
Bringing interactivity to a staple graphical display in the genomics space, how one team is taking the box approach to sharing and developing modular R code, and a set of intriguing benchmarks with the newly-releaed duckplyr that have your hosts thinking of many possibilities.
Episode Links
Episode Links
- This week's curator: Jon Carroll - @[email protected] (Mastodon) & @carroll_jono (X/Twitter)
- Interactive volcano plots with the ggiraph R package
- Modular R code for analytical projects with {box}
- Kicking tyres
- Entire issue available at rweekly.org/2024-W17
- How to interpret a volcano plot https://biostatsquid.com/volcano-plot/
- Source code behind Tim's {duckplyr} and {data.table} benchmarks https://git.sr.ht/~tim-taylor/duckplyr-benchmarks
- Attach to a DuckDB Database over HTTPS or S3 https://duckdb.org/docs/guides/networkcloudstorage/duckdboverhttpsors3
- Use the contact page at https://rweekly.fireside.fm/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
-
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Snow Cone Heaven - Ice Climber - Mazedude - https://ocremix.org/remix/OCR01176
- Cleaning Out Axis - Batman (NES) - Midee - https://ocremix.org/remix/OCR03008
[00:00:03]
Eric Nantz:
Hello, friends. We are back of episode 162 of the Our Weekly Highlights podcast. This is the weekly show where we showcase the latest, awesome resources that you will see every single week in this particular week on rweekly.org. My name is Eric Nantz, and I'm delighted you joined us from wherever you are around the world. And, yes, I am never doing this alone as you know by now. I am joined at the hip here virtually by my awesome cohost, Mike Thomas. Mike, how are you doing today?
[00:00:30] Mike Thomas:
Doing well, Eric. It's a good time to be a Boston sports fan. The the Celtics had a big win in the playoffs recently, and we have playoff hockey going on as well. And, I think the the Bruins took down the Leafs earlier this week or over the weekend.
[00:00:44] Eric Nantz:
Game 1, they did, but it was a tough one last night. Oh, I missed it. Yeah. Well They fell last night? Yeah. There was a there was a one goal difference. But, Boston and Toronto, they don't like each other, and this is probably gonna go the distance if I had to guess. So buckle your seatbelts wherever you are. But, of course, you had to bring that up. My beloved wings lost on a silly tiebreaker to not make the playoffs. So I'm still wincing from that. But, nonetheless, we're not gonna we're not gonna, you know, complain too much here because we got some fun rweekly content to talk to you about today, and this issue has been curated by Jonathan Carroll, now one of our long time contributors to the rweekly project. And as always, yeah, tremendous help from our fellow rweekly team members and contributors like all of you around the world with your poll requests and suggestions.
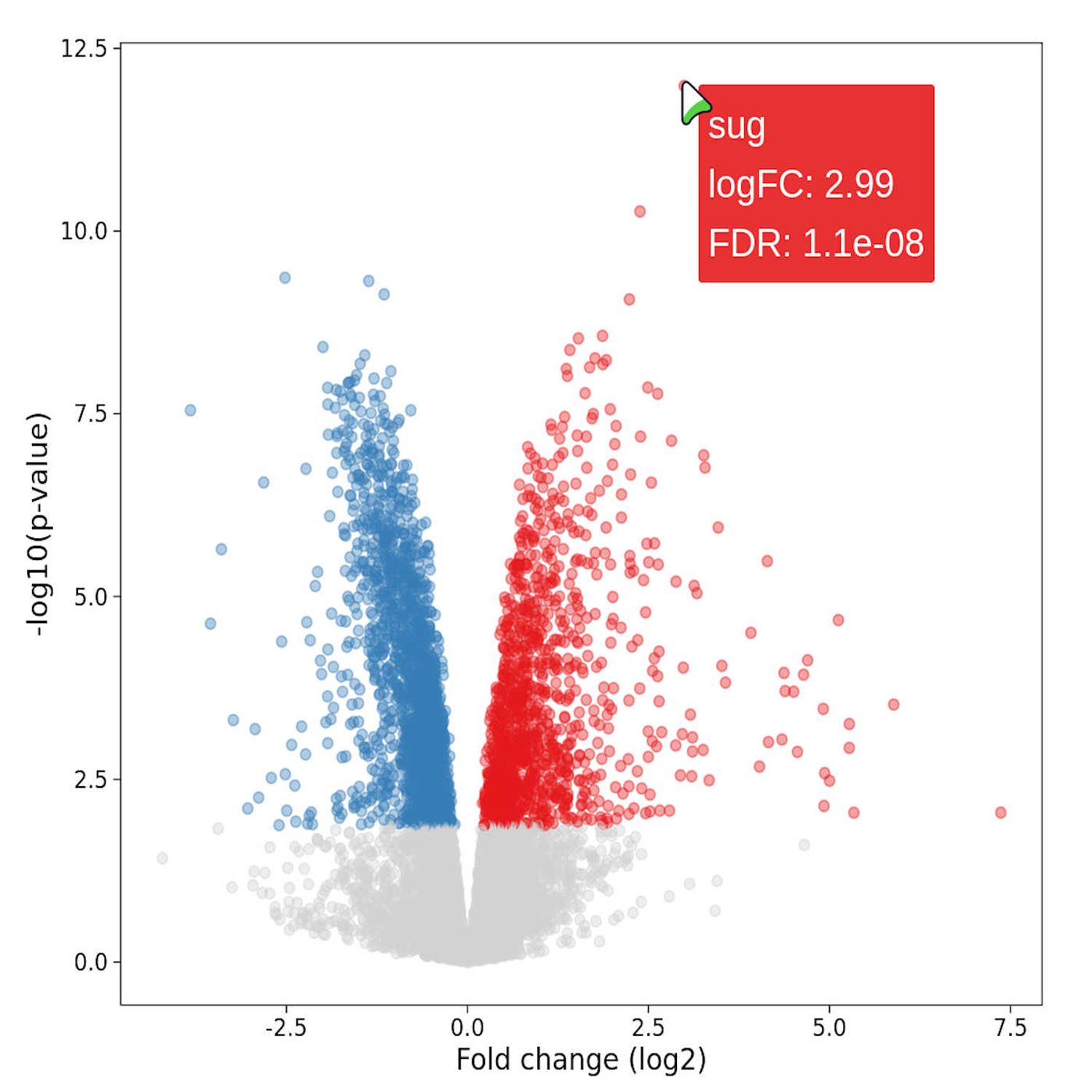
And we lead off with a visit to our visualization corner once again, and we're gonna talk about what is a very common and fundamental visualization that we often see in genetic and biomarker analyses and give it a little interactivity boost to make the experience even better for your collaborators. And this post comes to us from Thomas Sandman, who is a computational biologist. And he leads off with this situation where he wanted to share a very, powerful visualization called volcano plots to a collaborator. Now, what is a volcano plot, you might ask? Well, this is the plot where you can look at if you're comparing, say, 2 different groups in your experiment or your design.
Maybe it's, in the case of life sciences, it might be a treated set of patients versus a controlled set of patients. And with these biomarkers, you are measuring boatloads of genetic quantities such as gene expression for their genetic microarrays, you might call it. And then you're gonna do some inferences on these. But you're often gonna have 1,000 upon 1,000 of these genetic markers. So you don't really know, you know, right away which one of these is gonna show a, you know, positive or negative trend either way. So the volcano plot's job is on the y axis. You will see often a log adjusted p value of the inference method.
And then on the x axis, you'll see the fold change of the gene expression, which is like a ratio of the gene expression values from 1 group over the other. And, again, the shape, as you see, this does look literally like a volcano erupting on each side. It's a very, very intriguing visualization. I remember being blown away about that many years ago in my previous life as a statistician analyzing gene expression data. But, nonetheless, you can create these, as you can guess in R, quite, quite efficiently with the, always, you know, ready at your at your visualization hip here of ggplot2.
And he has a great example after downloading some, gene expression data to do this volcano plot where you see, as I mentioned on the y axis, the log transform p values. And on the x axis, the fold change, also log transform. And he colors it by the different groups in the experiments. And you can see above a certain threshold, the red dots with the the gene expression fold change going in the positive direction versus the blue dots going in negative direction. Now that's great, but what if your collaborator or yourself wants to get more information on individual points in this?
That's where interactivity comes to play. In particular, you can opt into interactivity quite efficiently with the g g I raf or g giraffe, depending on your pronunciation of it. That package has been mentioned quite a few times on the highlights over the years. That package is authored by David Goel, who is also the architect of the Office verse, family of packages that we often see in our enterprise work. But ggiraffe, the way that works is that all you have to really do is replace the geom point in your red regular ggplot2call with the geom point interactive function.
And with this, you supply a tooltip where when the user hovers over a point, you can supply metadata, if you will, on that particular point. And in the case of this plot, Thomas is supplying the p value, the log fold change, and the gene name itself. So, again, you can quickly see as you hover over that plot right in the blog post each of these, you know, specific genes and their fold change and p values. Now that's pretty good in and of itself. That might get you all the way there. But this is where this gets pretty intriguing, actually, because what if this plot is gonna be part of a larger report? I remember making these reports routinely with our markdown or even the predecessor to that s sweep in the in the early days.
But these plots, when you add these interactive elements, can take up a bit of size in terms of the HTML that's used to produce these plots when you add these tooltips in. So this comes now the very clever part of this post where Thomas is combining g g I f or something else and making the plot even more efficient for these reports. What what kind of trick has he done here? This this is pretty interesting where he combines the gg raster package with the ggiraffe
[00:06:20] Mike Thomas:
package, and, you know, essentially, what he's able to do here is to leverage this function called GeonpointRAST, to actually initially plot the points on the chart that you will see, but those points are not interactive. It's this, raster rasterized image which does not encode the position of each point separately. So it's sort of less overhead on the page in and of itself. And then on top of that, he overlays transparent interactive points for the significant, genes. And you could see that's where he leverages the Geon Point interactive function, but the the the alpha there is set to 0 such that there's no color.
You can't actually tell that those points are plotted unless you are hovering over them. So it's a very clever way to, I think, reduce the overhead on the page. And the use case here would be particularly if you, had a lot of plots on the same HTML page and it was, you know, slow maybe for users or, you know, the tooltip wasn't responsive because, you know, there's a lot of overhead potentially on those pages. So I thought this was super super clever. I see some use of, the poor man package to do some filtering, which is interesting as well to only show tool tips for the points that meet a certain significant threshold, which is really interesting. So sort of the grayed out portion of the bottom of the graph, you're not gonna get tool tooltips for, because, you know, the idea would be that users only necessarily care about those that are at or above the level of significance.
So a really really clever use case here for doing that. I think the code is very familiar to those who have experienced with ggplot. It's it's really not a very big step to go from ggplot to the ggiraffe package. And this gg raster package is one that I had not necessarily leveraged before but, it's very very very interesting to me and very, I don't know, kind of incredible how well these two packages work together, the gg raster package and the ggiraffe package, for being able to essentially, you know, plot the the points visually, sort of, in a static way on the page and then adding the interactivity, in a way that, you know, does not duplicate, the effort. So, great, great blog post top to bottom. I think for those either in the, you know, just interested in data visualization, I don't think you necessarily have to have the background in life sciences.
I certainly, you know, am not super well versed in in gene expression data or anything like that, but I still took a lot out of this blog post. So a great job by by Thomas and, great start to the highlights this week. Yeah. It's a really clever way of inter of, blending in these different elements, and it's also underscoring,
[00:09:16] Eric Nantz:
trend we're seeing in almost any industry you can think of. HTML for reports is the way for the future. Right? So anything we can do to optimize the display of these, to be able to share these in self contained ways, and to minimize the footprint, so to speak. I mean, let's face it. I can in the before times, well caught. Did you ever wanna up you know, open a PDF that's like 30 megabytes? Yeah. Probably not your most, pleasant experience. But being able to have these reports done efficiently, I'm really, really impressed by the things we can that are at our fingertips.
And, again, you as a a developer and R and programming these analyses and visualizations, you're not really stepping outside of a comfort zone here. You're just leveraging 2 additional packages that are in the same vein as your ggplot 2 type syntax. So it's a great way both, you know, from a cognitive standpoint to opt into this, and the result is absolutely fantastic. I've always been very impressed by ggiraffe and kind of its place in the visualization community. It often doesn't get enough love, but I think, you know, posts like this are definitely gonna show just just what it's capable of.
[00:10:31] Mike Thomas:
Absolutely, Eric. And I wish that you would tell my clients that HTML reports should be the only, sort of format that they should be interested in, but I'll digress.
[00:10:42] Eric Nantz:
Oh, don't get me started on the whole slide stuff. We're still in a PowerPoint world on that one, but, let's let's keep it positive, Michael. Let's keep it positive. And coming now speaking of, you know, efficiencies that we can gain with our code in general, our next highlight here has a very interesting take on how they're approaching modularity and their codevelopment across different projects and within the same project. This next post here comes from Owen Jones, who is a data science engineer at the UK Health Security Agency. And this post is all about how his team has been leveraging the box package as an alternative to other means and r of distributing and hosting reusable code, code bundles, modules, whatever you wanna call them, and to gain efficiencies in their projects.
So he mentions at the top that, you know, warms my heart to see a team that's using R for almost all of their data analysis and processing needs. And they definitely recognize a point where, hey. This project is doing this thing. This other project is doing the similar thing. Let's be efficient. Let's reuse that code and not duplicate it every time on the same project. So they're already on the right track from a cognitive standpoint, hopefully, beyond the path of minimizing technical debt and also enhancing collaboration. Now, if you're listening to the show and you've been in the art community for even just a little bit, you're probably thinking or even screaming at your, you know, podcast audio right now saying, this sounds like a package, and I would definitely agree with you. I think packages are a wonderful way to distribute shared functionality of data processing or other operational there is a bit of additional, you know, overhead or skill set that there is a bit of additional, you know, overhead or skill set that you need to be effective with packages. And, plus, if you have an update to make, you gotta update that package and then reinstall it or redistribute it amongst your different teams. These are all valid points. I definitely acknowledge it takes some discipline when you're in the the package mindset.
Now their approach, again, this is where things get interesting is they are leveraging the box package. And you may have heard of box more recently because box is actually a fundamental piece behind the Appsilon team's Rhino package for, building, Shiny apps in an enterprise fashion. Now Box and this is where Eric's gonna have some takes here. Mike might have some takes on this too. I think they take some getting used to just like our packages would just in different ways. But I will say, if you are familiar with Python, especially, your box is gonna seem pretty familiar to you because in Python, you're probably used to, at the top of your Python script, importing, say, all the functions from a given, you know, package, whatever you wanna call it, or importing specific functions, possibly even renaming them and being very explicit of what your global environment in that Python session is going to have from these modules. Well, Box basically gives the same thing in the context of our code. You'll have this preamble at the top of your script saying which function, which piece do you wanna use from another script.
That, hence, you know, be very tailored, so to speak, of what's going into your environment. I will admit that's still not, like, comfortable to me yet, but I can see that perspective for sure. And what, what, Peter oh, no. Shit. What Owen has done in his post is also talk about how they're organizing the way they use these modules. He defines 3 different types of these modules within the box framework. 1 is a general bucket. This is the stuff that's gonna be used across different projects. He cites connections to an AWS Redshift data warehouse. That makes complete sense to me. Having those be able to reuse across different projects.
And then within a project, they'll have a specific set of modules, and they call them project modules. Put them in a specific subdirectory that will be, you know, as the name says, specific to that particular project. And then lastly, a section called local modules. This category is meant for, you know, kind of tying it all together in that specific project, maybe more for utility purposes and whatnot. Now with Box, the other interesting piece of this is that much like in the our session, when you, say, call library dplyr, for example, it is searching for where dplyr is installed via what's called the library path.
And that's where you typically can see what these are in your R session when you do the dotlibpaths, function call. Box has a similar mechanism where you can define the box path, which is can be 1 or more paths to where these scripts that are containing these box modules are stored. That can also be set for an environment variable. In that case, they kind of do some custom manipulations of that for a given project via the dotrprofilefile, which again, this is where either at a project level or your main R session level, you can add code that will be run at startup automatically when you launch your r session.
So they're putting these box configurations in a dot r profile file, which is similar to what, say, the RM package does to tell our hey. Don't look at the default library path. Look at this RM specific library path for packages. So I did find it interesting that they're using that technique to customize the box set. And then the other little interesting bit here is that I mentioned they have a category for these general box modules that they'll use across projects. Well, they make a clever use of the get submodule technique that says for a given project, we are going to clone the upstream repository of that general box module, but in a subdirectory of the project git module.
Submodules will take a bit of getting used to. I've used them a couple of times, especially in my blog down, you know, blog down sites where I have the Hugo theme as a submodule for the repository so that I could, like, you know, keep up to date with the developer of that theme from time to time, or I could just keep it as static as is and not touch it ever since. They're using that similar technique with these general purpose box modules. That's quite interesting to me, and I think that technique can be used on a variety of situations.
So it was cool to see how Box can be used in, like, a day to day concept. I will admit I'm personally not not convinced yet to change my workflow, but, nonetheless, I can see for a team that's still not quite comfortable with package development or package basics, but yet are familiar with other languages and how they import dependencies, I can definitely see how this could be a useful fit for them. Curious, Mike. What's your take on this approach here?
[00:18:24] Mike Thomas:
Eric, I think this is super powerful depending on sort of how related, projects are within your organization from project to project. And I I think if you have a lot of projects where there's there's some overlap, right, maybe a little bit of overlap but not not sort of full overlap from project to project to the point where maybe you you wanna build, an R package that you know, contains a bunch of functions that you think are are going to be you're gonna use 80, 90% of them, you know, from project to project, then I think this may be the way to go when you're just trying to borrow sort of bits and pieces, from different places from from project to project where the the Venn diagram still has overlap from project to project but maybe a little bit, a little bit less where you're just trying to take a little bit here and there. And you're exactly right. It's it's sort of a very Python, type of mindset that you would have when leveraging the box package. I think it'll be very familiar to Python folks.
One of the third reasons why, they wanted to or Owen's team wanted to, leverage the box package as opposed to construct in our package and this reason is super relatable. It's that they would have to choose a package name and he admits that that is that is super hard that choosing a package name can be really difficult, which I will totally totally agree with. Although, I think, personally, that's sort of one of the the fun parts for me about developing R packages is I get to try to use that other side of my brain and then come up with an R package name that I think is is clever, and hopefully not one that, you know, a month from then I want to change and, because I, you know, at 3 in the morning I thought of a way better package name. You know, occasionally that may happen, may not happen. But I really do think, the use of Box can be incredibly powerful if it fits your use case. I I really appreciated the way that Owen, spelled out the different sub, the different module types in terms of general modules, project modules, and local modules because I think that makes a ton of sense in how to do that. I'm not personally familiar with git submodules. It sounds like something that I should get up to speed on because I can I can see from his explanation here how it would make a lot of sense to to leverage this git sub module technique, when you're employing, right, functions from these these quote unquote general modules and you have sort of multiple repositories potentially that you're interacting with pulling code from into the context of the current project that you're working on? So I think if you have the ability, capacity, you know, resources, understanding to leverage these 2 together, get sub modules in the box framework. I think it can be a really powerful way to develop within your team and and to share, resources, code, snippets, things like that, functions, that you want to leverage from project to project without introducing, you know, some of the the opinionated overhead that comes with developing in our package. And, Eric, as we always like to say, it's great to have options.
And I think that this is another fantastic option and this is one of, you know, I don't I don't wanna speak out of turn here if I'm not correct, but this is, like, one of the most comprehensive or or best showcase blog posts that I've seen around the box package, at least recently. So a huge thanks to Owen for spelling this all out for us in a a really, really nice way.
[00:22:09] Eric Nantz:
Yeah. I I fully agree with this. I've been looking for additional practical day to day kind of treatments of box or narratives around it. I mean, like, yeah, we've seen all the stuff from Rhino. We we see why they are using box and and the Rhino framework. But in terms of data analysis, data science in general, I still wasn't quite absorbing it. But this this really hits home, you know, why this is important to them and how how they're leveraging it. Definitely, the principles here I see, you know, no matter which route you take, whether it's box or the package route, because you could think of the submodules as their way of, let's imagine I have a Shiny app as a as a project, which I typically do, and I'm using RM for it. And I have as one of my RM package dependencies, an internal package that's doing a lot of the heavy lifting for analysis.
So the sub module is kind of like if I have a separate git repo for that, I'll call back end package. I make an update in it. But then in r m, I have to opt in to upgrading the package version in r m for that overall app library. This, the sub module approach is saying, okay. Maybe the team on the that other team has made an update to that general module. They go into their project modules or they do, like, a get sub module fetch or or pull or whatever, and then they'll get that updated sub module in their project. So it's it's similar to that. And, obviously, people are gonna have preferences, you know, maybe one way or the other or some combination of both for how they keep their dependencies for a project updated. I do think it's quite elegant, though, because like I said for my Hugo, blogs, for the my original r podcast site and for my shiny dev series site, I did make use to get submodules to help keep upstream with the themes that I was using.
And there were times that themes changed quite a bit, but I was like, do I really wanna opt into it yet? So I I got to chose when choose when to opt into it. But then when I did, I just gonna get some module fetcher or whatever, and I was off to the races. Yep. And you you mentioned lots of powerful ways or powerful ideas from that previous post, Mike. We're gonna really harness on the power aspect in this last highlight highlight here because there's been a lot of momentum in the recent weeks about DuckDV and the R community.
And this last post is gonna have somebody who was admittedly a bit skeptical about this and some of their eye opening moments as they kick the tires quite literally on this. This post comes to us from Tim Taylor, and this is normally the part where I talk about their background or what their role is. I actually don't know, Tim, if you're listening, what your what your, day to day is like, but I will say you are 2 for 2 because you have done 2 blog posts. And now this is the second one featured on our weekly highlights. Your last one on indentation and our scripts was on just about a year ago on this very podcast. So kudos to you. You're batting a 1,000 on that one.
[00:25:18] Mike Thomas:
Yes. No. All I can see is that Tim is a proud dad, enthusiastic R user, and when he has time, a climber, with a fondness for for coffee and cake. So, we'll have to to track down some more about him unless sort of it's intentionally that way. But, yeah, it his last blog post on this hidden elephants, blog site that he's developed was exactly one day off, a year apart. So he is batting a 1000 annually here on on our weekly highlights as well for these blogs.
[00:25:52] Eric Nantz:
Yeah. Well, kudos to you again on that one. But, yeah, this is quite a departure from indentation because, like us, he has seen this amazing momentum that DuckDV has had in the community, in particular, the Duckflyer package release that was announced about a week or so ago, and he he is intrigued. He's still skeptical, but he wanted to see just for his own his own, you know, curiosity how the recent duct plier package would stack up with data dot table, which, again, has been renowned for many years on performance on large datasets. So he decided to take matters in his own hands and download a set of parquet files that corresponding to the New York taxicab trip dataset, which has been used in quite a few examples talking about high performance and databases and the like.
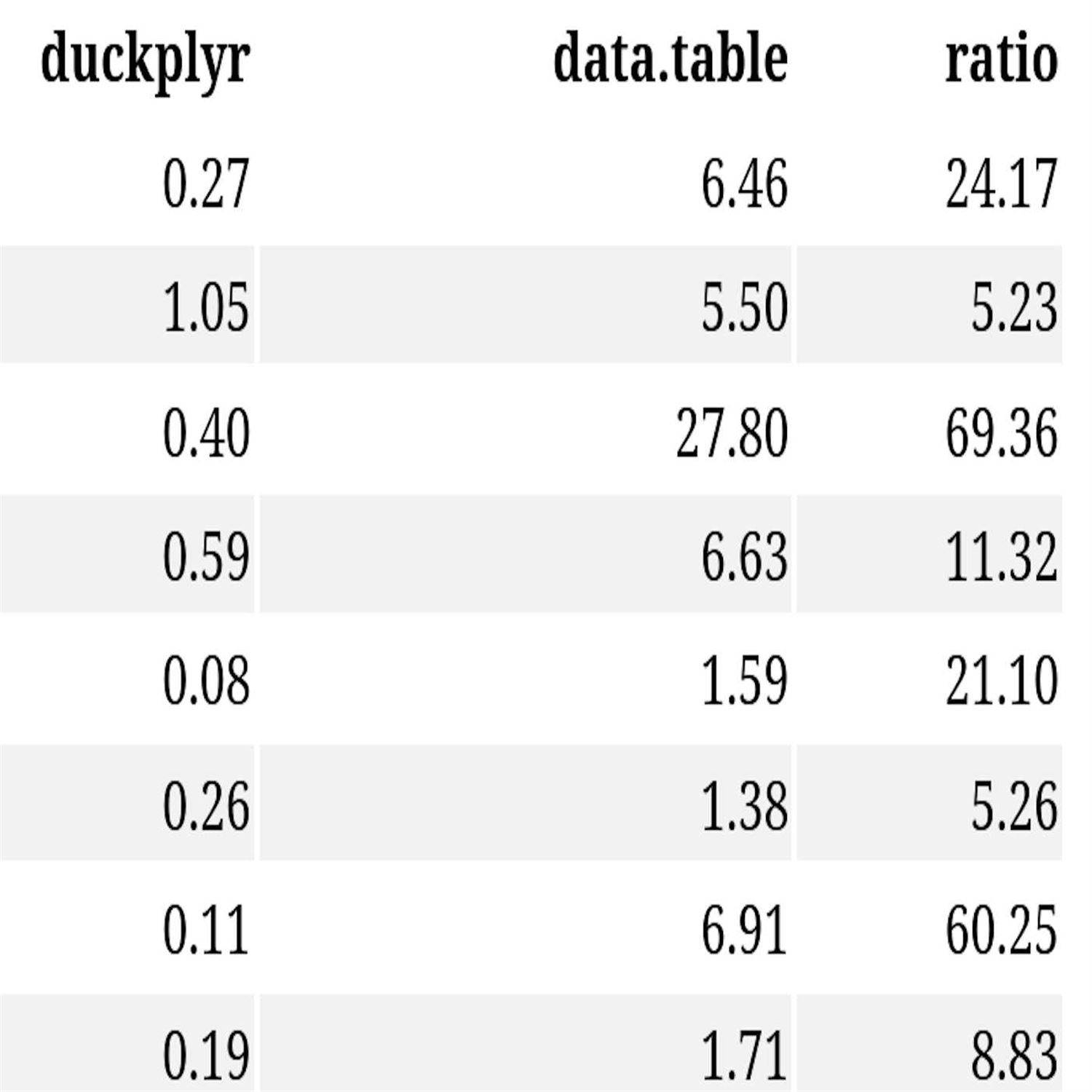
And he implemented a few benchmarks to compare the 2 packages. The, again, duck plier and data dot table. And he implemented a series, I believe, 4 benchmarks, and using a series of group summary type operations. Pretty intuitive stuff if you've done any kind of data analysis looking at, like, medium medium pickup times and other, another similar analysis like that. And then he shows us the results. In this table here, he ran this in in two scenarios for each benchmark. 1 was using a year's worth of data and one using a quarter year's worth or 3 months of data. And you see here, when you look at the median timings, in this case, it was 5 reps, so little caveat there.
The ratio of improvement of duct plier performance, the data dot table performance in terms of these run times is between 5 and even up to 70 times improvement. Holy jumping. That gets your attention. And he even admitted he was shocked at this as well. That that is amazing. Wine to said he needed some wine to take in these results. Yeah. I I probably would need to take a walk away from my desk and be like, what did I just see? Like, that's amazing. And so he dives into a bit more about how he, performed this. And by the way, there is a repo. We have all of his, code to set up these benchmarks. So I'll have a link to that in the show notes as well. But I think, again, trying to read between the lines here, what Doug Plyer and ductedbee are doing is a lot of, quote, unquote, lazy evaluation in terms of not doing the crunching until you absolutely have to, but it has certainly been optimized for performance like I didn't even dreamed of.
And, apparently, it's also being very optimal for joining operations as well. Tim makes, some caveats in the post that there may not be a quite direct apples to apples comparison, so to speak, with the duct flyer and data dot table code because he had to modify the data dot table way of doing things to not be as, in, quote, unquote, lazier of our, approaches. I'll have to dive into that a bit more, but he is very upfront that he wants to keep running these benchmarks as new versions of Datadot Table and Duckplier are released just to kinda see the improvements that we're seeing in performance for each of these frameworks. But he seems to be convinced that this is something he's gonna be paying attention to in his future analysis, and frankly, I am very intrigued as well. And as I was reading through this prepping for this show, I did have one moment.
Imagine something I read about a week ago. I'll put this in the show notes as well. With DuckDB, there is a way that you can read as a read only source, a DuckDb database stored in an http endpoint or an s 3 bucket. You combine that with the forms that we're seeing here. Oh my goodness. I'm thinking shiny live web assembly with Duck DB with a big day. Oh. Oh. The plot thickens. I am very intrigued to explore this, and this really hit home that you could see some massive performance wins in this space. So, yeah, I was skeptical as well. I remember first hearing about DuckDB and Duckflyer, but my goodness, this is a heck of a job to convince me that I need to watch this space very closely.
[00:30:26] Mike Thomas:
I'm in the same boat, Eric. You know, I saw LinkedIn that you were, interacting with some DuckDV content recently and I follow them and I'm always, I'm very excited to see they're developing. It seems like at the speed of light, like, there's new functionality coming out in DuckDV. I've seen people say that DuckDV has sort of native, like, similarity measurement type functions that you could use for, you know, text embeddings and and things like that. And it's it's crazy that something like that, you know, functionality exists in within DuckDV, but it's it's like there's no end to the possibilities when it comes to it. And it's sort of really just exploded here, in the last, I don't know, 12 months something like that or may maybe more.
So it's really interesting and, you know, I think, Tim, you know, is quick to say at the end of this blog post as well that, you know, the current performance of data dot table is still very, very good. And it's it's always been more than just about raw speed. You know, there's people that love the syntax as well, and, you know, it's it's sort of Swiss army like functionality he mentioned. So, you know, even though this this benchmark is against data dot table and I feel like lately we've seen, you know, whether it be Arrow or or DuckDV or something like that, everybody's always benchmarking it against data dot table to show, you know, how much it can outperform data. Table maybe because, you know, that was the the prior sort of fastest game in town. You know, I would have liked to have seen, you know, a benchmark against sort of just raw dplyr code as well or or base r as well to just get that sort of full comparison and maybe not single out a poor data table so so much, because we do try to support that effort as well. But it's like, you know, like you've said, Eric, it's incredible. It seems, you know, as the the size of the data and maybe complexity of the operation increases, you know, the gap between DuckDBS performance and, you know, take your pick data. Table, whatever, it just seems to widen, which is is pretty incredible that we're getting, you know, 60, 70 x improvements, in the timing for some of these queries against, you know, the very famous New York taxi trip dataset, which is is pretty big. You know, Tim notes that it resulted in a data frame at times occupying 15 gigs of memory, in his r session, and and duck duck plier was able to perform all 4 of the queries that he wrote in, like, a little over 2 seconds, which is is it's incredible. And like you said, it definitely opens up the possibility for leveraging DuckDb and and WebAssembly WASM to be able to to run these things completely client side, on a page that doesn't necessarily have, you know, your traditional server behind it, leveraging Shiny Live, you know, connecting to to s three sources, HTTPS sources, and yeah, it's the the possibilities are are just endless here, and I'm so excited to continue to watch this space and see what happens in the next next year, 2 years, things like that. Maybe I've spun up, you know, my last digital ocean droplet here in the next next year or 2, because we'll just be deploying everything on on GitHub pages.
But we'll we'll have to see. We'll have to see. It's really, really exciting time to be in the data
[00:33:50] Eric Nantz:
space. Konas Otterberg and myself, man. I'm really intrigued by where I can where I can take these efforts. And there's gonna be a lot of fast moving pieces in this, so we'll be watching this space quite closely. And where you can watch this and many more developments is, of course, our weekly itself where we have so much more than just these highlights that we share in every issue, such as new packages, updated packages, and awesome showcases of our in the real world and tutorials. Almost there's always something for everybody. So we'll take a minute for our additional finds here, and I'm gonna gonna plug our our first highlight author, once again, Thomas Sandman. He has another post on this issue about querying JSON files with AWS Athena and this Noctua r package. Now this is pretty sophisticated stuff, but imagine you have data collected as JSON files, which, of course, is quite common in the world of web technology and web development, that you could, with this athena, service and with the Noctua package, treat those as if they were a DBI compliant data source and be able to leverage, say, dplyr code to do manipulations, do summaries, and whatnot.
So, as I think about ways I can store data interoperability wise between R and other frameworks that they all can access it efficiently, I'm definitely gonna keep an eye on this space. So that was,
[00:35:20] Mike Thomas:
a lot of moments on that post Laurent by Thomas. So definitely check that out. No. That's a great find, Eric. Yeah. There's there's a lot of actually additional highlights from the Datawookie blog by Andrew Collier. And, one that I'll I'll point out, which is a nice short and sweet one, it resonates with a lot of what we do is is on model validation, and it looks like, he has a model developed to try to estimate, stock market returns or financial portfolio returns as well and has 3 different methodologies for trying to evaluate whether the model he developed is a quote unquote good model. So it's an interesting one to to check out if you're in the model validation space.
[00:36:00] Eric Nantz:
Nice. Yeah. I'll be checking that out as well. We're dealing with models left and right around here like everyone else. Very cool. And, of course, the rest of the issue is just as cool, so we invite you to check it out. The issue is always linked in the show notes, and John did another wonderful job curating this for us. And, again, our weekly is powered by all of you in the community. So the best way to help our project is to help send us a poll request for that new blog, that new resource, that new package, all marked down all the time. Details are at r wicked dot org. The upper right corner takes you directly to the upcoming issue draft. And, I think, yours truly is on the docket for next week's issue, so I can definitely use all the help I can get. So definitely help out your humble host here if you can.
But we also love hearing from you in the audience as well. You can send us a note on our contact page. This is directly linked in the show notes. Also, you can send us a fun little boost if you're using a modern podcast app like Paverse, Fountain, or Cast O Matic, Curio Castor. There's a whole bunch out there. And so you'll see details about that in the show notes as well. And we are still randomly walking those social media pathways. I'm mostly on Mastodon these days with at our podcast at podcast index.social. I am also on LinkedIn under my name, Eric Nance, and from time to time on the x thingy at the r cast. Mike, where can the listeners find you?
[00:37:26] Mike Thomas:
Sure. You can find me on mastodon@[email protected], or you can check out what I'm up to on LinkedIn by searching Catch Brook Analytics, ketchbrook. And I wanna shout out Matan Hakim for his message on mastodon after I put out a little post, on Llama 3 saying that they did not have Catchbook Analytics in the training data when we asked them who Catchbook Analytics was, and he recommended, that they the developers, I guess, meta, of Llama 3, should have used the Our Weekly Highlights podcast as training data, which would have enabled them to, definitely spell Catch Brook Analytics because it's something that I apparently do at the end of every single episode. So sorry to the listeners for that, but not sure if it's gonna stop.
[00:38:15] Eric Nantz:
No. No. We we we keep we keep consistency on this show. So, yeah, Nada, get on this, buddy. We got we you gotta update your training data.
[00:38:23] Mike Thomas:
That was awesome. Seriously.
[00:38:25] Eric Nantz:
Yes. Yes. Well, our weekly itself shouldn't be hard to spell. Again, we're at our weekly dotorg for everything, so definitely bookmark it if you haven't. But, of course, we very much appreciate you listening from wherever you are around the world. It's always a blast to do this show, and we'll keep the train going as they say. So that will put a bow on episode 162, and we'll be back with episode 100 63 of our weekly highlights next week.
Hello, friends. We are back of episode 162 of the Our Weekly Highlights podcast. This is the weekly show where we showcase the latest, awesome resources that you will see every single week in this particular week on rweekly.org. My name is Eric Nantz, and I'm delighted you joined us from wherever you are around the world. And, yes, I am never doing this alone as you know by now. I am joined at the hip here virtually by my awesome cohost, Mike Thomas. Mike, how are you doing today?
[00:00:30] Mike Thomas:
Doing well, Eric. It's a good time to be a Boston sports fan. The the Celtics had a big win in the playoffs recently, and we have playoff hockey going on as well. And, I think the the Bruins took down the Leafs earlier this week or over the weekend.
[00:00:44] Eric Nantz:
Game 1, they did, but it was a tough one last night. Oh, I missed it. Yeah. Well They fell last night? Yeah. There was a there was a one goal difference. But, Boston and Toronto, they don't like each other, and this is probably gonna go the distance if I had to guess. So buckle your seatbelts wherever you are. But, of course, you had to bring that up. My beloved wings lost on a silly tiebreaker to not make the playoffs. So I'm still wincing from that. But, nonetheless, we're not gonna we're not gonna, you know, complain too much here because we got some fun rweekly content to talk to you about today, and this issue has been curated by Jonathan Carroll, now one of our long time contributors to the rweekly project. And as always, yeah, tremendous help from our fellow rweekly team members and contributors like all of you around the world with your poll requests and suggestions.
And we lead off with a visit to our visualization corner once again, and we're gonna talk about what is a very common and fundamental visualization that we often see in genetic and biomarker analyses and give it a little interactivity boost to make the experience even better for your collaborators. And this post comes to us from Thomas Sandman, who is a computational biologist. And he leads off with this situation where he wanted to share a very, powerful visualization called volcano plots to a collaborator. Now, what is a volcano plot, you might ask? Well, this is the plot where you can look at if you're comparing, say, 2 different groups in your experiment or your design.
Maybe it's, in the case of life sciences, it might be a treated set of patients versus a controlled set of patients. And with these biomarkers, you are measuring boatloads of genetic quantities such as gene expression for their genetic microarrays, you might call it. And then you're gonna do some inferences on these. But you're often gonna have 1,000 upon 1,000 of these genetic markers. So you don't really know, you know, right away which one of these is gonna show a, you know, positive or negative trend either way. So the volcano plot's job is on the y axis. You will see often a log adjusted p value of the inference method.
And then on the x axis, you'll see the fold change of the gene expression, which is like a ratio of the gene expression values from 1 group over the other. And, again, the shape, as you see, this does look literally like a volcano erupting on each side. It's a very, very intriguing visualization. I remember being blown away about that many years ago in my previous life as a statistician analyzing gene expression data. But, nonetheless, you can create these, as you can guess in R, quite, quite efficiently with the, always, you know, ready at your at your visualization hip here of ggplot2.
And he has a great example after downloading some, gene expression data to do this volcano plot where you see, as I mentioned on the y axis, the log transform p values. And on the x axis, the fold change, also log transform. And he colors it by the different groups in the experiments. And you can see above a certain threshold, the red dots with the the gene expression fold change going in the positive direction versus the blue dots going in negative direction. Now that's great, but what if your collaborator or yourself wants to get more information on individual points in this?
That's where interactivity comes to play. In particular, you can opt into interactivity quite efficiently with the g g I raf or g giraffe, depending on your pronunciation of it. That package has been mentioned quite a few times on the highlights over the years. That package is authored by David Goel, who is also the architect of the Office verse, family of packages that we often see in our enterprise work. But ggiraffe, the way that works is that all you have to really do is replace the geom point in your red regular ggplot2call with the geom point interactive function.
And with this, you supply a tooltip where when the user hovers over a point, you can supply metadata, if you will, on that particular point. And in the case of this plot, Thomas is supplying the p value, the log fold change, and the gene name itself. So, again, you can quickly see as you hover over that plot right in the blog post each of these, you know, specific genes and their fold change and p values. Now that's pretty good in and of itself. That might get you all the way there. But this is where this gets pretty intriguing, actually, because what if this plot is gonna be part of a larger report? I remember making these reports routinely with our markdown or even the predecessor to that s sweep in the in the early days.
But these plots, when you add these interactive elements, can take up a bit of size in terms of the HTML that's used to produce these plots when you add these tooltips in. So this comes now the very clever part of this post where Thomas is combining g g I f or something else and making the plot even more efficient for these reports. What what kind of trick has he done here? This this is pretty interesting where he combines the gg raster package with the ggiraffe
[00:06:20] Mike Thomas:
package, and, you know, essentially, what he's able to do here is to leverage this function called GeonpointRAST, to actually initially plot the points on the chart that you will see, but those points are not interactive. It's this, raster rasterized image which does not encode the position of each point separately. So it's sort of less overhead on the page in and of itself. And then on top of that, he overlays transparent interactive points for the significant, genes. And you could see that's where he leverages the Geon Point interactive function, but the the the alpha there is set to 0 such that there's no color.
You can't actually tell that those points are plotted unless you are hovering over them. So it's a very clever way to, I think, reduce the overhead on the page. And the use case here would be particularly if you, had a lot of plots on the same HTML page and it was, you know, slow maybe for users or, you know, the tooltip wasn't responsive because, you know, there's a lot of overhead potentially on those pages. So I thought this was super super clever. I see some use of, the poor man package to do some filtering, which is interesting as well to only show tool tips for the points that meet a certain significant threshold, which is really interesting. So sort of the grayed out portion of the bottom of the graph, you're not gonna get tool tooltips for, because, you know, the idea would be that users only necessarily care about those that are at or above the level of significance.
So a really really clever use case here for doing that. I think the code is very familiar to those who have experienced with ggplot. It's it's really not a very big step to go from ggplot to the ggiraffe package. And this gg raster package is one that I had not necessarily leveraged before but, it's very very very interesting to me and very, I don't know, kind of incredible how well these two packages work together, the gg raster package and the ggiraffe package, for being able to essentially, you know, plot the the points visually, sort of, in a static way on the page and then adding the interactivity, in a way that, you know, does not duplicate, the effort. So, great, great blog post top to bottom. I think for those either in the, you know, just interested in data visualization, I don't think you necessarily have to have the background in life sciences.
I certainly, you know, am not super well versed in in gene expression data or anything like that, but I still took a lot out of this blog post. So a great job by by Thomas and, great start to the highlights this week. Yeah. It's a really clever way of inter of, blending in these different elements, and it's also underscoring,
[00:09:16] Eric Nantz:
trend we're seeing in almost any industry you can think of. HTML for reports is the way for the future. Right? So anything we can do to optimize the display of these, to be able to share these in self contained ways, and to minimize the footprint, so to speak. I mean, let's face it. I can in the before times, well caught. Did you ever wanna up you know, open a PDF that's like 30 megabytes? Yeah. Probably not your most, pleasant experience. But being able to have these reports done efficiently, I'm really, really impressed by the things we can that are at our fingertips.
And, again, you as a a developer and R and programming these analyses and visualizations, you're not really stepping outside of a comfort zone here. You're just leveraging 2 additional packages that are in the same vein as your ggplot 2 type syntax. So it's a great way both, you know, from a cognitive standpoint to opt into this, and the result is absolutely fantastic. I've always been very impressed by ggiraffe and kind of its place in the visualization community. It often doesn't get enough love, but I think, you know, posts like this are definitely gonna show just just what it's capable of.
[00:10:31] Mike Thomas:
Absolutely, Eric. And I wish that you would tell my clients that HTML reports should be the only, sort of format that they should be interested in, but I'll digress.
[00:10:42] Eric Nantz:
Oh, don't get me started on the whole slide stuff. We're still in a PowerPoint world on that one, but, let's let's keep it positive, Michael. Let's keep it positive. And coming now speaking of, you know, efficiencies that we can gain with our code in general, our next highlight here has a very interesting take on how they're approaching modularity and their codevelopment across different projects and within the same project. This next post here comes from Owen Jones, who is a data science engineer at the UK Health Security Agency. And this post is all about how his team has been leveraging the box package as an alternative to other means and r of distributing and hosting reusable code, code bundles, modules, whatever you wanna call them, and to gain efficiencies in their projects.
So he mentions at the top that, you know, warms my heart to see a team that's using R for almost all of their data analysis and processing needs. And they definitely recognize a point where, hey. This project is doing this thing. This other project is doing the similar thing. Let's be efficient. Let's reuse that code and not duplicate it every time on the same project. So they're already on the right track from a cognitive standpoint, hopefully, beyond the path of minimizing technical debt and also enhancing collaboration. Now, if you're listening to the show and you've been in the art community for even just a little bit, you're probably thinking or even screaming at your, you know, podcast audio right now saying, this sounds like a package, and I would definitely agree with you. I think packages are a wonderful way to distribute shared functionality of data processing or other operational there is a bit of additional, you know, overhead or skill set that there is a bit of additional, you know, overhead or skill set that you need to be effective with packages. And, plus, if you have an update to make, you gotta update that package and then reinstall it or redistribute it amongst your different teams. These are all valid points. I definitely acknowledge it takes some discipline when you're in the the package mindset.
Now their approach, again, this is where things get interesting is they are leveraging the box package. And you may have heard of box more recently because box is actually a fundamental piece behind the Appsilon team's Rhino package for, building, Shiny apps in an enterprise fashion. Now Box and this is where Eric's gonna have some takes here. Mike might have some takes on this too. I think they take some getting used to just like our packages would just in different ways. But I will say, if you are familiar with Python, especially, your box is gonna seem pretty familiar to you because in Python, you're probably used to, at the top of your Python script, importing, say, all the functions from a given, you know, package, whatever you wanna call it, or importing specific functions, possibly even renaming them and being very explicit of what your global environment in that Python session is going to have from these modules. Well, Box basically gives the same thing in the context of our code. You'll have this preamble at the top of your script saying which function, which piece do you wanna use from another script.
That, hence, you know, be very tailored, so to speak, of what's going into your environment. I will admit that's still not, like, comfortable to me yet, but I can see that perspective for sure. And what, what, Peter oh, no. Shit. What Owen has done in his post is also talk about how they're organizing the way they use these modules. He defines 3 different types of these modules within the box framework. 1 is a general bucket. This is the stuff that's gonna be used across different projects. He cites connections to an AWS Redshift data warehouse. That makes complete sense to me. Having those be able to reuse across different projects.
And then within a project, they'll have a specific set of modules, and they call them project modules. Put them in a specific subdirectory that will be, you know, as the name says, specific to that particular project. And then lastly, a section called local modules. This category is meant for, you know, kind of tying it all together in that specific project, maybe more for utility purposes and whatnot. Now with Box, the other interesting piece of this is that much like in the our session, when you, say, call library dplyr, for example, it is searching for where dplyr is installed via what's called the library path.
And that's where you typically can see what these are in your R session when you do the dotlibpaths, function call. Box has a similar mechanism where you can define the box path, which is can be 1 or more paths to where these scripts that are containing these box modules are stored. That can also be set for an environment variable. In that case, they kind of do some custom manipulations of that for a given project via the dotrprofilefile, which again, this is where either at a project level or your main R session level, you can add code that will be run at startup automatically when you launch your r session.
So they're putting these box configurations in a dot r profile file, which is similar to what, say, the RM package does to tell our hey. Don't look at the default library path. Look at this RM specific library path for packages. So I did find it interesting that they're using that technique to customize the box set. And then the other little interesting bit here is that I mentioned they have a category for these general box modules that they'll use across projects. Well, they make a clever use of the get submodule technique that says for a given project, we are going to clone the upstream repository of that general box module, but in a subdirectory of the project git module.
Submodules will take a bit of getting used to. I've used them a couple of times, especially in my blog down, you know, blog down sites where I have the Hugo theme as a submodule for the repository so that I could, like, you know, keep up to date with the developer of that theme from time to time, or I could just keep it as static as is and not touch it ever since. They're using that similar technique with these general purpose box modules. That's quite interesting to me, and I think that technique can be used on a variety of situations.
So it was cool to see how Box can be used in, like, a day to day concept. I will admit I'm personally not not convinced yet to change my workflow, but, nonetheless, I can see for a team that's still not quite comfortable with package development or package basics, but yet are familiar with other languages and how they import dependencies, I can definitely see how this could be a useful fit for them. Curious, Mike. What's your take on this approach here?
[00:18:24] Mike Thomas:
Eric, I think this is super powerful depending on sort of how related, projects are within your organization from project to project. And I I think if you have a lot of projects where there's there's some overlap, right, maybe a little bit of overlap but not not sort of full overlap from project to project to the point where maybe you you wanna build, an R package that you know, contains a bunch of functions that you think are are going to be you're gonna use 80, 90% of them, you know, from project to project, then I think this may be the way to go when you're just trying to borrow sort of bits and pieces, from different places from from project to project where the the Venn diagram still has overlap from project to project but maybe a little bit, a little bit less where you're just trying to take a little bit here and there. And you're exactly right. It's it's sort of a very Python, type of mindset that you would have when leveraging the box package. I think it'll be very familiar to Python folks.
One of the third reasons why, they wanted to or Owen's team wanted to, leverage the box package as opposed to construct in our package and this reason is super relatable. It's that they would have to choose a package name and he admits that that is that is super hard that choosing a package name can be really difficult, which I will totally totally agree with. Although, I think, personally, that's sort of one of the the fun parts for me about developing R packages is I get to try to use that other side of my brain and then come up with an R package name that I think is is clever, and hopefully not one that, you know, a month from then I want to change and, because I, you know, at 3 in the morning I thought of a way better package name. You know, occasionally that may happen, may not happen. But I really do think, the use of Box can be incredibly powerful if it fits your use case. I I really appreciated the way that Owen, spelled out the different sub, the different module types in terms of general modules, project modules, and local modules because I think that makes a ton of sense in how to do that. I'm not personally familiar with git submodules. It sounds like something that I should get up to speed on because I can I can see from his explanation here how it would make a lot of sense to to leverage this git sub module technique, when you're employing, right, functions from these these quote unquote general modules and you have sort of multiple repositories potentially that you're interacting with pulling code from into the context of the current project that you're working on? So I think if you have the ability, capacity, you know, resources, understanding to leverage these 2 together, get sub modules in the box framework. I think it can be a really powerful way to develop within your team and and to share, resources, code, snippets, things like that, functions, that you want to leverage from project to project without introducing, you know, some of the the opinionated overhead that comes with developing in our package. And, Eric, as we always like to say, it's great to have options.
And I think that this is another fantastic option and this is one of, you know, I don't I don't wanna speak out of turn here if I'm not correct, but this is, like, one of the most comprehensive or or best showcase blog posts that I've seen around the box package, at least recently. So a huge thanks to Owen for spelling this all out for us in a a really, really nice way.
[00:22:09] Eric Nantz:
Yeah. I I fully agree with this. I've been looking for additional practical day to day kind of treatments of box or narratives around it. I mean, like, yeah, we've seen all the stuff from Rhino. We we see why they are using box and and the Rhino framework. But in terms of data analysis, data science in general, I still wasn't quite absorbing it. But this this really hits home, you know, why this is important to them and how how they're leveraging it. Definitely, the principles here I see, you know, no matter which route you take, whether it's box or the package route, because you could think of the submodules as their way of, let's imagine I have a Shiny app as a as a project, which I typically do, and I'm using RM for it. And I have as one of my RM package dependencies, an internal package that's doing a lot of the heavy lifting for analysis.
So the sub module is kind of like if I have a separate git repo for that, I'll call back end package. I make an update in it. But then in r m, I have to opt in to upgrading the package version in r m for that overall app library. This, the sub module approach is saying, okay. Maybe the team on the that other team has made an update to that general module. They go into their project modules or they do, like, a get sub module fetch or or pull or whatever, and then they'll get that updated sub module in their project. So it's it's similar to that. And, obviously, people are gonna have preferences, you know, maybe one way or the other or some combination of both for how they keep their dependencies for a project updated. I do think it's quite elegant, though, because like I said for my Hugo, blogs, for the my original r podcast site and for my shiny dev series site, I did make use to get submodules to help keep upstream with the themes that I was using.
And there were times that themes changed quite a bit, but I was like, do I really wanna opt into it yet? So I I got to chose when choose when to opt into it. But then when I did, I just gonna get some module fetcher or whatever, and I was off to the races. Yep. And you you mentioned lots of powerful ways or powerful ideas from that previous post, Mike. We're gonna really harness on the power aspect in this last highlight highlight here because there's been a lot of momentum in the recent weeks about DuckDV and the R community.
And this last post is gonna have somebody who was admittedly a bit skeptical about this and some of their eye opening moments as they kick the tires quite literally on this. This post comes to us from Tim Taylor, and this is normally the part where I talk about their background or what their role is. I actually don't know, Tim, if you're listening, what your what your, day to day is like, but I will say you are 2 for 2 because you have done 2 blog posts. And now this is the second one featured on our weekly highlights. Your last one on indentation and our scripts was on just about a year ago on this very podcast. So kudos to you. You're batting a 1,000 on that one.
[00:25:18] Mike Thomas:
Yes. No. All I can see is that Tim is a proud dad, enthusiastic R user, and when he has time, a climber, with a fondness for for coffee and cake. So, we'll have to to track down some more about him unless sort of it's intentionally that way. But, yeah, it his last blog post on this hidden elephants, blog site that he's developed was exactly one day off, a year apart. So he is batting a 1000 annually here on on our weekly highlights as well for these blogs.
[00:25:52] Eric Nantz:
Yeah. Well, kudos to you again on that one. But, yeah, this is quite a departure from indentation because, like us, he has seen this amazing momentum that DuckDV has had in the community, in particular, the Duckflyer package release that was announced about a week or so ago, and he he is intrigued. He's still skeptical, but he wanted to see just for his own his own, you know, curiosity how the recent duct plier package would stack up with data dot table, which, again, has been renowned for many years on performance on large datasets. So he decided to take matters in his own hands and download a set of parquet files that corresponding to the New York taxicab trip dataset, which has been used in quite a few examples talking about high performance and databases and the like.
And he implemented a few benchmarks to compare the 2 packages. The, again, duck plier and data dot table. And he implemented a series, I believe, 4 benchmarks, and using a series of group summary type operations. Pretty intuitive stuff if you've done any kind of data analysis looking at, like, medium medium pickup times and other, another similar analysis like that. And then he shows us the results. In this table here, he ran this in in two scenarios for each benchmark. 1 was using a year's worth of data and one using a quarter year's worth or 3 months of data. And you see here, when you look at the median timings, in this case, it was 5 reps, so little caveat there.
The ratio of improvement of duct plier performance, the data dot table performance in terms of these run times is between 5 and even up to 70 times improvement. Holy jumping. That gets your attention. And he even admitted he was shocked at this as well. That that is amazing. Wine to said he needed some wine to take in these results. Yeah. I I probably would need to take a walk away from my desk and be like, what did I just see? Like, that's amazing. And so he dives into a bit more about how he, performed this. And by the way, there is a repo. We have all of his, code to set up these benchmarks. So I'll have a link to that in the show notes as well. But I think, again, trying to read between the lines here, what Doug Plyer and ductedbee are doing is a lot of, quote, unquote, lazy evaluation in terms of not doing the crunching until you absolutely have to, but it has certainly been optimized for performance like I didn't even dreamed of.
And, apparently, it's also being very optimal for joining operations as well. Tim makes, some caveats in the post that there may not be a quite direct apples to apples comparison, so to speak, with the duct flyer and data dot table code because he had to modify the data dot table way of doing things to not be as, in, quote, unquote, lazier of our, approaches. I'll have to dive into that a bit more, but he is very upfront that he wants to keep running these benchmarks as new versions of Datadot Table and Duckplier are released just to kinda see the improvements that we're seeing in performance for each of these frameworks. But he seems to be convinced that this is something he's gonna be paying attention to in his future analysis, and frankly, I am very intrigued as well. And as I was reading through this prepping for this show, I did have one moment.
Imagine something I read about a week ago. I'll put this in the show notes as well. With DuckDB, there is a way that you can read as a read only source, a DuckDb database stored in an http endpoint or an s 3 bucket. You combine that with the forms that we're seeing here. Oh my goodness. I'm thinking shiny live web assembly with Duck DB with a big day. Oh. Oh. The plot thickens. I am very intrigued to explore this, and this really hit home that you could see some massive performance wins in this space. So, yeah, I was skeptical as well. I remember first hearing about DuckDB and Duckflyer, but my goodness, this is a heck of a job to convince me that I need to watch this space very closely.
[00:30:26] Mike Thomas:
I'm in the same boat, Eric. You know, I saw LinkedIn that you were, interacting with some DuckDV content recently and I follow them and I'm always, I'm very excited to see they're developing. It seems like at the speed of light, like, there's new functionality coming out in DuckDV. I've seen people say that DuckDV has sort of native, like, similarity measurement type functions that you could use for, you know, text embeddings and and things like that. And it's it's crazy that something like that, you know, functionality exists in within DuckDV, but it's it's like there's no end to the possibilities when it comes to it. And it's sort of really just exploded here, in the last, I don't know, 12 months something like that or may maybe more.
So it's really interesting and, you know, I think, Tim, you know, is quick to say at the end of this blog post as well that, you know, the current performance of data dot table is still very, very good. And it's it's always been more than just about raw speed. You know, there's people that love the syntax as well, and, you know, it's it's sort of Swiss army like functionality he mentioned. So, you know, even though this this benchmark is against data dot table and I feel like lately we've seen, you know, whether it be Arrow or or DuckDV or something like that, everybody's always benchmarking it against data dot table to show, you know, how much it can outperform data. Table maybe because, you know, that was the the prior sort of fastest game in town. You know, I would have liked to have seen, you know, a benchmark against sort of just raw dplyr code as well or or base r as well to just get that sort of full comparison and maybe not single out a poor data table so so much, because we do try to support that effort as well. But it's like, you know, like you've said, Eric, it's incredible. It seems, you know, as the the size of the data and maybe complexity of the operation increases, you know, the gap between DuckDBS performance and, you know, take your pick data. Table, whatever, it just seems to widen, which is is pretty incredible that we're getting, you know, 60, 70 x improvements, in the timing for some of these queries against, you know, the very famous New York taxi trip dataset, which is is pretty big. You know, Tim notes that it resulted in a data frame at times occupying 15 gigs of memory, in his r session, and and duck duck plier was able to perform all 4 of the queries that he wrote in, like, a little over 2 seconds, which is is it's incredible. And like you said, it definitely opens up the possibility for leveraging DuckDb and and WebAssembly WASM to be able to to run these things completely client side, on a page that doesn't necessarily have, you know, your traditional server behind it, leveraging Shiny Live, you know, connecting to to s three sources, HTTPS sources, and yeah, it's the the possibilities are are just endless here, and I'm so excited to continue to watch this space and see what happens in the next next year, 2 years, things like that. Maybe I've spun up, you know, my last digital ocean droplet here in the next next year or 2, because we'll just be deploying everything on on GitHub pages.
But we'll we'll have to see. We'll have to see. It's really, really exciting time to be in the data
[00:33:50] Eric Nantz:
space. Konas Otterberg and myself, man. I'm really intrigued by where I can where I can take these efforts. And there's gonna be a lot of fast moving pieces in this, so we'll be watching this space quite closely. And where you can watch this and many more developments is, of course, our weekly itself where we have so much more than just these highlights that we share in every issue, such as new packages, updated packages, and awesome showcases of our in the real world and tutorials. Almost there's always something for everybody. So we'll take a minute for our additional finds here, and I'm gonna gonna plug our our first highlight author, once again, Thomas Sandman. He has another post on this issue about querying JSON files with AWS Athena and this Noctua r package. Now this is pretty sophisticated stuff, but imagine you have data collected as JSON files, which, of course, is quite common in the world of web technology and web development, that you could, with this athena, service and with the Noctua package, treat those as if they were a DBI compliant data source and be able to leverage, say, dplyr code to do manipulations, do summaries, and whatnot.
So, as I think about ways I can store data interoperability wise between R and other frameworks that they all can access it efficiently, I'm definitely gonna keep an eye on this space. So that was,
[00:35:20] Mike Thomas:
a lot of moments on that post Laurent by Thomas. So definitely check that out. No. That's a great find, Eric. Yeah. There's there's a lot of actually additional highlights from the Datawookie blog by Andrew Collier. And, one that I'll I'll point out, which is a nice short and sweet one, it resonates with a lot of what we do is is on model validation, and it looks like, he has a model developed to try to estimate, stock market returns or financial portfolio returns as well and has 3 different methodologies for trying to evaluate whether the model he developed is a quote unquote good model. So it's an interesting one to to check out if you're in the model validation space.
[00:36:00] Eric Nantz:
Nice. Yeah. I'll be checking that out as well. We're dealing with models left and right around here like everyone else. Very cool. And, of course, the rest of the issue is just as cool, so we invite you to check it out. The issue is always linked in the show notes, and John did another wonderful job curating this for us. And, again, our weekly is powered by all of you in the community. So the best way to help our project is to help send us a poll request for that new blog, that new resource, that new package, all marked down all the time. Details are at r wicked dot org. The upper right corner takes you directly to the upcoming issue draft. And, I think, yours truly is on the docket for next week's issue, so I can definitely use all the help I can get. So definitely help out your humble host here if you can.
But we also love hearing from you in the audience as well. You can send us a note on our contact page. This is directly linked in the show notes. Also, you can send us a fun little boost if you're using a modern podcast app like Paverse, Fountain, or Cast O Matic, Curio Castor. There's a whole bunch out there. And so you'll see details about that in the show notes as well. And we are still randomly walking those social media pathways. I'm mostly on Mastodon these days with at our podcast at podcast index.social. I am also on LinkedIn under my name, Eric Nance, and from time to time on the x thingy at the r cast. Mike, where can the listeners find you?
[00:37:26] Mike Thomas:
Sure. You can find me on mastodon@[email protected], or you can check out what I'm up to on LinkedIn by searching Catch Brook Analytics, ketchbrook. And I wanna shout out Matan Hakim for his message on mastodon after I put out a little post, on Llama 3 saying that they did not have Catchbook Analytics in the training data when we asked them who Catchbook Analytics was, and he recommended, that they the developers, I guess, meta, of Llama 3, should have used the Our Weekly Highlights podcast as training data, which would have enabled them to, definitely spell Catch Brook Analytics because it's something that I apparently do at the end of every single episode. So sorry to the listeners for that, but not sure if it's gonna stop.
[00:38:15] Eric Nantz:
No. No. We we we keep we keep consistency on this show. So, yeah, Nada, get on this, buddy. We got we you gotta update your training data.
[00:38:23] Mike Thomas:
That was awesome. Seriously.
[00:38:25] Eric Nantz:
Yes. Yes. Well, our weekly itself shouldn't be hard to spell. Again, we're at our weekly dotorg for everything, so definitely bookmark it if you haven't. But, of course, we very much appreciate you listening from wherever you are around the world. It's always a blast to do this show, and we'll keep the train going as they say. So that will put a bow on episode 162, and we'll be back with episode 100 63 of our weekly highlights next week.
Additional Finds
Episode Wrapup
