
The Nix and R train rolls on with automated caching, a collection of big improvements landing in webR, and how hand-crafted visualizations bring fundamental dplyr grouping operations to life.
Episode Links
Episode Links
- This week’s curator: Jon Calder (@jonmcalder) (X/Twitter)
- Reproducible data science with Nix, part 11 – build and cache binaries with Github Actions and Cachix
- webR 0.3.1
- Visualizing {dplyr}’s mutate(), summarize(), group_by(), and ungroup() with animations: Visually explore how {dplyr}’s more complex core functions work together to wrangle data
- Entire issue available at rweekly.org/2024-W15
- Bruno’s unit test involving {tidyselect} https://raw.githack.com/b-rodrigues/nixpkgs-r-updates-fails/targets-runs/output/r-updates-fails.html
- Cachix https://www.cachix.org/
- R/Medicine Call for Abstracts Open https://www.r-consortium.org/events/2024/04/05/r-medicine-coming-june-10-14-2024
- Survival analysis for time-to-event data with tidymodels https://www.tidyverse.org/blog/2024/04/tidymodels-survival-analysis/
- Use the contact page at https://rweekly.fireside.fm/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
- Mike Thomas: @[email protected] (Mastodon) and @mike_ketchbrook (X/Twitter)
- Sun Ra - Ragnarok Online - Anthony Lofton, Joshua Morse - https://ocremix.org/remix/OCR01811
- Chopinesque Kirby - Kirby’s Dream Land - Bladiator - https://ocremix.org/remix/OCR01257
[00:00:03]
Eric Nantz:
Hello, friends. We're back at episode 160 of the our wicked highlights podcast. My name is Eric Nance. And, hopefully, if you're able to listen to this, then the world is still spinning after the, little bit of an eclipse event we had here in this side of the world. But in any event, we are happy that you join us from wherever you are around the world. And as always, this show is our weekly take on the latest highlights that have been featured in this particular week's our weekly issue. And as always, I am never doing this alone, and he also survived the eclipse as well. My co host, Mike Thomas. Mike, how are you doing today? Doing pretty well, Eric. Yeah. We caught,
[00:00:40] Mike Thomas:
it here in Connecticut on the East Coast in the USA. I think, like, 95% of of total coverage. We weren't in the, line of totality as you are, but it was still still a pretty cool experience.
[00:00:54] Eric Nantz:
Yeah. I was here in the, Midwest. Got the lucky straw on this one, so had to take a very long trek. I mean, only a few steps to field in our neighborhood to check it out with a few, friends and and kids around. So, yeah, all in all, a good time. Temperature goes way down. You in about 3 minutes, it looked like we were in twilight zone. But, hey, I won't complain. It was a a ton of fun, and the world has still survived. So didn't have any, like, y two k issues from yesterday or anything like that. Internet is still on. It is still on. We're still recording here. And, thankfully, the Internet's on because that means that y'all can see the latest Our Weekly issue, which we're going to be talking about now, which has been curated by John Calder, another one of our long time contributors and curators on the project.
And as always, he had tremendous help from our fellow Rwicky team members and contributors like all of you around the world. Well, one of the rweekly highlights, especially in the last few months, if we didn't check-in with a good a good friend of the show who is continuing his journey with Knicks and r. And, of course, I am speaking about Bruno Rodriguez and his latest blog post on his blog, which is part 11. Yes. 11 of this series of reproducible data science with Nix. And this is gonna have a lot of aspects that I think you as a user and as a developer will both sympathize with. And I think open your eyes. There are a couple really interesting things that we can do with this ecosystem.
How does this part of the journey begin? Starts innocently enough with a package that Bruno has released years ago called chronicler. And he gets an email from the crane maintainers saying that there's been a failure in the build. What does this mean? So, of course, he checks out the CRAN package results. And this is where things start to really get out here because there is only 2 instances of r on Linux, and in particular, the Fedora distribution of Linux, that have the failure of the checks, yet Debian as well as, of course, the Windows and macOS test results all pass.
Now that is a head scratcher in and of its own because intuitively would think if there was a failure, a, would happen everywhere, and, b, even if it was isolated to Linux, that would hap but not all the Linux distributions that is checking. But that is not the case here. And so Bruno starts a little detective work. Right? And then he realizes, well, what would have happened on that particular day of the failure? Sure enough, there was an update to one of the dependencies. I would say a dependency of a dependency of his Chronicler package because it's not that obvious.
But in particular, the tidy select package, which for those aren't aware, is what powers now many of the tidyverse packages, functions that have to do with helpers in your select calls, like maybe select one of of the starts of a string or things like that. Well, it just so happened that tidy select got a new version on this day or at least the day before that this failure came to be. Now, again, you're wondering why on earth would this only affect one of the Linux variants. Turns out that Fedora is compiling the packages from source on each of these test runs, whereas the Debian distribution, and Debian is actually the base of the very popular Ubuntu distribution, that is using binaries of packages when they're available.
But for Fedora, they're not as available, these binary versions of packages. And, hence, a, you know, recently updated version of tidy select landed on the Fedora version, and there was an update in the tidy select, functions where an error message, in this case for eval select, was giving a more targeted message in terms of where that was actually happening in a select operation versus a subset operation. And Bruno, you know, listening to the advice of many package authors, has a very sophisticated automated testing suite where he is able to pinpoint one of the errors where this was failing because he was on the actual context of the error message or one of these select calls. We'll actually have a link in the show notes to this exact test because I I was just doing a bunch of testing for an internal package myself. So I'm always curious what others are doing in this space. And sure enough, yeah, that test was being triggered.
But because the other versions of Linux were not updated with the new tidy select binary yet, those pass the flying colors because that error message was the same as what he had built it on. Well, okay. Now what? Now what could we do differently here or at least what he could do differently here? Well, now that he's narrowed down where this failure occurred, where could Nix come in here? Well, he has a development environment that's powered by Nix now for building his packages. And, of course, for those who haven't heard the previous episodes, we've been talking about his Rix package, a way to help our users bootstrap these Nix like manifest to bring in dependencies of our packages and be able to constrain those particular versions and whatnot.
Well, he wondered, you know, would this happen on nix? Well, what's interesting enough, and this is another nugget for me, especially some I'll get to in a little bit, is that the packages in NICS that are that are literally corresponding to our packages themselves are actually not updated until a new release of our hits. This is actually kind of marrying a lot of what many of us in the life sciences industry deal with in terms of our internal R installations where there's a central library of packages, but they don't really get updated until a new version of R is released and deployed in production, and then we refresh the library with those. And, apparently, these stable releases on next follow that same paradigm, which that that's kind of food for thought for me as I think about ways of making environments a little more hardened as they say. But that's, again kind of a digression here.
So Bruno, what he wanted to do here is that, well, what what can he do to catch this more in real time with Nicks? And, of course, he has these nice mechanisms in place based on his learning to update what are called expressions in next to cat to bring in more up to date versions of packages. And he was able to do that with tidy select and then be able to then replicate the error on nicks that he was getting on that cran check Infidora. So with that, of course, now he's updated his unit test for chronicler to account for this new message.
That could be it right there. But Bruno, like me, likes to, go go a bit further deep in this and think about what is there a way to have these more up to date versions of packages kind of add availability whenever he needs it instead of, like, custom doing this for one off packages here and there like you did with this tidy select situation. Well, another thing that we've been plugging a lot is using automation when you can. Right? And so Nix can be incorporated quite nicely in GitHub actions, which is, of course, a great way for you to run, like, your CICD testing suite and whatnot for package development.
But could you also combine this with bootstrapping environments of our packages, much like how we often do with r env in a lot of our GitHub actions where we use r env to take in the versions of packages we we use for a given project. And then to get an actual look at that lock file, install everything, and then be just as if we are on our development machine, give or take a few differences, with that particular environment. There is a way to, of course, do this on Nick's, but he had to do a little bit of magic along the way. Well, him and his colleague, Philip Bowman have started a GitHub organization with their fork of the Nix packages repository, which basically contains all the expressions for every package that's built in the Nix ecosystem. And, yes, this includes r itself and the packages within r that are built with these next expressions.
So in theory, you could take this, clone it, update the expression to get, like, a more up to date version of the package. Well, as that version gets up to date, guess what it's gonna have to do? There are no binaries of that new version available at that time, which means you're compiling from source. And yes, if you ever compiled stuff in the tidy verse from source and you're on Linux, get yourself a coffee or a favorite water beverage, you're gonna be there a while. Ain't nobody got time for that. Right, Mike?
[00:10:38] Mike Thomas:
Nope. No. Especially when it comes to, you know, trying to install the tidy verse or something like that. You know, that's a suite of packages all getting built from source for sure. You're gonna have to, take a walk.
[00:10:51] Eric Nantz:
Take a walk. Get get those steps in, but you don't wanna do that over and over again because you can only do so much walking in the day probably. But there there is a happy medium here. There is a happy ending to this. And that is you can actually, in the Nix ecosystem, have your own binary cache of binary versions of packages. And that is using this service called cachex, which I had never heard about until this post. But, basically, one of the things I've been benoming in my early days of my next journey is the fact that I was having to compile some of our packages from source. And I was living that that very, time this the time sync situation that we were just referencing. But, apparently, with cache x is that you can hook that up to your maybe GitHub action that Bruno is working on here. And in essence, there's some clever manipulation of how this is triggered.
He's got a process now where every day, maybe it's multiple times a day, that then there is a push to this repo that's gonna do the caching. And then that is gonna automatically build these packages if they're new and then push them to this custom cachex binary cache such that if he builds an expression from this point on with next and then he is able to reference this custom cache in his kind of preamble for the expression, it will figure out that, a, is this version of, say, tidy select available on the custom cache that Bruno set up? If yes, it's gonna pull down that binary version right away.
And if it's not in the bind not in that cache x, it's gonna look for most likely where it will be is the default Nix repository for binary cache. If it's a package that hasn't been updated in months, it's probably gonna be there in the next stable repository, and it's gonna pull from that binary cache. So in essence, he's got his he's got a workflow now where he can pull these binary versions either from his custom cache or from the default NICS cache. That to me is massive, folks. That is absolutely massive because this was arguably one of the biggest deterrents I've seen thus far in my limited experience of Knicks that may have just been solved for this quote unquote developer setup.
I'm really intrigued by this because this may be something I want to plug in to my package development because now I actually have 1 or 2 open source packages under my name that are starting to get used by some people that I'm I'm working with. I wanna make sure that I'm up to date on these issues, albeit they're not on CRAN yet. But at the same time, if they ever to get on CRAN, I want to harden my development set up for this. So this is an amazing approach that, again, everything's in the open. They got links, and Bruno's got links in the to the GitHub repository where this cache is being built and this other custom repository that's doing kind of the triggering of all this. I think there are a lot of principles here that we all can take from a developer perspective to give ourselves extra peace of mind for these cases where Kran might have some mysterious errors in these checks. And, of course, they're not gonna tell you how deep the rabbit hole goes of which dependency of a dependency actually caused a failure. It's on you as the as a package maintainer to figure that piece out.
But this may be a step in the right direction to be more proactive in figuring that out. And so I'll be paying attention to this work flow and maybe grabbing some nuggets of this as I continue on my, albeit it's still baby steps, but I've been venturing and running NICS on a virtual machine, trying to start bootstrapping our environments, bootstrapping my other tools of choice from a developer perspective. And this one, I'm definitely gonna keep an eye on as another way to augment my, my potential workflow here. So again, this post had a mix of everything. The detective work to figure out just which dependency caused this error, fixing the annoyance of having to compile all this manually every single time. And lo and behold, we got some really fancy GitHub actions and caching to to thank Bruno for. So kudos to Bruno for this immense rabbit hole journey here in this part of the next journey.
[00:15:19] Mike Thomas:
Yeah. It is a little bit of a rabbit hole, Eric, but I I think there's a lot in here that might be useful to to those using Nix and maybe those even not using Nix or those maybe on their journey as well. You know, one thing that sort of stood out to me is for anyone that has a unit test, in their their R package or their, you know, our repository and that unit test is is maybe running up programmatically or on some schedule or something like that, you should probably be aware that in the latest version of the tidy select package, if you have a dplyr select call and write your that the error message that's going to get returned if one of the columns in that select statement doesn't exist. It used to say can't subset columns that don't exist. Now it says can't select columns that don't exist. So if you have an expect error call in your unit test and you're looking specifically for, that keyword subset, that's not going to to fire anymore. So that test is actually gonna fail because it that that rejects those strings will not match essentially so you may need to go in and update your unit test and take a look at the unit test that you have across your different R packages and repositories to to make sure that you are not too going to get bit by this issue the same way that Bruno did, and it was really interesting to me as well, how, you know, the binaries I guess of the the the release before, I guess, the 1.2.0 release of Tidy Select, which is now, quote unquote, the old version, were the versions of Tidy Select getting installed, on Debian and Windows and and Mac, you know, for these crayon package checks, but it was compiling from source on fedora so that's you know there's there's all these these funky things that take place you know that we I think we see all the time that are huge head scratchers for when your your packages are going through these automated tests across all these different operating systems, when when they're trying to pass their crayon checks.
Right? They'll pass 9 of them and then the 10th one will fail. And it'll probably make you wanna throw your computer out the window half the time. But, you know, it just sometimes takes a little investigative work like like Bruno did or maybe, you know, diving into your your r four d s Slack community or your Mastodon community, and trying to figure out, collectively what's going on here. And hopefully, it didn't take Bruno too long to to figure that out. But, you know, as you you mentioned, I think, Nick's actually is going to allow him to easily, you know, handle these types of situations in the future, where his unit tests need to ensure that they're running against the latest versions of all packages or or maybe, you know, on some OS's, it'll be, you know, building the the latest binaries versus on other OS's, the latest, packages compiled from source.
So, you know, I think one avenue again to to try to do some of this stuff, you know, might be having all sorts of different docker images, to handle all these different edge cases and and use cases and operating systems. But it seems like Nix actually might be a more streamlined, and efficient workflow to be able to to make those switches a little bit quicker and run those tests, within different environments a little quicker to to spin up VMs or something like that or install, you know, all sorts of different versions of our locally and all sorts of different versions of our packages locally and and you know just sort of cross your fingers that, you know, that your package checks would succeed on other operating systems that you didn't really necessarily have any access to. So you know that's really interesting and then and then maybe the last thing I'll point out here that I thought was interesting and and useful you know one a lot of times when we're you know, running GitHub actions. Right? It's it's running on some piece of compute that we we don't have full access to. So it's we're relying really on a YAML file at the end of the day and maybe this goes back to who was it? Yaron Ooms that authored that blog post a couple weeks ago about like, you know, workflows in our Oh. And Oh. You know, that's not repeat yourself. Miles Macbain. Miles Macbain. Oh. Miles Macbain. That's exactly who it was. Yeah. Oh, my goodness. This sort of brings me back to that where you know eventually you get to try to just do everything with it a YAML file and it would drive you crazy but, we're at the mercy you know with GitHub actions actions, you know, for better or for worse a lot has been abstracted for us which is awesome but we're at the mercy of, a YAML file. Right? To be able to handle, you know, setting up that that piece of compute, that runner and GitHub actions, installing the dependencies on there.
And, you know, one thing I think that can be be tricky sometimes is is maybe authenticating it into different services that you wanna leverage. And that was my first thought here when I was taking a look at the this cache x, this cache utility here that allows you to to cache, different, packages, within sort of your next environment. But one of the interesting things is that you don't need to authenticate to cache x to simply pull binaries. All Bruno had to do was was really just these two lines of YAML specifying the cache x GitHub action version that he wants to use and then he has a particular name I assume you know he's logged into the cache x platform and and developed his own cache. That's that's b dash rodriguez, and that's where his cache lives, and that's all he has to specify in his GitHub action to be able to pull, binaries from that cache. So I think that's incredibly powerful, really nice that how simplified sort of this workflow is to be able to set up, your cache x cache, it within a GitHub Actions workflow. So fantastic blog post from start to finish. It really walks us through sort of the entire problems problem space and and how he was able to solve it.
And another feather in in Nick's cap, I would say.
[00:21:37] Eric Nantz:
Yep. I totally agree. And I'm, again, very much anything that can make your development life easier to be proactive on these issues happening, you've done that hard work of building those unit tests. You're doing what you need to do in terms of giving yourself some sanity, hopefully, as dependencies get updated. But, be able to put this in action first when you need it in an ad hoc way, be able to just pull this environment down within probably a matter of a minute versus, like, an hour like it would be by default. I mean, they they can't underscore the time savings you get from the caching mechanism, But also there is a lot to glean from these repositories that you mentioned, Mike, that Bruno and Philippe have set up for these GitHub Action workflows.
I I was in GitHub action nightmares, a couple weeks ago, debugging things. And I remember with a quartile compilation, I just I just I almost just threw my keyboard out the window. I just could not figure out what the bloody heck was happening. So, yeah, there is a danger sometimes of having the abstraction too high up versus what lower level it's doing. And the other piece of advice I'll give is that, you know, it may seem intimidating to be like, these these kind of actions are doing such magical things with these YAMLs. You know what's behind these actions most of the time? It's shell scripting. It's just doing stuff on Linux and then be able to troubleshoot that.
So, like, I went into the GitHub action source of some of those quartile actions, and I figured out, okay. So these kind of quartile commands with this Boolean check if, like, I have this render flag enabled or not. Then I realized, you know what? Okay. I can take matters in my own hands. I can do my own custom rendering. It's not as intimidating as it sounds. It's just the bugging can be a complete nightmare unless you know where to look. So I'm sure I'd imagine Bruno's had a few of those experiences too like all of us.
[00:23:29] Mike Thomas:
Definitely. And GitHub actions has its own sort of cache as well which That is true. Has bit me a couple times not to speak ill of GitHub actions because I do I do love it. But, yeah, it's it's caches everywhere.
[00:23:43] Eric Nantz:
Yep. Caches, unfortunately, is not the kind of cache I could buy things with. But, you know, nonetheless, it's all everywhere. Right? Speaking of major updates that we're seeing in the ecosystems these days in terms of the tooling we use, another one I've kept my very close eye on with a lot of influential projects I'm trying to bootstrap right now is we are happy to talk about a new release for WebR itself. When this blog post comes from the tidyverse blog and authored by the WebR architect and brilliant, engineer George Stagg, who is in this blog post getting us through, you know, or talking us through a few of these major updates that we see in the WebR ecosystem.
And I'm going to speak to a few of these. And I know some of these I'm going to be able to benefit one very quickly, I would imagine. But the first major of note is that now they are basing WebR on the latest stable release of R itself because in essence, they have to bootstrap R with a couple of the custom shims under the hood to make it seem like you're installing a package from a default repository where instead you're installing it from WebR's binary package repository. So they always have to, in essence, patch R to make all this work. And now they patch the latest stable version of R, which, of course, will be great for consistency with maybe your typical environment that you're building these analyses on. And another great feature that I think the users are going to definitely notice is some improved air reporting too.
Whereas in the past, you might see a custom, like, uncalled exemption if something crazy was happening in the WebR process with respect to maybe an error in the r code itself. Well, now you're gonna be able to see the actual error in the JavaScript console whenever WebR is running, which, of course, is going to help you immensely with the bugging to narrow down, oh, did I get the JavaScript code wrong that I'm using WebR with, or was it in my R code itself? So that, again, for usability, a massive improvement for the quality of life. And speaking of quality of life enhancements, ones that you'll they'll hopefully be able to see and interact with is big improvements to the graphics engine.
Because now the graphics that are drawn with WebRx, they call it the canvas function, they're gonna be captured in that R based session in a similar way so that it's consistent with other output types that you would see in a normal installation of R, which is leading to more streamlined, you know, interaction with these graphics. And, also, along those lines, graphics that you create in Base R have had massive improvements to the rendering engine. And the blog post, when you see this linked in our weekly, you'll see very sharp looking images that they're able to produce when you evaluate that code. Even as I'm talking now, I'm running through these snippets, and they look very nice. Great anti alias text.
The symbols with the r logo look really sharp. Everything looks as if you were in your native r session. Again, just massive amazing improvements under the hood to make this, you know, very seamless and attractive to the end user. And it doesn't just stop with graphic objects. There has been a lot of under the hood enhancements as well as some new user facing enhancements that the R objects that are created in these WebR processes are going to be more easily converted back and forth between their JavaScript counterparts and their R counterparts. Where does this fit in the big picture?
The big thing for me is the data frame and r that is literally the fundamental building block of pricing 99% of my analyses. Now, of course, in r, you have your columns and you got your rows. Right? That's not always what JavaScript treats data as, especially if you're familiar with d 3. It is definitely a different type of layout you often see where it's basically the column is given a name. It's like a named vector of things in a row wise type fashion layout. But there are functions now in WebR to go back and forth between these JavaScript notations and the R native kind of representations.
In fact, there's a handy function called 2d3, where you can simply take that data frame in the R process, put it into a format that you could feed in any of your custom d three visualizations. These things are massive for that interoperability between maybe using r to do the heavy lifting statistically. But if you're familiar with JavaScript and you wanna keep with those JavaScript visuals, have at it. Have your d three magic and be able to get that that construct of the data as you need it. So, again, great way for you to take maybe baby steps if you're new to R, but you're familiar with JavaScript, a way to get the best of both worlds. Really, really a big fan of that.
And then some really fun plumbing type enhancements here that I'm paying a lot of attention to is that with collaboration, you named dropped them earlier, Mike, your own ooms as well as, Utahn. They have new system libraries in the WebR process and as well as a custom WebR Docker container. Hey. Containers again for you. Which they've included some new numeric libraries as well as the ImageMagick image manipulation suite. And wait for it. There is now a Rust compiler configured so that if your R package involves Rust in some way, you're not gonna be able to compile that into web assembly 2. Absolutely amazing stuff.
And to really, you know, you know, intrigue you even further, embedded in the post is a Shiny Live powered web app from your own himself on using that magic package that he's created in the past. But now in the blog post where you can absolutely distort or make fun of this random cat image. And I'm literally doing it right now as I speak. It is so responsive so quick. I can't believe this is happening, Mike. This is just amazing.
[00:30:30] Mike Thomas:
It's as if the shiny apps running locally. It's insane. It's actually, like, faster. I mean, the the fact that you can put effects on this image to like negate it and you know you totally changing how it's visually represented is awesome. You can upload your own image which is what I've done. I uploaded an old hex logo and I'm just messing around with it right now, rotating it, blurring it, imploding it you know it's it's pretty cool it flipping it reversing it yeah It's it's it's awesome. I cannot believe how responsive it is.
[00:31:03] Eric Nantz:
Yeah. This has come such a long way. I mean, even it was maybe, what, 4 or 5 months ago that would take a good minute or 2 for these things at Boostramp, and here we are. We got this as if it was plugged into the blog post directly. Like, this is this is magical stuff. So I'm really, really intrigued by by where this is going. And, again, we're seeing more in the community leverage Rust. So I'm sure there's going to be a lot of grain enhancements with this. And speaking of packages themselves, there is now additional, refresh, if you will, on the packages in in the CRAN ecosystem that are now supported in WebR, that total is now bumped to 12,969 or about 63% of the available CRAN packages that are now supported natively in WebR.
And like I mentioned before, what George and other engineers have to do with this WebR binary cache of packages is they have to compile them in a special way so that they're supported by web assembly. So not everything is there yet, but that's a massive jump compared to where we've been even just like I said a few months ago to what is supported in webr. That is absolutely amazing.
[00:32:18] Mike Thomas:
Yes. I couldn't agree more, and this is just, you know, more exciting improvements. I think, you know, probably the biggest thing for me as a, you know, practitioner, somebody who who's very data, hands on in most of our projects as well as as you talked about, Eric. The ability to to switch back and forth, between JavaScript sort of data frame objects, you know, especially, I guess, particularly in this case, we're talking about raw objects of typed array array buffer and array buffer view those are the types of raw vector objects that may now be used to construct our objects and like you said you can go back from an our data frame to a Javascript object with the either 2 object function or if you want to go more the d3 route that would be the the 2 d three function in Javascript so that's exciting because to me that makes it feel you know much more our framework as well. It kinda feels a little, I've been watching a lot of the observable project and they have some some excellent, utilities, blog post documentation around how to sort of convert back and forth between either pandas data frames, our data frames, and you know the JavaScript data frames that really power the visuals, on that platform. So this sort of reminds me of that in terms of how easy it is to go back and forth between the 2, and I think that that ease of use is really going to go a long way towards helping people get up to speed and build tools, within the WebR framework. So very very excited.
Thanks to to all who work on this. There's a fantastic acknowledgment section at the bottom of this and and a lot of familiar names there of folks who are are working hard to continue to drive this this forward and, you know, especially thanks to to George Stagg for sort of spearheading all of this and putting the blog post together.
[00:34:15] Eric Nantz:
Yeah. And and and any package authors out there that are saying, hey. You know what? I know my package is not crayon. Can I do this a web assembly? Oh, yes. You can. They actually have a r WASM package to help you compile your own r package into WebAssembly and be able to manage a repository for that. And, yes, we were talking about GitHub actions earlier. Another, you know, nugget at the end here is that they have put links to their reusable GitHub Actions that you could get inspiration from or just leverage yourself so that your package is compiled.
And, yes, you can also, check out we talked about this before. The R Universe project is offering WebR binaries of packages on any of the packages that they host too. So there is not just that binary, repository that WebR is hosting themselves. You know, our universe is another great inspiration or a great source of this as well. So lots to choose from in this space.
[00:35:15] Mike Thomas:
Yes. Absolutely. Don't blink.
[00:35:25] Eric Nantz:
Don't blink. You might miss it. Just like how you might miss some very snazzy visuals that we're gonna talk about on our last highlight today. And as you know, Mike, you and I can probably sympathize, especially early on in maybe a data science journey or you're leveraging Are you hearing about things like the tidyverse, you know, suite of packages for the first time, and you're trying to get a handle on a lot of these operations that occur when you want to manipulate your data frames like adding new variables, doing transposing, you know, doing group summaries.
A lot of people, myself included, do like to have a nice visual to accompany maybe the text around just what those particular functions are doing. Well, we're happy to share that Andrew Hice has authored a latest blog post on visualizing many of the important dplyr functions with both, single group as well as multiple group processing. And not just having static pictures, folks, he has handcrafted some absolutely amazing animations to go with this. I can I can imagine he is making heavy use of this in his statistics, lectures and his coursework?
But, yeah, of course, we're we're in an audio podcast talking about visuals here, but boy oh boy, you look at these and how he made them, first off, is that he tried to leverage what Garrigade and Bowie, from has built with his custom visuals in the tidy explain package, but he was running into a couple limitations. I'll be especially around the group processing. So Andrew is showing his, graphical editing shops here, has built custom Adobe Illustrator powered visuals and after effects. But guess what? He's actually shared the the files that if you have the software, you go import this in and try it yourself.
I I'm not an Adobe customer, so I can't exactly run this myself. But, hey, it's there if you have that same software. But throughout the blog posts, he's got not just the narrative of what a function does such as mutate. You can simply hit play in the blog post and then see literally the transformation of that data with this nice transition kind of layout from left to right with new variables or new records being colored the same as the new code snippet that's being shown on the right side. It is very easy to digest. It does as a mutate with summarize, and then where it really starts to shine is the grouping visuals. Or now, if you're grouping by a categorical variable, he's able to separate these blocks out logically and then really show the impact of that operation and then be able to ungroup that at the end to get that original setback or things like that. And also custom mutations within groups. So he's got the code snippets alongside the visuals. Again, really great to digest visually what is happening here. And, boy, I wish I'd had this when I was learning the manipulation in the old days. But, of course, in my day, not to be that guy saying get off my lawn, we didn't have Dplyr back then. We had Plyr midway through my hour journey, and that did not have nearly the resources that dplyr has both under the hood as well as in educational materials.
But, again, the visuals really do a terrific job of really isolating the key incremental steps in these operations, which I think you can see it in a pipeline operation just with the text. But seeing that visual paired with it, you really start to see what is the impact of each of those statements. So there is a whole lot to digest here. We definitely invite you to check out the post because our ramblings can only do us so much justice, But, kudos kudos to Andrew for handcrafting all this from the ground up. It is truly amazing stuff.
[00:39:28] Mike Thomas:
Yes. This is fantastic. You know, I think I know Andrew is a professor, and this is just go I wish I had him as a professor because this I know. Is just going to go, such a long way towards building his his students understanding of, you know, especially, you know, I think I think mutate, isn't isn't too difficult to wrap your head around. It's a little straightforward, but once you start getting into grouping by aggregation, summarization, doing a mutate on a grouped data frame, joins, things like that, It it, you know, takes it to an additional level of, you know, abstraction that can be difficult to wrap your head around when you're when you're a beginner.
And back in my day, Eric, it was, Excel pivot tables. That's how I first got my my start in, you know, understanding some of these concepts and then I had to bring it over, to the our side and I was like, wow. Hey, you know, this is a, maybe a hot take a little bit but what has a better expressive syntax to tell you exactly what it's doing, than dplyr and the tidyverse. I don't think there's anything else out there. Sure surely a whole lot better than Excel. I I can at least tell you that much in in terms of just being able to to look at the code, you know, I think SQL is probably a close second, but to be able to look at the code and understand sort of exactly what's going on and, you know, these examples applied to data, I think are fantastic. These these visuals go such a long way towards building that understanding as well because you can he's really representing sort of the the action taking place here, whether it be grouping, summarization, or a mutate.
So, yeah. Hats off to him. I would say that that his work doing this, he may not realize just how impactful this might be on his students or, you know, folks learning r who stumble across this blog post. So if you if you know someone, who's who's trying to learn r having a tough time, you know, first point them to the Tidyverse. That would be my recommendation to wrap their head around dang data wrangling, but I think this is going to be a fantastic blog post to to point people to as well, to help them get up to speed, to help them sort of get over the hump, right, in building their understanding of data manipulation in R. So I I really just can't understate, you know, I've said it a few times now, but I can't understate sort of the importance of this and, how useful I think this type of visual instruction can be.
[00:42:03] Eric Nantz:
And another thing I wanna say is critically important, especially in this new age of, I don't know how new it is per se, but really someone I've been gleaming in the community of really openly sharing our our wins and our key learnings to educate ourselves and others is that you may be wondering, oh, wow, Andrew. You did such amazing work with this. I wish I could use this in my materials. Guess what? You can, folks. These are all Creative Commons license, which means he's got links to, like, the finished products, both the video form and animated GIFs and static images of all this. So if you wanna leverage this in your materials, have at it. Right? I mean, that is a huge service that Andrew has done here. He could have easily kept this under his own, like, private coursework, you know, materials, but he's sharing it with all of us. So I think that is a massive win for all of us kind of in this educational space. So even our organization is trying to help teach others that are new to R how some of these operations work.
You better believe I'll be, drawing upon some of this when I get questions about how some of these, you know, group processing and deep wire works and the like. It's just amazing amazing work, Andrew, and even more amazing that you are so willing to share this with everybody. It's a new it's a new age, I would say.
[00:43:29] Mike Thomas:
And has the time to author all of this content out there. I don't know how he does it, but thank you so so much.
[00:43:35] Eric Nantz:
Yeah. I I whatever you're you're, either ingesting or whatever life hack you've done, please pass it our ways because we we would love to have it. I respect the It's gotta be those damn cold tubs. I still gotta do that. Yeah. Yeah. I think we're late on that, aren't we? But, you know, what you're not late on is that if you boot up our week without org, you're never going to be late and seeing the latest and greatest from the R community showcased by the R community. Great new packages, new announcements, and new blog posts, much like what we talked about here. And we'll take a couple of minutes to share some of our additional fines from the issue. And for me, it's a plug, especially for those in the health and medical industries.
The Our Medicine Conference is back for another year, and they have just opened up their their open call for talks. And that conference is taking place on June 10th or 14th this year. And on top of having the call for abstracts and and talks open, they've announced that they have keynotes lined up from Stephanie Hicks and Gunilla Bosch, talking about some really innovative work in medical research and genomic analysis. Always stuff that I resonate with, especially in the early part of my career where r was immensely helpful as I was doing a lot of genetic the to the post from the Arkansas Museum of all the details. And it's always been a really top notch and well run conference. It's been a great kind of companion in arms, so to speak, with our pharma conference that I'm a part of. But, yeah, they all are very complementary of each other and really great to see these resources shared in the community.
Mike, what did you find?
[00:45:27] Mike Thomas:
No. That's awesome, Eric. I found a fantastic blog post, I think, authored by, Hannah Frick, who's a member of the Tidymodels team at Posit, and she's been instrumental in incorporating survival analysis into the tidy models ecosystem. So there is now support for survival analysis for time to event data across tidy models, which is is really really fantastic and exciting for those of us, which, I know you as much in life sciences as, believe it or not, me, in financial services and and credit risk, use these time to event survival analysis types of models because, they handle, you know, leveraging longitudinal data.
They, you know, have a good setup to be able to introduce hierarchical models as well, with mixed effects models or or Bayesian type models that, you know, are and these these longitudinal, types of data sets, as well as these hierarchical types of data sets, we see them all the time. I mean, that that those things are present in a lot of the data sets that we work with in a way that machine learning just can't necessarily handle. Right? So survival analysis is really a great tool to be able to use in those particular use cases.
There's a fantastic amount of links in here. There's also an additional blog post that walks through a very hands on, data use case, a a case study here called how long until building complaints are dispositioned. That's now on the Tidymodels website. It's it's linked at the very bottom of this blog post, and that's, sort of how I I came across this Our Weekly Highlight as well, because I saw that one, I think, come across Mastodon. And it's just a great, great walk through and and use case of all the different functionality that we now have around survival modeling, within the Tidymodels framework. So super excited about this. Thanks to all the folks that worked on this, and thanks to to Hannah for putting this blog post together.
[00:47:31] Eric Nantz:
Yeah. I'm diving in. I'm gonna dive into this case study after this because, I'm starting to get back into the time to event mode now with some custom analysis and clinical operations. And this could be a very nice way to benchmark newer models and take what I've been learning over the years of tiny models and apply it directly to time the event. It has been requested for a long time, and it is gratifying to see the tiny models team has taken this head on, and now we've got a boatload of additional capabilities to choose from. So, yeah, kudos to everybody on the team for that.
[00:48:06] Mike Thomas:
Yeah. No trivial effort, I'm sure, because survival analysis modeling has a lot of different nuances for machine learning, but you can still borrow a lot of practices, you know, that we might traditionally associate with machine learning, like, hyperparameter tuning and things like that, and and leverage those within survival analysis workflow. So, it was no trivial effort, I'm sure, but extremely powerful, when brought together. And I'm very grateful for the fact that they have.
[00:48:35] Eric Nantz:
Yes. Absolutely. And I'm also grateful for hey. Hey. Our weekly even existing. So we can see this on a weekly basis and be able to talk to all of you about it. But it is, like I mentioned, powered by the community, and we always are appreciative of all of your help. And the best way to contribute to our weekly is send us a poll request with that awesome new blog post, that great new package you discovered, that great new resource that you think deserves the attention of the community. Is just a poll request away at the top right corner of r o k dot org. You'll see the frame little Octocad image there. Just click on that, and you got yourself a pull request template right there. It's all marked down all the time. I live in markdown. I live and breathe markdown now. I wish I could write my emails in markdown and have them render in real time, but that thing happened in Microsoft Outlook anytime soon. But I digress. At least, so every week, it does. So you can have that at your at your at your fingertips.
And as well as we love hearing from all of you in the audience as well, you got a few ways to get in touch with us. Got a handy little contact page linked in this episode show notes and as well as you can send us a friendly little boost along the way if you're on those awesome modern podcast apps like Podverse, Fountain, Cast O Matic, CurioCaster. I could go on and on. They're all linked in the show notes if you wanna get a nice selection of all that. And, yeah, this is now gonna be the 2nd episode. Our new podcast host, and everything is yours truly botching his end of the recording. Let's hope that this one goes more smoothly this time around. Did some testing before this, fingers crossed. It'll sound as clear as we've always been, but, we are on a new host. So if you have any trouble finding the show, we have updated all the links at rweekly to our new podcast landing page, so it should be a seamless transition.
But as always, don't hesitate to get in touch with me if you have any difficulties. And the best way to do that, you can find me on Mastodon these days. I am at our podcast at podcast index on social. I'm also on LinkedIn, with show announcements and the like. And on that Twitter x thingy jingy at DR cast. And, Mike, where can the listeners find you?
[00:50:41] Mike Thomas:
Sure. You can find me on mastodon don@mike_thomas@fossedon, dot org, or you can find me on LinkedIn by searching Ketchbrook Analytics, k e t c h b r o o k, and see what I'm up to lately.
[00:50:57] Eric Nantz:
Awesome stuff. And, yep. We we were on the other side of that major eclipse event, but the the community train never stops over the our ecosystem. And as always, we thank you so much for listening to us wherever you are around the world, and we will be back with another edition of our weekly highlights next week.
Hello, friends. We're back at episode 160 of the our wicked highlights podcast. My name is Eric Nance. And, hopefully, if you're able to listen to this, then the world is still spinning after the, little bit of an eclipse event we had here in this side of the world. But in any event, we are happy that you join us from wherever you are around the world. And as always, this show is our weekly take on the latest highlights that have been featured in this particular week's our weekly issue. And as always, I am never doing this alone, and he also survived the eclipse as well. My co host, Mike Thomas. Mike, how are you doing today? Doing pretty well, Eric. Yeah. We caught,
[00:00:40] Mike Thomas:
it here in Connecticut on the East Coast in the USA. I think, like, 95% of of total coverage. We weren't in the, line of totality as you are, but it was still still a pretty cool experience.
[00:00:54] Eric Nantz:
Yeah. I was here in the, Midwest. Got the lucky straw on this one, so had to take a very long trek. I mean, only a few steps to field in our neighborhood to check it out with a few, friends and and kids around. So, yeah, all in all, a good time. Temperature goes way down. You in about 3 minutes, it looked like we were in twilight zone. But, hey, I won't complain. It was a a ton of fun, and the world has still survived. So didn't have any, like, y two k issues from yesterday or anything like that. Internet is still on. It is still on. We're still recording here. And, thankfully, the Internet's on because that means that y'all can see the latest Our Weekly issue, which we're going to be talking about now, which has been curated by John Calder, another one of our long time contributors and curators on the project.
And as always, he had tremendous help from our fellow Rwicky team members and contributors like all of you around the world. Well, one of the rweekly highlights, especially in the last few months, if we didn't check-in with a good a good friend of the show who is continuing his journey with Knicks and r. And, of course, I am speaking about Bruno Rodriguez and his latest blog post on his blog, which is part 11. Yes. 11 of this series of reproducible data science with Nix. And this is gonna have a lot of aspects that I think you as a user and as a developer will both sympathize with. And I think open your eyes. There are a couple really interesting things that we can do with this ecosystem.
How does this part of the journey begin? Starts innocently enough with a package that Bruno has released years ago called chronicler. And he gets an email from the crane maintainers saying that there's been a failure in the build. What does this mean? So, of course, he checks out the CRAN package results. And this is where things start to really get out here because there is only 2 instances of r on Linux, and in particular, the Fedora distribution of Linux, that have the failure of the checks, yet Debian as well as, of course, the Windows and macOS test results all pass.
Now that is a head scratcher in and of its own because intuitively would think if there was a failure, a, would happen everywhere, and, b, even if it was isolated to Linux, that would hap but not all the Linux distributions that is checking. But that is not the case here. And so Bruno starts a little detective work. Right? And then he realizes, well, what would have happened on that particular day of the failure? Sure enough, there was an update to one of the dependencies. I would say a dependency of a dependency of his Chronicler package because it's not that obvious.
But in particular, the tidy select package, which for those aren't aware, is what powers now many of the tidyverse packages, functions that have to do with helpers in your select calls, like maybe select one of of the starts of a string or things like that. Well, it just so happened that tidy select got a new version on this day or at least the day before that this failure came to be. Now, again, you're wondering why on earth would this only affect one of the Linux variants. Turns out that Fedora is compiling the packages from source on each of these test runs, whereas the Debian distribution, and Debian is actually the base of the very popular Ubuntu distribution, that is using binaries of packages when they're available.
But for Fedora, they're not as available, these binary versions of packages. And, hence, a, you know, recently updated version of tidy select landed on the Fedora version, and there was an update in the tidy select, functions where an error message, in this case for eval select, was giving a more targeted message in terms of where that was actually happening in a select operation versus a subset operation. And Bruno, you know, listening to the advice of many package authors, has a very sophisticated automated testing suite where he is able to pinpoint one of the errors where this was failing because he was on the actual context of the error message or one of these select calls. We'll actually have a link in the show notes to this exact test because I I was just doing a bunch of testing for an internal package myself. So I'm always curious what others are doing in this space. And sure enough, yeah, that test was being triggered.
But because the other versions of Linux were not updated with the new tidy select binary yet, those pass the flying colors because that error message was the same as what he had built it on. Well, okay. Now what? Now what could we do differently here or at least what he could do differently here? Well, now that he's narrowed down where this failure occurred, where could Nix come in here? Well, he has a development environment that's powered by Nix now for building his packages. And, of course, for those who haven't heard the previous episodes, we've been talking about his Rix package, a way to help our users bootstrap these Nix like manifest to bring in dependencies of our packages and be able to constrain those particular versions and whatnot.
Well, he wondered, you know, would this happen on nix? Well, what's interesting enough, and this is another nugget for me, especially some I'll get to in a little bit, is that the packages in NICS that are that are literally corresponding to our packages themselves are actually not updated until a new release of our hits. This is actually kind of marrying a lot of what many of us in the life sciences industry deal with in terms of our internal R installations where there's a central library of packages, but they don't really get updated until a new version of R is released and deployed in production, and then we refresh the library with those. And, apparently, these stable releases on next follow that same paradigm, which that that's kind of food for thought for me as I think about ways of making environments a little more hardened as they say. But that's, again kind of a digression here.
So Bruno, what he wanted to do here is that, well, what what can he do to catch this more in real time with Nicks? And, of course, he has these nice mechanisms in place based on his learning to update what are called expressions in next to cat to bring in more up to date versions of packages. And he was able to do that with tidy select and then be able to then replicate the error on nicks that he was getting on that cran check Infidora. So with that, of course, now he's updated his unit test for chronicler to account for this new message.
That could be it right there. But Bruno, like me, likes to, go go a bit further deep in this and think about what is there a way to have these more up to date versions of packages kind of add availability whenever he needs it instead of, like, custom doing this for one off packages here and there like you did with this tidy select situation. Well, another thing that we've been plugging a lot is using automation when you can. Right? And so Nix can be incorporated quite nicely in GitHub actions, which is, of course, a great way for you to run, like, your CICD testing suite and whatnot for package development.
But could you also combine this with bootstrapping environments of our packages, much like how we often do with r env in a lot of our GitHub actions where we use r env to take in the versions of packages we we use for a given project. And then to get an actual look at that lock file, install everything, and then be just as if we are on our development machine, give or take a few differences, with that particular environment. There is a way to, of course, do this on Nick's, but he had to do a little bit of magic along the way. Well, him and his colleague, Philip Bowman have started a GitHub organization with their fork of the Nix packages repository, which basically contains all the expressions for every package that's built in the Nix ecosystem. And, yes, this includes r itself and the packages within r that are built with these next expressions.
So in theory, you could take this, clone it, update the expression to get, like, a more up to date version of the package. Well, as that version gets up to date, guess what it's gonna have to do? There are no binaries of that new version available at that time, which means you're compiling from source. And yes, if you ever compiled stuff in the tidy verse from source and you're on Linux, get yourself a coffee or a favorite water beverage, you're gonna be there a while. Ain't nobody got time for that. Right, Mike?
[00:10:38] Mike Thomas:
Nope. No. Especially when it comes to, you know, trying to install the tidy verse or something like that. You know, that's a suite of packages all getting built from source for sure. You're gonna have to, take a walk.
[00:10:51] Eric Nantz:
Take a walk. Get get those steps in, but you don't wanna do that over and over again because you can only do so much walking in the day probably. But there there is a happy medium here. There is a happy ending to this. And that is you can actually, in the Nix ecosystem, have your own binary cache of binary versions of packages. And that is using this service called cachex, which I had never heard about until this post. But, basically, one of the things I've been benoming in my early days of my next journey is the fact that I was having to compile some of our packages from source. And I was living that that very, time this the time sync situation that we were just referencing. But, apparently, with cache x is that you can hook that up to your maybe GitHub action that Bruno is working on here. And in essence, there's some clever manipulation of how this is triggered.
He's got a process now where every day, maybe it's multiple times a day, that then there is a push to this repo that's gonna do the caching. And then that is gonna automatically build these packages if they're new and then push them to this custom cachex binary cache such that if he builds an expression from this point on with next and then he is able to reference this custom cache in his kind of preamble for the expression, it will figure out that, a, is this version of, say, tidy select available on the custom cache that Bruno set up? If yes, it's gonna pull down that binary version right away.
And if it's not in the bind not in that cache x, it's gonna look for most likely where it will be is the default Nix repository for binary cache. If it's a package that hasn't been updated in months, it's probably gonna be there in the next stable repository, and it's gonna pull from that binary cache. So in essence, he's got his he's got a workflow now where he can pull these binary versions either from his custom cache or from the default NICS cache. That to me is massive, folks. That is absolutely massive because this was arguably one of the biggest deterrents I've seen thus far in my limited experience of Knicks that may have just been solved for this quote unquote developer setup.
I'm really intrigued by this because this may be something I want to plug in to my package development because now I actually have 1 or 2 open source packages under my name that are starting to get used by some people that I'm I'm working with. I wanna make sure that I'm up to date on these issues, albeit they're not on CRAN yet. But at the same time, if they ever to get on CRAN, I want to harden my development set up for this. So this is an amazing approach that, again, everything's in the open. They got links, and Bruno's got links in the to the GitHub repository where this cache is being built and this other custom repository that's doing kind of the triggering of all this. I think there are a lot of principles here that we all can take from a developer perspective to give ourselves extra peace of mind for these cases where Kran might have some mysterious errors in these checks. And, of course, they're not gonna tell you how deep the rabbit hole goes of which dependency of a dependency actually caused a failure. It's on you as the as a package maintainer to figure that piece out.
But this may be a step in the right direction to be more proactive in figuring that out. And so I'll be paying attention to this work flow and maybe grabbing some nuggets of this as I continue on my, albeit it's still baby steps, but I've been venturing and running NICS on a virtual machine, trying to start bootstrapping our environments, bootstrapping my other tools of choice from a developer perspective. And this one, I'm definitely gonna keep an eye on as another way to augment my, my potential workflow here. So again, this post had a mix of everything. The detective work to figure out just which dependency caused this error, fixing the annoyance of having to compile all this manually every single time. And lo and behold, we got some really fancy GitHub actions and caching to to thank Bruno for. So kudos to Bruno for this immense rabbit hole journey here in this part of the next journey.
[00:15:19] Mike Thomas:
Yeah. It is a little bit of a rabbit hole, Eric, but I I think there's a lot in here that might be useful to to those using Nix and maybe those even not using Nix or those maybe on their journey as well. You know, one thing that sort of stood out to me is for anyone that has a unit test, in their their R package or their, you know, our repository and that unit test is is maybe running up programmatically or on some schedule or something like that, you should probably be aware that in the latest version of the tidy select package, if you have a dplyr select call and write your that the error message that's going to get returned if one of the columns in that select statement doesn't exist. It used to say can't subset columns that don't exist. Now it says can't select columns that don't exist. So if you have an expect error call in your unit test and you're looking specifically for, that keyword subset, that's not going to to fire anymore. So that test is actually gonna fail because it that that rejects those strings will not match essentially so you may need to go in and update your unit test and take a look at the unit test that you have across your different R packages and repositories to to make sure that you are not too going to get bit by this issue the same way that Bruno did, and it was really interesting to me as well, how, you know, the binaries I guess of the the the release before, I guess, the 1.2.0 release of Tidy Select, which is now, quote unquote, the old version, were the versions of Tidy Select getting installed, on Debian and Windows and and Mac, you know, for these crayon package checks, but it was compiling from source on fedora so that's you know there's there's all these these funky things that take place you know that we I think we see all the time that are huge head scratchers for when your your packages are going through these automated tests across all these different operating systems, when when they're trying to pass their crayon checks.
Right? They'll pass 9 of them and then the 10th one will fail. And it'll probably make you wanna throw your computer out the window half the time. But, you know, it just sometimes takes a little investigative work like like Bruno did or maybe, you know, diving into your your r four d s Slack community or your Mastodon community, and trying to figure out, collectively what's going on here. And hopefully, it didn't take Bruno too long to to figure that out. But, you know, as you you mentioned, I think, Nick's actually is going to allow him to easily, you know, handle these types of situations in the future, where his unit tests need to ensure that they're running against the latest versions of all packages or or maybe, you know, on some OS's, it'll be, you know, building the the latest binaries versus on other OS's, the latest, packages compiled from source.
So, you know, I think one avenue again to to try to do some of this stuff, you know, might be having all sorts of different docker images, to handle all these different edge cases and and use cases and operating systems. But it seems like Nix actually might be a more streamlined, and efficient workflow to be able to to make those switches a little bit quicker and run those tests, within different environments a little quicker to to spin up VMs or something like that or install, you know, all sorts of different versions of our locally and all sorts of different versions of our packages locally and and you know just sort of cross your fingers that, you know, that your package checks would succeed on other operating systems that you didn't really necessarily have any access to. So you know that's really interesting and then and then maybe the last thing I'll point out here that I thought was interesting and and useful you know one a lot of times when we're you know, running GitHub actions. Right? It's it's running on some piece of compute that we we don't have full access to. So it's we're relying really on a YAML file at the end of the day and maybe this goes back to who was it? Yaron Ooms that authored that blog post a couple weeks ago about like, you know, workflows in our Oh. And Oh. You know, that's not repeat yourself. Miles Macbain. Miles Macbain. Oh. Miles Macbain. That's exactly who it was. Yeah. Oh, my goodness. This sort of brings me back to that where you know eventually you get to try to just do everything with it a YAML file and it would drive you crazy but, we're at the mercy you know with GitHub actions actions, you know, for better or for worse a lot has been abstracted for us which is awesome but we're at the mercy of, a YAML file. Right? To be able to handle, you know, setting up that that piece of compute, that runner and GitHub actions, installing the dependencies on there.
And, you know, one thing I think that can be be tricky sometimes is is maybe authenticating it into different services that you wanna leverage. And that was my first thought here when I was taking a look at the this cache x, this cache utility here that allows you to to cache, different, packages, within sort of your next environment. But one of the interesting things is that you don't need to authenticate to cache x to simply pull binaries. All Bruno had to do was was really just these two lines of YAML specifying the cache x GitHub action version that he wants to use and then he has a particular name I assume you know he's logged into the cache x platform and and developed his own cache. That's that's b dash rodriguez, and that's where his cache lives, and that's all he has to specify in his GitHub action to be able to pull, binaries from that cache. So I think that's incredibly powerful, really nice that how simplified sort of this workflow is to be able to set up, your cache x cache, it within a GitHub Actions workflow. So fantastic blog post from start to finish. It really walks us through sort of the entire problems problem space and and how he was able to solve it.
And another feather in in Nick's cap, I would say.
[00:21:37] Eric Nantz:
Yep. I totally agree. And I'm, again, very much anything that can make your development life easier to be proactive on these issues happening, you've done that hard work of building those unit tests. You're doing what you need to do in terms of giving yourself some sanity, hopefully, as dependencies get updated. But, be able to put this in action first when you need it in an ad hoc way, be able to just pull this environment down within probably a matter of a minute versus, like, an hour like it would be by default. I mean, they they can't underscore the time savings you get from the caching mechanism, But also there is a lot to glean from these repositories that you mentioned, Mike, that Bruno and Philippe have set up for these GitHub Action workflows.
I I was in GitHub action nightmares, a couple weeks ago, debugging things. And I remember with a quartile compilation, I just I just I almost just threw my keyboard out the window. I just could not figure out what the bloody heck was happening. So, yeah, there is a danger sometimes of having the abstraction too high up versus what lower level it's doing. And the other piece of advice I'll give is that, you know, it may seem intimidating to be like, these these kind of actions are doing such magical things with these YAMLs. You know what's behind these actions most of the time? It's shell scripting. It's just doing stuff on Linux and then be able to troubleshoot that.
So, like, I went into the GitHub action source of some of those quartile actions, and I figured out, okay. So these kind of quartile commands with this Boolean check if, like, I have this render flag enabled or not. Then I realized, you know what? Okay. I can take matters in my own hands. I can do my own custom rendering. It's not as intimidating as it sounds. It's just the bugging can be a complete nightmare unless you know where to look. So I'm sure I'd imagine Bruno's had a few of those experiences too like all of us.
[00:23:29] Mike Thomas:
Definitely. And GitHub actions has its own sort of cache as well which That is true. Has bit me a couple times not to speak ill of GitHub actions because I do I do love it. But, yeah, it's it's caches everywhere.
[00:23:43] Eric Nantz:
Yep. Caches, unfortunately, is not the kind of cache I could buy things with. But, you know, nonetheless, it's all everywhere. Right? Speaking of major updates that we're seeing in the ecosystems these days in terms of the tooling we use, another one I've kept my very close eye on with a lot of influential projects I'm trying to bootstrap right now is we are happy to talk about a new release for WebR itself. When this blog post comes from the tidyverse blog and authored by the WebR architect and brilliant, engineer George Stagg, who is in this blog post getting us through, you know, or talking us through a few of these major updates that we see in the WebR ecosystem.
And I'm going to speak to a few of these. And I know some of these I'm going to be able to benefit one very quickly, I would imagine. But the first major of note is that now they are basing WebR on the latest stable release of R itself because in essence, they have to bootstrap R with a couple of the custom shims under the hood to make it seem like you're installing a package from a default repository where instead you're installing it from WebR's binary package repository. So they always have to, in essence, patch R to make all this work. And now they patch the latest stable version of R, which, of course, will be great for consistency with maybe your typical environment that you're building these analyses on. And another great feature that I think the users are going to definitely notice is some improved air reporting too.
Whereas in the past, you might see a custom, like, uncalled exemption if something crazy was happening in the WebR process with respect to maybe an error in the r code itself. Well, now you're gonna be able to see the actual error in the JavaScript console whenever WebR is running, which, of course, is going to help you immensely with the bugging to narrow down, oh, did I get the JavaScript code wrong that I'm using WebR with, or was it in my R code itself? So that, again, for usability, a massive improvement for the quality of life. And speaking of quality of life enhancements, ones that you'll they'll hopefully be able to see and interact with is big improvements to the graphics engine.
Because now the graphics that are drawn with WebRx, they call it the canvas function, they're gonna be captured in that R based session in a similar way so that it's consistent with other output types that you would see in a normal installation of R, which is leading to more streamlined, you know, interaction with these graphics. And, also, along those lines, graphics that you create in Base R have had massive improvements to the rendering engine. And the blog post, when you see this linked in our weekly, you'll see very sharp looking images that they're able to produce when you evaluate that code. Even as I'm talking now, I'm running through these snippets, and they look very nice. Great anti alias text.
The symbols with the r logo look really sharp. Everything looks as if you were in your native r session. Again, just massive amazing improvements under the hood to make this, you know, very seamless and attractive to the end user. And it doesn't just stop with graphic objects. There has been a lot of under the hood enhancements as well as some new user facing enhancements that the R objects that are created in these WebR processes are going to be more easily converted back and forth between their JavaScript counterparts and their R counterparts. Where does this fit in the big picture?
The big thing for me is the data frame and r that is literally the fundamental building block of pricing 99% of my analyses. Now, of course, in r, you have your columns and you got your rows. Right? That's not always what JavaScript treats data as, especially if you're familiar with d 3. It is definitely a different type of layout you often see where it's basically the column is given a name. It's like a named vector of things in a row wise type fashion layout. But there are functions now in WebR to go back and forth between these JavaScript notations and the R native kind of representations.
In fact, there's a handy function called 2d3, where you can simply take that data frame in the R process, put it into a format that you could feed in any of your custom d three visualizations. These things are massive for that interoperability between maybe using r to do the heavy lifting statistically. But if you're familiar with JavaScript and you wanna keep with those JavaScript visuals, have at it. Have your d three magic and be able to get that that construct of the data as you need it. So, again, great way for you to take maybe baby steps if you're new to R, but you're familiar with JavaScript, a way to get the best of both worlds. Really, really a big fan of that.
And then some really fun plumbing type enhancements here that I'm paying a lot of attention to is that with collaboration, you named dropped them earlier, Mike, your own ooms as well as, Utahn. They have new system libraries in the WebR process and as well as a custom WebR Docker container. Hey. Containers again for you. Which they've included some new numeric libraries as well as the ImageMagick image manipulation suite. And wait for it. There is now a Rust compiler configured so that if your R package involves Rust in some way, you're not gonna be able to compile that into web assembly 2. Absolutely amazing stuff.
And to really, you know, you know, intrigue you even further, embedded in the post is a Shiny Live powered web app from your own himself on using that magic package that he's created in the past. But now in the blog post where you can absolutely distort or make fun of this random cat image. And I'm literally doing it right now as I speak. It is so responsive so quick. I can't believe this is happening, Mike. This is just amazing.
[00:30:30] Mike Thomas:
It's as if the shiny apps running locally. It's insane. It's actually, like, faster. I mean, the the fact that you can put effects on this image to like negate it and you know you totally changing how it's visually represented is awesome. You can upload your own image which is what I've done. I uploaded an old hex logo and I'm just messing around with it right now, rotating it, blurring it, imploding it you know it's it's pretty cool it flipping it reversing it yeah It's it's it's awesome. I cannot believe how responsive it is.
[00:31:03] Eric Nantz:
Yeah. This has come such a long way. I mean, even it was maybe, what, 4 or 5 months ago that would take a good minute or 2 for these things at Boostramp, and here we are. We got this as if it was plugged into the blog post directly. Like, this is this is magical stuff. So I'm really, really intrigued by by where this is going. And, again, we're seeing more in the community leverage Rust. So I'm sure there's going to be a lot of grain enhancements with this. And speaking of packages themselves, there is now additional, refresh, if you will, on the packages in in the CRAN ecosystem that are now supported in WebR, that total is now bumped to 12,969 or about 63% of the available CRAN packages that are now supported natively in WebR.
And like I mentioned before, what George and other engineers have to do with this WebR binary cache of packages is they have to compile them in a special way so that they're supported by web assembly. So not everything is there yet, but that's a massive jump compared to where we've been even just like I said a few months ago to what is supported in webr. That is absolutely amazing.
[00:32:18] Mike Thomas:
Yes. I couldn't agree more, and this is just, you know, more exciting improvements. I think, you know, probably the biggest thing for me as a, you know, practitioner, somebody who who's very data, hands on in most of our projects as well as as you talked about, Eric. The ability to to switch back and forth, between JavaScript sort of data frame objects, you know, especially, I guess, particularly in this case, we're talking about raw objects of typed array array buffer and array buffer view those are the types of raw vector objects that may now be used to construct our objects and like you said you can go back from an our data frame to a Javascript object with the either 2 object function or if you want to go more the d3 route that would be the the 2 d three function in Javascript so that's exciting because to me that makes it feel you know much more our framework as well. It kinda feels a little, I've been watching a lot of the observable project and they have some some excellent, utilities, blog post documentation around how to sort of convert back and forth between either pandas data frames, our data frames, and you know the JavaScript data frames that really power the visuals, on that platform. So this sort of reminds me of that in terms of how easy it is to go back and forth between the 2, and I think that that ease of use is really going to go a long way towards helping people get up to speed and build tools, within the WebR framework. So very very excited.
Thanks to to all who work on this. There's a fantastic acknowledgment section at the bottom of this and and a lot of familiar names there of folks who are are working hard to continue to drive this this forward and, you know, especially thanks to to George Stagg for sort of spearheading all of this and putting the blog post together.
[00:34:15] Eric Nantz:
Yeah. And and and any package authors out there that are saying, hey. You know what? I know my package is not crayon. Can I do this a web assembly? Oh, yes. You can. They actually have a r WASM package to help you compile your own r package into WebAssembly and be able to manage a repository for that. And, yes, we were talking about GitHub actions earlier. Another, you know, nugget at the end here is that they have put links to their reusable GitHub Actions that you could get inspiration from or just leverage yourself so that your package is compiled.
And, yes, you can also, check out we talked about this before. The R Universe project is offering WebR binaries of packages on any of the packages that they host too. So there is not just that binary, repository that WebR is hosting themselves. You know, our universe is another great inspiration or a great source of this as well. So lots to choose from in this space.
[00:35:15] Mike Thomas:
Yes. Absolutely. Don't blink.
[00:35:25] Eric Nantz:
Don't blink. You might miss it. Just like how you might miss some very snazzy visuals that we're gonna talk about on our last highlight today. And as you know, Mike, you and I can probably sympathize, especially early on in maybe a data science journey or you're leveraging Are you hearing about things like the tidyverse, you know, suite of packages for the first time, and you're trying to get a handle on a lot of these operations that occur when you want to manipulate your data frames like adding new variables, doing transposing, you know, doing group summaries.
A lot of people, myself included, do like to have a nice visual to accompany maybe the text around just what those particular functions are doing. Well, we're happy to share that Andrew Hice has authored a latest blog post on visualizing many of the important dplyr functions with both, single group as well as multiple group processing. And not just having static pictures, folks, he has handcrafted some absolutely amazing animations to go with this. I can I can imagine he is making heavy use of this in his statistics, lectures and his coursework?
But, yeah, of course, we're we're in an audio podcast talking about visuals here, but boy oh boy, you look at these and how he made them, first off, is that he tried to leverage what Garrigade and Bowie, from has built with his custom visuals in the tidy explain package, but he was running into a couple limitations. I'll be especially around the group processing. So Andrew is showing his, graphical editing shops here, has built custom Adobe Illustrator powered visuals and after effects. But guess what? He's actually shared the the files that if you have the software, you go import this in and try it yourself.
I I'm not an Adobe customer, so I can't exactly run this myself. But, hey, it's there if you have that same software. But throughout the blog posts, he's got not just the narrative of what a function does such as mutate. You can simply hit play in the blog post and then see literally the transformation of that data with this nice transition kind of layout from left to right with new variables or new records being colored the same as the new code snippet that's being shown on the right side. It is very easy to digest. It does as a mutate with summarize, and then where it really starts to shine is the grouping visuals. Or now, if you're grouping by a categorical variable, he's able to separate these blocks out logically and then really show the impact of that operation and then be able to ungroup that at the end to get that original setback or things like that. And also custom mutations within groups. So he's got the code snippets alongside the visuals. Again, really great to digest visually what is happening here. And, boy, I wish I'd had this when I was learning the manipulation in the old days. But, of course, in my day, not to be that guy saying get off my lawn, we didn't have Dplyr back then. We had Plyr midway through my hour journey, and that did not have nearly the resources that dplyr has both under the hood as well as in educational materials.
But, again, the visuals really do a terrific job of really isolating the key incremental steps in these operations, which I think you can see it in a pipeline operation just with the text. But seeing that visual paired with it, you really start to see what is the impact of each of those statements. So there is a whole lot to digest here. We definitely invite you to check out the post because our ramblings can only do us so much justice, But, kudos kudos to Andrew for handcrafting all this from the ground up. It is truly amazing stuff.
[00:39:28] Mike Thomas:
Yes. This is fantastic. You know, I think I know Andrew is a professor, and this is just go I wish I had him as a professor because this I know. Is just going to go, such a long way towards building his his students understanding of, you know, especially, you know, I think I think mutate, isn't isn't too difficult to wrap your head around. It's a little straightforward, but once you start getting into grouping by aggregation, summarization, doing a mutate on a grouped data frame, joins, things like that, It it, you know, takes it to an additional level of, you know, abstraction that can be difficult to wrap your head around when you're when you're a beginner.
And back in my day, Eric, it was, Excel pivot tables. That's how I first got my my start in, you know, understanding some of these concepts and then I had to bring it over, to the our side and I was like, wow. Hey, you know, this is a, maybe a hot take a little bit but what has a better expressive syntax to tell you exactly what it's doing, than dplyr and the tidyverse. I don't think there's anything else out there. Sure surely a whole lot better than Excel. I I can at least tell you that much in in terms of just being able to to look at the code, you know, I think SQL is probably a close second, but to be able to look at the code and understand sort of exactly what's going on and, you know, these examples applied to data, I think are fantastic. These these visuals go such a long way towards building that understanding as well because you can he's really representing sort of the the action taking place here, whether it be grouping, summarization, or a mutate.
So, yeah. Hats off to him. I would say that that his work doing this, he may not realize just how impactful this might be on his students or, you know, folks learning r who stumble across this blog post. So if you if you know someone, who's who's trying to learn r having a tough time, you know, first point them to the Tidyverse. That would be my recommendation to wrap their head around dang data wrangling, but I think this is going to be a fantastic blog post to to point people to as well, to help them get up to speed, to help them sort of get over the hump, right, in building their understanding of data manipulation in R. So I I really just can't understate, you know, I've said it a few times now, but I can't understate sort of the importance of this and, how useful I think this type of visual instruction can be.
[00:42:03] Eric Nantz:
And another thing I wanna say is critically important, especially in this new age of, I don't know how new it is per se, but really someone I've been gleaming in the community of really openly sharing our our wins and our key learnings to educate ourselves and others is that you may be wondering, oh, wow, Andrew. You did such amazing work with this. I wish I could use this in my materials. Guess what? You can, folks. These are all Creative Commons license, which means he's got links to, like, the finished products, both the video form and animated GIFs and static images of all this. So if you wanna leverage this in your materials, have at it. Right? I mean, that is a huge service that Andrew has done here. He could have easily kept this under his own, like, private coursework, you know, materials, but he's sharing it with all of us. So I think that is a massive win for all of us kind of in this educational space. So even our organization is trying to help teach others that are new to R how some of these operations work.
You better believe I'll be, drawing upon some of this when I get questions about how some of these, you know, group processing and deep wire works and the like. It's just amazing amazing work, Andrew, and even more amazing that you are so willing to share this with everybody. It's a new it's a new age, I would say.
[00:43:29] Mike Thomas:
And has the time to author all of this content out there. I don't know how he does it, but thank you so so much.
[00:43:35] Eric Nantz:
Yeah. I I whatever you're you're, either ingesting or whatever life hack you've done, please pass it our ways because we we would love to have it. I respect the It's gotta be those damn cold tubs. I still gotta do that. Yeah. Yeah. I think we're late on that, aren't we? But, you know, what you're not late on is that if you boot up our week without org, you're never going to be late and seeing the latest and greatest from the R community showcased by the R community. Great new packages, new announcements, and new blog posts, much like what we talked about here. And we'll take a couple of minutes to share some of our additional fines from the issue. And for me, it's a plug, especially for those in the health and medical industries.
The Our Medicine Conference is back for another year, and they have just opened up their their open call for talks. And that conference is taking place on June 10th or 14th this year. And on top of having the call for abstracts and and talks open, they've announced that they have keynotes lined up from Stephanie Hicks and Gunilla Bosch, talking about some really innovative work in medical research and genomic analysis. Always stuff that I resonate with, especially in the early part of my career where r was immensely helpful as I was doing a lot of genetic the to the post from the Arkansas Museum of all the details. And it's always been a really top notch and well run conference. It's been a great kind of companion in arms, so to speak, with our pharma conference that I'm a part of. But, yeah, they all are very complementary of each other and really great to see these resources shared in the community.
Mike, what did you find?
[00:45:27] Mike Thomas:
No. That's awesome, Eric. I found a fantastic blog post, I think, authored by, Hannah Frick, who's a member of the Tidymodels team at Posit, and she's been instrumental in incorporating survival analysis into the tidy models ecosystem. So there is now support for survival analysis for time to event data across tidy models, which is is really really fantastic and exciting for those of us, which, I know you as much in life sciences as, believe it or not, me, in financial services and and credit risk, use these time to event survival analysis types of models because, they handle, you know, leveraging longitudinal data.
They, you know, have a good setup to be able to introduce hierarchical models as well, with mixed effects models or or Bayesian type models that, you know, are and these these longitudinal, types of data sets, as well as these hierarchical types of data sets, we see them all the time. I mean, that that those things are present in a lot of the data sets that we work with in a way that machine learning just can't necessarily handle. Right? So survival analysis is really a great tool to be able to use in those particular use cases.
There's a fantastic amount of links in here. There's also an additional blog post that walks through a very hands on, data use case, a a case study here called how long until building complaints are dispositioned. That's now on the Tidymodels website. It's it's linked at the very bottom of this blog post, and that's, sort of how I I came across this Our Weekly Highlight as well, because I saw that one, I think, come across Mastodon. And it's just a great, great walk through and and use case of all the different functionality that we now have around survival modeling, within the Tidymodels framework. So super excited about this. Thanks to all the folks that worked on this, and thanks to to Hannah for putting this blog post together.
[00:47:31] Eric Nantz:
Yeah. I'm diving in. I'm gonna dive into this case study after this because, I'm starting to get back into the time to event mode now with some custom analysis and clinical operations. And this could be a very nice way to benchmark newer models and take what I've been learning over the years of tiny models and apply it directly to time the event. It has been requested for a long time, and it is gratifying to see the tiny models team has taken this head on, and now we've got a boatload of additional capabilities to choose from. So, yeah, kudos to everybody on the team for that.
[00:48:06] Mike Thomas:
Yeah. No trivial effort, I'm sure, because survival analysis modeling has a lot of different nuances for machine learning, but you can still borrow a lot of practices, you know, that we might traditionally associate with machine learning, like, hyperparameter tuning and things like that, and and leverage those within survival analysis workflow. So, it was no trivial effort, I'm sure, but extremely powerful, when brought together. And I'm very grateful for the fact that they have.
[00:48:35] Eric Nantz:
Yes. Absolutely. And I'm also grateful for hey. Hey. Our weekly even existing. So we can see this on a weekly basis and be able to talk to all of you about it. But it is, like I mentioned, powered by the community, and we always are appreciative of all of your help. And the best way to contribute to our weekly is send us a poll request with that awesome new blog post, that great new package you discovered, that great new resource that you think deserves the attention of the community. Is just a poll request away at the top right corner of r o k dot org. You'll see the frame little Octocad image there. Just click on that, and you got yourself a pull request template right there. It's all marked down all the time. I live in markdown. I live and breathe markdown now. I wish I could write my emails in markdown and have them render in real time, but that thing happened in Microsoft Outlook anytime soon. But I digress. At least, so every week, it does. So you can have that at your at your at your fingertips.
And as well as we love hearing from all of you in the audience as well, you got a few ways to get in touch with us. Got a handy little contact page linked in this episode show notes and as well as you can send us a friendly little boost along the way if you're on those awesome modern podcast apps like Podverse, Fountain, Cast O Matic, CurioCaster. I could go on and on. They're all linked in the show notes if you wanna get a nice selection of all that. And, yeah, this is now gonna be the 2nd episode. Our new podcast host, and everything is yours truly botching his end of the recording. Let's hope that this one goes more smoothly this time around. Did some testing before this, fingers crossed. It'll sound as clear as we've always been, but, we are on a new host. So if you have any trouble finding the show, we have updated all the links at rweekly to our new podcast landing page, so it should be a seamless transition.
But as always, don't hesitate to get in touch with me if you have any difficulties. And the best way to do that, you can find me on Mastodon these days. I am at our podcast at podcast index on social. I'm also on LinkedIn, with show announcements and the like. And on that Twitter x thingy jingy at DR cast. And, Mike, where can the listeners find you?
[00:50:41] Mike Thomas:
Sure. You can find me on mastodon don@mike_thomas@fossedon, dot org, or you can find me on LinkedIn by searching Ketchbrook Analytics, k e t c h b r o o k, and see what I'm up to lately.
[00:50:57] Eric Nantz:
Awesome stuff. And, yep. We we were on the other side of that major eclipse event, but the the community train never stops over the our ecosystem. And as always, we thank you so much for listening to us wherever you are around the world, and we will be back with another edition of our weekly highlights next week.

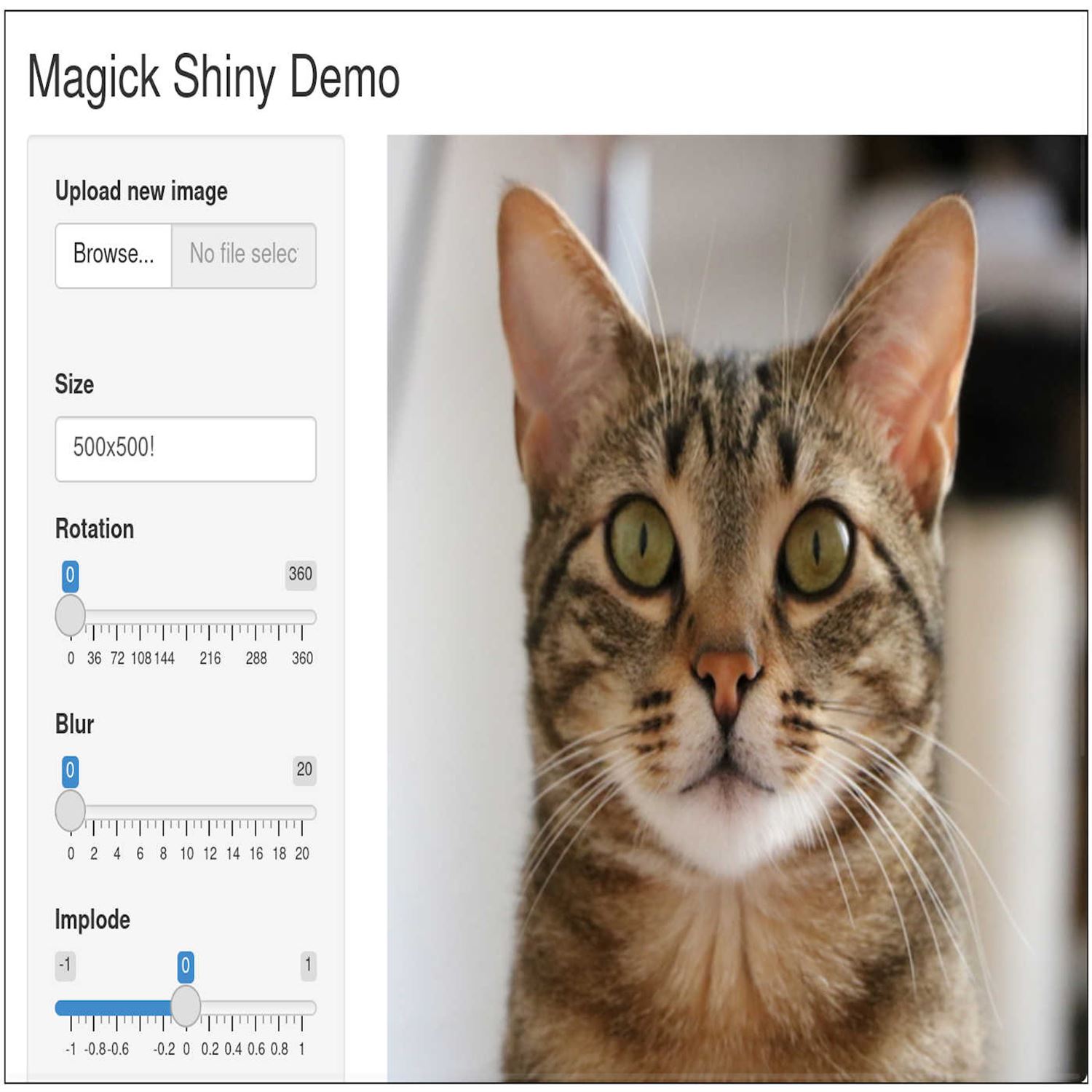

Additional Finds
Episode Wrapup
