A monumental achievement for bringing the Nix package manager to reproducible data science, travelling deep through the in-place modification rabbit hole across multiple languages, and a sampling of sage advice from the Data Science Hangout.
Episode Links
Episode Links
- This week's curator: Tony Elhabr - @tonyelhabr@skrimmage.com (Mastodon) & @TonyElHabr (X/Twitter)
- Reproducible data science with Nix, part 13 -- {rix} is on CRAN!
- In-Place Modifications
- Data Career Insights: Lessons from four senior leaders in the data space
- Entire issue available at rweekly.org/2024-W40
- rix rOpenSci review: https://github.com/ropensci/software-review/issues/625
- Determinate Systems Zero to Nix guide https://zero-to-nix.com/
- vec - A new vector class with added functionality https://jonocarroll.github.io/vec/
- rray - Simple arrays https://rray.r-lib.org/
- Libby Heeren's podcast Data Humans https://libbyheeren.com/podcast.html or https://datahumans.libsyn.com/site
- A Bayesian Plackett-Luce model in Stan applied to pinball championship data https://sumsar.net/blog/bayesian-plackett-luce-model-pinball-competition/
- Cover and modify, some tips for R package development https://masalmon.eu/2024/09/24/cover-modify-r-packages/
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @rpodcast@podcastindex.social (Mastodon) and @theRcast (X/Twitter)
- Mike Thomas: @mikethomas@fosstodon.org (Mastodon) and @mikeketchbrook (X/Twitter)
- Torvus Clockwork - Metroid Prime 2: Echoes - DarkeSword - https://ocremix.org/remix/OCR01507
- Home is Where You Belong - Final Fantasy IX - Reuben Spears, Earth Kid - https://ocremix.org/remix/OCR04135
[00:00:03]
Eric Nantz:
Hello, friends. We're back with episode a 181 of the Our Weekly Highlights podcast. If you're new to the show, this is the weekly podcast where we talk about the latest happenings that we see in our highlights and additional resources every single week at rweekly.org, your weekly curated content for all things news and other awesome events in the art community. My name is Eric Nantz, and I'm delighted you join us wherever you are around the world. And joining me as always, it seems like October is already here. Where did the time go, my friend? But join my my awesome co host, Mike Thomas. Mike, yeah, where did the time go? I can't believe it. Can't believe it either. The 2024 is almost wrapping up,
[00:00:44] Mike Thomas:
coming to a close here, but we're gonna try to enjoy what we have left of it. I'm looking forward to 2025 coming soon.
[00:00:52] Eric Nantz:
Absolutely. So many of us are probably in the midst of these year end activity wrap ups, getting releases out the door, getting other things documented. I'm definitely in that in that mode right now, but this is always the the highlight of my day, no pun intended, for what we do here today. So I'm happy to, record this awesome episode with you as always, Mike. And our issue this week has been curated by Tony Elharbar, who didn't have a a big break between his last curation, but he's helping with our he's kinda scheduling switches here and there. But if you're not familiar with the our weekly effort, we have a rotating list of curators that step in every single week so we kinda spread the spread the work around, but it's all community effort driven. But as always, yeah, tremendous help from our fellow ROCE team members and contributors like you all around the world with your poll requests and other suggestions.
As I saw the the highlights come through in our little voting at the end of the weekend, it was very obvious to me what I was gonna lead off with on this episode because I am delighted, super excited to share the news that an effort that we have been covering on this show, whether in the highlights section or in our additional finds for over a year, has officially hit CRAN, and we are talking about the ricks package authored by Bruno Rodriguez to help facilitate the use of the NICS package manager for reproducible data science workflows entirely in r.
I am, again, super excited and huge congratulations to Bruno on getting this release out. It is absolutely monumental to see this happen. And as he alludes to in the blog post, and we'll have Wing 2 as always, there has been over 15 months of rigs being in development, over 1300 commits, a 143 closed issues, 175 closed poll requests, and not only that not only is ricks on CRAN itself as of earlier last week, It is also under the rOpenSci umbrella. Another major achievement. And frankly, when you think about it, it makes total sense. We are talking about a huge, huge boost in making reproducible data science workflows. And rOpenSci is one of its biggest core principles is the idea of reproducible data science. So it does seem like a match made in heaven to me, so I'm very excited to see where this goes.
And as a result of being under the Arkansas umbrella, one of the ways that a package or an effort gets onboarded is a very robust and a very transparent peer review process to get the package into our OpenSci, which we can actually look at in real time, but also I have the link to in the show notes the very, poll request or the issue with all of the review feedback and all the review steps that Bruno has done to to address feedback. It's all there, all transparent. It was a very looks like a relatively smooth process. Lots of great documentation there. It's another showcase just how robust the opens side, effort is for getting high quality software under their umbrella.
So with those, notes out of the way, you may be new to this effort and wondering just what the heck Nix actually is. We're not talking about Linux. We're not talking about Unix. We're talking about Nix, and Nix is a package manager under the hood, not too dissimilar to what some Linux distributions do for distributing software in their respective systems. Distributions such as Ubuntu and Debian use the apt package manager. Red Hat, Fedora use an RPM based distribution system. Arch is definitely the host not for the faint of heart, has their own custom repository. Nix, however, you don't have to use Nix on Linux. You can actually use it on macOS as well as Windows itself, thanks to WSL or the Windows subsystem for Linux.
So no matter which OS you're on, chances are you could get Nix up and running. And one of the ways that we recommend, I know Bruno recommends this as well, to get started with Nix in a very smooth way is using what's called the determinant systems installer of Nix. That's a vendor that's trying to bring Nix, to a first class way to enterprises and in open source and the like. And I have I have a good friend on on that team named Martin Wimpress, who is helping a lot of their documentation and and other advocacy. So getting getting NICS on your system, I highly recommend checking out the determinant NICS installer.
We're also gonna have linked in the show notes a guide called 02 NICS. If you wanna get more familiar with what's happening with Nix and trying out a few different ways in your set of development environments. But as an R user, Rix is going to handle a lot of this integration with Nix for you in the sense that you can bootstrap the necessary manifest files to tell the Nix package manager not only in the version of r to install in this isolated development environment, but pull down the packages based on a snapshot in time. In total, Nix has over 80,000 packages across the entire spectrum of software, and R is a first class citizen in Nix along with other languages like Python and Julia and many others.
So what Rakes is gonna do is help you, you know, bootstrap these environments and then to be able to say on my host machine, which may or may not even have R installed, you can have this, again, self contained development environment ready to go, reproducible. You could commit these files that are generated, which are called default dot nix, as well as a dot R profile file that's going to help the R session specifics. That could be on your GitHub repo. And if you have a collaborator that's also running next, they can pull down that exact same environment. That is huge. And if that doesn't sound familiar, you might say that does sound kind of similar to what Docker would give you and sounds similar to what RM would do from a package management perspective.
You're not wrong. They're they are somewhat similar in that sense of the overall goal, but the way they achieve it is a bit different. Docker is a core space and container technology, and that can be a heavy footprint depending on your perspective. But it also, admittedly, has a lot more mindshare in most of the dev ops sector and even in in sectors of data science with things like the rocker project that we speak highly about. So Nix may not always be right for your use case, but I am very intrigued by the promise it brings you. And full disclosure, I've been using Nix on a brand new server I have here in this basement a few feet behind me, which has been a great learning experience in and of itself to have more reproducible software stack for my infrastructure.
But I have been putting Nix through a couple tests in my open source work. And what's even more intriguing is that on top of the R environment that I can bootstrap for Rix, I can also easily add in other utilities such as a custom instance of what's called vscodium to have its own IDE in that same environment and bring it up as a GUI and have it ready to go. It's completely segregated from the rest of my host system, but I can tailor it to my liking. I could put extensions in there. I can have a pretty neat experience with r on Nix in a custom IDE to boot. Like, the possibilities are almost endless with this, and that's why I'm still I'm still learning the ropes on this, quite a bit.
I will say I haven't had a perfect experience of it just yet. There was an instance, which if you're using R on a Linux system, you're probably all too accustomed to this, where I was installing a package, I believe it was called rag or something like that, where it needed an image library development libraries to help compile. And for whatever reason, when Rix was bootstrapping this, this development environment, it didn't pick up that I needed that extra library. So I had to manually add that in. So there's gonna be, I think, some cases that are still still getting worked out, but the the future is certainly bright here.
My other picky wish that I know has been mentioned in the Rick's issue tracker, for those of us that are coming from an RM mindset where we have projects that have an RM lock file, Oh my goodness. I sure would be nice to import that directly into Rix and then magically get the package installation. There's a lot of engineering required to do that. So I'm not surprised that it hasn't landed in just yet. But I am I am getting a bit more, you know, to say I I want this feature more and more because I have I I I'm I'm not I'm not gonna exaggerate here, Mike.
I probably have in my day job over 90 projects that use RM in some way. And if I wanna convert all those to Nicks, that's a lot of manual Mhmm. Manual effort to do. So having some kind of automated way to take a lock file, magically, you know, transform that into the necessary default dot nix and getting the right package hashes, that would be massive. I have seen Python having these custom utilities that tie that poetry framework for their package management with nix. I think they call it poetry to nix, where they can somehow do this magical inference of a poetry lock file, which looks a lot similar to an rmlock file, if you're familiar with that. And they can somehow parse out then from the next package manager which Python packages to install and what hashes that correspond to that particular version.
So I have been spoiled by seeing that on, like, the Python ecosystem. I believe they have a similar thing for Rust, maybe for Julia as well. So maybe it's a matter of time. I don't know. But once that comes in, yeah, that's gonna really ease the onboarding even further for those that are coming from a different framework such as RF to Rix. But nonetheless, I don't want that to discount my huge excitement for this. I think it's a huge step to seeing Nix really taking a a solid footing in in the realm of reproducible data science. And also in the post that we're gonna link to, Bruno has a short little 5 minute tutorial video. They get you up and running with Rick's quite quickly.
But we invite you to check out the rest of his blog because there are literally about 14 or 13 of these other posts that chronicle this entire journey, which you can tell is interspersed with his learning journey of Nick's along the way. It's great to kinda see that evolution happen, and it's all been open, so to speak, for us to watch. So, yes, am I excited? Oh, heck yes. I am because the the future does look pretty bright here. I'm interested to see whatever's in the art community do with next. I've had some brief conversation with George Stagg about it. He's intrigued by the possibilities as well.
[00:12:46] Mike Thomas:
But, yeah, the future's looking pretty bright. So I'll be honest with you, Eric. Before the Rix package came out, Nix was sort of intimidating to me. I had built up a lot of, you know, personal education around Docker, and containerized environments. And when Nix came along, I don't know, it just felt like too big for me to, you know, wrap my brain around at the time. I've switched since then because this Rix package makes me feel, and the 5 minute tutorial video that Bruno has put together, showcasing, you know, how to get up and running with this package, makes me feel like it's so much more accessible.
And I think that sort of the our functions, which I think there's only 6 or 7 in this package right now that help you get up and running, with a Nix environment for your art project. Take care of a lot of the things that may have intimidated me in the first place about Nix, and and sort of make it much easier to to get started with. And if you watch this 5 minute video, you you start to realize that maybe it's not maybe it's not all that intimidating, after all. And I think, you know, one of the potential benefits, as you alluded to, Eric, of having Nix as compared to maybe the Docker and and our end environments is that your Docker images that you create can get fairly heavy fairly quickly.
And I think that there may be use cases out there where Nix would do the same thing, but the end product would be a lot more lightweight. That end environment might be a lot more lightweight. And that might be really important, depending on the the type of project that you're working on, depending on where you're trying to deploy to, you know, on the edge or something like that, a a system that doesn't have a lot of space to store, you know, large Docker images. So I I I'm really intrigued by the next project. I think this Rix package makes it a lot more accessible. I think the, fact that this package is now part of the rOpenSci project says a lot about the amount of work that Bruno and the others who've contributed to this package have put into it, and its potential importance in data science as a whole. So, very excited to see it hit crayon, and very excited to to start playing around with it because right now, at this point, there's there's no excuse. I think Bruno has done all of the work to make this as easy as possible to get started with for our developers like us.
[00:15:23] Eric Nantz:
Yeah. And and and speaking of the ways of making it easier, when you look at what the Rick's package offers you, there are 2 other additional nuggets that even go above and beyond, in my opinion. One of which is being able to leverage an another service out there for next package binary is called cachex to be able to help build an an environment and have it cached there on their infrastructure. That way when somebody pulls it down, is not having to recompile a package of some source. It'll get binary versions of the packages and other dependencies of that particular project, which, again, if you're familiar of running R on Linux, you love having at your disposal binary installations because that cuts the installation time from sometimes hours to minutes, if not seconds. So you you'll definitely wanna you'll appreciate that when you find yourself in those situations.
But he's also put this additional nugget here. Bruno has also been one of the bigger proponents of the targets package by my good friend, Will Landau. And there is a function in here called TAR nix GA, which will help you run a Targus pipeline, bootstrap by nix on GitHub actions. Oh my goodness. Like, that's almost sensory overload of all the integrations there. But what a great fit for having an automated data science pipeline, but then next having the full control on your installation of your dependencies. That that's massive. I I I can't wait to play with that myself. Yeah. No. It's incredible, and I think that
[00:16:59] Mike Thomas:
Bruno has focused on those types of applications where I think Nix can be the most powerful, you know, in terms of GitHub's actions. We have functions here that are wrappers, as you said, around, you know, building an environment on GitHub actions and making sure that, you know, after it's run the first time, everything is cached on that cache server, so it's gonna run a lot faster. The second time sort of makes me, think of, you know, Docker Hub. Maybe you could sort of, equate cachex to that, but I think there's some differences there. But I think the idea is is fairly the same. Right?
So, yeah, I I I think just the applicability and the the usefulness and new utility that Bruno has built in to, sort of the concepts behind this package are are pretty incredible.
[00:17:47] Eric Nantz:
Yeah. So I invite you to not only go to his post, but also the Rick's package site. Again, very well documented. There are a lot of vignettes, and they're ordered in a logical way to kinda start when you're brand new to Rix up until some of the very advanced use cases. So the the website looks absolutely fantastic. Again, a great fit for our OpenSci in general. So, again, it's always a team effort when these packages come up. So I wanna make sure I give kudos not just to Bruno, but also Philip Bowman, who is one of the coauthors of the package. I've seen their their work on the GitHub repo. There's been a lot of commits, as I mentioned earlier. And, this is only the beginning. Like, I can see lots of improvements coming along to Rick's end, especially as adoption grows.
Heck, I I if I get more time, I wanna help contribute to this r and piece of it. Because, again, that is somewhat scratching my own niche, but I can't be the only one that wants to transfer some legacy projects that maybe to to have a more robust workflow with Nix, down the road. So we'll be watching this quite closely. And one other mind blowing thing that, again, when you have the next package that kind of blew me away when I first did this is that with Rix itself, if you want to get one of these files, you know, boostramp or the set of files boostramp for a particular project, you don't even need R on your host system to even get Rix running at first. Because with the next package manager, you can have a special command that basically shells out to compo to grabbing the the the R environment that Bruno has baked into the the package on GitHub and then pull that down interactively in what I call an interactive shell.
You can then run RICs on that directory and get the the necessary files in that temporary environment and then exit out. I guess it's similar to what Docker gives you, but it's still it just can't I can't believe that's even possible. So on this new laptop that I just got, I don't have r on it. It's all RICs. RICs or Docker. There's no r trace of it because each of the project has its own environment, and I didn't even need r to get RICs up and running. That how what magic time are we in, Mike? I just can't believe it. Gotta love it. Well, we're going to exercise a little bit different part of our brain on this next highlight, Mike. We got a fun little programming adventure for one of our fellow rweekly curators this week. And this blog post, this highlight, has been authored by Jonathan Caroll, and he is continually pushing the envelope and trying to solve what seems like almost all the programming problems that he can come across over the next year or so that he's been doing this series.
And he comes to us this week to talk about in place modifications in R and other languages. And this all stemmed from a recent post or a video that he saw based on a problem, which in a nutshell involved having an array of of integers, and then you define some integer k and then another integer he's calling multiplier, where the task is you've got k operations to perform on this vector of numbers. And in each of these operations or iterations, you've got to find the minimum value of this vector. And, of course, if there are multiple, you know, ties in this, you just take whatever appears first. Then you replace that number you found with that number times the multiplier, and then rinse and repeat until you've exhaustively gone through all these k iterations.
So when the video he saw that there was a pretty elegant way in Python to do this, And in particular, this Python solution is taking advantage of what it has built in a compound assignment type operator, the star equal to that to that result. That is, again, calling it an in place modification. Well, r itself doesn't quite have that built in operator. He does have a solution, but that solution is technically speaking making a copy of that updated number every time. You can inspect this when you look at the memory kind of hash of an object in r, and you would see that after that operation, which looks like it's in place overriding. No. It's not. It's actually making a copy of that object updated copy of it.
And this is another case wherein in John's r solution, he has to use a for loop. He's not able to use the map function because the iterations actually depend on what happened before it. So Markov chain. Markov chain. Oh, give me flashbacks to grad school, my friend. That's, that's some frightening stuff. But, yes, Markov chain's for the win here. So as he's going through this, he realizes that the closest thing that he's seen in the R ecosystem to this in place modifier is is from the Magritter package. If you've used this before, it's the percent sign, less than sign, greater than sign, and another percent sign.
I just short aside here, this operator has given me fits for debugging, so I stopped using it many years ago. Did you have those same issues as well? I've heard the same. Yeah. In stories. Never used it.
[00:23:31] Mike Thomas:
It scared me just just visually to look at, but I had heard similar things.
[00:23:38] Eric Nantz:
Yeah. I I lost, I lost a few hours one time. I was trying to be too cute with a deep fire pipeline, and I I wrecked havoc on myself. And I was like, nope. Not gonna do that again. None nonetheless, as, John's exploring, what possible ways could he kind of replicate this in place modifier in r itself? Because his motivation is, yeah, when you have a small variable name, it's kinda easy to take a reference that variable that's probably as a vector or some numbers. And then in the square brackets, call a function on that vector to grab the right element, but then reassign that a new value.
He says them says in this, well, what if that variable name is long? We don't have to keep typing that over and over again. Is there a more convenient way to do this? Turns out not really easily unless you take some, rather risky shortcuts, and that's where I'm kind of gutting to this meat of of the solution here. Again, this is giving me flashbacks to some bad practices I did in my earlier days where you're looking at the parent environment of the function, you know, that's being called in and then using a combination of the assign operator and then the deparse substitute for that variable and injecting into a basically a copy of that, a hidden copy of it.
Oh, you tell about the bugging nightmares. A lot of times in my early days, I would either get code from my old projects or a collaborator that did this, and it was so difficult to make heads or tails on what was happening there. But that is kind of the closest John was able to achieve with this solution, but he acknowledges he would not really wanna do that in production, that kind of solution. So he started to look at other languages and what they offer. And sure enough, in the Julia language, there are ways to have this in place operator with a slightly different syntax that or they call mutating, where they give the name of a function but then an explanation point afterwards and feeding in the name of the object that you want to modify in place.
And sure enough, he shows her this example of, like, reversing the order of numbers that you can, in Julia, get that in place modification of a simple vector without having to call the name more than once. So that that's pretty slick that Julia has that. And he experimented with that a little bit more, started to look at, you know, how could he do more elegant solutions to this, kind of do a little hacking around it. And so he's got at the end of the post a little modified version of this as based on, like, vector operations. He's calls that set underscore if. And sure enough, it kind of does the job.
But he's wondering if he could avoid if he can make that even easier and if maybe there's an r solution after all. So another update at the end of this post. Turns out John did end up writing a solution to this in r after all. He's got a package called Vec. It's available on GitHub. I'll link to it in the show notes with some of these features kind of baked in. And he said that there are some suggestions already from members of the community that in the base of what Vec is going to do is give you a new vector class that is gonna help with some of these in place modifying another optimized operations of vectors. So, again, great to see this. I haven't actually seen this yet.
And then yeah. So it was a great a great exploration into what's possible with these in place operators and gotten the learning journey of seeing r not quite having enough. And then in the end, like anything, you don't know if it you don't see any something there? Write a package for it. So fun journey nonetheless and a good little brain teaser once again that enters the highlights here.
[00:27:52] Mike Thomas:
Yeah. Absolutely. It was fun to, I guess, just see how a a leak code problem, could be, you know, as Jonathan, I feel like often does, push to its limits in a lot of different ways and then turned into an r package that potentially may have some practical applications for folks looking to to do this type of, you know, in place replacement, if you will, without consuming, more memory than necessary, you know, as we have typically had to do in r. And this new Vec package that he's created is is pretty interesting right now. It looks like it's fairly early on in its life. There are a couple of issues out there, looking for folks to help implement, some generics for, these these Vec objects, which are this new class of of vectors that hopefully will be able to to do some of the things that John mentions in the in the blog post, but have a lot more extensibility than what we get out of the box in in base r with, vectors. So that's pretty interesting as well.
It looks like in the GitHub issues, there's some discussions around this concept of of broadcasting, which wasn't a term, I believe, that I I saw in the the blog post, but, I think it intersects with maybe some work that Davis Phan has done as well on a an R package called R Ray, which I'm taking a look at at now. So it'd be I guess, this is all, you know, pretty interesting stuff as we're we're fairly in the weeds here as Jonathan often does in terms of taking a look at at really the internals of r, and I I really love the comparisons to Python and and Julia, and and taking a look at, you know, what's available over there and bringing it potentially into the r ecosystem. I feel like that's a concept that we see more and more of nowadays.
I've seen a lot of conversation lately about the the polars package in Python and and its potential, inspiration from the tidyverse. Right? So we have, I feel like, a lot of cross pollination going on to try to build the best products possible and and take a look at, you know, what are the best concepts across all programming languages, such that when we do create something new, we're trying to to create the best version of it. So very interesting blog post, by John. Cool thing about open source is that we can, you know, develop something that that somebody else can use pretty quickly here when we come up with an idea. So I highly recommend checking out the vecvecpackage if, this is a topic that is of interest to you.
[00:30:29] Eric Nantz:
Absolutely. We got that linked in the show notes as well. And, certainly, if not only is John's, you know, post insightful about his current take on these solutions, There's always, like, I wanna call history lesson per se, but he was venturing into some of the ideas of other programming languages. Some of them definitely have a a long history, you might say. Even this language that he references called APL, which at first I thought was a license abbreviation, but, no, that literally stands for a programming language, which has a book itself dedicated to it. So he's he's I love the way he intersperses kind of the lessons he's learned from these programming, you know, brain teasers, these exercises, but seeing the mindset across whatever languages are doing. So, certainly, if you wanna sharpen your dev toolbox, John's blog is a is a great place to go.
And rounding out, we're gonna get a bit, you know, back to the practical side of data science in our last highlight here because we have a very great showcase of some of the valuable insights that we've seen from recent sessions of the data science hangout, which is, hosted by Rachel Dempsey. And as of recently, her new co host is also the author of our last highlight today, Libby Heron, who has just joined POSIT as a contractor for helping with the data science hangout and also POSIT Academy. She authors this terrific post on the POSIT blog called Data Career Insights: Lessons from 4 Senior Leaders in the Data Space.
So we're gonna walk through 4 of these examples here in our in our roundup here. But first, I just want to mention that hangout is a great place, a great venue for those that are looking at learning from others in the community on their data science journey. If you're not familiar with the effort, there is what we call a featured leader or featured, you know, maybe co leaders that Rachel talks with and Libby talks of as well in the session, but it's a welcoming environment. Anyone at all are welcome to join no matter which industry, no matter which spectrum of data science you fall under. I had the pleasure of being on that about a year or so ago. It was it was a a a great time.
We've we've learned a lot even just through the questions that we would get from the audience, and the chat is always on fire, as I say, whenever whenever those sessions are on. There's lots of awesome insights on there. So she has links to all that in the blog post that we're mentioning here, but we're gonna give our take on some of the lessons that are highlighted in this post here. So the first, insight here is focusing on learning how things work and not being afraid of this feeling that you should already know how things work. I boy, does this resonate a lot? So this came from a conversation with Jamie Warner who is a managing director at Plymouth Rock Assurance, where she was talking about, yeah, you may have heard some advice before, but in the data science world, but there may be a legacy process, a legacy model that some it may be explained to you, but then there may be other situations where you may not know exactly how something works.
But when you are insight you're inquisitive, I should say, and you talk to a subject matter expert about, you know, what what is the mechanics behind this, getting around their thought process, Yeah. That is amazingly helpful. People end up being a wonderful resource. You can only do so much on Internet searches in your company's Internet or whatnot. Getting to the source of an effort or an author of a tool and getting to know their mindset on how things work. This is gonna help resonate or help illuminate a lot of ideas for you. There are times where I, again, will have impostor syndrome about some of the Bayesian methods that we use in our team on various tools.
And in in in past, I would say, oh my goodness, Eric, you got a PhD. You should know how Bayesian works. No. I don't know how long the Bayesian algorithms work, and that's okay because I can talk to the some of the my brilliant teammates who have authored these solutions. And lo and behold, we had a great project that we're about to release in production that incorporates some, you know, fairly standard with a little sugar on top Bayesian models for clinical designs, but I was not shy about learning about why they chose certain approaches for, like, a binomial approximation versus a normal approximation and things like that. So I still have to catch myself sometimes. I'm thinking, oh, Eric, you've been in that company for 15 years. You should know about that process. No. It's okay. It's okay. It's better to ask than to not ask at all. That's my biggest takeaway from that.
So moving on to another great advice and this one coming from JJ Allaire who, is the founder of Posit. He this this part is titled getting clear about what you like doing and then finding teammates that are excited by the stuff that you don't really like doing. So in JJ's example, he mentions that he enjoyed, you know, bootstrapping these companies or founding these companies such as Rstudio, which became POSIT. But he's not exactly one that likes a lot of the managing kind of stuff that goes with, you know, running your own company. And I'd imagine, Mike, you you deal with this quite a bit in your your daily work as well. So one of the in JJ's opinion, one of the best decisions he made was helping expand his team to help those managerial administrative type tasks of running a company so that he could focus on what he's interested in is product development and really getting into the technical weeds of these solutions, which if you follow JJ's path of Rstudio and now posit, you have seen how active JJ has been in ecosystems like Rmarkdown, now Quartle, and other efforts as well. It's not just that he's the founder of Pozid. He is one of their top engineers in getting these efforts off the ground. So all you have to do is check the GitHub repo, and you can see him on top of many issues, on top of many poll requests. He is really in that. But he surrounded himself with people like Tariff and others at Pasa that are helping running, you know, the the enterprise aspects of a company while he gets to really do what he is passionate about. Again, that product development and getting into the technical bits of these products that he's working on.
So really great insights there. And and each of these, you know, kind of summaries here, there are direct links to the recordings of these actual Hangouts on YouTube, the archived Zoom, you know, Hangout sessions. So if you wanna hear it again, you know, from the source, you you're able to do that. But there's some more nuggets. Mike, why don't you take us through those? No. That's some great advice from from JJ, especially as a as somebody running a business that I can
[00:38:06] Mike Thomas:
definitely appreciate and probably need to to listen to a little bit more about delegating and making sure that you're you're focusing specifically on the the the most important parts of your job function. 2 more that we have in this blog post are from Emily Riederer and Ben Aransabia. Emily's is all about essentially making sure or or understanding that, you know, sometimes the the less flashy parts of data science, maybe not building the the fanciest machine learning or now it's AI, right, model, maybe the more gratifying parts of your data science job and your data science journey as well. And that it's important to even as we see, you know, in all the marketing hype that the the machine learning and the AI and the the ML stuff, is is, you know, maybe the stuff that gets the the most press out there, taking the the time to to learn the maybe less sexy parts of data science, is is really important to not only building your foundation, but you might find that, you know, sometimes those are the the most interesting parts of of your day to day work and being open to all of the different, you know, facets of data science and understanding that that maybe there are some of these facets that are underappreciated, but, might essentially provide you with with the most gratitude in your your job on a day to day basis. One that I can think of is is our package development and our package management, something that I absolutely love to do. I love to be able to build in our package that somebody else can install, and and and run on their their own machine and all of the different less glamorous things, right, that go into maintaining that package, ensuring that all of the different, components of that fact that package and the different requirements that that go into in terms of of files and things like that that go into ensuring that your R package is is robust and, you know, less as as less prone to to troubleshooting or or errors for somebody else as possible, is something that I actually get a lot of gratification from. And it's it's why we build our a lot of our packages, both open source and and proprietary at Catchbook for others to use. So I really appreciated, that advice there. Emily always comes with really, really practical advice. Her, talk at positconf this past year on Python ergonomics was super practical.
And, yeah, anything that that she puts out there into the world is something that I enjoy consuming. And as I said, Ben, who's the director of data science at GSK, I think had some some great advice that's probably more general than just even if you're in data science, and it's the importance of saying no. Once in a while, Eric, I have to say I have to say no to you or or no to this podcast. And and as much as we absolutely hate to do it, sometimes we have to ensure that we're keeping the correct balance in our life. And by by saying no, you know, it can be a powerful word, but it can bring peace, I think, in your day to day life, not only, you know, professionally, but but also personally because we we can't do it all as much as we often try to and as much as I know you often try to, especially. So this is was a great reminder as well.
[00:41:42] Eric Nantz:
Yeah. I I find myself living that a lot lot these days. Yeah. I I'm okay with the nose from you. Sometimes my kids on your overhand, sometimes they say no a little bit too much, but that's a different story altogether. Oh, gosh. Oh, mighty. Yeah. In any event, yeah, I another example that I thought of where it's a combination of saying no to something, but then also finding a better way to do it was I had, joked with some colleagues at the day job where I made a shiny app a few years ago that was in essence a glorified PowerPoint slide generator based on dynamic data coming in with some ggplot2 based vector graphics going into, a PowerPoint via the officer package. Again, awesome tooling. Trust me. I I really love the officer package for when I need to do this stuff. But then the time came where I was kinda asked to do this again in a more, I guess, a more simplified way, albeit trying to use the same machinery.
And I did try. Like, I really tried, but this template just was not gonna cut it. It just was not gonna cut it. And I could have brute forced my way. I could have tried to find some clever algorithm to modify the text size based on number of characters going into these cells or these areas of a PowerPoint site, but I thought, no. You know what? There's a chance to do it a better way. Quartle came to the rescue. But quartle dashboards, a responsive layout for this template where it didn't matter how much text was in it, they could expand that little, you know, expander button in each of the boxes and then get a full screen view of that particular area and then wrap it back down and just zoom in, zoom out as needed. That team loved it. But I I I I probably did too much time trying to retrofit the old approach, but trying to know when to say no, even if it's just to yourself when you're trying to come up with a solution, is is a is a is a skill that I've had to learn from experience. I'm not great at it, but that was an interesting example this year. I could have said I could have said no sooner and done the portal thing right away, but it did. Sometimes you do have to struggle a little bit in these experiences to make it happen. But, yeah, I I really resonate with everyone in those posts, and there are all sorts of those nuggets on each of those hangout sessions. So if you've never been there before, again, Libby's got all the links in in this post to those previous recordings, but it's super easy to get that on your calendar and join every Thursday at noon PM EST for those wonderful hangout sessions.
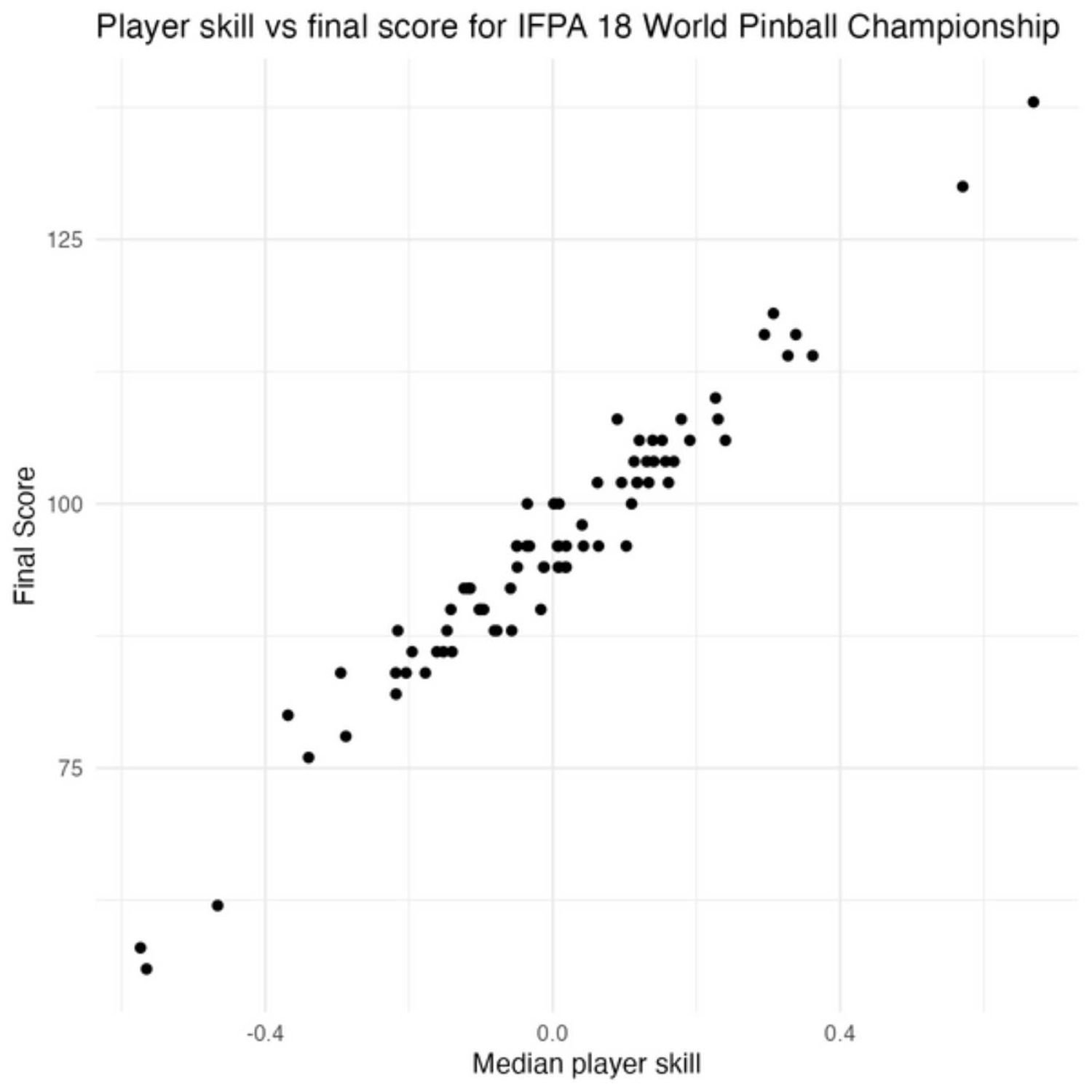
And so, yeah, I came away, you know, really excited after I had my little session last year. So, yeah, lots and lots of fun stuff there. Alright. And there's a lot more fun to be had when you look at this, some entire issue of our weekly that we have curated by Tony this week. And as much as we love to geek out and talk about the rest of the afternoon, we're gonna leave you a couple additional finds before we close-up shop here. And I told you earlier in this episode, not too long ago, that sometimes I feel a little impostor syndrome of Bayesian modeling because I did not have a lot of training of that in grad school, and I have some really brilliant teammates. I can do wizardry with it. Well, sometimes I just like to see, like, relatable examples to help connect some dots, if you will. And this this post here from Rasmuch Bath is titled a Bayesian Placket Loose Model in Stan that's applied to, of all things, pinball championship data.
So if I I love me some pinball, man. I have lots of lots of quarters ways on that in the arcade when I was younger. But what a great way to illustrate these great concept of taking, what in essence, our pairwise comparisons between different items of something such as when you have, you know, 2 teams or 2 players head to head and be able to predict them what is the likelihood of winning those particular matches based on this custom Bayesian Placket Luce model. So, they got they got the great, you know, you know, set of formulas here with the r codes of reproduce the visuals and then how to turn that into a stand model, which is, you know, a very robust way to fit Bayesian modeling, looking at all the trace spots for kind of the best fit. And then in the end, a nice little visualization, kind of hybrid line chart with the dots and the and the skill the skill of each player to see just who is kind of ranking above the rest in a somewhat forest plot like diagram. So lots lots of interesting nuggets here for a Bayesian novice like me with a domain that makes you wanna turn back time 20 years and go back to the arcade in my hometown.
[00:46:45] Mike Thomas:
Mike, what did you find? I found a great blog post from, Ma'el on it's called cover and modify some tips for our package development. A lot of it is about, maybe the workflow and and types of tests unit tests that you may want to incorporate when you are developing a test for a function that already exists. So some great, you know, little pieces of advice here, include, you know, take a look and see in the roxigen documentation above that function if there is any example code that you can leverage, to within the unit tests that you need to write for that. These are 2 types of tests that I I commonly write. It's, tests that expect type, and and, you know, you're setting maybe double or character or or or, maybe a table or something like that, a data frame, to make sure that the function is returning the type of object that you are expecting, as well as, you know, testing expect equal and actually maybe running some data through that function and ensuring that it is spinning out the the number or the value, or the character string that you would expect it to return.
And as Ma'el points out, it turns out that those two types of tests have a name, and they are called characterization tests, that lend themselves to this concept of cover and modify. So some really interesting little nuggets in here. Again, you know, anything that Mel authors is is kind of required reading for me. And I as I just mentioned in the in the last highlight that one of my, passions, if you will, is our package development and management. This is really applicable to that.
[00:48:27] Eric Nantz:
Yeah. I feel like you and I need to be accountability buddies to put these principles in practice because Yep. My, test driven development skills are not quite up to snuff yet.
[00:48:38] Mike Thomas:
You and me both.
[00:48:40] Eric Nantz:
Yep. Yep. Well, we'll keep each other honest on this. But, yeah, it's amazing to see as my mentions in the early part of this post, how she's been working with the iGraph r package quite a bit, all these different lessons that she's learning and these different techniques. Isn't that the way, though, we find ourselves knee deep in a project that may not always be comfortable at first, but then we're adapting to, you know, finding new solutions. And then you can take those solutions and use them in the rest of your, you know, development workflows. So for me, that whole portal thing I just mentioned, I'm now a huge fan of chordal dashboards because of what I learned because of, you know, putting that for the paces. So, yeah, we there's always something new to learn. Only only one one brain in my head, but I feel like I wish I had 2 or 3 of them so I could keep this track for. If I could convince all my clients to accept
[00:49:29] Mike Thomas:
HTML output, I'd be right there with you, Eric.
[00:49:33] Eric Nantz:
Yeah. I don't say I have it all figured out yet, but at least in this one case, I was like, which one would you rather have? And everybody said, I like that web version. So we're we're on the way. It's much nicer. Yep. It is very much so. You know, the Rwicky project itself is nice for your r learning. And then again, it is a community based effort. We we thrive and we frankly depend on the contributions from the community as we go through your awesome resources that you're authoring on your blogs or authoring these great packages, perhaps even compile with Nix. Who knows? But if you wanna contribute to the r weekly project, there are a few ways to do so. First of which is if you find that terrific resource, put get it in touch with us because we can do that via a poll request on the main repo at rweekly.org.
There's a link in the upper right corner, that little octocat ribbon there. You can click that and get taken directly to the poll request template in markdown format, all markdown all the time. You get a very quick primer with that template of what the contribution should be, and you are on your way. And, also, we love hearing from you for this very show. We love, to hear have you give us a fun little boost if you're listening to one of those modern podcast apps. I just listened to a a fun webinar about the podcasting 2 point o landscape, really nice insights to some of the top developers. So I may put a link to that in the show notes if you wanna listen to the the post recording on that. But, also, you can get in contact with us through our contact page, which is linked in the show notes of this episode.
And we are on social media sporadically sometimes, but I you can find me mostly on Mastodon. I am at our podcast at podcast index on social. I am also on LinkedIn as well. In fact, I will be sending a note probably in the next week or so when we put the recordings out from our recent Gen AI day for our pharma that took place a couple weeks ago. There'll be fun fun talks to to watch there. I'll put an announcement on that shortly. And then also you can find me sporackling on that weapon next thing with at the r cast. And, Mike, where can the listeners find a hold of you? Yep. You can find me on mastodon@mike_thomas@phostodon.org,
[00:51:47] Mike Thomas:
or you can check out what I'm up to on LinkedIn by searching Catch Brook Analytics,
[00:51:52] Eric Nantz:
k e t c h b r o o k. Awesome stuff. Yep. Definitely a fun read as always whenever you put your post out there. But we can't have my fun much longer. Our day jobs are calling us back, so we're gonna close-up shop here, and wish you best of luck in your data science journeys for the rest of the week, and we will be back with another episode of our weekly highlights next week.
Hello, friends. We're back with episode a 181 of the Our Weekly Highlights podcast. If you're new to the show, this is the weekly podcast where we talk about the latest happenings that we see in our highlights and additional resources every single week at rweekly.org, your weekly curated content for all things news and other awesome events in the art community. My name is Eric Nantz, and I'm delighted you join us wherever you are around the world. And joining me as always, it seems like October is already here. Where did the time go, my friend? But join my my awesome co host, Mike Thomas. Mike, yeah, where did the time go? I can't believe it. Can't believe it either. The 2024 is almost wrapping up,
[00:00:44] Mike Thomas:
coming to a close here, but we're gonna try to enjoy what we have left of it. I'm looking forward to 2025 coming soon.
[00:00:52] Eric Nantz:
Absolutely. So many of us are probably in the midst of these year end activity wrap ups, getting releases out the door, getting other things documented. I'm definitely in that in that mode right now, but this is always the the highlight of my day, no pun intended, for what we do here today. So I'm happy to, record this awesome episode with you as always, Mike. And our issue this week has been curated by Tony Elharbar, who didn't have a a big break between his last curation, but he's helping with our he's kinda scheduling switches here and there. But if you're not familiar with the our weekly effort, we have a rotating list of curators that step in every single week so we kinda spread the spread the work around, but it's all community effort driven. But as always, yeah, tremendous help from our fellow ROCE team members and contributors like you all around the world with your poll requests and other suggestions.
As I saw the the highlights come through in our little voting at the end of the weekend, it was very obvious to me what I was gonna lead off with on this episode because I am delighted, super excited to share the news that an effort that we have been covering on this show, whether in the highlights section or in our additional finds for over a year, has officially hit CRAN, and we are talking about the ricks package authored by Bruno Rodriguez to help facilitate the use of the NICS package manager for reproducible data science workflows entirely in r.
I am, again, super excited and huge congratulations to Bruno on getting this release out. It is absolutely monumental to see this happen. And as he alludes to in the blog post, and we'll have Wing 2 as always, there has been over 15 months of rigs being in development, over 1300 commits, a 143 closed issues, 175 closed poll requests, and not only that not only is ricks on CRAN itself as of earlier last week, It is also under the rOpenSci umbrella. Another major achievement. And frankly, when you think about it, it makes total sense. We are talking about a huge, huge boost in making reproducible data science workflows. And rOpenSci is one of its biggest core principles is the idea of reproducible data science. So it does seem like a match made in heaven to me, so I'm very excited to see where this goes.
And as a result of being under the Arkansas umbrella, one of the ways that a package or an effort gets onboarded is a very robust and a very transparent peer review process to get the package into our OpenSci, which we can actually look at in real time, but also I have the link to in the show notes the very, poll request or the issue with all of the review feedback and all the review steps that Bruno has done to to address feedback. It's all there, all transparent. It was a very looks like a relatively smooth process. Lots of great documentation there. It's another showcase just how robust the opens side, effort is for getting high quality software under their umbrella.
So with those, notes out of the way, you may be new to this effort and wondering just what the heck Nix actually is. We're not talking about Linux. We're not talking about Unix. We're talking about Nix, and Nix is a package manager under the hood, not too dissimilar to what some Linux distributions do for distributing software in their respective systems. Distributions such as Ubuntu and Debian use the apt package manager. Red Hat, Fedora use an RPM based distribution system. Arch is definitely the host not for the faint of heart, has their own custom repository. Nix, however, you don't have to use Nix on Linux. You can actually use it on macOS as well as Windows itself, thanks to WSL or the Windows subsystem for Linux.
So no matter which OS you're on, chances are you could get Nix up and running. And one of the ways that we recommend, I know Bruno recommends this as well, to get started with Nix in a very smooth way is using what's called the determinant systems installer of Nix. That's a vendor that's trying to bring Nix, to a first class way to enterprises and in open source and the like. And I have I have a good friend on on that team named Martin Wimpress, who is helping a lot of their documentation and and other advocacy. So getting getting NICS on your system, I highly recommend checking out the determinant NICS installer.
We're also gonna have linked in the show notes a guide called 02 NICS. If you wanna get more familiar with what's happening with Nix and trying out a few different ways in your set of development environments. But as an R user, Rix is going to handle a lot of this integration with Nix for you in the sense that you can bootstrap the necessary manifest files to tell the Nix package manager not only in the version of r to install in this isolated development environment, but pull down the packages based on a snapshot in time. In total, Nix has over 80,000 packages across the entire spectrum of software, and R is a first class citizen in Nix along with other languages like Python and Julia and many others.
So what Rakes is gonna do is help you, you know, bootstrap these environments and then to be able to say on my host machine, which may or may not even have R installed, you can have this, again, self contained development environment ready to go, reproducible. You could commit these files that are generated, which are called default dot nix, as well as a dot R profile file that's going to help the R session specifics. That could be on your GitHub repo. And if you have a collaborator that's also running next, they can pull down that exact same environment. That is huge. And if that doesn't sound familiar, you might say that does sound kind of similar to what Docker would give you and sounds similar to what RM would do from a package management perspective.
You're not wrong. They're they are somewhat similar in that sense of the overall goal, but the way they achieve it is a bit different. Docker is a core space and container technology, and that can be a heavy footprint depending on your perspective. But it also, admittedly, has a lot more mindshare in most of the dev ops sector and even in in sectors of data science with things like the rocker project that we speak highly about. So Nix may not always be right for your use case, but I am very intrigued by the promise it brings you. And full disclosure, I've been using Nix on a brand new server I have here in this basement a few feet behind me, which has been a great learning experience in and of itself to have more reproducible software stack for my infrastructure.
But I have been putting Nix through a couple tests in my open source work. And what's even more intriguing is that on top of the R environment that I can bootstrap for Rix, I can also easily add in other utilities such as a custom instance of what's called vscodium to have its own IDE in that same environment and bring it up as a GUI and have it ready to go. It's completely segregated from the rest of my host system, but I can tailor it to my liking. I could put extensions in there. I can have a pretty neat experience with r on Nix in a custom IDE to boot. Like, the possibilities are almost endless with this, and that's why I'm still I'm still learning the ropes on this, quite a bit.
I will say I haven't had a perfect experience of it just yet. There was an instance, which if you're using R on a Linux system, you're probably all too accustomed to this, where I was installing a package, I believe it was called rag or something like that, where it needed an image library development libraries to help compile. And for whatever reason, when Rix was bootstrapping this, this development environment, it didn't pick up that I needed that extra library. So I had to manually add that in. So there's gonna be, I think, some cases that are still still getting worked out, but the the future is certainly bright here.
My other picky wish that I know has been mentioned in the Rick's issue tracker, for those of us that are coming from an RM mindset where we have projects that have an RM lock file, Oh my goodness. I sure would be nice to import that directly into Rix and then magically get the package installation. There's a lot of engineering required to do that. So I'm not surprised that it hasn't landed in just yet. But I am I am getting a bit more, you know, to say I I want this feature more and more because I have I I I'm I'm not I'm not gonna exaggerate here, Mike.
I probably have in my day job over 90 projects that use RM in some way. And if I wanna convert all those to Nicks, that's a lot of manual Mhmm. Manual effort to do. So having some kind of automated way to take a lock file, magically, you know, transform that into the necessary default dot nix and getting the right package hashes, that would be massive. I have seen Python having these custom utilities that tie that poetry framework for their package management with nix. I think they call it poetry to nix, where they can somehow do this magical inference of a poetry lock file, which looks a lot similar to an rmlock file, if you're familiar with that. And they can somehow parse out then from the next package manager which Python packages to install and what hashes that correspond to that particular version.
So I have been spoiled by seeing that on, like, the Python ecosystem. I believe they have a similar thing for Rust, maybe for Julia as well. So maybe it's a matter of time. I don't know. But once that comes in, yeah, that's gonna really ease the onboarding even further for those that are coming from a different framework such as RF to Rix. But nonetheless, I don't want that to discount my huge excitement for this. I think it's a huge step to seeing Nix really taking a a solid footing in in the realm of reproducible data science. And also in the post that we're gonna link to, Bruno has a short little 5 minute tutorial video. They get you up and running with Rick's quite quickly.
But we invite you to check out the rest of his blog because there are literally about 14 or 13 of these other posts that chronicle this entire journey, which you can tell is interspersed with his learning journey of Nick's along the way. It's great to kinda see that evolution happen, and it's all been open, so to speak, for us to watch. So, yes, am I excited? Oh, heck yes. I am because the the future does look pretty bright here. I'm interested to see whatever's in the art community do with next. I've had some brief conversation with George Stagg about it. He's intrigued by the possibilities as well.
[00:12:46] Mike Thomas:
But, yeah, the future's looking pretty bright. So I'll be honest with you, Eric. Before the Rix package came out, Nix was sort of intimidating to me. I had built up a lot of, you know, personal education around Docker, and containerized environments. And when Nix came along, I don't know, it just felt like too big for me to, you know, wrap my brain around at the time. I've switched since then because this Rix package makes me feel, and the 5 minute tutorial video that Bruno has put together, showcasing, you know, how to get up and running with this package, makes me feel like it's so much more accessible.
And I think that sort of the our functions, which I think there's only 6 or 7 in this package right now that help you get up and running, with a Nix environment for your art project. Take care of a lot of the things that may have intimidated me in the first place about Nix, and and sort of make it much easier to to get started with. And if you watch this 5 minute video, you you start to realize that maybe it's not maybe it's not all that intimidating, after all. And I think, you know, one of the potential benefits, as you alluded to, Eric, of having Nix as compared to maybe the Docker and and our end environments is that your Docker images that you create can get fairly heavy fairly quickly.
And I think that there may be use cases out there where Nix would do the same thing, but the end product would be a lot more lightweight. That end environment might be a lot more lightweight. And that might be really important, depending on the the type of project that you're working on, depending on where you're trying to deploy to, you know, on the edge or something like that, a a system that doesn't have a lot of space to store, you know, large Docker images. So I I I'm really intrigued by the next project. I think this Rix package makes it a lot more accessible. I think the, fact that this package is now part of the rOpenSci project says a lot about the amount of work that Bruno and the others who've contributed to this package have put into it, and its potential importance in data science as a whole. So, very excited to see it hit crayon, and very excited to to start playing around with it because right now, at this point, there's there's no excuse. I think Bruno has done all of the work to make this as easy as possible to get started with for our developers like us.
[00:15:23] Eric Nantz:
Yeah. And and and speaking of the ways of making it easier, when you look at what the Rick's package offers you, there are 2 other additional nuggets that even go above and beyond, in my opinion. One of which is being able to leverage an another service out there for next package binary is called cachex to be able to help build an an environment and have it cached there on their infrastructure. That way when somebody pulls it down, is not having to recompile a package of some source. It'll get binary versions of the packages and other dependencies of that particular project, which, again, if you're familiar of running R on Linux, you love having at your disposal binary installations because that cuts the installation time from sometimes hours to minutes, if not seconds. So you you'll definitely wanna you'll appreciate that when you find yourself in those situations.
But he's also put this additional nugget here. Bruno has also been one of the bigger proponents of the targets package by my good friend, Will Landau. And there is a function in here called TAR nix GA, which will help you run a Targus pipeline, bootstrap by nix on GitHub actions. Oh my goodness. Like, that's almost sensory overload of all the integrations there. But what a great fit for having an automated data science pipeline, but then next having the full control on your installation of your dependencies. That that's massive. I I I can't wait to play with that myself. Yeah. No. It's incredible, and I think that
[00:16:59] Mike Thomas:
Bruno has focused on those types of applications where I think Nix can be the most powerful, you know, in terms of GitHub's actions. We have functions here that are wrappers, as you said, around, you know, building an environment on GitHub actions and making sure that, you know, after it's run the first time, everything is cached on that cache server, so it's gonna run a lot faster. The second time sort of makes me, think of, you know, Docker Hub. Maybe you could sort of, equate cachex to that, but I think there's some differences there. But I think the idea is is fairly the same. Right?
So, yeah, I I I think just the applicability and the the usefulness and new utility that Bruno has built in to, sort of the concepts behind this package are are pretty incredible.
[00:17:47] Eric Nantz:
Yeah. So I invite you to not only go to his post, but also the Rick's package site. Again, very well documented. There are a lot of vignettes, and they're ordered in a logical way to kinda start when you're brand new to Rix up until some of the very advanced use cases. So the the website looks absolutely fantastic. Again, a great fit for our OpenSci in general. So, again, it's always a team effort when these packages come up. So I wanna make sure I give kudos not just to Bruno, but also Philip Bowman, who is one of the coauthors of the package. I've seen their their work on the GitHub repo. There's been a lot of commits, as I mentioned earlier. And, this is only the beginning. Like, I can see lots of improvements coming along to Rick's end, especially as adoption grows.
Heck, I I if I get more time, I wanna help contribute to this r and piece of it. Because, again, that is somewhat scratching my own niche, but I can't be the only one that wants to transfer some legacy projects that maybe to to have a more robust workflow with Nix, down the road. So we'll be watching this quite closely. And one other mind blowing thing that, again, when you have the next package that kind of blew me away when I first did this is that with Rix itself, if you want to get one of these files, you know, boostramp or the set of files boostramp for a particular project, you don't even need R on your host system to even get Rix running at first. Because with the next package manager, you can have a special command that basically shells out to compo to grabbing the the the R environment that Bruno has baked into the the package on GitHub and then pull that down interactively in what I call an interactive shell.
You can then run RICs on that directory and get the the necessary files in that temporary environment and then exit out. I guess it's similar to what Docker gives you, but it's still it just can't I can't believe that's even possible. So on this new laptop that I just got, I don't have r on it. It's all RICs. RICs or Docker. There's no r trace of it because each of the project has its own environment, and I didn't even need r to get RICs up and running. That how what magic time are we in, Mike? I just can't believe it. Gotta love it. Well, we're going to exercise a little bit different part of our brain on this next highlight, Mike. We got a fun little programming adventure for one of our fellow rweekly curators this week. And this blog post, this highlight, has been authored by Jonathan Caroll, and he is continually pushing the envelope and trying to solve what seems like almost all the programming problems that he can come across over the next year or so that he's been doing this series.
And he comes to us this week to talk about in place modifications in R and other languages. And this all stemmed from a recent post or a video that he saw based on a problem, which in a nutshell involved having an array of of integers, and then you define some integer k and then another integer he's calling multiplier, where the task is you've got k operations to perform on this vector of numbers. And in each of these operations or iterations, you've got to find the minimum value of this vector. And, of course, if there are multiple, you know, ties in this, you just take whatever appears first. Then you replace that number you found with that number times the multiplier, and then rinse and repeat until you've exhaustively gone through all these k iterations.
So when the video he saw that there was a pretty elegant way in Python to do this, And in particular, this Python solution is taking advantage of what it has built in a compound assignment type operator, the star equal to that to that result. That is, again, calling it an in place modification. Well, r itself doesn't quite have that built in operator. He does have a solution, but that solution is technically speaking making a copy of that updated number every time. You can inspect this when you look at the memory kind of hash of an object in r, and you would see that after that operation, which looks like it's in place overriding. No. It's not. It's actually making a copy of that object updated copy of it.
And this is another case wherein in John's r solution, he has to use a for loop. He's not able to use the map function because the iterations actually depend on what happened before it. So Markov chain. Markov chain. Oh, give me flashbacks to grad school, my friend. That's, that's some frightening stuff. But, yes, Markov chain's for the win here. So as he's going through this, he realizes that the closest thing that he's seen in the R ecosystem to this in place modifier is is from the Magritter package. If you've used this before, it's the percent sign, less than sign, greater than sign, and another percent sign.
I just short aside here, this operator has given me fits for debugging, so I stopped using it many years ago. Did you have those same issues as well? I've heard the same. Yeah. In stories. Never used it.
[00:23:31] Mike Thomas:
It scared me just just visually to look at, but I had heard similar things.
[00:23:38] Eric Nantz:
Yeah. I I lost, I lost a few hours one time. I was trying to be too cute with a deep fire pipeline, and I I wrecked havoc on myself. And I was like, nope. Not gonna do that again. None nonetheless, as, John's exploring, what possible ways could he kind of replicate this in place modifier in r itself? Because his motivation is, yeah, when you have a small variable name, it's kinda easy to take a reference that variable that's probably as a vector or some numbers. And then in the square brackets, call a function on that vector to grab the right element, but then reassign that a new value.
He says them says in this, well, what if that variable name is long? We don't have to keep typing that over and over again. Is there a more convenient way to do this? Turns out not really easily unless you take some, rather risky shortcuts, and that's where I'm kind of gutting to this meat of of the solution here. Again, this is giving me flashbacks to some bad practices I did in my earlier days where you're looking at the parent environment of the function, you know, that's being called in and then using a combination of the assign operator and then the deparse substitute for that variable and injecting into a basically a copy of that, a hidden copy of it.
Oh, you tell about the bugging nightmares. A lot of times in my early days, I would either get code from my old projects or a collaborator that did this, and it was so difficult to make heads or tails on what was happening there. But that is kind of the closest John was able to achieve with this solution, but he acknowledges he would not really wanna do that in production, that kind of solution. So he started to look at other languages and what they offer. And sure enough, in the Julia language, there are ways to have this in place operator with a slightly different syntax that or they call mutating, where they give the name of a function but then an explanation point afterwards and feeding in the name of the object that you want to modify in place.
And sure enough, he shows her this example of, like, reversing the order of numbers that you can, in Julia, get that in place modification of a simple vector without having to call the name more than once. So that that's pretty slick that Julia has that. And he experimented with that a little bit more, started to look at, you know, how could he do more elegant solutions to this, kind of do a little hacking around it. And so he's got at the end of the post a little modified version of this as based on, like, vector operations. He's calls that set underscore if. And sure enough, it kind of does the job.
But he's wondering if he could avoid if he can make that even easier and if maybe there's an r solution after all. So another update at the end of this post. Turns out John did end up writing a solution to this in r after all. He's got a package called Vec. It's available on GitHub. I'll link to it in the show notes with some of these features kind of baked in. And he said that there are some suggestions already from members of the community that in the base of what Vec is going to do is give you a new vector class that is gonna help with some of these in place modifying another optimized operations of vectors. So, again, great to see this. I haven't actually seen this yet.
And then yeah. So it was a great a great exploration into what's possible with these in place operators and gotten the learning journey of seeing r not quite having enough. And then in the end, like anything, you don't know if it you don't see any something there? Write a package for it. So fun journey nonetheless and a good little brain teaser once again that enters the highlights here.
[00:27:52] Mike Thomas:
Yeah. Absolutely. It was fun to, I guess, just see how a a leak code problem, could be, you know, as Jonathan, I feel like often does, push to its limits in a lot of different ways and then turned into an r package that potentially may have some practical applications for folks looking to to do this type of, you know, in place replacement, if you will, without consuming, more memory than necessary, you know, as we have typically had to do in r. And this new Vec package that he's created is is pretty interesting right now. It looks like it's fairly early on in its life. There are a couple of issues out there, looking for folks to help implement, some generics for, these these Vec objects, which are this new class of of vectors that hopefully will be able to to do some of the things that John mentions in the in the blog post, but have a lot more extensibility than what we get out of the box in in base r with, vectors. So that's pretty interesting as well.
It looks like in the GitHub issues, there's some discussions around this concept of of broadcasting, which wasn't a term, I believe, that I I saw in the the blog post, but, I think it intersects with maybe some work that Davis Phan has done as well on a an R package called R Ray, which I'm taking a look at at now. So it'd be I guess, this is all, you know, pretty interesting stuff as we're we're fairly in the weeds here as Jonathan often does in terms of taking a look at at really the internals of r, and I I really love the comparisons to Python and and Julia, and and taking a look at, you know, what's available over there and bringing it potentially into the r ecosystem. I feel like that's a concept that we see more and more of nowadays.
I've seen a lot of conversation lately about the the polars package in Python and and its potential, inspiration from the tidyverse. Right? So we have, I feel like, a lot of cross pollination going on to try to build the best products possible and and take a look at, you know, what are the best concepts across all programming languages, such that when we do create something new, we're trying to to create the best version of it. So very interesting blog post, by John. Cool thing about open source is that we can, you know, develop something that that somebody else can use pretty quickly here when we come up with an idea. So I highly recommend checking out the vecvecpackage if, this is a topic that is of interest to you.
[00:30:29] Eric Nantz:
Absolutely. We got that linked in the show notes as well. And, certainly, if not only is John's, you know, post insightful about his current take on these solutions, There's always, like, I wanna call history lesson per se, but he was venturing into some of the ideas of other programming languages. Some of them definitely have a a long history, you might say. Even this language that he references called APL, which at first I thought was a license abbreviation, but, no, that literally stands for a programming language, which has a book itself dedicated to it. So he's he's I love the way he intersperses kind of the lessons he's learned from these programming, you know, brain teasers, these exercises, but seeing the mindset across whatever languages are doing. So, certainly, if you wanna sharpen your dev toolbox, John's blog is a is a great place to go.
And rounding out, we're gonna get a bit, you know, back to the practical side of data science in our last highlight here because we have a very great showcase of some of the valuable insights that we've seen from recent sessions of the data science hangout, which is, hosted by Rachel Dempsey. And as of recently, her new co host is also the author of our last highlight today, Libby Heron, who has just joined POSIT as a contractor for helping with the data science hangout and also POSIT Academy. She authors this terrific post on the POSIT blog called Data Career Insights: Lessons from 4 Senior Leaders in the Data Space.
So we're gonna walk through 4 of these examples here in our in our roundup here. But first, I just want to mention that hangout is a great place, a great venue for those that are looking at learning from others in the community on their data science journey. If you're not familiar with the effort, there is what we call a featured leader or featured, you know, maybe co leaders that Rachel talks with and Libby talks of as well in the session, but it's a welcoming environment. Anyone at all are welcome to join no matter which industry, no matter which spectrum of data science you fall under. I had the pleasure of being on that about a year or so ago. It was it was a a a great time.
We've we've learned a lot even just through the questions that we would get from the audience, and the chat is always on fire, as I say, whenever whenever those sessions are on. There's lots of awesome insights on there. So she has links to all that in the blog post that we're mentioning here, but we're gonna give our take on some of the lessons that are highlighted in this post here. So the first, insight here is focusing on learning how things work and not being afraid of this feeling that you should already know how things work. I boy, does this resonate a lot? So this came from a conversation with Jamie Warner who is a managing director at Plymouth Rock Assurance, where she was talking about, yeah, you may have heard some advice before, but in the data science world, but there may be a legacy process, a legacy model that some it may be explained to you, but then there may be other situations where you may not know exactly how something works.
But when you are insight you're inquisitive, I should say, and you talk to a subject matter expert about, you know, what what is the mechanics behind this, getting around their thought process, Yeah. That is amazingly helpful. People end up being a wonderful resource. You can only do so much on Internet searches in your company's Internet or whatnot. Getting to the source of an effort or an author of a tool and getting to know their mindset on how things work. This is gonna help resonate or help illuminate a lot of ideas for you. There are times where I, again, will have impostor syndrome about some of the Bayesian methods that we use in our team on various tools.
And in in in past, I would say, oh my goodness, Eric, you got a PhD. You should know how Bayesian works. No. I don't know how long the Bayesian algorithms work, and that's okay because I can talk to the some of the my brilliant teammates who have authored these solutions. And lo and behold, we had a great project that we're about to release in production that incorporates some, you know, fairly standard with a little sugar on top Bayesian models for clinical designs, but I was not shy about learning about why they chose certain approaches for, like, a binomial approximation versus a normal approximation and things like that. So I still have to catch myself sometimes. I'm thinking, oh, Eric, you've been in that company for 15 years. You should know about that process. No. It's okay. It's okay. It's better to ask than to not ask at all. That's my biggest takeaway from that.
So moving on to another great advice and this one coming from JJ Allaire who, is the founder of Posit. He this this part is titled getting clear about what you like doing and then finding teammates that are excited by the stuff that you don't really like doing. So in JJ's example, he mentions that he enjoyed, you know, bootstrapping these companies or founding these companies such as Rstudio, which became POSIT. But he's not exactly one that likes a lot of the managing kind of stuff that goes with, you know, running your own company. And I'd imagine, Mike, you you deal with this quite a bit in your your daily work as well. So one of the in JJ's opinion, one of the best decisions he made was helping expand his team to help those managerial administrative type tasks of running a company so that he could focus on what he's interested in is product development and really getting into the technical weeds of these solutions, which if you follow JJ's path of Rstudio and now posit, you have seen how active JJ has been in ecosystems like Rmarkdown, now Quartle, and other efforts as well. It's not just that he's the founder of Pozid. He is one of their top engineers in getting these efforts off the ground. So all you have to do is check the GitHub repo, and you can see him on top of many issues, on top of many poll requests. He is really in that. But he surrounded himself with people like Tariff and others at Pasa that are helping running, you know, the the enterprise aspects of a company while he gets to really do what he is passionate about. Again, that product development and getting into the technical bits of these products that he's working on.
So really great insights there. And and each of these, you know, kind of summaries here, there are direct links to the recordings of these actual Hangouts on YouTube, the archived Zoom, you know, Hangout sessions. So if you wanna hear it again, you know, from the source, you you're able to do that. But there's some more nuggets. Mike, why don't you take us through those? No. That's some great advice from from JJ, especially as a as somebody running a business that I can
[00:38:06] Mike Thomas:
definitely appreciate and probably need to to listen to a little bit more about delegating and making sure that you're you're focusing specifically on the the the most important parts of your job function. 2 more that we have in this blog post are from Emily Riederer and Ben Aransabia. Emily's is all about essentially making sure or or understanding that, you know, sometimes the the less flashy parts of data science, maybe not building the the fanciest machine learning or now it's AI, right, model, maybe the more gratifying parts of your data science job and your data science journey as well. And that it's important to even as we see, you know, in all the marketing hype that the the machine learning and the AI and the the ML stuff, is is, you know, maybe the stuff that gets the the most press out there, taking the the time to to learn the maybe less sexy parts of data science, is is really important to not only building your foundation, but you might find that, you know, sometimes those are the the most interesting parts of of your day to day work and being open to all of the different, you know, facets of data science and understanding that that maybe there are some of these facets that are underappreciated, but, might essentially provide you with with the most gratitude in your your job on a day to day basis. One that I can think of is is our package development and our package management, something that I absolutely love to do. I love to be able to build in our package that somebody else can install, and and and run on their their own machine and all of the different less glamorous things, right, that go into maintaining that package, ensuring that all of the different, components of that fact that package and the different requirements that that go into in terms of of files and things like that that go into ensuring that your R package is is robust and, you know, less as as less prone to to troubleshooting or or errors for somebody else as possible, is something that I actually get a lot of gratification from. And it's it's why we build our a lot of our packages, both open source and and proprietary at Catchbook for others to use. So I really appreciated, that advice there. Emily always comes with really, really practical advice. Her, talk at positconf this past year on Python ergonomics was super practical.
And, yeah, anything that that she puts out there into the world is something that I enjoy consuming. And as I said, Ben, who's the director of data science at GSK, I think had some some great advice that's probably more general than just even if you're in data science, and it's the importance of saying no. Once in a while, Eric, I have to say I have to say no to you or or no to this podcast. And and as much as we absolutely hate to do it, sometimes we have to ensure that we're keeping the correct balance in our life. And by by saying no, you know, it can be a powerful word, but it can bring peace, I think, in your day to day life, not only, you know, professionally, but but also personally because we we can't do it all as much as we often try to and as much as I know you often try to, especially. So this is was a great reminder as well.
[00:41:42] Eric Nantz:
Yeah. I I find myself living that a lot lot these days. Yeah. I I'm okay with the nose from you. Sometimes my kids on your overhand, sometimes they say no a little bit too much, but that's a different story altogether. Oh, gosh. Oh, mighty. Yeah. In any event, yeah, I another example that I thought of where it's a combination of saying no to something, but then also finding a better way to do it was I had, joked with some colleagues at the day job where I made a shiny app a few years ago that was in essence a glorified PowerPoint slide generator based on dynamic data coming in with some ggplot2 based vector graphics going into, a PowerPoint via the officer package. Again, awesome tooling. Trust me. I I really love the officer package for when I need to do this stuff. But then the time came where I was kinda asked to do this again in a more, I guess, a more simplified way, albeit trying to use the same machinery.
And I did try. Like, I really tried, but this template just was not gonna cut it. It just was not gonna cut it. And I could have brute forced my way. I could have tried to find some clever algorithm to modify the text size based on number of characters going into these cells or these areas of a PowerPoint site, but I thought, no. You know what? There's a chance to do it a better way. Quartle came to the rescue. But quartle dashboards, a responsive layout for this template where it didn't matter how much text was in it, they could expand that little, you know, expander button in each of the boxes and then get a full screen view of that particular area and then wrap it back down and just zoom in, zoom out as needed. That team loved it. But I I I I probably did too much time trying to retrofit the old approach, but trying to know when to say no, even if it's just to yourself when you're trying to come up with a solution, is is a is a is a skill that I've had to learn from experience. I'm not great at it, but that was an interesting example this year. I could have said I could have said no sooner and done the portal thing right away, but it did. Sometimes you do have to struggle a little bit in these experiences to make it happen. But, yeah, I I really resonate with everyone in those posts, and there are all sorts of those nuggets on each of those hangout sessions. So if you've never been there before, again, Libby's got all the links in in this post to those previous recordings, but it's super easy to get that on your calendar and join every Thursday at noon PM EST for those wonderful hangout sessions.
And so, yeah, I came away, you know, really excited after I had my little session last year. So, yeah, lots and lots of fun stuff there. Alright. And there's a lot more fun to be had when you look at this, some entire issue of our weekly that we have curated by Tony this week. And as much as we love to geek out and talk about the rest of the afternoon, we're gonna leave you a couple additional finds before we close-up shop here. And I told you earlier in this episode, not too long ago, that sometimes I feel a little impostor syndrome of Bayesian modeling because I did not have a lot of training of that in grad school, and I have some really brilliant teammates. I can do wizardry with it. Well, sometimes I just like to see, like, relatable examples to help connect some dots, if you will. And this this post here from Rasmuch Bath is titled a Bayesian Placket Loose Model in Stan that's applied to, of all things, pinball championship data.
So if I I love me some pinball, man. I have lots of lots of quarters ways on that in the arcade when I was younger. But what a great way to illustrate these great concept of taking, what in essence, our pairwise comparisons between different items of something such as when you have, you know, 2 teams or 2 players head to head and be able to predict them what is the likelihood of winning those particular matches based on this custom Bayesian Placket Luce model. So, they got they got the great, you know, you know, set of formulas here with the r codes of reproduce the visuals and then how to turn that into a stand model, which is, you know, a very robust way to fit Bayesian modeling, looking at all the trace spots for kind of the best fit. And then in the end, a nice little visualization, kind of hybrid line chart with the dots and the and the skill the skill of each player to see just who is kind of ranking above the rest in a somewhat forest plot like diagram. So lots lots of interesting nuggets here for a Bayesian novice like me with a domain that makes you wanna turn back time 20 years and go back to the arcade in my hometown.
[00:46:45] Mike Thomas:
Mike, what did you find? I found a great blog post from, Ma'el on it's called cover and modify some tips for our package development. A lot of it is about, maybe the workflow and and types of tests unit tests that you may want to incorporate when you are developing a test for a function that already exists. So some great, you know, little pieces of advice here, include, you know, take a look and see in the roxigen documentation above that function if there is any example code that you can leverage, to within the unit tests that you need to write for that. These are 2 types of tests that I I commonly write. It's, tests that expect type, and and, you know, you're setting maybe double or character or or or, maybe a table or something like that, a data frame, to make sure that the function is returning the type of object that you are expecting, as well as, you know, testing expect equal and actually maybe running some data through that function and ensuring that it is spinning out the the number or the value, or the character string that you would expect it to return.
And as Ma'el points out, it turns out that those two types of tests have a name, and they are called characterization tests, that lend themselves to this concept of cover and modify. So some really interesting little nuggets in here. Again, you know, anything that Mel authors is is kind of required reading for me. And I as I just mentioned in the in the last highlight that one of my, passions, if you will, is our package development and management. This is really applicable to that.
[00:48:27] Eric Nantz:
Yeah. I feel like you and I need to be accountability buddies to put these principles in practice because Yep. My, test driven development skills are not quite up to snuff yet.
[00:48:38] Mike Thomas:
You and me both.
[00:48:40] Eric Nantz:
Yep. Yep. Well, we'll keep each other honest on this. But, yeah, it's amazing to see as my mentions in the early part of this post, how she's been working with the iGraph r package quite a bit, all these different lessons that she's learning and these different techniques. Isn't that the way, though, we find ourselves knee deep in a project that may not always be comfortable at first, but then we're adapting to, you know, finding new solutions. And then you can take those solutions and use them in the rest of your, you know, development workflows. So for me, that whole portal thing I just mentioned, I'm now a huge fan of chordal dashboards because of what I learned because of, you know, putting that for the paces. So, yeah, we there's always something new to learn. Only only one one brain in my head, but I feel like I wish I had 2 or 3 of them so I could keep this track for. If I could convince all my clients to accept
[00:49:29] Mike Thomas:
HTML output, I'd be right there with you, Eric.
[00:49:33] Eric Nantz:
Yeah. I don't say I have it all figured out yet, but at least in this one case, I was like, which one would you rather have? And everybody said, I like that web version. So we're we're on the way. It's much nicer. Yep. It is very much so. You know, the Rwicky project itself is nice for your r learning. And then again, it is a community based effort. We we thrive and we frankly depend on the contributions from the community as we go through your awesome resources that you're authoring on your blogs or authoring these great packages, perhaps even compile with Nix. Who knows? But if you wanna contribute to the r weekly project, there are a few ways to do so. First of which is if you find that terrific resource, put get it in touch with us because we can do that via a poll request on the main repo at rweekly.org.
There's a link in the upper right corner, that little octocat ribbon there. You can click that and get taken directly to the poll request template in markdown format, all markdown all the time. You get a very quick primer with that template of what the contribution should be, and you are on your way. And, also, we love hearing from you for this very show. We love, to hear have you give us a fun little boost if you're listening to one of those modern podcast apps. I just listened to a a fun webinar about the podcasting 2 point o landscape, really nice insights to some of the top developers. So I may put a link to that in the show notes if you wanna listen to the the post recording on that. But, also, you can get in contact with us through our contact page, which is linked in the show notes of this episode.
And we are on social media sporadically sometimes, but I you can find me mostly on Mastodon. I am at our podcast at podcast index on social. I am also on LinkedIn as well. In fact, I will be sending a note probably in the next week or so when we put the recordings out from our recent Gen AI day for our pharma that took place a couple weeks ago. There'll be fun fun talks to to watch there. I'll put an announcement on that shortly. And then also you can find me sporackling on that weapon next thing with at the r cast. And, Mike, where can the listeners find a hold of you? Yep. You can find me on mastodon@mike_thomas@phostodon.org,
[00:51:47] Mike Thomas:
or you can check out what I'm up to on LinkedIn by searching Catch Brook Analytics,
[00:51:52] Eric Nantz:
k e t c h b r o o k. Awesome stuff. Yep. Definitely a fun read as always whenever you put your post out there. But we can't have my fun much longer. Our day jobs are calling us back, so we're gonna close-up shop here, and wish you best of luck in your data science journeys for the rest of the week, and we will be back with another episode of our weekly highlights next week.