Why R 4.4.0 may reduce your trips to a certain kind of stack overflow, a call to update your favorite Shiny application code snippets, and how the steller ASTHOS Profile Shiny dashboard has your hosts blown away and fighting the urge to refactor their applications UIs!
Episode Links
Episode Links
- This week's curator: Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
- What's new in R 4.4.0?
- It's time to add bslib to your shinyapp snippet
- Tailoring Shiny for Modern Users
- Entire issue available at rweekly.org/2024-W18
- Full R 4.4.0 changelog https://cran.r-project.org/doc/manuals/r-release/NEWS.html
- R-bitrary Code Execution: Vulnerability in R’s Deserialization https://hiddenlayer.com/research/r-bitrary-code-execution/
- ASTHO Profile dashboard https://astho.shinyapps.io/profile/
- {plotcli} command-line plots for R https://github.com/cheuerde/plotcli
- Fritz Leisch (1968-2024) https://www.r-project.org/doc/obit/fritz.html
- Use the contact page at https://rweekly.fireside.fm/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Trippin' on the Bridge - Streets of Rage - lazygecko - http://ocremix.org/remix/OCR00993
- You Are Not Confined - Final Fantasy IX - Sonicade - https://ocremix.org/remix/OCR01064
[00:00:03]
Eric Nantz:
Hello, friends. We're back of episode 163 of the Our Weekly Highlights podcast. This is the weekly show showcasing the latest innovations and terrific resources that have been highlighted at ourweekly.org. My name is Eric Nanson. If you couldn't tell already, your your trusty host here is feeling a little bit under the weather here, but I'm gonna power through this because it's always exciting to talk about awesome art content with my trusted cohost right here virtually, Mike Thomas. Mike, I hope you're doing better than I am these days.
[00:00:34] Mike Thomas:
I am, Eric. My allergies are in full bloom. Had a little bit of a tough time on the the golf course on Sunday, both allergy wise and golfing wise. But, we'll not talk about the latter. And but everything else is is going pretty well. I'll tell you what also bloomed was engagement on my LinkedIn post on dev containers. So keep gonna keep rolling on that topic. It seems like it's something that people enjoy hearing about. Yeah. I'm really excited to see see how much that took off, and I am
[00:01:07] Eric Nantz:
super thrilled that it's helping your team, you know, enhance your work flows. And, you know, once you once you go that route, it's very hard to go back because it just makes things so much easier to get effective collaboration in your dev environments because ain't nobody got time for package mismatches and all that fun jazz. Right? No. And system dependencies, system libraries, and stuff like that not being installed.
[00:01:30] Mike Thomas:
Yeah. It's it's really changed the game for us from a collaboration standpoint. It it makes collaboration pretty much frictionless, which is amazing.
[00:01:39] Eric Nantz:
And, yes, we are here to talk about our latest issue. And let's see who was that curator. Oh, yeah. It was me before I got this bad cold. So luckily, I was able to knock out some awesome resources here. Really terrific stuff we're gonna be talking about today. And as always, I have tremendous help from my fellow curators and contributors like all of you around the world. I will be honest. There weren't any poll requests this time, but luckily, many of you have submitted your websites to rweekly.org, so you're able to grab that content dynamically and put it into this issue.
So without further ado, here we go with a very important highlight to start with because version r4.4.0, codenamed puppy cup, has been released as of last week. And as always, it's always a big event whenever a new version of r has been released, and a great summary of the big changes has been put together by Russ Hyde, who is a data scientist at Jumping Rivers. And Russ leads off this post on the latest updates of 4.40 with a very interesting example on a concept that I don't take as much advantage of, although it can be very important, especially in situations where you don't quite know how to get to the right answer, so to speak.
And this example is, of course, based on recursion. And, again, this is a paradigm often used when we're trying to get a close approximation to a type of solution. But, again, the path to that made me unclear, so to speak. So we may have to approximate running a function over and over again and then maybe build some either stopping rules or other criteria to say, how close are we? Are we close enough? And the example in the post that Russ puts in here is having to do a finding zeros in a mathematical function, such as, like, the sine curve and whatnot. He has a nice example of, like, if you're gonna build this function from scratch, how you might how you might approach it. He is quick to mention that there is a a built in function in R that would be better for this, but he calls this a bisect function and it's got some mathematical operations under the hood. But at the end, you'll notice it calls BISECT again right at the end of the code. So this is gonna keep running until it hits the right criteria for, say, getting that answer in a tolerance limit. Now beforehand, you might not know how many times this is gonna have to be called. You hope it's not very much, but it could be it's gonna be called quite a bit, perhaps 1,000 or even 1,000,000 of times.
And what happens when that happens? You fall victim to a Stack Overflow error. And there's probably a generation of listeners on this show who may think a Stack Overflow is a website to get programming help, but this is actually a CS term when you have these function results that are built on top of this stack, usually based in c or whatnot. But in r, you may have encountered this unwillingly if you accidentally put recursion in your paradigm, and it just ends up blowing up the stack, and then r will literally crash saying, you know what? I got too much in this stack. I don't know what to do with myself kinda thing. In version 440 of r, there is now a new function called tail call, which is gonna be basically a drop in replacement for that last call to your function at the end of the original function where instead of, like, doing, in this case, the bisect call again at the end, you're gonna put bisect into this tail call function.
The motivation for this is that r is only going to keep track of that last call that ended up knee being necessary for the solution instead of all those intermediate calls beforehand. Hence, you could have a recursive function ends up being used, say, 1,000,000 of times, but that call stack is only gonna retain what it needed at the end, so to speak. Now I admit, I don't do recursion very much, but I can definitely see how useful this will be in situations where you're probably gonna need some additional iterations before you get to that elegant solution that you're trying to solve.
So they do mention it is experimental because this is a brand new function, so, hopefully, it'll work well for your use cases and recursion. But certainly a welcome feature for those of you in the approximation realm. And I deal with this a lot in simulations as well, so that will be a very nice usability enhancement for my recursion workflows. But of course, there is much more here, too. And also new to R is the introduction of a nice and elegant way to deal with those null values and conditionals. And, Mike, why don't you tell us about that? Yeah. This is something that's been in Arling for quite a while now,
[00:06:33] Mike Thomas:
that I've seen, you know, in a lot of source code that I've taken a look at online but maybe not realized, and and haven't used it myself either and and not realized that it's not in base r. So it's this operator and if you want to write it, it is 4 characters, percent sign, pipe pipe percent sign. And essentially what it does is it evaluates the left hand side of that pipe and it says if that left hand side is null return what's on the right hand right hand side of the pipe. So it's it's a sort of a shorthand for is dot null, essentially for evaluating maybe conditional, if statements, flow control type statements, and just making, your code a little bit more concise that you don't have to write out that full is null, you know, else statement if you want. So especially if if you're someone maybe developing in our package or something like that where you are trying to test to see if a particular element is null and if it is, you want to return maybe a message or a different object or something like that just because you're trying to program defensively, which is something that we all try to do, in all of our work, I think this this shorthand operator could potentially be your friend there and may reduce the need to import Arlang, although I haven't written an R package where I don't have to bring in our where I haven't brought in Arlang in quite a long time.
But maybe it'll still be useful, you know, in your local scripts if if you don't need Arlang as well and you just wanna have this particular operator handy. So very excited to see this operator come into Besar. I think it's, I think it's a good a good decision by the ArcCorp team. I know it's probably not a trivial thing to add, you know, an operator to base r, and that's probably, actually a fairly big decision at the end of the day. But I believe that its use is is so widespread probably at this point that it makes sense for them to have done that. So that's a a nice little inclusion that we have in our 4 dot 4. One additional thing that is introduced as well is this new shorthand hexadecimal format, which I guess is common in in web programming. And and you can think about, you know, specifying your your hex codes for your colors. Right? Maybe in your ggplots or something like that. And most of the time, if we're we're trying to specify a particular hex code, we have to write it out all 6 digits out, you know, except maybe in the case of, some hex code that has a repeating pattern, you know. I think of black and white. It's just f f f and and 0.
Right? Sometimes you don't need to write those all the way out. But, I guess the the shorthand allows you to translate a code like 112233 to just, you know, pound sign 123 or hashtag 123 for the kids out there. So it's interesting, that that we now have this shorthand textadecimal format. There's some additional, improvements around parsing and formatting complex numbers if you're someone that leverages complex numbers in your R code, I can't say that that I'm one as well. And then probably the the last one which may be arguably the most useful is this new sort by function, sort underscore by. And it allows you to essentially sort a data frame typically based upon 1 or more columns, that you could specify in a list if you have multiple columns or you can just provide that one column to the sort by function.
And, you know, I I think it's it's really interesting that we have that now. It's it's going to make, everybody's life easier to to sort of data frame in base r,
[00:10:18] Eric Nantz:
by 1 or more columns. So nice little handy improvement as well. Yeah. There there is much more to it. So Russ links, and we'll put a link in this as well to the full news file of the the all the updated changes. And he also concludes we're we're just talking about containers earlier, Mike. A great way for you to try r 44, if you don't wanna put it on your system right away, is to leverage Docker containers. Then he's got a simple example of pulling that, into into your system, and it's very easy to do, 2 lines in in each of those cases. And you may wanna look at this sooner or later because I you you can't write this you can't script this, so to speak, but literally the morning after I released our weekly, this updated issue, A news item that's been making the waves, and we'll probably have a lot more to say possibly next week on, is that for possibly the first time ever, there has been a critical vulnerability exploit discovered for the r language with respect to potential malicious code that could be inserted into what's called the RDS file format, which for those that aren't familiar, is a way for you to serialize our objects into a binary type format that's tailored to what R can use to import and export.
Now there's a lot you know, I think there's a lot of information that's still going to be shared, without throughout the community on this. But if you're in an organization or you help consult with an organization, it may be worth informing them about this in case they wanna update their r version of 44 now that that's been released. And that's important because r44 event has been set to fix this vulnerability. So it would only be previous versions of r that could be potentially vulnerable to this. Like I said, I imagine we'll have more to say about this in the coming weeks because there's still a lot to digest here, but that is something for awareness. If you were you're on the fence about updating, that might, push you onto that edge sooner than later.
[00:12:20] Mike Thomas:
No. That's a great call out, Eric. And, yes, I I agree that I think we'll probably be hearing more about this story and maybe it's Genesis within the next week. Perhaps, something that we can talk about in more depth in the highlights next week, but I I guess it's good to see that this has been, you know, detected. This has been, you know, run up the food chain where it needs to be run up to and folks are investigating and it sounds like it's been remedied actually in in r4.4. So I think now it's it's sort of about spreading the word, maybe doing some sort of, you know, post mortem analysis to see if there's any other places within r that could potentially be impacted by this vulnerability or the way that r sort of serializes and and deserializes, data and, it's it's very interesting you know to to see this come across.
[00:13:21] Eric Nantz:
And for our last couple highlights here, we're gonna visit our friendly, old Shiny Corner here because we got 2 terrific highlights having to do with Shiny itself that we'll touch on here. And actually, both of these are fresh off some presentations that were shared at the recent Appsilon Shiny conference. So lots of momentum from that. And first, we're going to dive into a very nice kind of usability enhancement for you as you bootstrap these Shiny apps and you want to take advantage of the latest and greatest best practices.
And in particular, we're going to talk about a post by Garrick Aiden-Buie, who is a software engineer on the Shiny team at Posit. And he mentions in this post that a big initial focus in his 1st year with the team has been, you know, enhancing the bslib package, which Mike and I have been singing the praises of for over a year now, I believe, of this package. But for those that aren't aware, bslib kinda started off as a way to bring in the modern bootstrap styling into your Shiny apps without it affecting the Shiny core package itself. So this is an additional package that you'll load with your Shiny apps. And with it came some really nice new takes on layout functions, such as page sidebar and other, layouts that are very well tailored for dashboards and much more, as he says. Well, it's one thing to be a SLIB out there. It's one thing to have these examples out in the community, you know, say, with the package vignettes, the package website, and whatnot.
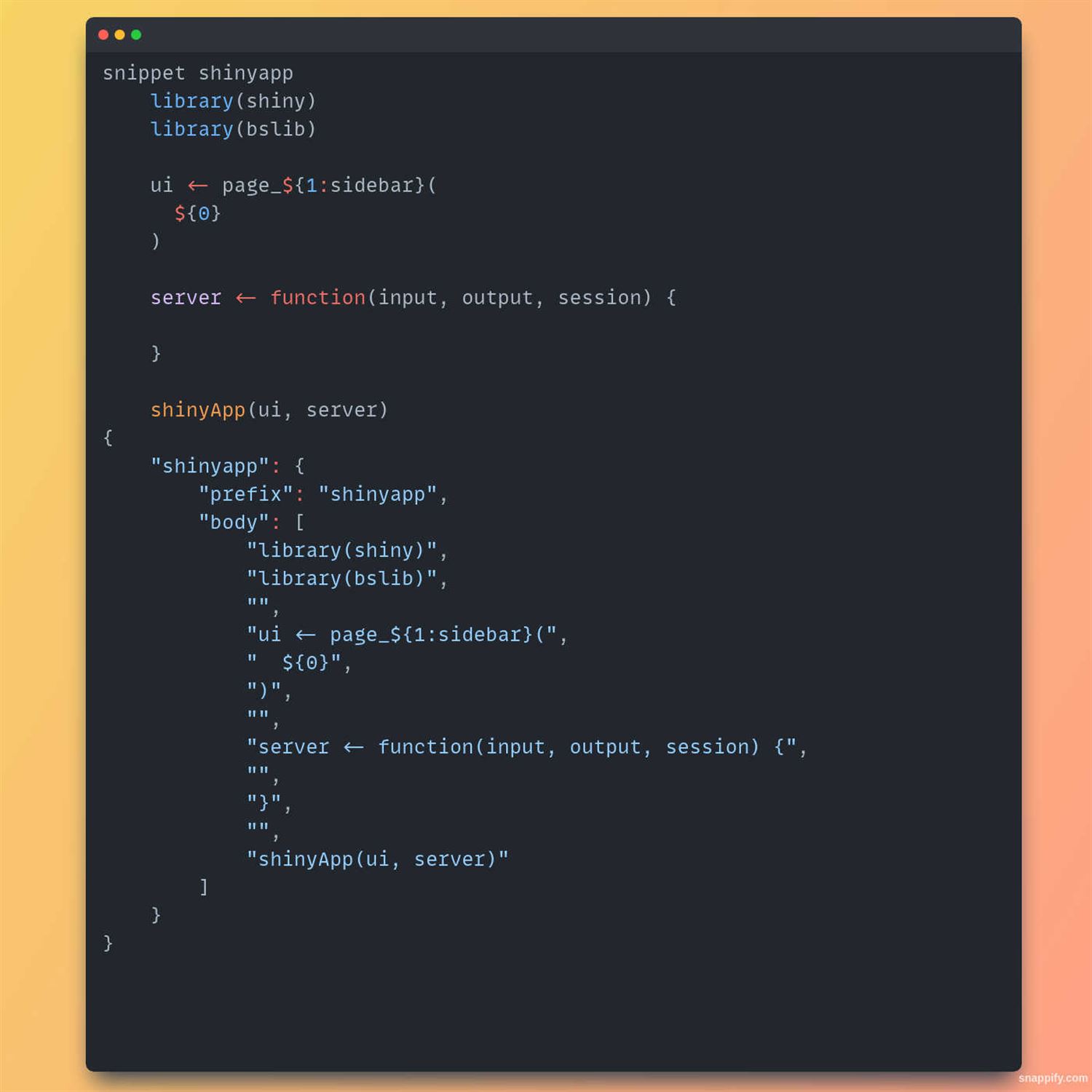
But there has always been a feature that many have taken advantage of in their development environments to quickly get Shiny apps up and running with a traditional sidebar layout, and that's the use of snippets. So in in RStudio Workbench or RStudio IDE, for example, there are a handful of built in snippets, including one to get a Shiny app off the ground. But you'll notice that this Shiny app is using the traditional Shiny package itself with its sidebar functions. And what Garrick does in this post is shows you how to quickly update that to take advantage of bslibs page sidebar layout so that you can get started right away with using bslib in your app. And it is super helpful, especially if you're going to be building these on a routine basis and you want to be able to not have to refactor your code after you get that initial snippet off the ground and say, oh, wait. No. I I wanna pivot the BS flips thing for this. So great. Yeah. Now you can have this snippet added in your Rstudio or update your snippet, I should say, in your Rstudio IDE's available snippets.
But there is more. This was an intriguing thing I've seen from somebody at Pasa themselves is that he also calls out a simple way for you to update or add a new snippet in your Versus Code snippets as well, which I know has been used heavily in a lot of Shiny app development these days. We in fact, at the recent Appsilon Shiny conference, we had a lot of people spreading enthusiasm about using Versus Code for more complicated setups. So Garrick has an example at this post of how you can add this snippet that looks very similar to the one that you would add in our studio's snippets feature, just a little bit more quoting around it. And let's say JSON, you know, syntax. But once you have it, then you can get that same functionality in in Rstudio or Versus Code. So take your pick. You're gonna have a nice snippet that you can use to get yourself started with BS Lib right away, right on the right foot.
[00:16:57] Mike Thomas:
Yeah, Eric. That's a great find, and snippets are something that I feel like I was very late to the game taking advantage of. But nowadays, you know, especially when I'm creating, like, small reprexes or examples or stuff like that for clients, you know, the the little Shiny app snippet that I get in R Studio is so much faster. It probably saves me a minute or 2 of actually creating that that UI in that server and loading Shiny at the header. So this is fan and I haven't really explored the concept of, like, creating your own snippets, but this is just a really nice simple walk through by Garrick on on how you could go about doing this in either RStudio or Versus Code. So it's definitely something that I need to start taking advantage of a little bit more because it is such a time saver. It's such a no brainer.
And as Garrick sort of outlines in this post here, it's easy. It's it's not difficult at all to get up and running with. So, fantastic walkthrough by Garrick. And, you know, just like you, Eric, I am all bslib all the time when it comes to Shiny apps these days. So having some shorthand that actually sort of skeletons out the bslib app as opposed to having to edit what gets returned from the old Shiny app snippet, to conform to a bslib type structure is just going to additionally save that amount of time and and make my workflows more efficient.
[00:18:20] Eric Nantz:
Yeah. You're you're right. I've been late to the snippet game as well, but I think to myself, what are on top of, like, getting the app, you know, boilerplate going, I have a bunch of widgets that I use every single time in my apps. In particular, I've always been a big fan of the ones such as picker input from Shiny Widgets, for example. I should have a snippet just to get one of those off the ground very quickly. I mean, there's you could take this to many different levels. But, yeah, anything to save you time to get this off the right way and then kind of reducing that manual effort of maybe just copy and pasting that snip that thing from one app to another. Oh, I gotta change the input and the ID and all this jazz. This can be a very efficient way for many aspects of Shiny development to to streamline your workflow.
[00:19:05] Mike Thomas:
Absolutely.
[00:19:21] Eric Nantz:
And our last highlight for today, again, we're gonna stay in the shiny corner for this. But Mike and I both agree we are blown away in very positive ways from what we're seeing in this summary here. And this is actually a presentation that was given at the aforementioned Appsilon Shiny Conference. And this was given by Lindsay Jorgensen, who is a director of business intelligence at Athos and as well as John Coene, who, Mike and I know very well, has been a prominent member of the shiny community all of these years. He actually is the CTO of the Y company that he cofounded earlier this year. So that's a new venture on his part. But they co presented a presentation called Tailoring Shiny for Modern Users.
And the motivation for this was in this organization, as ASDOS, they have, which stands for Association of State and Territorial Health Officials, they usually they conduct on a regular basis a longitudinal type census every 3 years, and they started this back in 2007 to help get some information with respect to potential funding and other projects that are happening at the state level for these different agencies. The results of these are very instrumental, apparently, for monitoring trends, advocating for additional funding, informing their future strategies, and much more.
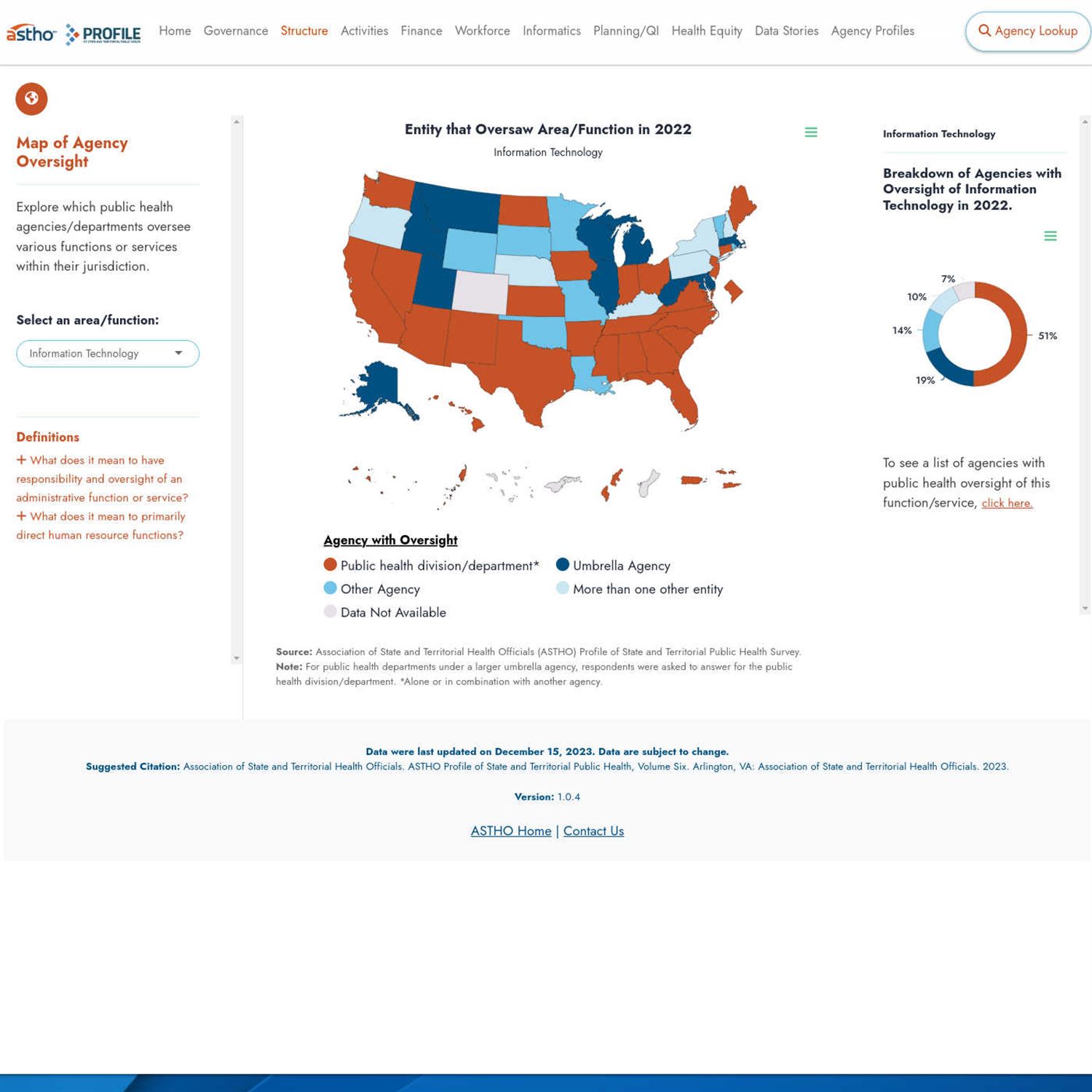
So lots of data to deal with. And, of course, what's a good way to deal with these data? Let's throw this into a dashboard for end users to review. And the previous generation of this dashboard was built with Tableau where everything was in a kinda one interface layout, And certainly it looked functional. I never used it, but it definitely looked functional. But everything, like I said, is in kind of the single view and may or may not leave a little bit to be desired. Well, fast forward to the way they approach refactoring this with usability in mind and design in mind. So they took a step back and they modernized the user interface approach with this, I'll call, 3 column type layout, Where on the left, they've organized the inputs and not just, like, throwing all the inputs top to bottom in a a huge sidebar they have to scroll down on to actually see everything.
They've sub you know, they kinda compartmentalize these in different unique tabs at the top to get you focused on a few key inputs at a time and be able to click through these, different, like, tabs or organization so it's not overwhelming you right away. And then in the middle is like the main content. In this case, it's a lot of interactive additional context for that result. Maybe it's links to additional information or other information that would be useful as you're reviewing those visual results. And they have this kind of unified approach for the different tabs representing different analysis, you know, results all within the same application.
But, Mike, I when you look at this, there is almost no way you can tell this is a shiny f. This just looks absolutely fantastic. And on top of that, they even looked at accessibility as a first class citizen, so to speak, and how they built the colors of this as well. There's just so much going on here. It's just amazing stuff.
[00:22:47] Mike Thomas:
This is one of the best designed, like, websites in general, you know, information based websites, dashboards, whatever you wanna call it that I've ever seen, shiny or not. It's it's so clean. It's so thorough. It's incredibly thorough. You know, just some of the concepts that get employed here around displaying information and and trying to minimize clutter, you know, when there's sort of long explanations they cut it off after after 4 lines with an ellipse but have a hyperlink to to read more where that will open up, you know, sort of a longer form screen to to read more context on that text. They have definitions which are, you know, expandable, and nicely collapsed. Like you said, these these Highcharts driven charts are are beautifully tool tipped on top that that have a really nice, really nice encapsulation of all the information that they're trying to display. One of the coolest things for me, Eric, that we talked about preshow a little bit was on some of these, charts pages, you know, they allow you to sort of add filters dynamically where you can, you know, click a single button that says add a filter, you select, I believe, the column that you want to use for filtering and then you select the different, value or values, within that column that you want to filter down the data to and and that, you know, results in filtering the information that gets displayed in the chart. But instead of having, you know, a bunch of different filters on screen already across all the different columns that are probably represented in the underlying dataset, that would probably clutter the screen with the idea that maybe the user only wants to to leverage 1 or 2 columns for filtering context.
You know, don't create that clutter right off the bat and allow the user to select as many filters as they want. It's a few extra clicks, but I think I'm sure that they paid a lot of attention to user experience and really got to know the audience that's gonna be using this this app and understand that, you know, maybe they're only using a couple filters, and and maybe it's it's certainly gonna change from user to user, then it would make sense to to go with that approach. But, again, you know, that approach just makes everything super clean on screen and it I'm still blown away. I think I'm probably gonna it's gonna be very difficult for me to navigate away from this app today and actually start doing my work, as opposed to just playing in here, and desperately, you know, begging John and Lindsay for the source code behind this app.
But, it's it's one of the most beautiful apps I've I've ever seen. So I'm very grateful that they, you know, at least shared this app with us. I I think if nothing else, you know, and we don't get access to the source code or anything like that, the design ideas behind this are are just fantastic. And as I told you earlier, Eric, it just makes me want to go into all of our Shiny app projects and just immediately refactor them and bring in some of these principles because I feel like our work is light years away from what they've put together here. It is the the best way that I can describe it is just so clean.
[00:26:02] Eric Nantz:
It's so clean, so organized, and they're it's the perfect balance of making sure the user is seeing what they need to see first, but then letting them opt into additional context, additional information without thinking like, oh, they might want this. I'm gonna throw it on there. I'm gonna throw it on this other side. I'm gonna throw it on this footer. Like, it it will just drive you nuts. And, yes, I have seen many dashboards that were built with Shiny or things like Power BI that just become so cluttered with everything in your face, so to speak.
This, the organization at the top nav bar, but then within these sidebars, not overwhelming us of all the inputs at once. I mean, these are it is just it takes so it it just means that if you pay attention to detail on this early on, I mean, you're just gonna set you up for so much success for a wider range of customers or audience for your app and really taking advantage of these modern principles. Are quite overwhelming. Even though they're meant for statisticians, I don't think a statistician should have to suffer, so to speak, from information overload. So there are definitely techniques from here I wanna take into my production apps. Now the one thing they have open sourced, is this concept of what they call the data stories feature, where in the app itself, you will see this gallery of these different kinda more long form articles, but they're very nicely organized, kinda like a scrolly teletype setup a little bit. But then as you scroll, you get this nice interspersed set of narrative with the aforementioned visualizations and really a great way to kind of break apart visually, so to speak, these different sections. So there is an example repo for that that we will link to in the show notes if you wanna take advantage of that feature in your development. But, yeah, I'm gonna have to fight the urge to refactor all my apps now. But I do think I will refactor some of my apps. Just kidding.
[00:28:01] Mike Thomas:
I'm in the same boat, and it looks I this is deployed on Shiny apps dot io. One of the interesting things is that there is a, you know, extension on that Shinyapps.ioURL, where it's backslash profile. Makes me wonder if they're using some sort of a multi page approach here with brochure or maybe John didn't John have a a project called Ambiorix or something like that that Yeah. He does. That's right. Was leveraged here to have that sort of multi page possibility. So that would be interesting as well to see if there's any of that employed. But for how big this app is and where it's deployed on Shiny apps dot io, it's quite performant. So I'm sure they paid a lot of attention to trying to minimize the overhead on the on the back end as well. So very, very impressive.
[00:28:49] Eric Nantz:
Yep. And, I'll I'll put this out there, and I don't know when it will be yet. But I did, I was very enthusiastic about what I saw here, and I did get in touch with Lindsey, and she does seem receptive to being to joining me on a future shiny dev series episode. We're hopefully be able to dive into a lot of the technical bits on this in the future because I think it's a excellent story to tell, not just the the journey to get here to these principles, but actually how she pulled it off. So stay tuned for that. I don't know when yet, but you will know when when it's ready for that. But there's a lot more to stay tuned for because the rest of the Wiki issue has a boatload of additional resources, whether it's new tutorials, new packages, and updated packages. And I dare say this might be my biggest package section update yet because I got a lot to choose from here and a lot of great innovations across all different areas of of our and we'll take a couple of minutes for our additional finds in this in this segment like we always do.
I've been, you know, a very big proponent, especially on my interactions of HPC systems, being on the command line, so to speak, you know, getting down and dirty with my data, quick inspections, you know, like Ed or tail of the last few rows. And I've I've been, you know, very enamored by some of these tools in the Linux community that let you profile performance of your system. There's something called HTOP and VTOP, etcetera. You can see, like, in real time your system performance and these nice line charts and stuff. Well, if you want that similar situation with R, guess what? There is a brand new pack that's released to CRAN called plot CLI, which has been authored by Klasheuer.
Hopefully, I'm saying that right. And like I said, it just hit CRAN recently. And this is going to take a very traditional type ggplot and convert it to a special object that you can print in the terminal and get nice coloring and symbol representation, which if you can't get to, like, say, a POSIT or RStudio IDE or a Versus Code instance, this might be a great thing to do if you're on that lower level, so to speak, with that HPC system and wanna look at a quick visualization. So I'm really excited about that. And, Mike, what did you wanna talk about? Oh, very cool find, Eric.
[00:31:05] Mike Thomas:
You know, not to be, morbid here sort of at the end of the show, but I think it it certainly warrants talking about, there is Fritz Leisch, passed away recently, and and Fritz was a member of, really the the core our project team. He helped cofound CRAN, if you can believe that, with Kurt Ornic, and that was, I think, around 1997. Yeah. He worked at Vienna University of Technology, and then moved to the University of Munich. I was a professor in computational statistics and became the head of that department actually in 2010 before moving back to to Vienna in in 2011 to to to work at the University of Natural Resources and Life Sciences.
So a very impressive career. One of his also additional contributions, I mean, this this almost sounds sounds made up, is that he actually developed the sWeave system that allows you to combine our and LaTeX into a single document which obviously is sort of, you know, the the core engine and how the Knitter project sort of came about and was built on top of, and now we have quarto sort of on top of that. So and I'm imagining that that also predates things like Jupyter Notebooks. So that idea of, you know, creating sort of reproducible research that encompasses both your your code and your narrative and your figures and your tables and your output like that, is is largely, I have to imagine, due to Fritz's work which is incredible.
You know, they also note that that led to, you know, the ability to create our package vignettes which obviously is something that's super powerful, I think, in the our ecosystem because it provides us with a way to give end users documentation that is does not necessarily exist or is not as thorough, or or beautiful, in my opinion, as what some other languages offer in terms of documentation around their packages. So, you know, he they say that in his, professorship, he he taught generations of of students, at bachelor, master, and PhD level, introduced 100 of, R users to to proper R development workflows, and he is going to be extremely missed by the our core team and the our community, and we're incredibly grateful for his contributions to the our ecosystem and really allowing us what allowing us the ability to do what we do on a daily basis. So, definitely some sad news, but I guess maybe a time to reflect and and be grateful for the legacy that he leaves behind.
[00:33:53] Eric Nantz:
Yeah. Yeah. Thank you for that, Mike. Very well summarized. And, again, our our deepest condolences to his family and close friends and, yeah, the rest of the our core team. But I I mentioned this before either on this or my, older podcast. My dissertation was written in s sweep. It was revolutionary to me how I could literally without having to do the old copy paste method, I could get that plot, get that table into my LaTeX file. And just think of what's been built on top of that paradigm, as you said. That that cannot be understated, and we're really fortunate that we've been able to take advantage of these ideas, that that he's created, since the very beginning of our basically. So it is so many so many innovations that he's brought to the project that brought to the community.
It yeah. I definitely am very appreciative of everything he's accomplished. And, you know, it's always a it's always a time to reflect back and really appreciate what we have. And the innovations have to start somewhere. And he was one of those instrumentals to get the R project going. So definitely thank you for mentioning that. And also, you know, we always love to hear from all of you as well with respect to the R weekly project and this very podcast here. And again, one of our favorite parts of this job is to be able to showcase what all of you are building in this community and extending some of those great ideas. And if you want to get in touch with us, there's a few ways to do that. You can use the contact page directly in this episode's show notes. And also, if you want to contribute to our weekly itself, we have a link to contribution in terms of a poll request to the upcoming issue draft. You just click the right hand corner at the top. You'll get directly linked to GitHub for a poll request template, all marked down all the time. You know how it goes. I don't have to keep saying it anymore.
And if you have a modern podcast app, such as, Podverse, Fountain Cast o Matic, and CurioCaster, you can send us fun little boosts along the way to give us a little encouragement and show your value of liking the show. And, also, you can get in touch with me on social media these days. I am on Mastodon at @[email protected]. I'm also on LinkedIn under my name, Eric Nantz. You'll see, tweets are posted from time to time and sometimes on that x thingy at @theRcast. And, Mike, before my voice completely goes haywire, where can the listeners find you? You're hanging on pretty well, Eric. Yeah.
[00:36:19] Mike Thomas:
You can find me on mastodon at [email protected], Ketchbrook Analytics, k e t c h b r o o k. There's too many Mike Thomases out there, so you're better off looking that way. I'm gonna need to recharge my batteries now, so we're gonna close-up shop here on episode
[00:36:41] Eric Nantz:
163. We thank you so much for listening, especially to my horrid voice here. And, hopefully, I'll be back to normal shape and as well as to talk to you about awesome new resources for our next episode, which is coming up next week.
Hello, friends. We're back of episode 163 of the Our Weekly Highlights podcast. This is the weekly show showcasing the latest innovations and terrific resources that have been highlighted at ourweekly.org. My name is Eric Nanson. If you couldn't tell already, your your trusty host here is feeling a little bit under the weather here, but I'm gonna power through this because it's always exciting to talk about awesome art content with my trusted cohost right here virtually, Mike Thomas. Mike, I hope you're doing better than I am these days.
[00:00:34] Mike Thomas:
I am, Eric. My allergies are in full bloom. Had a little bit of a tough time on the the golf course on Sunday, both allergy wise and golfing wise. But, we'll not talk about the latter. And but everything else is is going pretty well. I'll tell you what also bloomed was engagement on my LinkedIn post on dev containers. So keep gonna keep rolling on that topic. It seems like it's something that people enjoy hearing about. Yeah. I'm really excited to see see how much that took off, and I am
[00:01:07] Eric Nantz:
super thrilled that it's helping your team, you know, enhance your work flows. And, you know, once you once you go that route, it's very hard to go back because it just makes things so much easier to get effective collaboration in your dev environments because ain't nobody got time for package mismatches and all that fun jazz. Right? No. And system dependencies, system libraries, and stuff like that not being installed.
[00:01:30] Mike Thomas:
Yeah. It's it's really changed the game for us from a collaboration standpoint. It it makes collaboration pretty much frictionless, which is amazing.
[00:01:39] Eric Nantz:
And, yes, we are here to talk about our latest issue. And let's see who was that curator. Oh, yeah. It was me before I got this bad cold. So luckily, I was able to knock out some awesome resources here. Really terrific stuff we're gonna be talking about today. And as always, I have tremendous help from my fellow curators and contributors like all of you around the world. I will be honest. There weren't any poll requests this time, but luckily, many of you have submitted your websites to rweekly.org, so you're able to grab that content dynamically and put it into this issue.
So without further ado, here we go with a very important highlight to start with because version r4.4.0, codenamed puppy cup, has been released as of last week. And as always, it's always a big event whenever a new version of r has been released, and a great summary of the big changes has been put together by Russ Hyde, who is a data scientist at Jumping Rivers. And Russ leads off this post on the latest updates of 4.40 with a very interesting example on a concept that I don't take as much advantage of, although it can be very important, especially in situations where you don't quite know how to get to the right answer, so to speak.
And this example is, of course, based on recursion. And, again, this is a paradigm often used when we're trying to get a close approximation to a type of solution. But, again, the path to that made me unclear, so to speak. So we may have to approximate running a function over and over again and then maybe build some either stopping rules or other criteria to say, how close are we? Are we close enough? And the example in the post that Russ puts in here is having to do a finding zeros in a mathematical function, such as, like, the sine curve and whatnot. He has a nice example of, like, if you're gonna build this function from scratch, how you might how you might approach it. He is quick to mention that there is a a built in function in R that would be better for this, but he calls this a bisect function and it's got some mathematical operations under the hood. But at the end, you'll notice it calls BISECT again right at the end of the code. So this is gonna keep running until it hits the right criteria for, say, getting that answer in a tolerance limit. Now beforehand, you might not know how many times this is gonna have to be called. You hope it's not very much, but it could be it's gonna be called quite a bit, perhaps 1,000 or even 1,000,000 of times.
And what happens when that happens? You fall victim to a Stack Overflow error. And there's probably a generation of listeners on this show who may think a Stack Overflow is a website to get programming help, but this is actually a CS term when you have these function results that are built on top of this stack, usually based in c or whatnot. But in r, you may have encountered this unwillingly if you accidentally put recursion in your paradigm, and it just ends up blowing up the stack, and then r will literally crash saying, you know what? I got too much in this stack. I don't know what to do with myself kinda thing. In version 440 of r, there is now a new function called tail call, which is gonna be basically a drop in replacement for that last call to your function at the end of the original function where instead of, like, doing, in this case, the bisect call again at the end, you're gonna put bisect into this tail call function.
The motivation for this is that r is only going to keep track of that last call that ended up knee being necessary for the solution instead of all those intermediate calls beforehand. Hence, you could have a recursive function ends up being used, say, 1,000,000 of times, but that call stack is only gonna retain what it needed at the end, so to speak. Now I admit, I don't do recursion very much, but I can definitely see how useful this will be in situations where you're probably gonna need some additional iterations before you get to that elegant solution that you're trying to solve.
So they do mention it is experimental because this is a brand new function, so, hopefully, it'll work well for your use cases and recursion. But certainly a welcome feature for those of you in the approximation realm. And I deal with this a lot in simulations as well, so that will be a very nice usability enhancement for my recursion workflows. But of course, there is much more here, too. And also new to R is the introduction of a nice and elegant way to deal with those null values and conditionals. And, Mike, why don't you tell us about that? Yeah. This is something that's been in Arling for quite a while now,
[00:06:33] Mike Thomas:
that I've seen, you know, in a lot of source code that I've taken a look at online but maybe not realized, and and haven't used it myself either and and not realized that it's not in base r. So it's this operator and if you want to write it, it is 4 characters, percent sign, pipe pipe percent sign. And essentially what it does is it evaluates the left hand side of that pipe and it says if that left hand side is null return what's on the right hand right hand side of the pipe. So it's it's a sort of a shorthand for is dot null, essentially for evaluating maybe conditional, if statements, flow control type statements, and just making, your code a little bit more concise that you don't have to write out that full is null, you know, else statement if you want. So especially if if you're someone maybe developing in our package or something like that where you are trying to test to see if a particular element is null and if it is, you want to return maybe a message or a different object or something like that just because you're trying to program defensively, which is something that we all try to do, in all of our work, I think this this shorthand operator could potentially be your friend there and may reduce the need to import Arlang, although I haven't written an R package where I don't have to bring in our where I haven't brought in Arlang in quite a long time.
But maybe it'll still be useful, you know, in your local scripts if if you don't need Arlang as well and you just wanna have this particular operator handy. So very excited to see this operator come into Besar. I think it's, I think it's a good a good decision by the ArcCorp team. I know it's probably not a trivial thing to add, you know, an operator to base r, and that's probably, actually a fairly big decision at the end of the day. But I believe that its use is is so widespread probably at this point that it makes sense for them to have done that. So that's a a nice little inclusion that we have in our 4 dot 4. One additional thing that is introduced as well is this new shorthand hexadecimal format, which I guess is common in in web programming. And and you can think about, you know, specifying your your hex codes for your colors. Right? Maybe in your ggplots or something like that. And most of the time, if we're we're trying to specify a particular hex code, we have to write it out all 6 digits out, you know, except maybe in the case of, some hex code that has a repeating pattern, you know. I think of black and white. It's just f f f and and 0.
Right? Sometimes you don't need to write those all the way out. But, I guess the the shorthand allows you to translate a code like 112233 to just, you know, pound sign 123 or hashtag 123 for the kids out there. So it's interesting, that that we now have this shorthand textadecimal format. There's some additional, improvements around parsing and formatting complex numbers if you're someone that leverages complex numbers in your R code, I can't say that that I'm one as well. And then probably the the last one which may be arguably the most useful is this new sort by function, sort underscore by. And it allows you to essentially sort a data frame typically based upon 1 or more columns, that you could specify in a list if you have multiple columns or you can just provide that one column to the sort by function.
And, you know, I I think it's it's really interesting that we have that now. It's it's going to make, everybody's life easier to to sort of data frame in base r,
[00:10:18] Eric Nantz:
by 1 or more columns. So nice little handy improvement as well. Yeah. There there is much more to it. So Russ links, and we'll put a link in this as well to the full news file of the the all the updated changes. And he also concludes we're we're just talking about containers earlier, Mike. A great way for you to try r 44, if you don't wanna put it on your system right away, is to leverage Docker containers. Then he's got a simple example of pulling that, into into your system, and it's very easy to do, 2 lines in in each of those cases. And you may wanna look at this sooner or later because I you you can't write this you can't script this, so to speak, but literally the morning after I released our weekly, this updated issue, A news item that's been making the waves, and we'll probably have a lot more to say possibly next week on, is that for possibly the first time ever, there has been a critical vulnerability exploit discovered for the r language with respect to potential malicious code that could be inserted into what's called the RDS file format, which for those that aren't familiar, is a way for you to serialize our objects into a binary type format that's tailored to what R can use to import and export.
Now there's a lot you know, I think there's a lot of information that's still going to be shared, without throughout the community on this. But if you're in an organization or you help consult with an organization, it may be worth informing them about this in case they wanna update their r version of 44 now that that's been released. And that's important because r44 event has been set to fix this vulnerability. So it would only be previous versions of r that could be potentially vulnerable to this. Like I said, I imagine we'll have more to say about this in the coming weeks because there's still a lot to digest here, but that is something for awareness. If you were you're on the fence about updating, that might, push you onto that edge sooner than later.
[00:12:20] Mike Thomas:
No. That's a great call out, Eric. And, yes, I I agree that I think we'll probably be hearing more about this story and maybe it's Genesis within the next week. Perhaps, something that we can talk about in more depth in the highlights next week, but I I guess it's good to see that this has been, you know, detected. This has been, you know, run up the food chain where it needs to be run up to and folks are investigating and it sounds like it's been remedied actually in in r4.4. So I think now it's it's sort of about spreading the word, maybe doing some sort of, you know, post mortem analysis to see if there's any other places within r that could potentially be impacted by this vulnerability or the way that r sort of serializes and and deserializes, data and, it's it's very interesting you know to to see this come across.
[00:13:21] Eric Nantz:
And for our last couple highlights here, we're gonna visit our friendly, old Shiny Corner here because we got 2 terrific highlights having to do with Shiny itself that we'll touch on here. And actually, both of these are fresh off some presentations that were shared at the recent Appsilon Shiny conference. So lots of momentum from that. And first, we're going to dive into a very nice kind of usability enhancement for you as you bootstrap these Shiny apps and you want to take advantage of the latest and greatest best practices.
And in particular, we're going to talk about a post by Garrick Aiden-Buie, who is a software engineer on the Shiny team at Posit. And he mentions in this post that a big initial focus in his 1st year with the team has been, you know, enhancing the bslib package, which Mike and I have been singing the praises of for over a year now, I believe, of this package. But for those that aren't aware, bslib kinda started off as a way to bring in the modern bootstrap styling into your Shiny apps without it affecting the Shiny core package itself. So this is an additional package that you'll load with your Shiny apps. And with it came some really nice new takes on layout functions, such as page sidebar and other, layouts that are very well tailored for dashboards and much more, as he says. Well, it's one thing to be a SLIB out there. It's one thing to have these examples out in the community, you know, say, with the package vignettes, the package website, and whatnot.
But there has always been a feature that many have taken advantage of in their development environments to quickly get Shiny apps up and running with a traditional sidebar layout, and that's the use of snippets. So in in RStudio Workbench or RStudio IDE, for example, there are a handful of built in snippets, including one to get a Shiny app off the ground. But you'll notice that this Shiny app is using the traditional Shiny package itself with its sidebar functions. And what Garrick does in this post is shows you how to quickly update that to take advantage of bslibs page sidebar layout so that you can get started right away with using bslib in your app. And it is super helpful, especially if you're going to be building these on a routine basis and you want to be able to not have to refactor your code after you get that initial snippet off the ground and say, oh, wait. No. I I wanna pivot the BS flips thing for this. So great. Yeah. Now you can have this snippet added in your Rstudio or update your snippet, I should say, in your Rstudio IDE's available snippets.
But there is more. This was an intriguing thing I've seen from somebody at Pasa themselves is that he also calls out a simple way for you to update or add a new snippet in your Versus Code snippets as well, which I know has been used heavily in a lot of Shiny app development these days. We in fact, at the recent Appsilon Shiny conference, we had a lot of people spreading enthusiasm about using Versus Code for more complicated setups. So Garrick has an example at this post of how you can add this snippet that looks very similar to the one that you would add in our studio's snippets feature, just a little bit more quoting around it. And let's say JSON, you know, syntax. But once you have it, then you can get that same functionality in in Rstudio or Versus Code. So take your pick. You're gonna have a nice snippet that you can use to get yourself started with BS Lib right away, right on the right foot.
[00:16:57] Mike Thomas:
Yeah, Eric. That's a great find, and snippets are something that I feel like I was very late to the game taking advantage of. But nowadays, you know, especially when I'm creating, like, small reprexes or examples or stuff like that for clients, you know, the the little Shiny app snippet that I get in R Studio is so much faster. It probably saves me a minute or 2 of actually creating that that UI in that server and loading Shiny at the header. So this is fan and I haven't really explored the concept of, like, creating your own snippets, but this is just a really nice simple walk through by Garrick on on how you could go about doing this in either RStudio or Versus Code. So it's definitely something that I need to start taking advantage of a little bit more because it is such a time saver. It's such a no brainer.
And as Garrick sort of outlines in this post here, it's easy. It's it's not difficult at all to get up and running with. So, fantastic walkthrough by Garrick. And, you know, just like you, Eric, I am all bslib all the time when it comes to Shiny apps these days. So having some shorthand that actually sort of skeletons out the bslib app as opposed to having to edit what gets returned from the old Shiny app snippet, to conform to a bslib type structure is just going to additionally save that amount of time and and make my workflows more efficient.
[00:18:20] Eric Nantz:
Yeah. You're you're right. I've been late to the snippet game as well, but I think to myself, what are on top of, like, getting the app, you know, boilerplate going, I have a bunch of widgets that I use every single time in my apps. In particular, I've always been a big fan of the ones such as picker input from Shiny Widgets, for example. I should have a snippet just to get one of those off the ground very quickly. I mean, there's you could take this to many different levels. But, yeah, anything to save you time to get this off the right way and then kind of reducing that manual effort of maybe just copy and pasting that snip that thing from one app to another. Oh, I gotta change the input and the ID and all this jazz. This can be a very efficient way for many aspects of Shiny development to to streamline your workflow.
[00:19:05] Mike Thomas:
Absolutely.
[00:19:21] Eric Nantz:
And our last highlight for today, again, we're gonna stay in the shiny corner for this. But Mike and I both agree we are blown away in very positive ways from what we're seeing in this summary here. And this is actually a presentation that was given at the aforementioned Appsilon Shiny Conference. And this was given by Lindsay Jorgensen, who is a director of business intelligence at Athos and as well as John Coene, who, Mike and I know very well, has been a prominent member of the shiny community all of these years. He actually is the CTO of the Y company that he cofounded earlier this year. So that's a new venture on his part. But they co presented a presentation called Tailoring Shiny for Modern Users.
And the motivation for this was in this organization, as ASDOS, they have, which stands for Association of State and Territorial Health Officials, they usually they conduct on a regular basis a longitudinal type census every 3 years, and they started this back in 2007 to help get some information with respect to potential funding and other projects that are happening at the state level for these different agencies. The results of these are very instrumental, apparently, for monitoring trends, advocating for additional funding, informing their future strategies, and much more.
So lots of data to deal with. And, of course, what's a good way to deal with these data? Let's throw this into a dashboard for end users to review. And the previous generation of this dashboard was built with Tableau where everything was in a kinda one interface layout, And certainly it looked functional. I never used it, but it definitely looked functional. But everything, like I said, is in kind of the single view and may or may not leave a little bit to be desired. Well, fast forward to the way they approach refactoring this with usability in mind and design in mind. So they took a step back and they modernized the user interface approach with this, I'll call, 3 column type layout, Where on the left, they've organized the inputs and not just, like, throwing all the inputs top to bottom in a a huge sidebar they have to scroll down on to actually see everything.
They've sub you know, they kinda compartmentalize these in different unique tabs at the top to get you focused on a few key inputs at a time and be able to click through these, different, like, tabs or organization so it's not overwhelming you right away. And then in the middle is like the main content. In this case, it's a lot of interactive additional context for that result. Maybe it's links to additional information or other information that would be useful as you're reviewing those visual results. And they have this kind of unified approach for the different tabs representing different analysis, you know, results all within the same application.
But, Mike, I when you look at this, there is almost no way you can tell this is a shiny f. This just looks absolutely fantastic. And on top of that, they even looked at accessibility as a first class citizen, so to speak, and how they built the colors of this as well. There's just so much going on here. It's just amazing stuff.
[00:22:47] Mike Thomas:
This is one of the best designed, like, websites in general, you know, information based websites, dashboards, whatever you wanna call it that I've ever seen, shiny or not. It's it's so clean. It's so thorough. It's incredibly thorough. You know, just some of the concepts that get employed here around displaying information and and trying to minimize clutter, you know, when there's sort of long explanations they cut it off after after 4 lines with an ellipse but have a hyperlink to to read more where that will open up, you know, sort of a longer form screen to to read more context on that text. They have definitions which are, you know, expandable, and nicely collapsed. Like you said, these these Highcharts driven charts are are beautifully tool tipped on top that that have a really nice, really nice encapsulation of all the information that they're trying to display. One of the coolest things for me, Eric, that we talked about preshow a little bit was on some of these, charts pages, you know, they allow you to sort of add filters dynamically where you can, you know, click a single button that says add a filter, you select, I believe, the column that you want to use for filtering and then you select the different, value or values, within that column that you want to filter down the data to and and that, you know, results in filtering the information that gets displayed in the chart. But instead of having, you know, a bunch of different filters on screen already across all the different columns that are probably represented in the underlying dataset, that would probably clutter the screen with the idea that maybe the user only wants to to leverage 1 or 2 columns for filtering context.
You know, don't create that clutter right off the bat and allow the user to select as many filters as they want. It's a few extra clicks, but I think I'm sure that they paid a lot of attention to user experience and really got to know the audience that's gonna be using this this app and understand that, you know, maybe they're only using a couple filters, and and maybe it's it's certainly gonna change from user to user, then it would make sense to to go with that approach. But, again, you know, that approach just makes everything super clean on screen and it I'm still blown away. I think I'm probably gonna it's gonna be very difficult for me to navigate away from this app today and actually start doing my work, as opposed to just playing in here, and desperately, you know, begging John and Lindsay for the source code behind this app.
But, it's it's one of the most beautiful apps I've I've ever seen. So I'm very grateful that they, you know, at least shared this app with us. I I think if nothing else, you know, and we don't get access to the source code or anything like that, the design ideas behind this are are just fantastic. And as I told you earlier, Eric, it just makes me want to go into all of our Shiny app projects and just immediately refactor them and bring in some of these principles because I feel like our work is light years away from what they've put together here. It is the the best way that I can describe it is just so clean.
[00:26:02] Eric Nantz:
It's so clean, so organized, and they're it's the perfect balance of making sure the user is seeing what they need to see first, but then letting them opt into additional context, additional information without thinking like, oh, they might want this. I'm gonna throw it on there. I'm gonna throw it on this other side. I'm gonna throw it on this footer. Like, it it will just drive you nuts. And, yes, I have seen many dashboards that were built with Shiny or things like Power BI that just become so cluttered with everything in your face, so to speak.
This, the organization at the top nav bar, but then within these sidebars, not overwhelming us of all the inputs at once. I mean, these are it is just it takes so it it just means that if you pay attention to detail on this early on, I mean, you're just gonna set you up for so much success for a wider range of customers or audience for your app and really taking advantage of these modern principles. Are quite overwhelming. Even though they're meant for statisticians, I don't think a statistician should have to suffer, so to speak, from information overload. So there are definitely techniques from here I wanna take into my production apps. Now the one thing they have open sourced, is this concept of what they call the data stories feature, where in the app itself, you will see this gallery of these different kinda more long form articles, but they're very nicely organized, kinda like a scrolly teletype setup a little bit. But then as you scroll, you get this nice interspersed set of narrative with the aforementioned visualizations and really a great way to kind of break apart visually, so to speak, these different sections. So there is an example repo for that that we will link to in the show notes if you wanna take advantage of that feature in your development. But, yeah, I'm gonna have to fight the urge to refactor all my apps now. But I do think I will refactor some of my apps. Just kidding.
[00:28:01] Mike Thomas:
I'm in the same boat, and it looks I this is deployed on Shiny apps dot io. One of the interesting things is that there is a, you know, extension on that Shinyapps.ioURL, where it's backslash profile. Makes me wonder if they're using some sort of a multi page approach here with brochure or maybe John didn't John have a a project called Ambiorix or something like that that Yeah. He does. That's right. Was leveraged here to have that sort of multi page possibility. So that would be interesting as well to see if there's any of that employed. But for how big this app is and where it's deployed on Shiny apps dot io, it's quite performant. So I'm sure they paid a lot of attention to trying to minimize the overhead on the on the back end as well. So very, very impressive.
[00:28:49] Eric Nantz:
Yep. And, I'll I'll put this out there, and I don't know when it will be yet. But I did, I was very enthusiastic about what I saw here, and I did get in touch with Lindsey, and she does seem receptive to being to joining me on a future shiny dev series episode. We're hopefully be able to dive into a lot of the technical bits on this in the future because I think it's a excellent story to tell, not just the the journey to get here to these principles, but actually how she pulled it off. So stay tuned for that. I don't know when yet, but you will know when when it's ready for that. But there's a lot more to stay tuned for because the rest of the Wiki issue has a boatload of additional resources, whether it's new tutorials, new packages, and updated packages. And I dare say this might be my biggest package section update yet because I got a lot to choose from here and a lot of great innovations across all different areas of of our and we'll take a couple of minutes for our additional finds in this in this segment like we always do.
I've been, you know, a very big proponent, especially on my interactions of HPC systems, being on the command line, so to speak, you know, getting down and dirty with my data, quick inspections, you know, like Ed or tail of the last few rows. And I've I've been, you know, very enamored by some of these tools in the Linux community that let you profile performance of your system. There's something called HTOP and VTOP, etcetera. You can see, like, in real time your system performance and these nice line charts and stuff. Well, if you want that similar situation with R, guess what? There is a brand new pack that's released to CRAN called plot CLI, which has been authored by Klasheuer.
Hopefully, I'm saying that right. And like I said, it just hit CRAN recently. And this is going to take a very traditional type ggplot and convert it to a special object that you can print in the terminal and get nice coloring and symbol representation, which if you can't get to, like, say, a POSIT or RStudio IDE or a Versus Code instance, this might be a great thing to do if you're on that lower level, so to speak, with that HPC system and wanna look at a quick visualization. So I'm really excited about that. And, Mike, what did you wanna talk about? Oh, very cool find, Eric.
[00:31:05] Mike Thomas:
You know, not to be, morbid here sort of at the end of the show, but I think it it certainly warrants talking about, there is Fritz Leisch, passed away recently, and and Fritz was a member of, really the the core our project team. He helped cofound CRAN, if you can believe that, with Kurt Ornic, and that was, I think, around 1997. Yeah. He worked at Vienna University of Technology, and then moved to the University of Munich. I was a professor in computational statistics and became the head of that department actually in 2010 before moving back to to Vienna in in 2011 to to to work at the University of Natural Resources and Life Sciences.
So a very impressive career. One of his also additional contributions, I mean, this this almost sounds sounds made up, is that he actually developed the sWeave system that allows you to combine our and LaTeX into a single document which obviously is sort of, you know, the the core engine and how the Knitter project sort of came about and was built on top of, and now we have quarto sort of on top of that. So and I'm imagining that that also predates things like Jupyter Notebooks. So that idea of, you know, creating sort of reproducible research that encompasses both your your code and your narrative and your figures and your tables and your output like that, is is largely, I have to imagine, due to Fritz's work which is incredible.
You know, they also note that that led to, you know, the ability to create our package vignettes which obviously is something that's super powerful, I think, in the our ecosystem because it provides us with a way to give end users documentation that is does not necessarily exist or is not as thorough, or or beautiful, in my opinion, as what some other languages offer in terms of documentation around their packages. So, you know, he they say that in his, professorship, he he taught generations of of students, at bachelor, master, and PhD level, introduced 100 of, R users to to proper R development workflows, and he is going to be extremely missed by the our core team and the our community, and we're incredibly grateful for his contributions to the our ecosystem and really allowing us what allowing us the ability to do what we do on a daily basis. So, definitely some sad news, but I guess maybe a time to reflect and and be grateful for the legacy that he leaves behind.
[00:33:53] Eric Nantz:
Yeah. Yeah. Thank you for that, Mike. Very well summarized. And, again, our our deepest condolences to his family and close friends and, yeah, the rest of the our core team. But I I mentioned this before either on this or my, older podcast. My dissertation was written in s sweep. It was revolutionary to me how I could literally without having to do the old copy paste method, I could get that plot, get that table into my LaTeX file. And just think of what's been built on top of that paradigm, as you said. That that cannot be understated, and we're really fortunate that we've been able to take advantage of these ideas, that that he's created, since the very beginning of our basically. So it is so many so many innovations that he's brought to the project that brought to the community.
It yeah. I definitely am very appreciative of everything he's accomplished. And, you know, it's always a it's always a time to reflect back and really appreciate what we have. And the innovations have to start somewhere. And he was one of those instrumentals to get the R project going. So definitely thank you for mentioning that. And also, you know, we always love to hear from all of you as well with respect to the R weekly project and this very podcast here. And again, one of our favorite parts of this job is to be able to showcase what all of you are building in this community and extending some of those great ideas. And if you want to get in touch with us, there's a few ways to do that. You can use the contact page directly in this episode's show notes. And also, if you want to contribute to our weekly itself, we have a link to contribution in terms of a poll request to the upcoming issue draft. You just click the right hand corner at the top. You'll get directly linked to GitHub for a poll request template, all marked down all the time. You know how it goes. I don't have to keep saying it anymore.
And if you have a modern podcast app, such as, Podverse, Fountain Cast o Matic, and CurioCaster, you can send us fun little boosts along the way to give us a little encouragement and show your value of liking the show. And, also, you can get in touch with me on social media these days. I am on Mastodon at @[email protected]. I'm also on LinkedIn under my name, Eric Nantz. You'll see, tweets are posted from time to time and sometimes on that x thingy at @theRcast. And, Mike, before my voice completely goes haywire, where can the listeners find you? You're hanging on pretty well, Eric. Yeah.
[00:36:19] Mike Thomas:
You can find me on mastodon at [email protected], Ketchbrook Analytics, k e t c h b r o o k. There's too many Mike Thomases out there, so you're better off looking that way. I'm gonna need to recharge my batteries now, so we're gonna close-up shop here on episode
[00:36:41] Eric Nantz:
163. We thank you so much for listening, especially to my horrid voice here. And, hopefully, I'll be back to normal shape and as well as to talk to you about awesome new resources for our next episode, which is coming up next week.