what? It's very strict guidelines with respect to regulators that we transfer data in a very specific format that is not a serialized object. They have very rigorous procedures in place to eliminate the hint of any file being transferred that is, quote, unquote, executable in that sense. So we wouldn't even be bothering with these formats in a clinical submission as as of now.
But the other piece that I thought about, and I may mention this at the end of the episode, is I've been been working on a side project with a portal dashboard and GitHub actions that does duplication analysis but, and also a data quality check. But then I'm sending extracts of, like, each of the, quote, unquote, failed quality checks in 2 file formats, RDS and parquet. But the key point is that if someone is wants to inspect that themselves and maybe they are our user as well and they wanna see the RDS file for that particular step of, like, looking at duplicate IDs in a database or whatever.
1st, they got a choice of which data format to pick from. But second, if they wanna see how I produce the RDS file, guess what? It's all in the open. Right? That's the nature of open source. I have all my my my GitHub action, our script, all in there that's run every week, and they can see for themselves what algorithm I'm using, how I'm serializing at the RDS, and, hence, transparency when it is available, I think, is paramount in these situations. So I think, you know, leaning on that but also leaning on the practical, you know, you know, practical, you know, thinking process, thought process of, you know, being critical about your data sources and then being transparent to your customers or your other colleagues about how this is being produced.
I think that is being brought to the forthright foreflight here, so to speak. And I hope the discussion keeps going in this direction and not just tunnel vision on this very specific CVE itself because that's missing the point. This when we bring back the point to the general use of open source, the use of these serialized formats in general, again, nothing new in this ecosystem. It just so happens that it got popular enough that it became the light. So I guess that's that.
[00:21:38] Mike Thomas:
Yeah. Or if, in Bob's take, you know, I think there's some sort of a conference coming up and somebody may have been looking for a little clout, heading into that conference. So who who knows? A lot of a lot of different possibilities out there, and I would definitely, sort of recommend that folks take the time to read up on this across all these different perspectives and and form their own opinion and and figure out how to, best communicate this and and make any changes necessary within your own organization.
[00:22:16] Eric Nantz:
Well, Mike, let's lighten up the mood a little bit, shall we? Because, we're gonna we're gonna go back to school a little bit. But I hear there's a way we can even circumvent some of those hard math details in our next highlight here. And this is coming from Andrew Heiss who has been a frequent contributor to the our weekly highlights in in many episodes ago. And he has this great post on how you can take advantage of a method I've been utilizing in my day job for years, of simulation to help calculate probabilities where you might have had to rely on those, you know, famous or infamisimally or prospective math formulas that you might have seen in grad school. So what are we talking about here is that this is motivated by situations where maybe you're asked or you're teaching a concept that has to deal with some very, you know, intricate concepts and probability.
I don't know about you, Mike, but I remember in my stats or math coursework, whenever you got the probability, you always were hit to that problem of you got, like, 1 or more of these urns of red, green, or yellow balls or whatever. Nice. And you gotta pick pick which what's the probability of getting, like, at least one of each color or 2 colors and not that one and whatnot. That's where Andrew in this post starts with, you know, a little refresher on how to use common metrics to represent the pool of choices from these balls and these earns and choose k, you would often call it. So the formulas are all there.
You I remember in the old days, I used the old TI 85 to calculate all this. Shout out to all the TI 85 nerds out there. We may or may not put games on it, but that's what I'm sorry for another day. But in any event, guess what? You can do this in r itself. There's the choose function. Right? There's choose, and you can say out of 40 balls, choose 5. What are the number of possibilities you can get there? And then, of course, you can do that for your answer. It gets a little more complicated when you get to more nuanced questions of maybe at least one red, blue, or green ball. Then you can see in the post here, there's lots of different combinations they have to sort through in your numerator and denominator.
And, yes, you can use r for it, but, again, you've got you've got a lot going on there. Well, Andrew mentions way back in his training in 2012, he had a professor that kind of mentioned a comment at the end of one of his lectures that, you know what? You could get a similar answer as what you're doing in this math probability through simulation. And, of course, I'm sure if I had heard that at the time, I probably would have had that light bulb moment in my head too of like, hey. I wonder if I could circumvent some of this gnarly math formulation. And sure enough, you certainly can.
So Andrew dug up some old some of his historic r code. Again, credit to him for being transparent on this of a 4 loop that he created to simulate that earned problem of choosing at least one color probability of choosing at least one color out of that. And it's a pretty intuitive for loop. Right? You'll see it in the post, but when you read it, you grok what's happening there without the need of those fancy combination formulas. Now where does this mean practically? Well, he was inspired by a post he saw on Blue Sky of someone asking in their household.
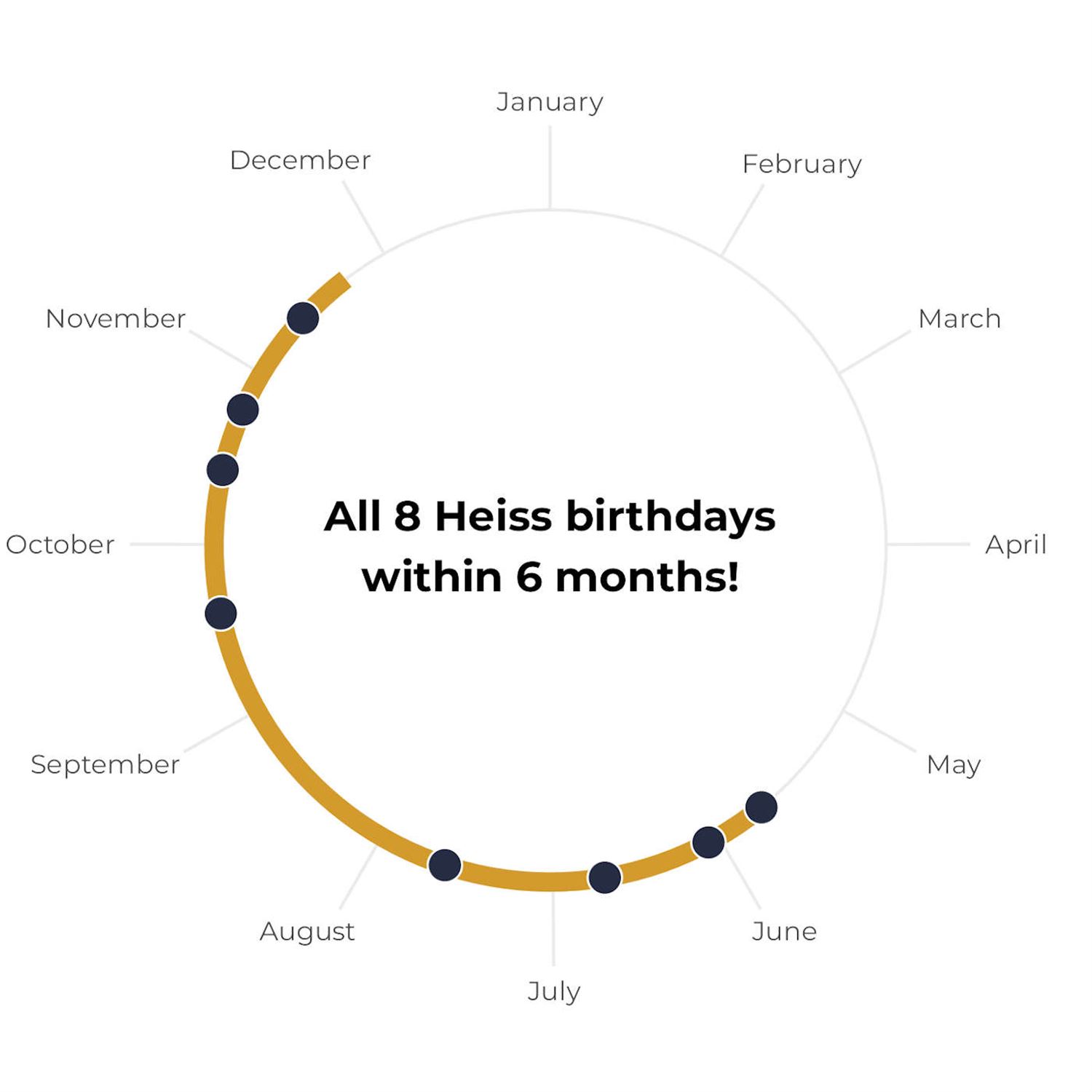
They have an n o six. They have all their birthdays inside a 6 month interval. How likely or unlikely is that in practice? That's an interesting birthday problem, if I dare say so myself. So the rest of this post goes into all the different ways that we can address this. And one neat way to address this first is taking advantage of a unique geometric representation to see just how this shapes up in terms of how the months are related to each other. And he mentions creating a radial chart of sorts, taking advantage of a newer GEOME that's supposed to ggplot23.5. And there's code here in the blog post to do this.
I believe it's called GM radio or if I recall correctly. Yep. Oh, cord radio. Yep. Yep. And there's some great visuals here, for his household where these birthdays fit birthday months fit in this spectrum. And if they're in a 6 month window, they're going to be all within a half circle radius of each other or half circle on the on the perimeter, if you will. My geometry is rusty, folks. Bear with me here. But it gets even more gnarly of that when you start thinking about, well, now let's try to generalize this a little bit. And what happens in the case where a birthday is from a previous year, but it's still within that 6 month window? How do you navigate representation on that?
So he's got some examples of how you do a clever use of additional segments to go from the previous year to the January 1st date of the new year and visualizing that. So there's great code in ggplot2 that walked through how he is able to accomplish this visualization and how it handles birthdays outside that 6 month scope and wealth within it. And like I said, with years overlapping and whatnot, but that's just the visualization part. Now, the actual calculation of the probabilities at hand, this is where I've always said dates, times, time zones are hard. And this is another situation here because you can't quite get away with representing the birthdays on this perfect circle because in calendar years, we got different days a month. We got the leap year to deal with and whatnot.
So there's a lot of custom code that's needed to derive things like the distance between the the earliest date and the latest date, accounting for year transitions, trying to transform this into a pseudo circle representation. There's a lot of interesting code here that's doing a hybrid of, you know, per map reducing and arithmetic with respect to these birthday dates, sometimes having to multiply time spans by 2 and whatnot to make this happen. And then once you get through kind of the algorithm side of it, now you gotta actually perform the simulation.
And, again, taking into account leap years and whatnot. So he does come up with a function that takes advantage of some of the algorithms he develops early in the post to start simulating this. And, again, at this first glance, from a uniform type setup, assuming all birthdays could be, you know, occurring equal on equal days in the calendar. On the surface, that seems like a a gen like a reasonable assumption. Actually, not so much. And this is where at the end of the post, he discovers that there are sources from the CD and the Social Security Administration here in the US that actually keeps track of daily births in the United States from in fact, in 538, that portal had a story in 2016 about the patterns in this. And guess what? They put their CSV files on GitHub that they use to assemble all this. So guess what?
Now instead of assuming that it's a uniform distribution of these birthdays falling on any of the 365 days of the year, we can actually sample from this known set of prior birthdays to get a more accurate representation of that distribution in in daily practice. He does this nice visualization of the kind of a heat map here showing that there are indeed portions of the calendar where birthdays are more common, such as, like, not many are current around Christmas and New Year's. Yeah. I wonder why, but that's an interesting thought exercise for everybody. But it it's right there. Yeah. You can see it's clearly not uniform.
So he's able to update his probability functions to utilize this type of distribution approach to sample from here. And then in the end, we get a nice little bar chart at the end or a lollipop chart, depending on how you wanna call it, where you look at, depending on the household size, the decrease in probability that all these birthdays occur in a 6 month window. To no surprise, when you have less number in the household, like 2 or 3, although, actually, 2, looks almost a 100% confident that you'll have birthdays that fall in the 6 month time span. But as you get the 3, 4, 5, 6, you start to see that kind of exponential decay, if you will, of seeing how unlikely it is to when you have a larger household, such as, like, 6.4% for an 8 person household.
But in the end, what is not in all the functions that he produced here to derive this answer? No call outs of probability formulas. No calls to that choose function. It is all based on a rigorous set of simulations. I admit there's a lot going on in this post here, but in the end, the approach is what I wanna take away from here is that when you're in doubt to find that maybe close form solution or that neat probabilistic, you know, derivation or formula calculation, simulation is your friend here. And with the computer technology we have and modern systems and whatnot.
You can get a great approximation to these answers even for fun problems like this birthday problem. So, again, felt like I was going to school here, but it was a great way to tie in multiple things that I do in the day to day. But explain in Andrew's a really great,
[00:32:04] Mike Thomas:
technique here. Well, I felt like I was going to school too, and I think it's fitting because I believe Andrew is a professor and he is also a machine because, this is a a lengthy phenomenal blog post with, you know, looks like it might be authored in in quarto or something like that with fantastic narrative, inline code, all these beautiful gg plots. You know, that's sort of what really stands out to me. It's just really the attention to detail on a lot of these gg plots as well. And I too, Eric, like you, really wish that I had been taught probability and statistics, with the concepts of of simulation, instead of the more theoretical approach that I was taught with. I think my grades probably would have been a little bit higher in that class if that had been the case, but, you know, what can we do now? It eventually clicks fortunately, and I imagine that Andrew's students are probably pretty grateful of his very practical and applied approaches, to explaining and demonstrating concepts like this. I I too thought it was pretty interesting, the idea that, birthdays maybe are not sort of normally distributed.
Although, it looks like the difference between his simulation when he made that assumption that birthdays are normally distributed across the year, versus, you know, when he went to using the data from 538. The differences there are are pretty marginal, you know, with his household size of of 6. You know, assuming that there was a uniform distribution of birthdays, I think his simulation returned like a a 17.8% chance of all 6 of those birthdays occurring within the same 6 month window. And when he used that 538 data to simulate from, the percentage actually jumped or the likelihood actually jumped from 17.8 to 19.3.
So a a little bit higher probability with 6 folks in your household that they will all have a a birthday within sort of a same 6 month window. I I thought that was, you know, fairly interesting. And really, it's the approach here. It's the practicality. It's the the tools that he's giving us to to execute the same type of analysis that I think are super useful. So I would recommend that that anybody who is maybe, having a difficult time or or just needs a refresher on, you know, sort of basic probability and statistics via simulation, check out this blog post. It's fantastic top to bottom.
[00:34:38] Eric Nantz:
Yeah. And I dare say it's also kind of a little gateway, if you will, to the concepts of Bayesian statistics as well with this idea of you may not know in real life what that distribution of outcomes or that set of data you're dealing with. When in doubt, you'll take what you do know, try to use that as prior information. Again, I'm using this on purpose, but these are things that again, when I was in school, I didn't know heads or tails about Bayesian probability. I was over in the Bayes theorem, which we just glossed over in 1 week, and then suddenly I'm off to the next convergence stuff. That is a fascinating world that we often dealing with with respect to the multitude of data sources we have.
And it is very difficult to assume one type of specific recipe, if you will, for how these are being created in the real world. So simulations combined with Bayesian methodology, I think they put so much in the hands of you, the data scientist or statistician, to come up with meaningful answers in light of not knowing what is the real source of truth here. So, again, it's a great it's a great, you know, pseudo, you know, gateway to to that side of the world. And, yeah, I probably would have had a little better grades if I had something like Andrew as a professor, but we don't have that time machine yet, Mike. And, I dare say we ended up pretty well nonetheless, but, you know, hindsight is 2020.
[00:36:02] Mike Thomas:
I think so too, Eric.
[00:36:14] Eric Nantz:
And lastly on the show today, we're gonna talk about we referenced this a little bit last week, but we had the good fortune, both Mike and I, of attending the recent, shiny conference, 2024, that was held by Absalon. And our last highlight today is a little, very nice and insightful blog post that they had that they wrote earlier this week on their particular highlights from the conference. And trust me, as someone who's been on the other side organizing these type of events, it is always great to reflect back, and I think what they share is what I share as well.
The content that we saw at Shining Conf was absolutely amazing from top to bottom across many different spectrums of innovation on Shiny itself the respect to doing data for good, which is a track that was led by our good friend, John Harmon. And then our shiny life sciences track, I had the pleasure of leading that track and having a lot of great content as well and amongst much more about Shining and Enterprise as well. They first mentioned, you know, talk that we actually talked about in the highlights last week, the tailoring Shiny for modern users. There's a shout out here in the post about that. You gotta listen to last week's episode for our take on that particular talk.
But, also, one of the keynotes that gave a lot of attention there were a few keynotes, actually. But Joe Chang, of course, the CTO and author of Shiny himself, talked about the async interest session concurrency in Shiny with extended task. This has been in the works for a long time, but when the recording comes out, you'll definitely wanna watch this talk because if you've been down the promises train that was talked about years ago in one of the, Rstudio conf keynotes, You know that wasn't for the faint of heart. This is really trying to put async within Shiny apps in a much more accessible way to developers.
And there's a lot to come in this space, I'm sure, as more teams adopt this. As well as, of course, the keynote that I was fortunate to recruit, George Stagg from from the Pasa team to talk about reproducibility of WebAssembly and WebR. And boy, oh, boy, there's some nuggets at the end of that talk. And when they come to fruition, oh, boy, the game is going to change in respect of reproducibility and package versions and the like. There's some big, big stuff happening in this space. So that was really fun to have charts talk about that as well. We're also fortunate to have Pedro Silva from Appsilog, give his keynote on the past and future are shiny and and so much more. And, apparently, there is an announcement that they're gonna have a new open source package in the works with respect to, I believe, something to do with Rhino.
[00:38:58] Mike Thomas:
That's, that's a tease here. So I think it's already I think it's about a time between when we're recording today and when this blog post came out, I think it's already out. It's a new package called Tapyr, t a pyr, from Appsilon, which is sort of their Rhino approach to Shiny for Python. So it's building modularized Oh. Shiny for Python applications.
[00:39:21] Eric Nantz:
Nice. Nice. So they they put the t's out and, apparently, it was announced after the fact. So, yeah, congratulations to them for that monumental achievement. And there were some fun stuff in in the conference as well. In fact, they had a little are which package are you quiz, which is a fun one to take. I remember taking that, and I I actually forgot my answer already. But I think it has something to do with data modeling or something like that, which probably isn't too surprising for me. Although I thought it might be a shiny thing, but I got gross. I'm a I'm a complicated case. Do you remember what you got on that score, Mike?
[00:39:55] Mike Thomas:
I don't quite remember what I got. I might have missed that, I might have missed that game, but I would be very interested to see what I would come up with. Yeah. You have to try that out after this episode for sure. It might be a more complicated case, Eric.
[00:40:08] Eric Nantz:
Yeah. Yeah. We're we're we're we're, we're complicated folks, aren't we? But, but in the end, this was, I believe, the first of the shining conferences that had the multiple tracks. So, again, there's always pros and cons of that approach, but in the end, really excellent content nonetheless. And, hence, when the recordings come out, you might be able to catch up with what you missed. But, overall, that was a fantastic event, very well attended, and the engagement from the audience was top notch,
[00:40:37] Mike Thomas:
from top to bottom. So, Mike, what are your impressions of what you saw there? Yeah. That was fantastic. I mean, you covered a lot of the the ones that were big highlights for me between Joe Chang and and George Staggs. Another one that really resonated with me because I really appreciate someone who is actually trying to take an applied approach to quote, unquote AI was Tanya Casarelli's, best practices and lessons learned. I guess it was a real world use cases for AI in Shiny, which was just a fantastic talk and great to see a practitioner out there actually, you know, putting, you know, fingers to keyboard to spin up solutions that are helpful, for her clients with, you know, AI and Shiny as opposed to just a lot of those vendors out there that are just sort of yell AI at you with, with no sort of, you know, execution plan behind it. But I'll digress, you know, it resonated a lot with me because I have to give a very similar talk on applied AI use cases at a conference in August. So I may study up on on her materials again and rewatch it in on the recording in the RingCentral platform which folks who attended, have the ability to do.
[00:41:54] Eric Nantz:
Awesome. Yep. And like I said, watch out for those recordings. But, yeah, there was, I think, something for everybody. And, again, excellent, job by Epsilon, and congrats to them. Hopefully, they're getting some well deserved rest after that because I know after the our pharmas that I've helped organize in the past along with an excellent team, we're like, okay. We can exhale now, and then give us a couple weeks before we think about the next year. So in any event, what you do have to think about is where do you find content like this every week? Well, it's our weekly dotorg, of course, and we got more than much more than what we just talked about here. Collins put together a fantastic issue, and we'll talk about some additional fines over the next couple of minutes here. I'm gonna I'm gonna I'm gonna give a little plug to Collins organization, ThinkR, on their blog. They have a great blog post. If you ever felt a little intimidated or don't know where to start with after you find that awesome JavaScript library online, but yet you're not quite sure how to put that into your Shiny app, they have a great, example here about taking the Sweet Alert 2 JavaScript library and putting that into a Shiny application, which to no surprise is powered by Golem.
So this is a great, you know, compliment to what you might find in the existing, like, engineering production grade shiny apps book that I think R and Colin Fay have authored. If you want a kind of a quick take and you found that Sweet Alert 2 utility, how do you bundle the dependencies together? How do you inject that into your golem app manifest? And how do you build, you know, easy functions on the other side of things to call that JavaScript and passing the data back and forth. It can definitely be very helpful to see how this works in the day to day because in the end, you're probably if you're in the shiny space for more than a little bit, you're gonna be asked by a customer or maybe even yourself to bling it up a little bit, give a little more pizzazz with that awesome utility. And you're like, wait a minute. There's no package for that. What do I do? Well, this approach is a is a great way to call that out. And I didn't know there was a new Sweet Alert 2 library. I've been using Sweet Alert via Dean Nitelli's shiny alert package, so maybe I need to throw him a note to see if he's interested in something like this. But in the event, as a shiny nerd, that was right up my alley.
[00:44:10] Mike Thomas:
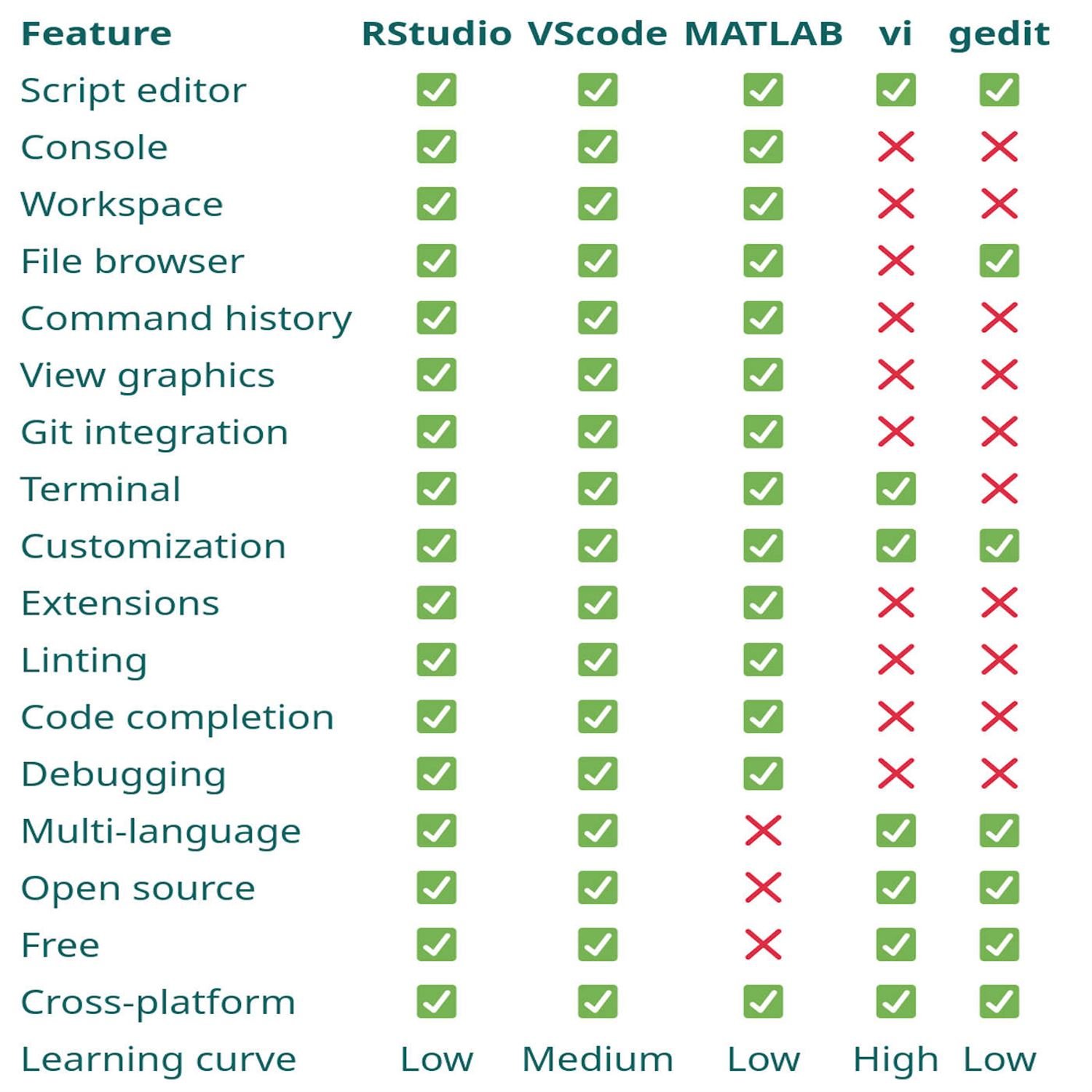
Me too, Eric. That was a great find. One that was also right up my alley was a blog post from Athanasia Moical on the different IDE's that she uses. And, she flip flops sort of back and forth between RStudio and Versus Code in a way that is resonates very much with myself. She's Rstudio. Typically, for anything R related, if there's a a git conflict, you know, that's when she'll spin up a Versus Code window to be able to solve, those different git conflicts. And then for just about every other project or language, she'll use Versus Code. And there's just some great comparisons across the different features in RStudio, Versus Code. And also, you know, she talks about her her journey, you know, in her early days. She actually started out in MATLAB, as well as, like, the the Vim editor.
And it really compares, you know, the features that she experienced along that journey, to the different tools that she was using across the different tools that she was using. And, it's a great rundown, resonated a lot with me because I think there's a lot of folks out there that are, you know, seeing some some of the different ways that you can do different things across different IDEs, even though a lot of the times it's it's just a matter of of preference. You can pretty much accomplish all the same stuff, depending on on which IDE you're in. It might just be, you know, different keyboard shortcuts. It might be, you know, different options to to set up, and and click on. But it resonated a lot with me and for any folks who are trying to navigate which IDE is best for them on their project. This might be a nice blog post to read.
[00:45:49] Eric Nantz:
Yeah. And being, in my opinion, having the awareness of each of these out there, but then knowing what are the best use cases for your environment or your projects is hugely important. I have an aspirational goal. I want to be just as fluent with using, say, the combination of Vim or Neovim with the r plug in as much as I am fluent with RStudio and Versus Code. That's my aspirational goal. I don't know if I'll ever get there, but, boy, I'm gonna keep trying more than ever. I've seen it. It's it is cool. It's very cool. Yeah. There's I've seen some screen cast by some good friends, and I'm like, how did you pull that off? Whether it's VIM or Emax or stuff.
Some good cred there, I must say. But, you know how you get good cred, you read the rest of our weekly, I tell you, because it's gonna give you a boatload of additional insights that we couldn't cover today. So, again, if you don't know where it is, I'm gonna tell you again, it's rweaker.org, and we love hearing from you in the audience. We have a few ways to do that. We have a contact page in the episode show notes, Also, we have a modern podcast app, like, say, Poverse, Fountain Cast O Matic, CurioCast. So there's a bundle of others. You can send us a fun little boost along the way, and we'll get that message directly sent to us. And we'll be able to read it right here on this very show. And, also, we are sporadically on social media as well.
I am mostly, I'm masking on these days of at our podcast at podcast index dot social. Speaking of podcast index, yours truly has a good fortune of joining Adam Curry and Dave Jones on the podcasting 2 point o show this Friday to talk about a quartile dashboard that I built with our quartile to visualize the podcast index database duplication analysis and quality checks with the point blank package. So if you wanna hear me talk about that, tune in this Friday around 1:30 EST. But in any event, I'm also on the, LinkedIn as well and also on Twitter with at the r cast.
[00:47:48] Mike Thomas:
Mike, where can they find you? Eric, if I was in charge of editing this podcast, I would insert some celebratory applause. That is awesome. I'm very excited to listen to that that episode, and I'm sure that the folks, working, you know, on that project are are super, appreciative of the work that you put into building that quarto dashboard. Is that publicly available for folks to check out? It sure is. Oh, man. We'll put a link in the show notes. Put a link in the show notes. I would love to take a look at the final final product. I think I've seen some draft iterations as you've been working on it but I'd love to see the final products. That's awesome. Folks can find me on mastodon@[email protected] or you can check out what I'm up to on LinkedIn if you search for Catchbrook Analytics, k e t c h b r o o k. That's where you'll be able to to check out what I've been up to lately.
[00:48:37] Eric Nantz:
Awesome stuff. And, yep. So we're gonna wrap up here on this edition of our weekly highlights, and, hopefully, you've been able to take away some good insights from us. We knew that this was a very important week for our show because of the big story that was at the top, but, certainly, give us feedback if you enjoyed the discussion or if you have other things you want us to discuss. In any event, we'll close-up shop here, and we'll see you back here for another episode of our weekly highlights next week.
Hello, friends. We are back with episode 164 of the Our Week of Highlights podcast. This is the weekly show where we showcase the latest highlights and awesome resources that you can see every single week and the Our Weekly issue at rweekly.org. My name is Eric Nanson. Yeah. I'm on demand. I'm sounding a bit more like my normal self. So thanks to all of you for persevering through that last week if you're listening to that. But we have a lot to discuss today, and I'm not going to do this alone. And there's no way I could do it alone today because I have my awesome cohost with me, as always, Mike Thomas. Mike, are you ready for a jam packed episode?
[00:00:38] Mike Thomas:
I'm ready, Eric. The highlights are heating up. It's it's heating up here on the East Coast.
[00:00:43] Eric Nantz:
And I don't know if you wanna hear this or not, but my Boston Bruins are heating up as well. Yeah. You know. Yeah. Yeah. At that point, you know, when you get to game sevens, they're a coin flip. But, yeah, once they got through that pesky, Toronto Maple Leafs, now they're gonna they're gonna give those, dreaded Panthers a run for their money, it looks like. So fun times ahead for you. We'll see. We'll see. Well, revenge in action because last year, they, they got a rude awakening and 7 games from them. So maybe the revenge factor strikes again like it does in pro sports. But, yep. But we don't have any revenge to conduct against each other. We're good friends as always. But, of course, this issue is, of course, not built by us. It is built by the R weekly team. And in particular, this issue was curated by the esteemed Colin Fay, of course, the architect of all things GOLM and many of our shiny awesome packages.
But, of course, he had tremendous help from our OurWeekly team members and contributors like all all of you around the world. Well, if you had to guess where we're gonna start, it's probably not so much a mystery because this has been making the waves for the past about 2 weeks now in the R community and even other tech sectors outside of R itself. We are, of course, talking about the recently disclosed critical vulnerability exploit or CVE that was disclosed with respect to the serialization of particular r data types with the RDS format. And we had a little bit of a mention of this last week because it was literally late breaking as we're recording in last week's episode. But if you're not familiar what we're talking about here, it was about, about near the end of April, April 29th, to be exact.
A vendor called Hiddenware, who I've not heard of before this particular story, had this had disclosed the vulnerability called CVE 202427322. I don't expect you to memorize that, but all the links are in the show notes. But this is describing that an exploit that you can utilize in previous versions of R up to version 4.4, where apparently this has been patched, where you can inject arbitrary code to be executed into an RDS serialized file through means of clever uses of the headers inside that file and taking advantage of concepts like PROMISE for evaluation and the like.
We won't read that post verbatim here. You can look in the show notes for it. But as I expected, when this broke, I thought there would be some additional either fallout slash follow-up from the community, especially for those that are in tune with both the intersections of data science and infosec or information security. And this first highlight is one of those responses we're gonna dive into along with a bunch of related resources. And this post comes from Ivan Krivlov, who I believe has been featured in previous highlights. And his post succinctly titled, everything you never want to know about the r vulnerability, but shouldn't be afraid to ask. I think that's an awesome title because this is really going to break it down piece by piece in terms of what this practically means in terms of our day to day for the usage of R and just what is going on under the hood.
One thing that we're going to say right off the bat is that this specific instance in this CVE is just one example of how potentially, and I do mean potentially, someone could exploit certain features of the R language to, you know, do malicious things on a on a somebody's system and whatnot. But these are features of the language itself, and R is most definitely not alone in having these features in place. We'll get to that in a little bit. But in essence, Ivan starts off the post with kind of some background on the RDS and R data file formats. Where they are, their job is to directly represent the state of an art type of object.
And I mean really represent it. In essence, serialize it such that it can be completely reproduced on another system or another installation of R via the loading functions for that particular object. Now these objects do, by nature, often contain code that needs to be executed on the system related to R itself. A good example that he calls out here is a lot of those model fit objects that you might pass around based on a linear regression fit or whatnot. It's gonna contain code VSA s three methods or others under the hood to do certain things with, say, the data that was supplied in that model fit, looking at model assumption, you know, model metrics and whatnot, that's by design, folks. That's always been there.
So, yes, what this vulnerability really is is just finding clever ways to inject additional execution of code in these places, in these serialized objects so that you could take advantage of it. But if you really wanna get really deep it, it's not that easy. He does have examples talking about the anatomy of a particular vulnerability like this, of how you might have to get into the source of R itself and how it serializes objects and try to interject things in between if you want to do something really nefarious.
But in the end, this is all things that have happened in other languages as well. And that's where he leads off with, at the end, you know, our friends in the Python community, this is something they've been dealing with for years with respect to an arbitrary serialized object called pickle, often used in machine learning model fits, prediction modeling in general. There's nothing stopping a nefarious person from injecting Python code. He got somewhat hidden in that object where if you don't know to look for it, you might miss it. But I'm going to take a step back here and think about an example that I've been telling people as they've been asking me about this.
We live in this era of digital communication. Right? And what is the most you know, one of the most direct means of communication these days is the good old email message. Right? You often have text and email, but you might also have something else with it called attachments. And I know in my organization, they put us through very rigorous training to say, did you get an attachment with someone you trust? If not, you might wanna think twice about opening that up on your system. And that's where I think the CV is bringing the light maybe something that I don't know if glossed over is the right word, just hasn't been talked about much, is that these serialized data objects have always had this capability.
The question is, do you trust the process that's building it and who is sending that to you? And with that, on top of Ivan's post, we've got other terrific resources here that I'll put in the show notes that really dive into the practicalities of what the CV really means. In particular, Bob Rudis has an excellent post on his blog, and he is very, opinionated on this. Although, frankly, I share his opinion. This probably never should have been a CVE in the first place. Again, this is not a unique problem to R. This is the language operating as, quote, unquote, its design.
It doesn't take away our responsibility as end users to be, you know, critical of when we're receiving these data objects, verifying the source. And in particular, he's got a proof of concept in his GitHub repository that will let you scan these data objects to look for potential vulnerabilities or potential nefarious code injections inside. That's just one example. And another great example linked to is Josiah Perry just has a very brief or to the point video on his YouTube channel about how you can take advantage of these exploits as well, again, using fundamental features of the language that are not gonna go away anytime soon, nor they should of you know, executing arbitrary code in s 3 methods and other, you know, methods that you get when you load a data object into your memory.
And then a couple other things before I, well, glide down here is that the concept of CVEs in general, while, of course, I acknowledge they are hugely important in the realm of security, there's always more than meets the eye about this. So I found this great interesting post from Daniel Stenberg who has a interesting take on the CVE process and some of the nuances behind it in light of disclosures back a few years ago with respect the curl utility and other frameworks. Just something to have in the back of your mind as you see this reported in the general tech sector of these outlets that aren't really going really deep into this story. And that's what we're trying to do here. We want you to give you the resources to do more follow-up on your own and make your own call about what this means to you. We're just sharing what it means to us.
And then lastly, if this whole data serialization topic is new to you, like it was to me even just a year or so ago. Another link I'll throw in the show notes is Daniel Navarro has an awesome blog blog post, easy for me to say, about how data serialization and r really works, in particular, the RDS format. So you can kinda see the nuts and bolts of how this works. So my takeaway is I think this v CVE, while I don't really agree with how it was disclosed and highlighting a feature of a language itself that's not in and itself a vulnerability. I am at least you know, happy is probably not the right word, but I am glad that it's bringing to light the the discussion that we've had internally in my company, but also others in the community about really being responsible about how we're using these data that's supplied to us or being built by these other processes.
So I think that's good that's good discussion to have. I've seen it on Mastodon. I've seen it on LinkedIn and other places. So maybe it is that wake up call that the community needed that the art language has grown enough in popularity
[00:11:20] Mike Thomas:
that now we really have to think critically about these methods that could potentially be used again for nefarious means. But, Mike, I've rambled enough. What's your take on all this? No. Eric, I share a lot of the same thoughts, and it's I'm glad that you pointed out Danielle's, blog post there because that was one that came across my mind when I was reading, you know, all the different blog posts around this topic because really what underlies the issue here is, you know, serialization and deserialization of of our objects and how that works. And I think a large, you know, sort of, point to projects like the the Parquet project was to try to get away from some of that serialization and deserialization of language agnostic or or yeah, language specific, I should say, you know, formatted objects like RDS files, like pickle files, and to try to be able to store data in more of an agnostic way, that doesn't involve serialization that allows users, to be able to to to work with that data no matter, what language they're in. But obviously, we don't have something like that when it comes to something like a model object, right, or storing, you know, pretty much anything else, you know, in an RDS file or and I believe on the Python side in a pickle file, you can pretty much store anything you want in those files, which is incredibly useful, when it comes to doing things like machine learning and and having to, you know, deploy a machine learning model. Right? You want don't wanna have to retrain that model, as part of your production process. You wanna train that model, store it as a some sort of single object that makes it very easy to make predictions, to load and make predictions against. And that's where a lot of the times we'll use RDS files or or pickle files on the Python side.
But, you know, I certainly share your sentiment that if nothing else this CVE brings to light, you know, the point that you need to trust the sources of your RDS or your pickle files, completely. And, you know, if someone I I thought of this this sort of use case here that I think I've seen before, you know, in, like, a GitHub gist, you're you're trying to solve a problem. You're you're diving deep into to GitHub and to Stack Overflow, places like that, and you finally, you know, see somebody who has a reproducible example with some code, but in order to run that code, right, they they've also attached a file. There could be a CSV, could be an RDS file, a pickle file, something like that. And you you need to have that file to be able to run their code. Right? They weren't able to create, like, a full reproducible example for for whatever reason just based out of code where they they sort of simulated that data. You they're providing you this file that you're going to need to run that gist or run that example.
And maybe in the past, you know, depending on where that file was was located, depending on, you know, who the author is of that that gist. If it's a repository of someone, you know, well known that you trust, maybe it's in the Pandas project or the DeepLiar project and it's posted by, you know, somebody from somebody from Posit or or Wes McKinney or something like that, maybe you're you're likely to trust that file and to download it and run it against that code. But if it's, you know, that that gets into a very sticky situation. And I think it's just a good time maybe to remind your team in situations like that that they need to exercise extreme caution when opening and opening any file. Right? And and the the open source community, I think relies on a lot of trust for better or for worse. Right?
And, you know, I guess this is just a good time for us to sort of step back and remember that, you know, there there could be bad actors out there and that we we have to deal with a lot of skepticism, in order to ensure the safety of the data products that we're creating and deploying to production. So, you know, like I said, if nothing else, you know, this is maybe a good time to to do that step back and to think twice. You know, admittedly, when this came out, you know, the the fact that that NIST, which I believe is, like, the government, entity, National Institute, Institute National Vulnerability Database is the NVD, place where this got posted to. And NIST is the big, you know, cybersecurity risk management, you government entity out there. So whenever you see something come across NIST, you know, and I'm thinking of, like, you know, a lot of the organizations constantly watching what NIST is publishing.
So if this came across their desk and, you know, NIST is sort of blasting this this new R vulnerability, It's something that we need to pay attention to and we need to engage in communication with those stakeholders to to really bring all sides of, you know, the the discussion to the table so that we can sort of understand, you know, exactly how this impacts us, what what's the messaging that needs to take place, What are any changes, if any, you know, that need to take place? And, you know, I think, again, sort of some of the the blog posts from from Bob's, sort of some of the blog posts here that we're we're reading from Ivan, you know, may just reiterate the the need that the the messaging, and the conversations, and the reinforcement of, you know, best security practices is is maybe more important here than actually making any changes to your R infrastructure.
So admittedly, you know, when I I did see this initial blog post come across from Hidden Layers and, you know, this new entry in the national vulnerability database come across, it was, you know, it was sort of big scary news a little bit. I put out a LinkedIn post, you know, talking about that we're we're sort of advising our clients to up to to our 4.4.0 for new projects that they have and just to exercise that caution on RDS files or RDA files or any sort of, you know, pickle type file that, you know, you don't know exactly where it originated from. I I think those two pieces of advice are are still, you know, solid pieces of advice But in terms of, like, going backwards and and blowing up any processes that you had in place that maybe don't have anything to do with with the RDS or RDA files or something like that. I I don't think there's a need for that, at all. But obviously, a lot of opinions on this subject. I'm glad that we're getting a lot of opinions on this subject and folks are taking the time to really dig in here, but but this is sort of a a great blog post from Ivan to provide that perspective. It comes with a lot of links, a lot of citations, and I sincerely appreciate his work on this post.
[00:18:16] Eric Nantz:
Likewise. And, yeah, there's been there's been a a few others as well, and Bob's been quick to acknowledge others in his blog posts that have really been looking at these issues, you know, for a long term. But now ever since this came out, they were looking at even more. So Conrad Rudolph's another one. I call Davydov is another one if I'm saying it correctly. They've been on Mastodon looking at different proof proof of concepts of how this exploit could be utilized. But, again, the message is is that the language itself is still doing what it expected, that that it it hinges on this type of feature in terms of, you know, serializing data objects as efficient ways of transferring and whatnot.
But I do like your your callout about other formats that are taking shape in the community, such as parquet and the like. And with respect to putting on my life sciences hat for a second, there was questions I would get about, what does this mean in terms of if we use r for clinical submissions and whatnot? Well, guess what? It's very strict guidelines with respect to regulators that we transfer data in a very specific format that is not a serialized object. They have very rigorous procedures in place to eliminate the hint of any file being transferred that is, quote, unquote, executable in that sense. So we wouldn't even be bothering with these formats in a clinical submission as as of now.
But the other piece that I thought about, and I may mention this at the end of the episode, is I've been been working on a side project with a portal dashboard and GitHub actions that does duplication analysis but, and also a data quality check. But then I'm sending extracts of, like, each of the, quote, unquote, failed quality checks in 2 file formats, RDS and parquet. But the key point is that if someone is wants to inspect that themselves and maybe they are our user as well and they wanna see the RDS file for that particular step of, like, looking at duplicate IDs in a database or whatever.
1st, they got a choice of which data format to pick from. But second, if they wanna see how I produce the RDS file, guess what? It's all in the open. Right? That's the nature of open source. I have all my my my GitHub action, our script, all in there that's run every week, and they can see for themselves what algorithm I'm using, how I'm serializing at the RDS, and, hence, transparency when it is available, I think, is paramount in these situations. So I think, you know, leaning on that but also leaning on the practical, you know, you know, practical, you know, thinking process, thought process of, you know, being critical about your data sources and then being transparent to your customers or your other colleagues about how this is being produced.
I think that is being brought to the forthright foreflight here, so to speak. And I hope the discussion keeps going in this direction and not just tunnel vision on this very specific CVE itself because that's missing the point. This when we bring back the point to the general use of open source, the use of these serialized formats in general, again, nothing new in this ecosystem. It just so happens that it got popular enough that it became the light. So I guess that's that.
[00:21:38] Mike Thomas:
Yeah. Or if, in Bob's take, you know, I think there's some sort of a conference coming up and somebody may have been looking for a little clout, heading into that conference. So who who knows? A lot of a lot of different possibilities out there, and I would definitely, sort of recommend that folks take the time to read up on this across all these different perspectives and and form their own opinion and and figure out how to, best communicate this and and make any changes necessary within your own organization.
[00:22:16] Eric Nantz:
Well, Mike, let's lighten up the mood a little bit, shall we? Because, we're gonna we're gonna go back to school a little bit. But I hear there's a way we can even circumvent some of those hard math details in our next highlight here. And this is coming from Andrew Heiss who has been a frequent contributor to the our weekly highlights in in many episodes ago. And he has this great post on how you can take advantage of a method I've been utilizing in my day job for years, of simulation to help calculate probabilities where you might have had to rely on those, you know, famous or infamisimally or prospective math formulas that you might have seen in grad school. So what are we talking about here is that this is motivated by situations where maybe you're asked or you're teaching a concept that has to deal with some very, you know, intricate concepts and probability.
I don't know about you, Mike, but I remember in my stats or math coursework, whenever you got the probability, you always were hit to that problem of you got, like, 1 or more of these urns of red, green, or yellow balls or whatever. Nice. And you gotta pick pick which what's the probability of getting, like, at least one of each color or 2 colors and not that one and whatnot. That's where Andrew in this post starts with, you know, a little refresher on how to use common metrics to represent the pool of choices from these balls and these earns and choose k, you would often call it. So the formulas are all there.
You I remember in the old days, I used the old TI 85 to calculate all this. Shout out to all the TI 85 nerds out there. We may or may not put games on it, but that's what I'm sorry for another day. But in any event, guess what? You can do this in r itself. There's the choose function. Right? There's choose, and you can say out of 40 balls, choose 5. What are the number of possibilities you can get there? And then, of course, you can do that for your answer. It gets a little more complicated when you get to more nuanced questions of maybe at least one red, blue, or green ball. Then you can see in the post here, there's lots of different combinations they have to sort through in your numerator and denominator.
And, yes, you can use r for it, but, again, you've got you've got a lot going on there. Well, Andrew mentions way back in his training in 2012, he had a professor that kind of mentioned a comment at the end of one of his lectures that, you know what? You could get a similar answer as what you're doing in this math probability through simulation. And, of course, I'm sure if I had heard that at the time, I probably would have had that light bulb moment in my head too of like, hey. I wonder if I could circumvent some of this gnarly math formulation. And sure enough, you certainly can.
So Andrew dug up some old some of his historic r code. Again, credit to him for being transparent on this of a 4 loop that he created to simulate that earned problem of choosing at least one color probability of choosing at least one color out of that. And it's a pretty intuitive for loop. Right? You'll see it in the post, but when you read it, you grok what's happening there without the need of those fancy combination formulas. Now where does this mean practically? Well, he was inspired by a post he saw on Blue Sky of someone asking in their household.
They have an n o six. They have all their birthdays inside a 6 month interval. How likely or unlikely is that in practice? That's an interesting birthday problem, if I dare say so myself. So the rest of this post goes into all the different ways that we can address this. And one neat way to address this first is taking advantage of a unique geometric representation to see just how this shapes up in terms of how the months are related to each other. And he mentions creating a radial chart of sorts, taking advantage of a newer GEOME that's supposed to ggplot23.5. And there's code here in the blog post to do this.
I believe it's called GM radio or if I recall correctly. Yep. Oh, cord radio. Yep. Yep. And there's some great visuals here, for his household where these birthdays fit birthday months fit in this spectrum. And if they're in a 6 month window, they're going to be all within a half circle radius of each other or half circle on the on the perimeter, if you will. My geometry is rusty, folks. Bear with me here. But it gets even more gnarly of that when you start thinking about, well, now let's try to generalize this a little bit. And what happens in the case where a birthday is from a previous year, but it's still within that 6 month window? How do you navigate representation on that?
So he's got some examples of how you do a clever use of additional segments to go from the previous year to the January 1st date of the new year and visualizing that. So there's great code in ggplot2 that walked through how he is able to accomplish this visualization and how it handles birthdays outside that 6 month scope and wealth within it. And like I said, with years overlapping and whatnot, but that's just the visualization part. Now, the actual calculation of the probabilities at hand, this is where I've always said dates, times, time zones are hard. And this is another situation here because you can't quite get away with representing the birthdays on this perfect circle because in calendar years, we got different days a month. We got the leap year to deal with and whatnot.
So there's a lot of custom code that's needed to derive things like the distance between the the earliest date and the latest date, accounting for year transitions, trying to transform this into a pseudo circle representation. There's a lot of interesting code here that's doing a hybrid of, you know, per map reducing and arithmetic with respect to these birthday dates, sometimes having to multiply time spans by 2 and whatnot to make this happen. And then once you get through kind of the algorithm side of it, now you gotta actually perform the simulation.
And, again, taking into account leap years and whatnot. So he does come up with a function that takes advantage of some of the algorithms he develops early in the post to start simulating this. And, again, at this first glance, from a uniform type setup, assuming all birthdays could be, you know, occurring equal on equal days in the calendar. On the surface, that seems like a a gen like a reasonable assumption. Actually, not so much. And this is where at the end of the post, he discovers that there are sources from the CD and the Social Security Administration here in the US that actually keeps track of daily births in the United States from in fact, in 538, that portal had a story in 2016 about the patterns in this. And guess what? They put their CSV files on GitHub that they use to assemble all this. So guess what?
Now instead of assuming that it's a uniform distribution of these birthdays falling on any of the 365 days of the year, we can actually sample from this known set of prior birthdays to get a more accurate representation of that distribution in in daily practice. He does this nice visualization of the kind of a heat map here showing that there are indeed portions of the calendar where birthdays are more common, such as, like, not many are current around Christmas and New Year's. Yeah. I wonder why, but that's an interesting thought exercise for everybody. But it it's right there. Yeah. You can see it's clearly not uniform.
So he's able to update his probability functions to utilize this type of distribution approach to sample from here. And then in the end, we get a nice little bar chart at the end or a lollipop chart, depending on how you wanna call it, where you look at, depending on the household size, the decrease in probability that all these birthdays occur in a 6 month window. To no surprise, when you have less number in the household, like 2 or 3, although, actually, 2, looks almost a 100% confident that you'll have birthdays that fall in the 6 month time span. But as you get the 3, 4, 5, 6, you start to see that kind of exponential decay, if you will, of seeing how unlikely it is to when you have a larger household, such as, like, 6.4% for an 8 person household.
But in the end, what is not in all the functions that he produced here to derive this answer? No call outs of probability formulas. No calls to that choose function. It is all based on a rigorous set of simulations. I admit there's a lot going on in this post here, but in the end, the approach is what I wanna take away from here is that when you're in doubt to find that maybe close form solution or that neat probabilistic, you know, derivation or formula calculation, simulation is your friend here. And with the computer technology we have and modern systems and whatnot.
You can get a great approximation to these answers even for fun problems like this birthday problem. So, again, felt like I was going to school here, but it was a great way to tie in multiple things that I do in the day to day. But explain in Andrew's a really great,
[00:32:04] Mike Thomas:
technique here. Well, I felt like I was going to school too, and I think it's fitting because I believe Andrew is a professor and he is also a machine because, this is a a lengthy phenomenal blog post with, you know, looks like it might be authored in in quarto or something like that with fantastic narrative, inline code, all these beautiful gg plots. You know, that's sort of what really stands out to me. It's just really the attention to detail on a lot of these gg plots as well. And I too, Eric, like you, really wish that I had been taught probability and statistics, with the concepts of of simulation, instead of the more theoretical approach that I was taught with. I think my grades probably would have been a little bit higher in that class if that had been the case, but, you know, what can we do now? It eventually clicks fortunately, and I imagine that Andrew's students are probably pretty grateful of his very practical and applied approaches, to explaining and demonstrating concepts like this. I I too thought it was pretty interesting, the idea that, birthdays maybe are not sort of normally distributed.
Although, it looks like the difference between his simulation when he made that assumption that birthdays are normally distributed across the year, versus, you know, when he went to using the data from 538. The differences there are are pretty marginal, you know, with his household size of of 6. You know, assuming that there was a uniform distribution of birthdays, I think his simulation returned like a a 17.8% chance of all 6 of those birthdays occurring within the same 6 month window. And when he used that 538 data to simulate from, the percentage actually jumped or the likelihood actually jumped from 17.8 to 19.3.
So a a little bit higher probability with 6 folks in your household that they will all have a a birthday within sort of a same 6 month window. I I thought that was, you know, fairly interesting. And really, it's the approach here. It's the practicality. It's the the tools that he's giving us to to execute the same type of analysis that I think are super useful. So I would recommend that that anybody who is maybe, having a difficult time or or just needs a refresher on, you know, sort of basic probability and statistics via simulation, check out this blog post. It's fantastic top to bottom.
[00:34:38] Eric Nantz:
Yeah. And I dare say it's also kind of a little gateway, if you will, to the concepts of Bayesian statistics as well with this idea of you may not know in real life what that distribution of outcomes or that set of data you're dealing with. When in doubt, you'll take what you do know, try to use that as prior information. Again, I'm using this on purpose, but these are things that again, when I was in school, I didn't know heads or tails about Bayesian probability. I was over in the Bayes theorem, which we just glossed over in 1 week, and then suddenly I'm off to the next convergence stuff. That is a fascinating world that we often dealing with with respect to the multitude of data sources we have.
And it is very difficult to assume one type of specific recipe, if you will, for how these are being created in the real world. So simulations combined with Bayesian methodology, I think they put so much in the hands of you, the data scientist or statistician, to come up with meaningful answers in light of not knowing what is the real source of truth here. So, again, it's a great it's a great, you know, pseudo, you know, gateway to to that side of the world. And, yeah, I probably would have had a little better grades if I had something like Andrew as a professor, but we don't have that time machine yet, Mike. And, I dare say we ended up pretty well nonetheless, but, you know, hindsight is 2020.
[00:36:02] Mike Thomas:
I think so too, Eric.
[00:36:14] Eric Nantz:
And lastly on the show today, we're gonna talk about we referenced this a little bit last week, but we had the good fortune, both Mike and I, of attending the recent, shiny conference, 2024, that was held by Absalon. And our last highlight today is a little, very nice and insightful blog post that they had that they wrote earlier this week on their particular highlights from the conference. And trust me, as someone who's been on the other side organizing these type of events, it is always great to reflect back, and I think what they share is what I share as well.
The content that we saw at Shining Conf was absolutely amazing from top to bottom across many different spectrums of innovation on Shiny itself the respect to doing data for good, which is a track that was led by our good friend, John Harmon. And then our shiny life sciences track, I had the pleasure of leading that track and having a lot of great content as well and amongst much more about Shining and Enterprise as well. They first mentioned, you know, talk that we actually talked about in the highlights last week, the tailoring Shiny for modern users. There's a shout out here in the post about that. You gotta listen to last week's episode for our take on that particular talk.
But, also, one of the keynotes that gave a lot of attention there were a few keynotes, actually. But Joe Chang, of course, the CTO and author of Shiny himself, talked about the async interest session concurrency in Shiny with extended task. This has been in the works for a long time, but when the recording comes out, you'll definitely wanna watch this talk because if you've been down the promises train that was talked about years ago in one of the, Rstudio conf keynotes, You know that wasn't for the faint of heart. This is really trying to put async within Shiny apps in a much more accessible way to developers.
And there's a lot to come in this space, I'm sure, as more teams adopt this. As well as, of course, the keynote that I was fortunate to recruit, George Stagg from from the Pasa team to talk about reproducibility of WebAssembly and WebR. And boy, oh, boy, there's some nuggets at the end of that talk. And when they come to fruition, oh, boy, the game is going to change in respect of reproducibility and package versions and the like. There's some big, big stuff happening in this space. So that was really fun to have charts talk about that as well. We're also fortunate to have Pedro Silva from Appsilog, give his keynote on the past and future are shiny and and so much more. And, apparently, there is an announcement that they're gonna have a new open source package in the works with respect to, I believe, something to do with Rhino.
[00:38:58] Mike Thomas:
That's, that's a tease here. So I think it's already I think it's about a time between when we're recording today and when this blog post came out, I think it's already out. It's a new package called Tapyr, t a pyr, from Appsilon, which is sort of their Rhino approach to Shiny for Python. So it's building modularized Oh. Shiny for Python applications.
[00:39:21] Eric Nantz:
Nice. Nice. So they they put the t's out and, apparently, it was announced after the fact. So, yeah, congratulations to them for that monumental achievement. And there were some fun stuff in in the conference as well. In fact, they had a little are which package are you quiz, which is a fun one to take. I remember taking that, and I I actually forgot my answer already. But I think it has something to do with data modeling or something like that, which probably isn't too surprising for me. Although I thought it might be a shiny thing, but I got gross. I'm a I'm a complicated case. Do you remember what you got on that score, Mike?
[00:39:55] Mike Thomas:
I don't quite remember what I got. I might have missed that, I might have missed that game, but I would be very interested to see what I would come up with. Yeah. You have to try that out after this episode for sure. It might be a more complicated case, Eric.
[00:40:08] Eric Nantz:
Yeah. Yeah. We're we're we're we're, we're complicated folks, aren't we? But, but in the end, this was, I believe, the first of the shining conferences that had the multiple tracks. So, again, there's always pros and cons of that approach, but in the end, really excellent content nonetheless. And, hence, when the recordings come out, you might be able to catch up with what you missed. But, overall, that was a fantastic event, very well attended, and the engagement from the audience was top notch,
[00:40:37] Mike Thomas:
from top to bottom. So, Mike, what are your impressions of what you saw there? Yeah. That was fantastic. I mean, you covered a lot of the the ones that were big highlights for me between Joe Chang and and George Staggs. Another one that really resonated with me because I really appreciate someone who is actually trying to take an applied approach to quote, unquote AI was Tanya Casarelli's, best practices and lessons learned. I guess it was a real world use cases for AI in Shiny, which was just a fantastic talk and great to see a practitioner out there actually, you know, putting, you know, fingers to keyboard to spin up solutions that are helpful, for her clients with, you know, AI and Shiny as opposed to just a lot of those vendors out there that are just sort of yell AI at you with, with no sort of, you know, execution plan behind it. But I'll digress, you know, it resonated a lot with me because I have to give a very similar talk on applied AI use cases at a conference in August. So I may study up on on her materials again and rewatch it in on the recording in the RingCentral platform which folks who attended, have the ability to do.
[00:41:54] Eric Nantz:
Awesome. Yep. And like I said, watch out for those recordings. But, yeah, there was, I think, something for everybody. And, again, excellent, job by Epsilon, and congrats to them. Hopefully, they're getting some well deserved rest after that because I know after the our pharmas that I've helped organize in the past along with an excellent team, we're like, okay. We can exhale now, and then give us a couple weeks before we think about the next year. So in any event, what you do have to think about is where do you find content like this every week? Well, it's our weekly dotorg, of course, and we got more than much more than what we just talked about here. Collins put together a fantastic issue, and we'll talk about some additional fines over the next couple of minutes here. I'm gonna I'm gonna I'm gonna give a little plug to Collins organization, ThinkR, on their blog. They have a great blog post. If you ever felt a little intimidated or don't know where to start with after you find that awesome JavaScript library online, but yet you're not quite sure how to put that into your Shiny app, they have a great, example here about taking the Sweet Alert 2 JavaScript library and putting that into a Shiny application, which to no surprise is powered by Golem.
So this is a great, you know, compliment to what you might find in the existing, like, engineering production grade shiny apps book that I think R and Colin Fay have authored. If you want a kind of a quick take and you found that Sweet Alert 2 utility, how do you bundle the dependencies together? How do you inject that into your golem app manifest? And how do you build, you know, easy functions on the other side of things to call that JavaScript and passing the data back and forth. It can definitely be very helpful to see how this works in the day to day because in the end, you're probably if you're in the shiny space for more than a little bit, you're gonna be asked by a customer or maybe even yourself to bling it up a little bit, give a little more pizzazz with that awesome utility. And you're like, wait a minute. There's no package for that. What do I do? Well, this approach is a is a great way to call that out. And I didn't know there was a new Sweet Alert 2 library. I've been using Sweet Alert via Dean Nitelli's shiny alert package, so maybe I need to throw him a note to see if he's interested in something like this. But in the event, as a shiny nerd, that was right up my alley.
[00:44:10] Mike Thomas:
Me too, Eric. That was a great find. One that was also right up my alley was a blog post from Athanasia Moical on the different IDE's that she uses. And, she flip flops sort of back and forth between RStudio and Versus Code in a way that is resonates very much with myself. She's Rstudio. Typically, for anything R related, if there's a a git conflict, you know, that's when she'll spin up a Versus Code window to be able to solve, those different git conflicts. And then for just about every other project or language, she'll use Versus Code. And there's just some great comparisons across the different features in RStudio, Versus Code. And also, you know, she talks about her her journey, you know, in her early days. She actually started out in MATLAB, as well as, like, the the Vim editor.
And it really compares, you know, the features that she experienced along that journey, to the different tools that she was using across the different tools that she was using. And, it's a great rundown, resonated a lot with me because I think there's a lot of folks out there that are, you know, seeing some some of the different ways that you can do different things across different IDEs, even though a lot of the times it's it's just a matter of of preference. You can pretty much accomplish all the same stuff, depending on on which IDE you're in. It might just be, you know, different keyboard shortcuts. It might be, you know, different options to to set up, and and click on. But it resonated a lot with me and for any folks who are trying to navigate which IDE is best for them on their project. This might be a nice blog post to read.
[00:45:49] Eric Nantz:
Yeah. And being, in my opinion, having the awareness of each of these out there, but then knowing what are the best use cases for your environment or your projects is hugely important. I have an aspirational goal. I want to be just as fluent with using, say, the combination of Vim or Neovim with the r plug in as much as I am fluent with RStudio and Versus Code. That's my aspirational goal. I don't know if I'll ever get there, but, boy, I'm gonna keep trying more than ever. I've seen it. It's it is cool. It's very cool. Yeah. There's I've seen some screen cast by some good friends, and I'm like, how did you pull that off? Whether it's VIM or Emax or stuff.
Some good cred there, I must say. But, you know how you get good cred, you read the rest of our weekly, I tell you, because it's gonna give you a boatload of additional insights that we couldn't cover today. So, again, if you don't know where it is, I'm gonna tell you again, it's rweaker.org, and we love hearing from you in the audience. We have a few ways to do that. We have a contact page in the episode show notes, Also, we have a modern podcast app, like, say, Poverse, Fountain Cast O Matic, CurioCast. So there's a bundle of others. You can send us a fun little boost along the way, and we'll get that message directly sent to us. And we'll be able to read it right here on this very show. And, also, we are sporadically on social media as well.
I am mostly, I'm masking on these days of at our podcast at podcast index dot social. Speaking of podcast index, yours truly has a good fortune of joining Adam Curry and Dave Jones on the podcasting 2 point o show this Friday to talk about a quartile dashboard that I built with our quartile to visualize the podcast index database duplication analysis and quality checks with the point blank package. So if you wanna hear me talk about that, tune in this Friday around 1:30 EST. But in any event, I'm also on the, LinkedIn as well and also on Twitter with at the r cast.
[00:47:48] Mike Thomas:
Mike, where can they find you? Eric, if I was in charge of editing this podcast, I would insert some celebratory applause. That is awesome. I'm very excited to listen to that that episode, and I'm sure that the folks, working, you know, on that project are are super, appreciative of the work that you put into building that quarto dashboard. Is that publicly available for folks to check out? It sure is. Oh, man. We'll put a link in the show notes. Put a link in the show notes. I would love to take a look at the final final product. I think I've seen some draft iterations as you've been working on it but I'd love to see the final products. That's awesome. Folks can find me on mastodon@[email protected] or you can check out what I'm up to on LinkedIn if you search for Catchbrook Analytics, k e t c h b r o o k. That's where you'll be able to to check out what I've been up to lately.
[00:48:37] Eric Nantz:
Awesome stuff. And, yep. So we're gonna wrap up here on this edition of our weekly highlights, and, hopefully, you've been able to take away some good insights from us. We knew that this was a very important week for our show because of the big story that was at the top, but, certainly, give us feedback if you enjoyed the discussion or if you have other things you want us to discuss. In any event, we'll close-up shop here, and we'll see you back here for another episode of our weekly highlights next week.