How the latest release of patchwork is saving a cozy space for gt tables, a new package in the ggplot2 ecosystem to lend a guide for your guides, and a prime way of using R to brute-force the answer to a mathematical brain-teaser.
Episode Links
Episode Links
- This week's curator: Tony Elhabr - @[email protected] (Mastodon) & @TonyElHabr (X/Twitter)
- patchwork 1.3.0
- {gguidance}: Extended guide options for 'ggplot2'
- Prime numbers as sums of three squares. by @ellis2013nz
- Entire issue available at rweekly.org/2024-W39
- gt 0.11.0 release notes https://gt.rstudio.com/news/index.html#gt-0110
- Being free from constraint https://www.data-imaginist.com/posts/2024-01-05-patchwork-1-2-0/#being-free-from-constraint
- gguidance: A guided tour vignette https://teunbrand.github.io/gguidance/articles/tour.html
- Create a free Llama 3.1 405B-powered chatbot on an R package's GitHub repo in <1 min https://blog.stephenturner.us/p/create-a-free-llama-405b-llm-chatbot-github-repo-huggingface
- Ease renv::restore() by updating your repository to Posit Public Package Manager https://www.pipinghotdata.com/posts/2024-09-16-ease-renvrestore-by-updating-your-repositories-to-p3m
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @[email protected] (Mastodon) and @theRcast (X/Twitter)
- Mike Thomas: @mike[email protected] (Mastodon) and @mikeketchbrook (X/Twitter)
- Smoke & Marbles - Castlevania: Symphony of the Night - Emunator, ZackParrish, Lucas Guimaraes - https://ocremix.org/remix/OCR04714
- See Me Again - Valis III - tibonev - https://ocremix.org/remix/OCR04610
[00:00:03]
Eric Nantz:
Hello, friends. We're back of episode a 180 of the Our Weekly Highlights podcast. You know what? That's a cool number. Maybe we should 180 and call this the SaaS Weekly Highlights podcast. Oh, oh, I get it. No. I'm just kidding. No. No. No. No. Buckle up, folks. We're we're still the rweeklyhighways. I couldn't resist. Anyway, this is the weekly podcast where we're talking about the awesome highlights and other resources I've shared every single week at rweekly.org. My name is Eric Nantz, and I'm delighted that you join us from wherever you are around the world. We're back at our usual recording time. But, of course, just like usual, I never do this alone, at least not unless I'm forced to because I still have my trust to cohost Mike Thomas with me. Mike, how are you doing this morning? Doing well, Eric.
[00:00:47] Mike Thomas:
Had a look a tiny, tiny little time change. I appreciate you being accommodating here, but we're we're getting it in.
[00:00:54] Eric Nantz:
We're getting it in. One way, look like crook. No matter if we're moving or doing chaotic virtual events, we always find a way. Right? Exactly. Exactly. And just like finding a way, our weekly finds a way to release an issue practically every single week, and that is not possible without this being a community driven effort by our curator team. And our curator this week is Tony Elharbar. Of course, he was, made famous a few years ago with his participation in the slice competition. I saw a fond memories of watching that. But, of course, he had tremendous help from our fellow Arrowrocki team members and contributors like all of you around the world with your poll requests and other suggestions. And we're gonna actually, for our first two highlights, we're gonna definitely deep dive into some novel visualization upgrades for your toolbox.
The first of which is a package that has gotten a lot of positive attention since it was released a few years ago. If you've ever been in the situation where you had multiple plots that you wanted to put together in a seamless, like, multi figure, multi panel environment and may and have them be completely separate types of plots, Patchwork is your friend here. Patchwork is the r package that's been authored by Thomas Lynn Peterson, who is a software engineer on the tidyverse team over at Posit. And in particular, Patchwork just had a major new release, version 1 dot 3 dot o. And we're gonna cover a few of the major features landing this release.
And to start off with, I have some good friends in another, industry, we'll call it, named Bubba Ray and D Von. And, boy, they sure like their tables. They were telling me, Eric, get the tables for Patchwork. Well, guess what? We're gonna get some tables for Patchwork because in this release, you are now able to not just put a ggplot2typeplot in patchwork. You now have first class support to put in a table created by GT. GT has made a lot of waves in the table generation ecosystem and r, which, of course, has been authored by Rich Yone, who did a wonderful presentation on the past and the future of GT at Positconf.
But a lot of this feature is possible because of yet more terrific contributions to the open source GT package. This one, authored by Toon Wendenbrand, who will be featured on another highlight later on, but he laid the foundation so that GT objects can now be composed or rendered as GROBs. Where if you're not familiar what a GROB is, that is the underpinning type of object that the system used by ggplot2 is using to compose the plots together in the underpinnings. So with both now a gt object as a GROB and, of course, ggplot2 objects as GROBs, they now can fit seamlessly into patchwork.
And we'll just, I'll cover a couple of the major things about this new feature. And, again, this is brand new, but already out of the box, you're gonna have terrific support to just literally just add this GT object in your patchwork call. Just literally adding the 2 objects together, and you're gonna get the patchwork rendered composition right away. And you get some niceties under the hood or as part of the functions with this because you will now have first class support for adding titles, subtitles, captions, just like you would in a normal GT, and they will show up just fine in a patchwork composition as well.
But if you wanna customize things further for how tables are wrapped into this, there is appropriate enough a function called wrap underscore tables that's gonna let you customize how the table utilizes, say, the space around it. So in Patchwork, each object gets put in what's called a panel. And with this wrap table, you can actually define which parts of the table are fitting into that panel. By default, it's every part of the table, which includes, like, row labels, titles, column headers, and whatnot. But you can actually customize which parts are actually going outside the panel area, such as maybe the top, the left margin, the right margin, and what have you. That's nice if you wanna line things up in a more custom way.
And then also with that, there are some other enhancements as well to how you define the layouts. And what's cool is that it's even gonna be intelligent enough if you're doing, like, a top down composition and your table and your plot are sharing, say, the same variables in, say, rows or columns. They will automatically kinda line up next to each other. So your your eye can visually track maybe that plot at the top with that particular variable and then the table at the bottom and line those values up. It's really slick how they do that. I have no idea how they did it, but it's a lot of awesome engineering around it nonetheless.
And the one the one caveat I wanna mention has to do with accessibility. Because under the hood, when these tables are rendered as GROBs and then put into a patchwork composition, the table is converted to an image PNG representation. Whereas by default in GT, if you're just creating the table, the default output format for that is HTML, which, of course, HTML. You can actually get the text that's representing that table and use that in accessibility type features. So if you are going to put a GT table in a patchwork setup, make sure to especially if it's going in, like, a report, publication, or whatnot, make sure to complete the alt text for that entire patchwork to include not just the text around the plot itself, but also the text around the table. It might take a little getting used to, but if you're already well versed in how accessibility features in GBOD 2 works, it should be a pretty seamless workflow for you. And it will also have a link to the the show notes for additional content with regards to the GT release notes where this, GROB feature landed if you want to learn more about how that worked.
But wait. There's more, as I say, in this Patchwork release. And if you've been looking for a little freedom in your Patchwork compositions, well, that has you covered with a lot of bells and whistles around that, doesn't it, Mike? Yes. It does. And I believe in
[00:07:46] Mike Thomas:
the previous version of Patchwork that was released, there was this new function called free, that was added to the API. And I know that Thomas Lynn Peterson, who I think is is one of the leads on the Patchwork project Yep. Not only talked about, you know, this function at at PasaComp last year, but was also really wanted to be really thoughtful about, you know, how this particular function called free was was going to work and and really careful because, you know, as you noted, Eric, Patchwork does some pretty incredible stuff for us, under the hood that, you know, you and I don't even understand necessarily how it works in terms of aligning axes and and things like that.
So so Thomas wanted to be really careful, and I think that the Patchwork team wanted to be really careful that, they made the correct decisions when it came to how this new free function was going to work. So there's there's some additional arguments, that are now introduced into this free function that allow you to better sort of, align, you know, multiple charts with each other. So one of those arguments is is called side, which allows you to supply either a a character t, r, b, or l. I think that's top, right, bottom, and left characters to indicate sort of which side you want to free up and not necessarily, you know, fix, axes and things like that.
So there's, you know again, we're doing podcasts on data visualization. You're gonna be best served if you take a look at the blog yourself, but he is a great example of, using the side equals l argument to to free up the left side of the plot, while the the right side of the plot sort of stays fixed, if you will, with the the plot below it. There is also, a type possible argument within the free function as well, which prior to, that type argument being introduced when you were putting 2 stacking, you know, for instance, vertically, 2 plots on top of each other, sometimes a plot that had a an axis label, that axis label would be pushed way out, if the other plot above it, if you will, in in this particular example, did not have an access title.
So that that access title in the the one plot that did have an access title was kinda floating way out in space in in situations where you had, long, sort of, access labels, on one plot. And, again, the the blog post does a great job of demonstrating an an example here. So now we have this type equals label, argument that we did not have previously that pushes that axis label on the the one plot that does have the axis title, excuse me, much closer to the axis labels themselves. So it's not that axis title is no longer, sort of, floating out in space, which is is really helpful. There is also a type equals space argument, that sort of just better condenses, from what I can tell, you know, your plots and the the white space in the margins between your plots, which is always something that I've had a tricky time doing, you know, especially when we are trying to in a lot of instances, you know, we might be saving this as some sort of an image file that we're then putting into a a quarto presentation or or something like that.
And, you know, white space becomes very important when you were trying to fit a lot of content on a slide, for instance, or in a PDF. Right? So we have this new type equals space argument that allows us to to better manage that. And I think that there there might be a couple additional bug fixes in this highlight as well, but the new functionality, you know, is is really helpful. I've been doing a lot of work lately, unfortunately, in matplotlib. Some of this stuff is equivalent and possible, but some of it wrestling with with spacing and white space and what are called subplots in matplotlib, is is very, very tricky. And I wish that I had the patchwork,
[00:11:52] Eric Nantz:
package available over there. Yeah. So once you start using it, you don't know how you live without it. I mean, this has been an issue that I wrestle with so much back in my earlier days of helping do a lot of biomarker analysis and creating custom PDF reports so we wouldn't just have one type of plot. We would have multiple types and then trying to get into the grid system to do all the alignment manually. It was a major undertaking. Patchwork is just giving you such a elegant API on that fits so natively with the ggplot2, you know, layered philosophy of the grammar graphics. It it really is hard to replicate this across different different languages. So anytime I need these type of gg plots to be present, especially in a report, yeah, Patchwork is gonna be my go to for it. My greedy ass has been and I've been not the only one asking this, but if you recall, there was some work to create animated ggplot. So ggAnimate that, Thomas took over from David Robinson.
Oh, I'm so greedy. I would love that patchwork work with those, but that's okay. I I can I can wait for that because this is already spectacular in terms of the compositions we are have at our disposal? And now with GT, the possibilities are even more more endless in my opinion. And like many things in the r community, there's a lot of synergy in respect to this issue because our next highlight is coming from that same contributor I mentioned that helped build the foundation for getting GTE pack tables into patchwork. And this next highlight is a brand new art package that has hit the ecosystem authored by Ton Vandenbrand who is a PhD student at the Netherlands Cancer Institute. And, apparently, he's been working on a lot of ggplot2 stuff in his previous open source efforts. But in particular, this new effort is a new r package called gguidance.
I have to catch myself from saying ggguidance because of ggplot2, but, you know, hopefully, I got it right. But, nonetheless, if you've ever wanted or found yourself in a situation where, yeah, you get a lot of nice customizations already out of the box with respect to your guides and other aspects of how you, you know, customize your axes, labels, and your legend attributes in ggplot2, the vanilla version of it. G guidance is gonna give you kind of a more elegant way to bring some additional customization with some of its own versions of these guides.
And the and this, vignette that we're gonna be highlighting here and that we'll put in the show notes as well as a nice summary of 2 kind of major categories of these features. I'm gonna lead off with these really great functions that are prefixed with guide underscore axis. So these are tailored towards bringing some additional formatting possibilities to the way your axis labels and tick marks are specified. The first of which is guide axis custom. And this is great for when you have, you know, your typical two dimensional plot with an x and y axis, and those axes are some kind of positional type metric, maybe a discrete scale or or a bin to continuous scale.
And this is great when you want to add a little customization to it. Say one of the things that comes out of the box is on the tick marks. You can add what are called bidirectional tick marks where, again, as an audio podcast, it's gonna be hard to hard to say this, you know, very clearly, but it gives you kind of both the the line at the bottom of that or the axis line and above it as well. So in case you want that additional that visual cue of where the axis label tick actually starts, that's a it's a nice little visual cue around that. But the real selling point in tones of vignette here about this function comes when you decide in your plot to switch maybe the coordinate system going from, say, the typical scatterplot like x y, you know, 2 dimensional layout to a more radial, you know, type, you know, circle layout.
In the past, you would have to also modify the guide yet again in your usual route to call when you switch those coordinate systems. But with Guide Access Custom, it is intelligent enough to know when you switch that coordinate type of system, and you don't have to customize it any further. So there's a great example in the in the vignette here where he goes from, like, the scatterplot type visualization to a, to a radio plot, but he could keep the guide, access call exactly the same. That's pretty handy when you have to switch these, you know, on the fly with a lot of friction in between. And then another really neat feature, and I don't remember when this landed in Jigetwapattu proper, but now on your axes you can have nested axes where maybe you have in the case of the in the vignette here you've got a bar a stat a bar chart where you've got different flavors of a product of food maybe, you know, coffee, tea, apple, pear, or whatever.
And then you've got a more overarching category for these. So you can put that overarching category underneath the appropriate labels, and you can do this with ggplot2 proper. But what, is offered in this package is a way to customize how you're exactly doing that categorization, or maybe you have a leftover category in your nested top, you know, sublevel, and you don't care about putting that under any top level. So you just wanna leave that blank. You can do that by manually defining a key of these labels as a simple data frame like setup.
But then you can also customize instead of just having a horizontal line that separates these heading or these nested labels. You could have, like, a, like, a curly bracket, or you can have, in fact, up to 7 types of brackets that come out of the box for that separation between the sub labels and the top level labels. And, yes, if you're adventurous enough with creative enough, you can create your own bracket style by feeding in a simple kind of matrix of x and y coordinates. And in the example, he's got, like, a a jagged line instead, whatever you wanna do. That's beyond me. But the cool point is if you really want full control over the visual cues of these nested labels, you've got a lot of power exposed to you with this with this awesome function of guide access nested.
So I'm definitely gonna be checking that one out, but there is a lot more to this with respect to color customization. So, Mike, why don't you take us through what he offers you in this package? Yes. There is. There are these two functions,
[00:19:18] Mike Thomas:
guide call bar and guide call steps, which we'll talk about first, which are are pretty incredible that allow us to be able to either have, you know, sort of this continuous gradient gradient, in our legend, color gradient, or we can have, something that looks more like a discrete color gradient, where we have, you know, specific sort of bins, for the particular colors that we're going to show, in our legend that correspond to the colors that are shown on the plot as well. There's this, notion of caps as well, where you can sort of fix your color scale in your legend and have it bounded with a a lower limit and an upper limit. And then you can have a shape, that also has a corresponding, you know, perhaps different color. In this case, it's it's gray because, he's trying to show that, you know, these values would be out of bounds anything above 30 or below 10, and and he has a triangle on either side of the, the color guide here in the legend to represent, what are called these caps on the the legend or the guide, if you'll which are pretty cool.
You can also, you know, implement those caps as as shapes, and he uses triangles in the example here. But instead of, you know, having them be these out of bounds values, you could have them be, you know, these colors that, sort of, still correspond to your gradient that you're using in your chart. You can cap just one side, either the top or the bottom of the legend, which is pretty interesting as well. Just a lot of different flexibility to do things here. And then sort of similar, Eric, to what you were talking about in terms of brackets, you know, on the axes of the chart, you can also add brackets to the legend. So there's one example here where, he's he's sort of creating brackets on the legend that classify values, in a group a or, you know, if you're higher up in the gradient, then you would belong to to group b. And you can stick those brackets right against, the side of your legend, which is a really, really cool feature, something I had had never really thought about myself as well.
He he has an example here where the legend itself is is radial. It's it's a circle. It kinda looks like a donut chart or or a clock, if you will, where you have this this sort of polar coordinate system for your legend, which is really interesting. I can't think of a use case where I would necessarily employ that over a a legend that's, you know, just just rectangular. But it's it's wild that we have the ability to do that. So a lot of customization here, a lot of flexibility. I think, you know, one of my main takeaways in terms of the the most what I takeaways as some of the most useful functionality of this package is it's almost like chart annotation.
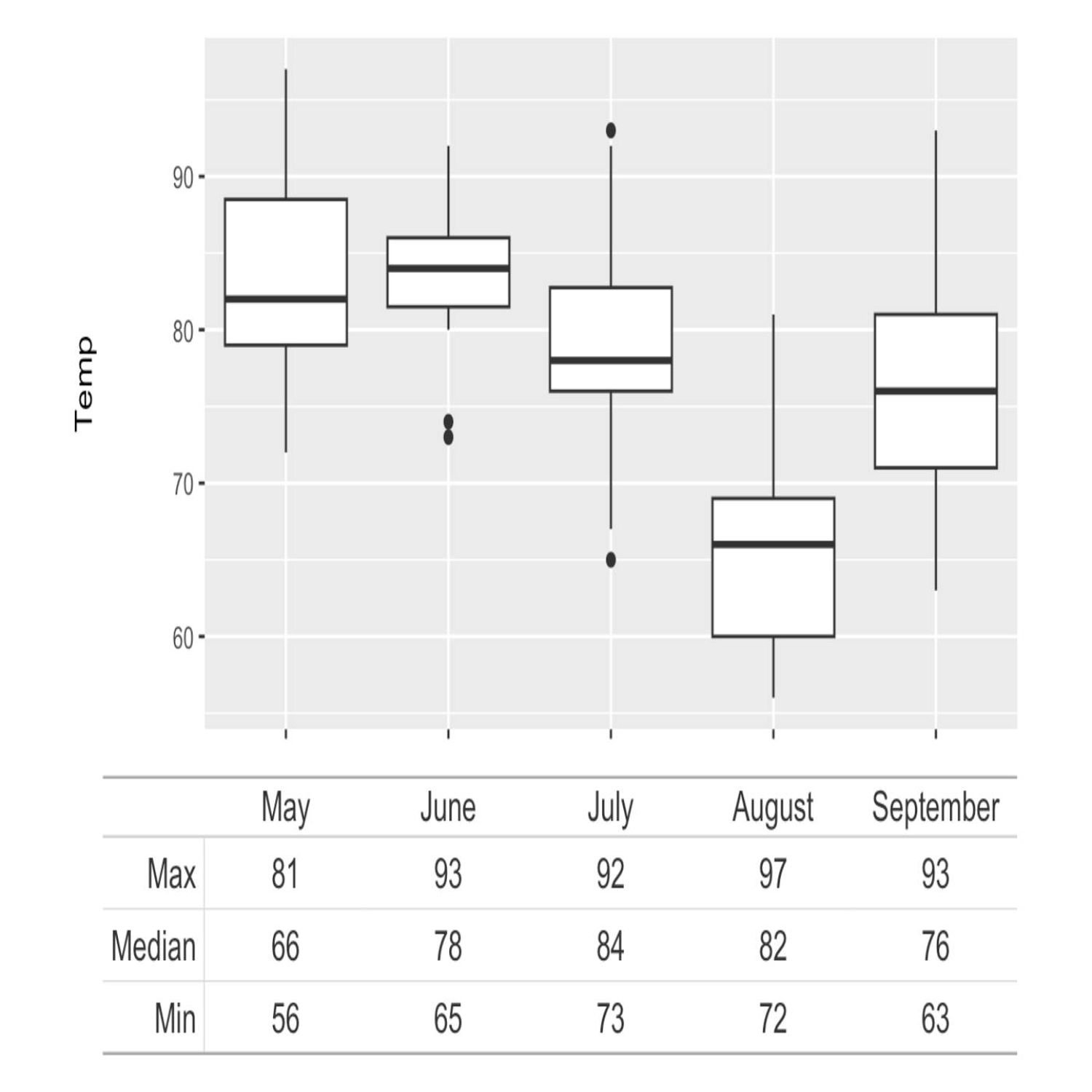
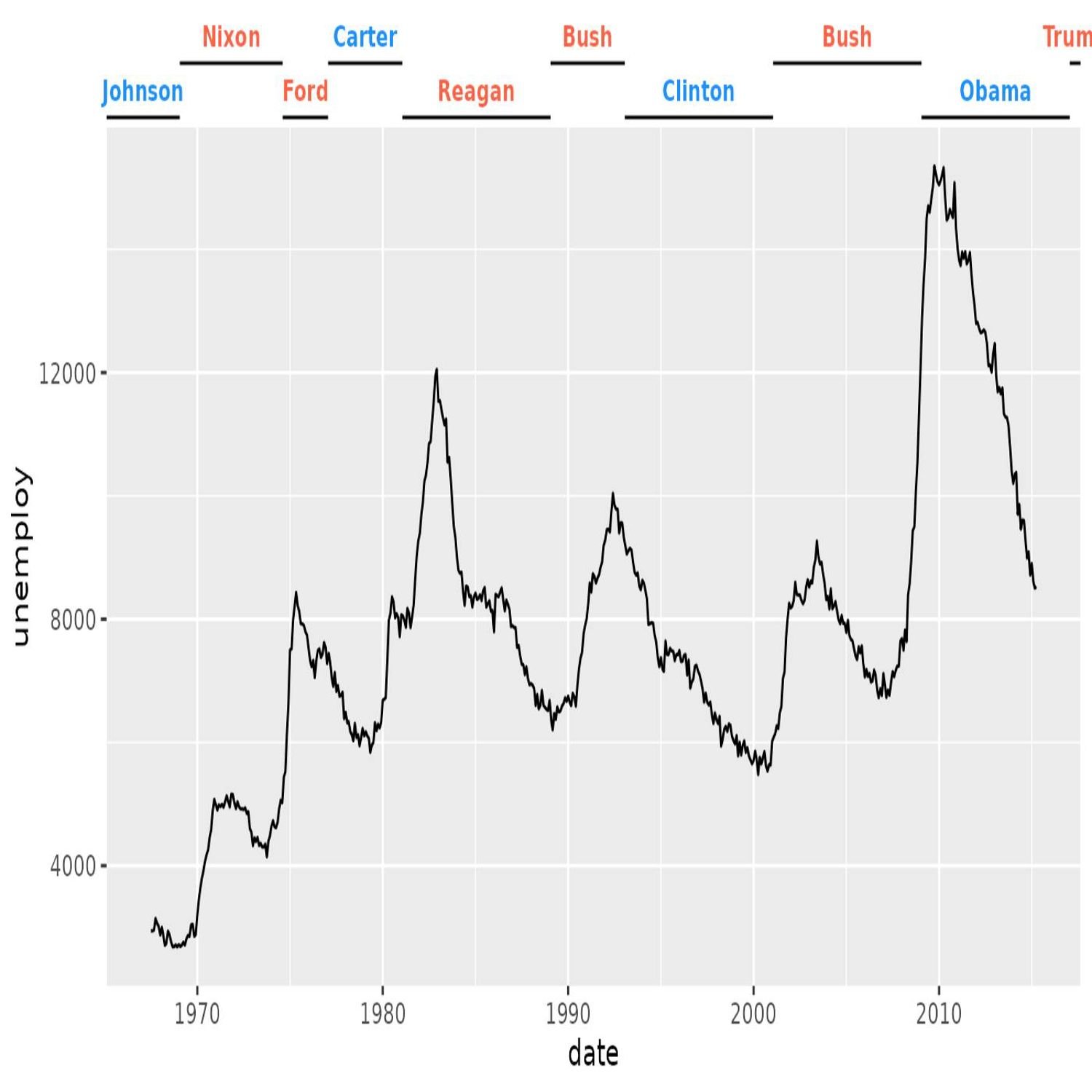
Right? Here's one example in here where, you know, the the x axis is time. It's it's years, and it's some sort of a political, I think it's unemployment. Right? Right? And it's it's, you know, intended to be a political type of chart. And he has these horizontal brackets underneath the x axis values that show the administration, you know, the name of the president at the time, you know, and those those values are gonna change based upon whether they serve 4 years or or 8 years or or different, you know, the the horizontal width of those particular bars. And, you know, I think that annotation is is a really powerful addition to the chart, you know, in regards to the story that you may be trying to tell.
Obviously, the the subgroups as well in the bracketing and the boxes, that we talked about, I think, can be really, really helpful for, again, you know, doing the additional things and custom things that we need in our visualizations to ensure that we're getting our point across as effectively as possible.
[00:23:14] Eric Nantz:
Yeah. I wanna, you know, dive in on that as I've been digesting this more since I read about it. I feel like this is really still trying its best with these additional aesthetic kind of customizations to keep the the the viewer's attention on the main event, so to speak, of the plot itself, but then putting some nice annotations around that main area without you having to really switch context and maybe looking at a a paragraph above below the plot that talks about, like, categories of these color ranges or, like, these different, like, inherent groupings that are comprising these data points, like the time axis or whatnot.
I think this is wonderful from, like, a best practices when you've gotta you've gotta nail that that initial look at these data. And there have been, you know, countless workshops about effective visualization with jigapod too, and those, you know, those great materials by Cedric Shearer and others are still must reads if you find yourself doing this routinely. I feel like this this package, g guidance, is giving us, our users, that don't really wanna dive into the realms of utilizing another program such as Adobe Illustrator or other software to do those, like, fancy customizations you often see in blog posts or whatnot.
Now we can do a lot of that here and especially with making it the striking the balance between overwhelming the user but then not having enough information. I think this is hitting the sweet spot even in this early stage, which I am, you know, thoroughly impressed for. This isn't even on CRAN yet. This is its initial release, I believe, of this package. So I'm I'm I am, like I said, very impressed by this. I'm definitely gonna recommend this both to to future collaborators. I wanna level up their ggplot2 visualizations with these nice annotations, and, of course, I may be using this in the future as well. So job well done, Tone, and, we can't wait to see what's next in this package.
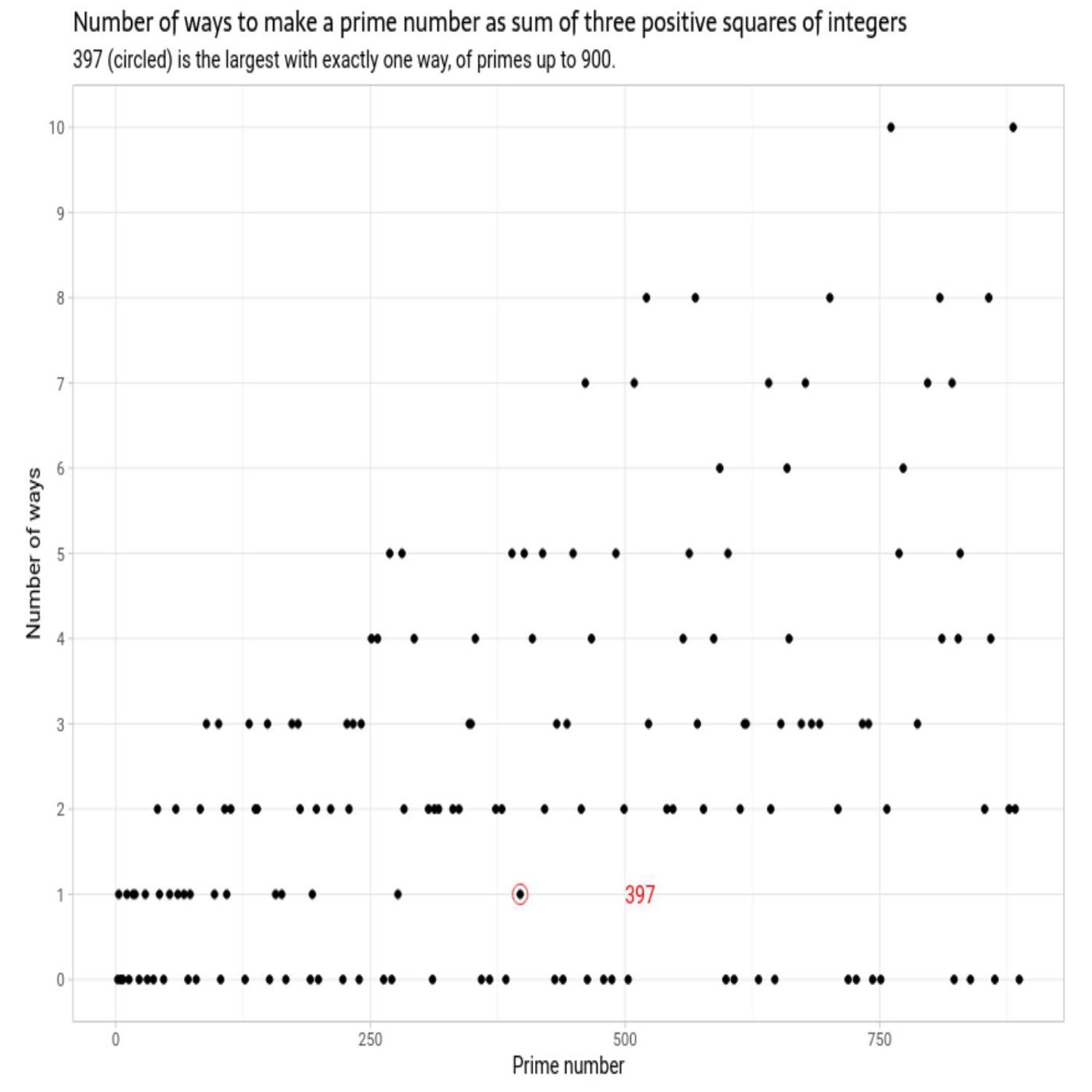
Well, let's, take a little break from our visualization round up there, and we're gonna go back to school a little bit, Mike. And I hope you're ready because you're gonna have to dust off some concepts, ironically, my, oldest son is starting to learn about, in this last highlight here. And this was spurred on by a LinkedIn post that was discovered by Peter Ellis, who actually was featured on the highlights of last episode with his blog post on the Australian Census. Well, he's back in a decidedly different topic this time around, whereas I mentioned, he saw on LinkedIn this post about how a particular number, 397, and this was conjecture to be the largest prime number that can be represented uniquely as the sum of 3 positive squares.
So let's step back a little bit because, you know, I'm gonna dust off my convoys here a little bit. If you're not familiar of what prime number is, this is the concept where there are no smaller numbers other than that number times one that you can use to derive the product of to get to that same number. So a classic example, the number 5. Right? You can't do, like, 2 times 2 or whatever. It's gotta be 1 times 5 or 5 times 1. That's the concept of a prime number. And, Mike, you're gonna keep me honest here. We're talking integers. Integers. Yes. Thank you. Integers. Yeah. Good caveats. Yeah. I knew I'd be rusty on this.
But, as as Peter read this, he wanted in his mind, he's going to change the wording a little bit to this, as being 3 97 is a conjectured largest prime number integer that can be represented as the sum of 3 positive squares of integers in exactly one way. So had I been very much smarter, maybe there would be a way you could figure out a clever mix of linear algebra or other optimization to solve for this in a, you know, rigorous mathematical proof. I'm not one of those people. So, like like, what my approach might be, Peter decides to take matters in his own hands. He calls it a brute force approach, which, actually isn't too brute force, but you can kind of get the logic of this as we talk through it.
He decided to do a couple things for a given what we'll call max integer. He used 30 in this example. He first computes all the squares of those numbers, saves that as a vector. And then for a visualization later on, he's actually gonna leverage a package called primes, which I never heard about until this post, and I did some research on this. This is a package that's authored by, that's authored by Oz Keys, who I have a link to in the show notes, for all sorts of derivations and testing with respect to prime numbers and r. So he's going to have that kind of on the on the back burner, but he's going to leverage the tried and true expand dot grid to take basically all those squares, that vector of squared numbers, and do 3 columns of them that represent the three numbers that have to be added to get to this, you know, magical prime number.
He's gonna expand grid all the combinations of those and then filter for when those are uniquely different from each other and that the the sum of that is 397. And sure enough, when he does that filtering in the blog post, you can see that it's numbers 964324 that get you to that final result. Now that's great for, you know, the smaller cases. Certainly, if you want to beef this up further, yeah, you're going to start needing some processing time. If you go above 30 for the possible other answers, you could derive here. But it's just he does some additional customization to count how frequently some of these other results might happen with these different combinations.
And, say, they're like for the number 54, he found that there were 3 instances where you can satisfy this requirement. But as you think about all the ways to explore this, this could balloon up pretty quick. So to wrap it all up, he's got this nice visual set of visual charts of ggplot2 to look at all the possible prime numbers, with a given range on the x axis and the number of times that these are these are occurring on the y axis or the number of ways that you can derive to that to that particular prime number. And as as you can see, he does a nice annotation on the first one to show where 3 97 wise. And then as you bump up that number from 30 to a much higher, such as 10,000 and then ballooning it up even more, yeah, it's it's gonna it's gonna eat up some horsepower on your machine because, of course, default r is memory based. Right? You're gonna be making this massive dataset of these different combinations. So he conjectures whether we could have, like, a way to fit this nicely into a, like, a database structure, which sounds like a a nice challenge for you readers out there if you wanna try that out. But a nice little exercise that once again with the power of r and its, you know, capacity under the hood, You don't always have to have that fancy mathematician mindset to figure out data driven approaches to these answers. So maybe I give this to my son as a homework assignment one day. I have no idea. There you go. No. It's a nice little brain teaser. I enjoyed it. I thought it was a really unique and interesting post and I I thought the data visualization aspect of it was interesting. I I'm not sure if that's
[00:31:33] Mike Thomas:
an approach that I would have thought of when, you know, trying to solve this problem and and come to this answer and I think it does a great job. We have a few different plots here essentially representing the same exact thing, that really demonstrate that, you know, this number 397 is is the largest number, that is uniquely able to to be, the sum of 3 positive squares of integers and that's that's the the highest prime number, if you will. Like the like the ggplot annotation, the little red circle, around the dot across the three 3 plots, which is really nice. I believe it's just all base ggplot, that we have here and some dplyr code. And it's incredible, you know, sort of simulation based analysis, you know, what we can do with really just 2 packages, dplyr and ggplot.
[00:32:23] Eric Nantz:
Yeah. And this gave me flashbacks to a a project at the day job where we had a situation for smaller sample sizes. We couldn't rely on the normal approximation to help derive some of our probabilities of success and and p value inferences. So we had to make kinda make our own exact type of solution, but we couldn't, like, be exact from a mathematical sense. We had the brute force what you might have had in your classical statistics or data science courses when you're learning about p values for the first time. And maybe this doesn't happen now because yours truly is a dinosaur in terms of the the world now. But we have lookup tables of the p values in the back of our textbooks where, like, the t distribution, the the normal distribution, the f distribution, or whatnot.
And we had to do this kind of thing with our, situation where we made up this distribution, but we did, like, a preconfigured set of configurations of these p values, not too dissimilar to having, like, a configuration of ends in these p value lookup tables of yesteryear. And, yeah, we found out that if we did a bunch of these combinations, our resources, this data frame holding all that would blow up, and it will slow our app down immensely. So we've we fixed that quite a bit in this, upcoming release of this reenvisioning of this app. But I got flashbacks to, like, if you don't have the right answer, sometimes you gotta brute force it somehow, and sure enough, this is another interesting use case of that. And, of course, the real geeky side of me thinks, what if you could do all this in DuckDV and have, like, a huge massive table out of all this that you could explore with, like, a shiny app. What am I thinking? I have no idea. Mike, you gotta watch me on this. I have no idea.
That'd be pretty cool, Eric. Sounds like a challenge. I may have just opted myself into by accident. Nonetheless, what's not an accident? The rest of this issue is no accident and how awesome it is. Right? This is all curated very handily and and very carefully by our curator every week. In this case, it is the aforementioned Tony Elhar Bar. And there's a lot more to this issue, but we're gonna take a couple of minutes for our additional finds that we talk that we, that caught our attention. And for me, it's, as I'm starting to learn more about leveraging AI modeling into my workflows, I'm still very much in my baby steps of this journey.
One thing I have been pretty, you know, passionate about is where we can leverage the open source model tooling and creative ways of utilizing that. So Stephen Turner's recent post on his blog we we featured Stephen in a few highlights ago. He has a great blog post about how you how he was able to create the route the newly released olama3.one.four zero five b, which basically is the way they denote how many parameters, in this case, 405,000,000 parameters. And now he was able to set that up on a GitHub repository to incorporate into Hugging Face to expose as a custom model deployment.
Not something I've ever tried before, and he does warn in the post that with this amount of parameters, the responsiveness is not always great and that there might be alternatives if you really need speed such as using the 70,000,000,000 parameter model instead. But it's another kind of showcase to me, some of the flexibility that we get with these open source models, which in my industry is gonna be something we have to pay a lot of attention to. So I thought that was a pretty clever use of at least one existing platform, but opening the possibilities of what we can do, with these model choices.
[00:36:07] Mike Thomas:
That's super interesting, Eric. It's something that we've been toying around with. So I'm gonna have to take a look at that that blog post as well. I found a great blog, from Shannon Pileggi on her blog called Piping Hot Data. Shout out Shannon. I had the opportunity to meet her in real life at PositeConference this year, which was pretty cool. And she has a very applicable blog post, something that we've wrestled with quite a bit, which is our end and, the sort of repository that you're going to use, CRAN versus POSIT package manager. And if you are not already, using POSIT package manager or, I guess some other service that, you know, maybe our universe that provides binaries, you definitely should with your r n projects. And a lot of times, by default, r n in the lock file, specified is crayon, which isn't always going to install, install binaries of the packages that you need when you run rnd restore.
So Shannon points out this handy file in the rnd this handy function in the rnd package called lock file modify, which allows you to, change your repository, for example, from CRAN to posit package manager. And then there is a second file a second function in r end called lock file write that would allow you to overwrite your lock file with that change, which is pretty cool. One of the questions that I have here, something that I'm gonna have to dive into myself, is to ensure that this would also update, the specified repository in your r n block file that is there for every package as well. So your first entry in your lock file is is typically the repository or repositories that you're going to use. And then and every individual package in your lock file as well also, you know, links to the particular repository, that was specified in that header that you want to use to install that particular package.
As a sort of a cheat, sometimes when we're switching from CRAN deposit package manager, I'll leave the the name or the label of the repository as CRAN, but we'll change the URL from from CRAN to, package manager.posit.co instead, so that we don't have to change all of the package entries. But if there is a much better way than control f and replace all to do that, which it seems like, you know, these functions that Shannon's pointed out for us might be able to accomplish, I am absolutely all ears. So really appreciate, this blog post because I think it's an applicable use case for all users of the r env package.
[00:38:47] Eric Nantz:
Yeah. I've I've done that exact same hack or trick that you caught literally this week as, those of you that well, nobody listened to the pre show of this when Mike and I were exchanging. But the war stories of this with me and my recent shiny test 2 go on headless browser adventures with Docker, that's been a nightmare to deal with. But there was one point where I had to replicate my dev environment to a Docker container. And in my work setup, we have an internal repository that's, like, cram but in our firewall. Of course, that's not gonna play nicely with Docker, especially on GitHub Action. So, yeah, I switched that to positive package manager, but I'm gonna have to take the advice that Shannon has here and see if this is a a more elegant way to dynamically do this instead of being like a, you know, a a silly person and manually do that every time I pivot to a different architecture. So I the the creative juices are going after reading this post for sure.
But, yeah, if you wanna get creative, we invite you to check out the rest of the issue of of our of our weekly. There's a whole bunch of additional content with new packages, new resources, and upcoming events. And in fact, you mentioned Shannon earlier, Mike. She and I will be part of a team that's gonna we don't have the full details ironed out just yet in terms of the timing of it. But later in October, as part of the r pharma conference, we're having a diversity workshop with respect to getting started with version control. So Shannon will be one of the the leads on that. I'll be teaming up with my, fellow RUKI member, Sam Palmer, on a project.
Get those that are new to Git that want a gentle introduction to that up and running. It's gonna be a lot of fun. We're putting all the finishing touches on that, so we'll be able to talk more about that later on. But, yeah, that that's just one of the things that you might find in that upcoming events section along with many other great resources. So how's the best keep the project going? Well, we can do this about you, the community. So any great blog post, resource, tutorial, anything that you think is useful to the r community, whether it's by yourself or by members of the community. We're just a pull request away on our GitHub page, but you can find all that atarwika.org.
A little link to the pull request is in the upper right little ribbon there. It'll take you to the template. Very easy to fill out, all marked down all the time. Very easy to parse that through. And then our curator for the week will be able to get that merged in and be on your way. And, also, we love hearing from you in the audience. We've got a contact page in your podcast, player show notes for this episode. Directly link there. You can also send us a fun little boost with one of those modern podcast apps like Fountain Podverse, Cast O Matic. Lots of great happenings, especially in the fountain ecosystem these days. I'm paying attention to lots of great choices on that. And, also, you can get in touch with us on these social medias. I am on mastodon at our podcast at podcast index dot social.
Also on LinkedIn, just search my name, and you'll find me there. And sporadically on the Weapon X thing, although really not so much anymore. But if you must, I am at the r cast on there. Mike, where can listeners find you? You can find me on mastodon@[email protected].
[00:42:07] Mike Thomas:
You can find me on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k. You can see what I'm up to lately.
[00:42:15] Eric Nantz:
Very good. Always a fun time when you see you see your post on there. But it's always been fun recording with you as always, but we're gonna close-up the docket here before more things get mangled and I respect the setup. So with that, we're gonna say goodbye to this edition of ROK Highlights, and we hope to see you back for another edition of ROK Highlights next week.
Hello, friends. We're back of episode a 180 of the Our Weekly Highlights podcast. You know what? That's a cool number. Maybe we should 180 and call this the SaaS Weekly Highlights podcast. Oh, oh, I get it. No. I'm just kidding. No. No. No. No. Buckle up, folks. We're we're still the rweeklyhighways. I couldn't resist. Anyway, this is the weekly podcast where we're talking about the awesome highlights and other resources I've shared every single week at rweekly.org. My name is Eric Nantz, and I'm delighted that you join us from wherever you are around the world. We're back at our usual recording time. But, of course, just like usual, I never do this alone, at least not unless I'm forced to because I still have my trust to cohost Mike Thomas with me. Mike, how are you doing this morning? Doing well, Eric.
[00:00:47] Mike Thomas:
Had a look a tiny, tiny little time change. I appreciate you being accommodating here, but we're we're getting it in.
[00:00:54] Eric Nantz:
We're getting it in. One way, look like crook. No matter if we're moving or doing chaotic virtual events, we always find a way. Right? Exactly. Exactly. And just like finding a way, our weekly finds a way to release an issue practically every single week, and that is not possible without this being a community driven effort by our curator team. And our curator this week is Tony Elharbar. Of course, he was, made famous a few years ago with his participation in the slice competition. I saw a fond memories of watching that. But, of course, he had tremendous help from our fellow Arrowrocki team members and contributors like all of you around the world with your poll requests and other suggestions. And we're gonna actually, for our first two highlights, we're gonna definitely deep dive into some novel visualization upgrades for your toolbox.
The first of which is a package that has gotten a lot of positive attention since it was released a few years ago. If you've ever been in the situation where you had multiple plots that you wanted to put together in a seamless, like, multi figure, multi panel environment and may and have them be completely separate types of plots, Patchwork is your friend here. Patchwork is the r package that's been authored by Thomas Lynn Peterson, who is a software engineer on the tidyverse team over at Posit. And in particular, Patchwork just had a major new release, version 1 dot 3 dot o. And we're gonna cover a few of the major features landing this release.
And to start off with, I have some good friends in another, industry, we'll call it, named Bubba Ray and D Von. And, boy, they sure like their tables. They were telling me, Eric, get the tables for Patchwork. Well, guess what? We're gonna get some tables for Patchwork because in this release, you are now able to not just put a ggplot2typeplot in patchwork. You now have first class support to put in a table created by GT. GT has made a lot of waves in the table generation ecosystem and r, which, of course, has been authored by Rich Yone, who did a wonderful presentation on the past and the future of GT at Positconf.
But a lot of this feature is possible because of yet more terrific contributions to the open source GT package. This one, authored by Toon Wendenbrand, who will be featured on another highlight later on, but he laid the foundation so that GT objects can now be composed or rendered as GROBs. Where if you're not familiar what a GROB is, that is the underpinning type of object that the system used by ggplot2 is using to compose the plots together in the underpinnings. So with both now a gt object as a GROB and, of course, ggplot2 objects as GROBs, they now can fit seamlessly into patchwork.
And we'll just, I'll cover a couple of the major things about this new feature. And, again, this is brand new, but already out of the box, you're gonna have terrific support to just literally just add this GT object in your patchwork call. Just literally adding the 2 objects together, and you're gonna get the patchwork rendered composition right away. And you get some niceties under the hood or as part of the functions with this because you will now have first class support for adding titles, subtitles, captions, just like you would in a normal GT, and they will show up just fine in a patchwork composition as well.
But if you wanna customize things further for how tables are wrapped into this, there is appropriate enough a function called wrap underscore tables that's gonna let you customize how the table utilizes, say, the space around it. So in Patchwork, each object gets put in what's called a panel. And with this wrap table, you can actually define which parts of the table are fitting into that panel. By default, it's every part of the table, which includes, like, row labels, titles, column headers, and whatnot. But you can actually customize which parts are actually going outside the panel area, such as maybe the top, the left margin, the right margin, and what have you. That's nice if you wanna line things up in a more custom way.
And then also with that, there are some other enhancements as well to how you define the layouts. And what's cool is that it's even gonna be intelligent enough if you're doing, like, a top down composition and your table and your plot are sharing, say, the same variables in, say, rows or columns. They will automatically kinda line up next to each other. So your your eye can visually track maybe that plot at the top with that particular variable and then the table at the bottom and line those values up. It's really slick how they do that. I have no idea how they did it, but it's a lot of awesome engineering around it nonetheless.
And the one the one caveat I wanna mention has to do with accessibility. Because under the hood, when these tables are rendered as GROBs and then put into a patchwork composition, the table is converted to an image PNG representation. Whereas by default in GT, if you're just creating the table, the default output format for that is HTML, which, of course, HTML. You can actually get the text that's representing that table and use that in accessibility type features. So if you are going to put a GT table in a patchwork setup, make sure to especially if it's going in, like, a report, publication, or whatnot, make sure to complete the alt text for that entire patchwork to include not just the text around the plot itself, but also the text around the table. It might take a little getting used to, but if you're already well versed in how accessibility features in GBOD 2 works, it should be a pretty seamless workflow for you. And it will also have a link to the the show notes for additional content with regards to the GT release notes where this, GROB feature landed if you want to learn more about how that worked.
But wait. There's more, as I say, in this Patchwork release. And if you've been looking for a little freedom in your Patchwork compositions, well, that has you covered with a lot of bells and whistles around that, doesn't it, Mike? Yes. It does. And I believe in
[00:07:46] Mike Thomas:
the previous version of Patchwork that was released, there was this new function called free, that was added to the API. And I know that Thomas Lynn Peterson, who I think is is one of the leads on the Patchwork project Yep. Not only talked about, you know, this function at at PasaComp last year, but was also really wanted to be really thoughtful about, you know, how this particular function called free was was going to work and and really careful because, you know, as you noted, Eric, Patchwork does some pretty incredible stuff for us, under the hood that, you know, you and I don't even understand necessarily how it works in terms of aligning axes and and things like that.
So so Thomas wanted to be really careful, and I think that the Patchwork team wanted to be really careful that, they made the correct decisions when it came to how this new free function was going to work. So there's there's some additional arguments, that are now introduced into this free function that allow you to better sort of, align, you know, multiple charts with each other. So one of those arguments is is called side, which allows you to supply either a a character t, r, b, or l. I think that's top, right, bottom, and left characters to indicate sort of which side you want to free up and not necessarily, you know, fix, axes and things like that.
So there's, you know again, we're doing podcasts on data visualization. You're gonna be best served if you take a look at the blog yourself, but he is a great example of, using the side equals l argument to to free up the left side of the plot, while the the right side of the plot sort of stays fixed, if you will, with the the plot below it. There is also, a type possible argument within the free function as well, which prior to, that type argument being introduced when you were putting 2 stacking, you know, for instance, vertically, 2 plots on top of each other, sometimes a plot that had a an axis label, that axis label would be pushed way out, if the other plot above it, if you will, in in this particular example, did not have an access title.
So that that access title in the the one plot that did have an access title was kinda floating way out in space in in situations where you had, long, sort of, access labels, on one plot. And, again, the the blog post does a great job of demonstrating an an example here. So now we have this type equals label, argument that we did not have previously that pushes that axis label on the the one plot that does have the axis title, excuse me, much closer to the axis labels themselves. So it's not that axis title is no longer, sort of, floating out in space, which is is really helpful. There is also a type equals space argument, that sort of just better condenses, from what I can tell, you know, your plots and the the white space in the margins between your plots, which is always something that I've had a tricky time doing, you know, especially when we are trying to in a lot of instances, you know, we might be saving this as some sort of an image file that we're then putting into a a quarto presentation or or something like that.
And, you know, white space becomes very important when you were trying to fit a lot of content on a slide, for instance, or in a PDF. Right? So we have this new type equals space argument that allows us to to better manage that. And I think that there there might be a couple additional bug fixes in this highlight as well, but the new functionality, you know, is is really helpful. I've been doing a lot of work lately, unfortunately, in matplotlib. Some of this stuff is equivalent and possible, but some of it wrestling with with spacing and white space and what are called subplots in matplotlib, is is very, very tricky. And I wish that I had the patchwork,
[00:11:52] Eric Nantz:
package available over there. Yeah. So once you start using it, you don't know how you live without it. I mean, this has been an issue that I wrestle with so much back in my earlier days of helping do a lot of biomarker analysis and creating custom PDF reports so we wouldn't just have one type of plot. We would have multiple types and then trying to get into the grid system to do all the alignment manually. It was a major undertaking. Patchwork is just giving you such a elegant API on that fits so natively with the ggplot2, you know, layered philosophy of the grammar graphics. It it really is hard to replicate this across different different languages. So anytime I need these type of gg plots to be present, especially in a report, yeah, Patchwork is gonna be my go to for it. My greedy ass has been and I've been not the only one asking this, but if you recall, there was some work to create animated ggplot. So ggAnimate that, Thomas took over from David Robinson.
Oh, I'm so greedy. I would love that patchwork work with those, but that's okay. I I can I can wait for that because this is already spectacular in terms of the compositions we are have at our disposal? And now with GT, the possibilities are even more more endless in my opinion. And like many things in the r community, there's a lot of synergy in respect to this issue because our next highlight is coming from that same contributor I mentioned that helped build the foundation for getting GTE pack tables into patchwork. And this next highlight is a brand new art package that has hit the ecosystem authored by Ton Vandenbrand who is a PhD student at the Netherlands Cancer Institute. And, apparently, he's been working on a lot of ggplot2 stuff in his previous open source efforts. But in particular, this new effort is a new r package called gguidance.
I have to catch myself from saying ggguidance because of ggplot2, but, you know, hopefully, I got it right. But, nonetheless, if you've ever wanted or found yourself in a situation where, yeah, you get a lot of nice customizations already out of the box with respect to your guides and other aspects of how you, you know, customize your axes, labels, and your legend attributes in ggplot2, the vanilla version of it. G guidance is gonna give you kind of a more elegant way to bring some additional customization with some of its own versions of these guides.
And the and this, vignette that we're gonna be highlighting here and that we'll put in the show notes as well as a nice summary of 2 kind of major categories of these features. I'm gonna lead off with these really great functions that are prefixed with guide underscore axis. So these are tailored towards bringing some additional formatting possibilities to the way your axis labels and tick marks are specified. The first of which is guide axis custom. And this is great for when you have, you know, your typical two dimensional plot with an x and y axis, and those axes are some kind of positional type metric, maybe a discrete scale or or a bin to continuous scale.
And this is great when you want to add a little customization to it. Say one of the things that comes out of the box is on the tick marks. You can add what are called bidirectional tick marks where, again, as an audio podcast, it's gonna be hard to hard to say this, you know, very clearly, but it gives you kind of both the the line at the bottom of that or the axis line and above it as well. So in case you want that additional that visual cue of where the axis label tick actually starts, that's a it's a nice little visual cue around that. But the real selling point in tones of vignette here about this function comes when you decide in your plot to switch maybe the coordinate system going from, say, the typical scatterplot like x y, you know, 2 dimensional layout to a more radial, you know, type, you know, circle layout.
In the past, you would have to also modify the guide yet again in your usual route to call when you switch those coordinate systems. But with Guide Access Custom, it is intelligent enough to know when you switch that coordinate type of system, and you don't have to customize it any further. So there's a great example in the in the vignette here where he goes from, like, the scatterplot type visualization to a, to a radio plot, but he could keep the guide, access call exactly the same. That's pretty handy when you have to switch these, you know, on the fly with a lot of friction in between. And then another really neat feature, and I don't remember when this landed in Jigetwapattu proper, but now on your axes you can have nested axes where maybe you have in the case of the in the vignette here you've got a bar a stat a bar chart where you've got different flavors of a product of food maybe, you know, coffee, tea, apple, pear, or whatever.
And then you've got a more overarching category for these. So you can put that overarching category underneath the appropriate labels, and you can do this with ggplot2 proper. But what, is offered in this package is a way to customize how you're exactly doing that categorization, or maybe you have a leftover category in your nested top, you know, sublevel, and you don't care about putting that under any top level. So you just wanna leave that blank. You can do that by manually defining a key of these labels as a simple data frame like setup.
But then you can also customize instead of just having a horizontal line that separates these heading or these nested labels. You could have, like, a, like, a curly bracket, or you can have, in fact, up to 7 types of brackets that come out of the box for that separation between the sub labels and the top level labels. And, yes, if you're adventurous enough with creative enough, you can create your own bracket style by feeding in a simple kind of matrix of x and y coordinates. And in the example, he's got, like, a a jagged line instead, whatever you wanna do. That's beyond me. But the cool point is if you really want full control over the visual cues of these nested labels, you've got a lot of power exposed to you with this with this awesome function of guide access nested.
So I'm definitely gonna be checking that one out, but there is a lot more to this with respect to color customization. So, Mike, why don't you take us through what he offers you in this package? Yes. There is. There are these two functions,
[00:19:18] Mike Thomas:
guide call bar and guide call steps, which we'll talk about first, which are are pretty incredible that allow us to be able to either have, you know, sort of this continuous gradient gradient, in our legend, color gradient, or we can have, something that looks more like a discrete color gradient, where we have, you know, specific sort of bins, for the particular colors that we're going to show, in our legend that correspond to the colors that are shown on the plot as well. There's this, notion of caps as well, where you can sort of fix your color scale in your legend and have it bounded with a a lower limit and an upper limit. And then you can have a shape, that also has a corresponding, you know, perhaps different color. In this case, it's it's gray because, he's trying to show that, you know, these values would be out of bounds anything above 30 or below 10, and and he has a triangle on either side of the, the color guide here in the legend to represent, what are called these caps on the the legend or the guide, if you'll which are pretty cool.
You can also, you know, implement those caps as as shapes, and he uses triangles in the example here. But instead of, you know, having them be these out of bounds values, you could have them be, you know, these colors that, sort of, still correspond to your gradient that you're using in your chart. You can cap just one side, either the top or the bottom of the legend, which is pretty interesting as well. Just a lot of different flexibility to do things here. And then sort of similar, Eric, to what you were talking about in terms of brackets, you know, on the axes of the chart, you can also add brackets to the legend. So there's one example here where, he's he's sort of creating brackets on the legend that classify values, in a group a or, you know, if you're higher up in the gradient, then you would belong to to group b. And you can stick those brackets right against, the side of your legend, which is a really, really cool feature, something I had had never really thought about myself as well.
He he has an example here where the legend itself is is radial. It's it's a circle. It kinda looks like a donut chart or or a clock, if you will, where you have this this sort of polar coordinate system for your legend, which is really interesting. I can't think of a use case where I would necessarily employ that over a a legend that's, you know, just just rectangular. But it's it's wild that we have the ability to do that. So a lot of customization here, a lot of flexibility. I think, you know, one of my main takeaways in terms of the the most what I takeaways as some of the most useful functionality of this package is it's almost like chart annotation.
Right? Here's one example in here where, you know, the the x axis is time. It's it's years, and it's some sort of a political, I think it's unemployment. Right? Right? And it's it's, you know, intended to be a political type of chart. And he has these horizontal brackets underneath the x axis values that show the administration, you know, the name of the president at the time, you know, and those those values are gonna change based upon whether they serve 4 years or or 8 years or or different, you know, the the horizontal width of those particular bars. And, you know, I think that annotation is is a really powerful addition to the chart, you know, in regards to the story that you may be trying to tell.
Obviously, the the subgroups as well in the bracketing and the boxes, that we talked about, I think, can be really, really helpful for, again, you know, doing the additional things and custom things that we need in our visualizations to ensure that we're getting our point across as effectively as possible.
[00:23:14] Eric Nantz:
Yeah. I wanna, you know, dive in on that as I've been digesting this more since I read about it. I feel like this is really still trying its best with these additional aesthetic kind of customizations to keep the the the viewer's attention on the main event, so to speak, of the plot itself, but then putting some nice annotations around that main area without you having to really switch context and maybe looking at a a paragraph above below the plot that talks about, like, categories of these color ranges or, like, these different, like, inherent groupings that are comprising these data points, like the time axis or whatnot.
I think this is wonderful from, like, a best practices when you've gotta you've gotta nail that that initial look at these data. And there have been, you know, countless workshops about effective visualization with jigapod too, and those, you know, those great materials by Cedric Shearer and others are still must reads if you find yourself doing this routinely. I feel like this this package, g guidance, is giving us, our users, that don't really wanna dive into the realms of utilizing another program such as Adobe Illustrator or other software to do those, like, fancy customizations you often see in blog posts or whatnot.
Now we can do a lot of that here and especially with making it the striking the balance between overwhelming the user but then not having enough information. I think this is hitting the sweet spot even in this early stage, which I am, you know, thoroughly impressed for. This isn't even on CRAN yet. This is its initial release, I believe, of this package. So I'm I'm I am, like I said, very impressed by this. I'm definitely gonna recommend this both to to future collaborators. I wanna level up their ggplot2 visualizations with these nice annotations, and, of course, I may be using this in the future as well. So job well done, Tone, and, we can't wait to see what's next in this package.
Well, let's, take a little break from our visualization round up there, and we're gonna go back to school a little bit, Mike. And I hope you're ready because you're gonna have to dust off some concepts, ironically, my, oldest son is starting to learn about, in this last highlight here. And this was spurred on by a LinkedIn post that was discovered by Peter Ellis, who actually was featured on the highlights of last episode with his blog post on the Australian Census. Well, he's back in a decidedly different topic this time around, whereas I mentioned, he saw on LinkedIn this post about how a particular number, 397, and this was conjecture to be the largest prime number that can be represented uniquely as the sum of 3 positive squares.
So let's step back a little bit because, you know, I'm gonna dust off my convoys here a little bit. If you're not familiar of what prime number is, this is the concept where there are no smaller numbers other than that number times one that you can use to derive the product of to get to that same number. So a classic example, the number 5. Right? You can't do, like, 2 times 2 or whatever. It's gotta be 1 times 5 or 5 times 1. That's the concept of a prime number. And, Mike, you're gonna keep me honest here. We're talking integers. Integers. Yes. Thank you. Integers. Yeah. Good caveats. Yeah. I knew I'd be rusty on this.
But, as as Peter read this, he wanted in his mind, he's going to change the wording a little bit to this, as being 3 97 is a conjectured largest prime number integer that can be represented as the sum of 3 positive squares of integers in exactly one way. So had I been very much smarter, maybe there would be a way you could figure out a clever mix of linear algebra or other optimization to solve for this in a, you know, rigorous mathematical proof. I'm not one of those people. So, like like, what my approach might be, Peter decides to take matters in his own hands. He calls it a brute force approach, which, actually isn't too brute force, but you can kind of get the logic of this as we talk through it.
He decided to do a couple things for a given what we'll call max integer. He used 30 in this example. He first computes all the squares of those numbers, saves that as a vector. And then for a visualization later on, he's actually gonna leverage a package called primes, which I never heard about until this post, and I did some research on this. This is a package that's authored by, that's authored by Oz Keys, who I have a link to in the show notes, for all sorts of derivations and testing with respect to prime numbers and r. So he's going to have that kind of on the on the back burner, but he's going to leverage the tried and true expand dot grid to take basically all those squares, that vector of squared numbers, and do 3 columns of them that represent the three numbers that have to be added to get to this, you know, magical prime number.
He's gonna expand grid all the combinations of those and then filter for when those are uniquely different from each other and that the the sum of that is 397. And sure enough, when he does that filtering in the blog post, you can see that it's numbers 964324 that get you to that final result. Now that's great for, you know, the smaller cases. Certainly, if you want to beef this up further, yeah, you're going to start needing some processing time. If you go above 30 for the possible other answers, you could derive here. But it's just he does some additional customization to count how frequently some of these other results might happen with these different combinations.
And, say, they're like for the number 54, he found that there were 3 instances where you can satisfy this requirement. But as you think about all the ways to explore this, this could balloon up pretty quick. So to wrap it all up, he's got this nice visual set of visual charts of ggplot2 to look at all the possible prime numbers, with a given range on the x axis and the number of times that these are these are occurring on the y axis or the number of ways that you can derive to that to that particular prime number. And as as you can see, he does a nice annotation on the first one to show where 3 97 wise. And then as you bump up that number from 30 to a much higher, such as 10,000 and then ballooning it up even more, yeah, it's it's gonna it's gonna eat up some horsepower on your machine because, of course, default r is memory based. Right? You're gonna be making this massive dataset of these different combinations. So he conjectures whether we could have, like, a way to fit this nicely into a, like, a database structure, which sounds like a a nice challenge for you readers out there if you wanna try that out. But a nice little exercise that once again with the power of r and its, you know, capacity under the hood, You don't always have to have that fancy mathematician mindset to figure out data driven approaches to these answers. So maybe I give this to my son as a homework assignment one day. I have no idea. There you go. No. It's a nice little brain teaser. I enjoyed it. I thought it was a really unique and interesting post and I I thought the data visualization aspect of it was interesting. I I'm not sure if that's
[00:31:33] Mike Thomas:
an approach that I would have thought of when, you know, trying to solve this problem and and come to this answer and I think it does a great job. We have a few different plots here essentially representing the same exact thing, that really demonstrate that, you know, this number 397 is is the largest number, that is uniquely able to to be, the sum of 3 positive squares of integers and that's that's the the highest prime number, if you will. Like the like the ggplot annotation, the little red circle, around the dot across the three 3 plots, which is really nice. I believe it's just all base ggplot, that we have here and some dplyr code. And it's incredible, you know, sort of simulation based analysis, you know, what we can do with really just 2 packages, dplyr and ggplot.
[00:32:23] Eric Nantz:
Yeah. And this gave me flashbacks to a a project at the day job where we had a situation for smaller sample sizes. We couldn't rely on the normal approximation to help derive some of our probabilities of success and and p value inferences. So we had to make kinda make our own exact type of solution, but we couldn't, like, be exact from a mathematical sense. We had the brute force what you might have had in your classical statistics or data science courses when you're learning about p values for the first time. And maybe this doesn't happen now because yours truly is a dinosaur in terms of the the world now. But we have lookup tables of the p values in the back of our textbooks where, like, the t distribution, the the normal distribution, the f distribution, or whatnot.
And we had to do this kind of thing with our, situation where we made up this distribution, but we did, like, a preconfigured set of configurations of these p values, not too dissimilar to having, like, a configuration of ends in these p value lookup tables of yesteryear. And, yeah, we found out that if we did a bunch of these combinations, our resources, this data frame holding all that would blow up, and it will slow our app down immensely. So we've we fixed that quite a bit in this, upcoming release of this reenvisioning of this app. But I got flashbacks to, like, if you don't have the right answer, sometimes you gotta brute force it somehow, and sure enough, this is another interesting use case of that. And, of course, the real geeky side of me thinks, what if you could do all this in DuckDV and have, like, a huge massive table out of all this that you could explore with, like, a shiny app. What am I thinking? I have no idea. Mike, you gotta watch me on this. I have no idea.
That'd be pretty cool, Eric. Sounds like a challenge. I may have just opted myself into by accident. Nonetheless, what's not an accident? The rest of this issue is no accident and how awesome it is. Right? This is all curated very handily and and very carefully by our curator every week. In this case, it is the aforementioned Tony Elhar Bar. And there's a lot more to this issue, but we're gonna take a couple of minutes for our additional finds that we talk that we, that caught our attention. And for me, it's, as I'm starting to learn more about leveraging AI modeling into my workflows, I'm still very much in my baby steps of this journey.
One thing I have been pretty, you know, passionate about is where we can leverage the open source model tooling and creative ways of utilizing that. So Stephen Turner's recent post on his blog we we featured Stephen in a few highlights ago. He has a great blog post about how you how he was able to create the route the newly released olama3.one.four zero five b, which basically is the way they denote how many parameters, in this case, 405,000,000 parameters. And now he was able to set that up on a GitHub repository to incorporate into Hugging Face to expose as a custom model deployment.
Not something I've ever tried before, and he does warn in the post that with this amount of parameters, the responsiveness is not always great and that there might be alternatives if you really need speed such as using the 70,000,000,000 parameter model instead. But it's another kind of showcase to me, some of the flexibility that we get with these open source models, which in my industry is gonna be something we have to pay a lot of attention to. So I thought that was a pretty clever use of at least one existing platform, but opening the possibilities of what we can do, with these model choices.
[00:36:07] Mike Thomas:
That's super interesting, Eric. It's something that we've been toying around with. So I'm gonna have to take a look at that that blog post as well. I found a great blog, from Shannon Pileggi on her blog called Piping Hot Data. Shout out Shannon. I had the opportunity to meet her in real life at PositeConference this year, which was pretty cool. And she has a very applicable blog post, something that we've wrestled with quite a bit, which is our end and, the sort of repository that you're going to use, CRAN versus POSIT package manager. And if you are not already, using POSIT package manager or, I guess some other service that, you know, maybe our universe that provides binaries, you definitely should with your r n projects. And a lot of times, by default, r n in the lock file, specified is crayon, which isn't always going to install, install binaries of the packages that you need when you run rnd restore.
So Shannon points out this handy file in the rnd this handy function in the rnd package called lock file modify, which allows you to, change your repository, for example, from CRAN to posit package manager. And then there is a second file a second function in r end called lock file write that would allow you to overwrite your lock file with that change, which is pretty cool. One of the questions that I have here, something that I'm gonna have to dive into myself, is to ensure that this would also update, the specified repository in your r n block file that is there for every package as well. So your first entry in your lock file is is typically the repository or repositories that you're going to use. And then and every individual package in your lock file as well also, you know, links to the particular repository, that was specified in that header that you want to use to install that particular package.
As a sort of a cheat, sometimes when we're switching from CRAN deposit package manager, I'll leave the the name or the label of the repository as CRAN, but we'll change the URL from from CRAN to, package manager.posit.co instead, so that we don't have to change all of the package entries. But if there is a much better way than control f and replace all to do that, which it seems like, you know, these functions that Shannon's pointed out for us might be able to accomplish, I am absolutely all ears. So really appreciate, this blog post because I think it's an applicable use case for all users of the r env package.
[00:38:47] Eric Nantz:
Yeah. I've I've done that exact same hack or trick that you caught literally this week as, those of you that well, nobody listened to the pre show of this when Mike and I were exchanging. But the war stories of this with me and my recent shiny test 2 go on headless browser adventures with Docker, that's been a nightmare to deal with. But there was one point where I had to replicate my dev environment to a Docker container. And in my work setup, we have an internal repository that's, like, cram but in our firewall. Of course, that's not gonna play nicely with Docker, especially on GitHub Action. So, yeah, I switched that to positive package manager, but I'm gonna have to take the advice that Shannon has here and see if this is a a more elegant way to dynamically do this instead of being like a, you know, a a silly person and manually do that every time I pivot to a different architecture. So I the the creative juices are going after reading this post for sure.
But, yeah, if you wanna get creative, we invite you to check out the rest of the issue of of our of our weekly. There's a whole bunch of additional content with new packages, new resources, and upcoming events. And in fact, you mentioned Shannon earlier, Mike. She and I will be part of a team that's gonna we don't have the full details ironed out just yet in terms of the timing of it. But later in October, as part of the r pharma conference, we're having a diversity workshop with respect to getting started with version control. So Shannon will be one of the the leads on that. I'll be teaming up with my, fellow RUKI member, Sam Palmer, on a project.
Get those that are new to Git that want a gentle introduction to that up and running. It's gonna be a lot of fun. We're putting all the finishing touches on that, so we'll be able to talk more about that later on. But, yeah, that that's just one of the things that you might find in that upcoming events section along with many other great resources. So how's the best keep the project going? Well, we can do this about you, the community. So any great blog post, resource, tutorial, anything that you think is useful to the r community, whether it's by yourself or by members of the community. We're just a pull request away on our GitHub page, but you can find all that atarwika.org.
A little link to the pull request is in the upper right little ribbon there. It'll take you to the template. Very easy to fill out, all marked down all the time. Very easy to parse that through. And then our curator for the week will be able to get that merged in and be on your way. And, also, we love hearing from you in the audience. We've got a contact page in your podcast, player show notes for this episode. Directly link there. You can also send us a fun little boost with one of those modern podcast apps like Fountain Podverse, Cast O Matic. Lots of great happenings, especially in the fountain ecosystem these days. I'm paying attention to lots of great choices on that. And, also, you can get in touch with us on these social medias. I am on mastodon at our podcast at podcast index dot social.
Also on LinkedIn, just search my name, and you'll find me there. And sporadically on the Weapon X thing, although really not so much anymore. But if you must, I am at the r cast on there. Mike, where can listeners find you? You can find me on mastodon@[email protected].
[00:42:07] Mike Thomas:
You can find me on LinkedIn if you search Ketchbrook Analytics, ketchb r o o k. You can see what I'm up to lately.
[00:42:15] Eric Nantz:
Very good. Always a fun time when you see you see your post on there. But it's always been fun recording with you as always, but we're gonna close-up the docket here before more things get mangled and I respect the setup. So with that, we're gonna say goodbye to this edition of ROK Highlights, and we hope to see you back for another edition of ROK Highlights next week.