Hide a picture of Homer Simpson in a residual plot of all places? Oh it's real, you could say "surreal!" Plus a data-driven approach to investigate recent changes to the Australian census, and a cautionary reminder to check just where those numbers are coming from the next time you build a prediction model.
Plus the quest to make R the official language for the Coder Radio program reaps a new reward!
Episode Links
Supporting the show
Plus the quest to make R the official language for the Coder Radio program reaps a new reward!
Episode Links
- This week's curator: Ryo Nakagawara - @RbyRyo@mstdn.social (Mastodon) & @RbyRyo) (X/Twitter)
- {surreal} 0.0.1: Create Datasets with Hidden Images in Residual Plots
- Gender and sexuality in Australian surveys and census
- Please Version Data
- Entire issue available at rweekly.org/2024-W38
- Surfing the WSL Wave - Coder Radio episode 587 https://www.jupiterbroadcasting.com/show/coder-radio/587/
- Brian (bhh32) on Nostr
- surreal https://r-pkg.thecoatlessprofessor.com/surreal/
- Residual Plots and Data Sets (archived version) https://web.archive.org/web/20210927100125/https://www4.stat.ncsu.edu/~stefanski/NSFSupported/HiddenImages/statresplots.html
- Labels for Technical Writing Projects https://ropensci.org/blog/2024/09/12/labels-writing-projects/
- Express to Impress: Leveraging IBCS Standards for Powerful Data Presentations https://medium.com/number-around-us/express-to-impress-leveraging-ibcs-standards-for-powerful-data-presentations-3c3a269f0ec0
Supporting the show
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @rpodcast@podcastindex.social (Mastodon) and @theRcast (X/Twitter)
- Mike Thomas: @mikethomas@fosstodon.org (Mastodon) and @mikeketchbrook (X/Twitter)
- Moonlight Vibin' - Mega Man X5 - DCT - https://ocremix.org/remix/OCR02053
- You Are Not Confined - Final Fantasy IX - Sonicade - https://ocremix.org/remix/OCR01064
[00:00:03]
Eric Nantz:
Hello, friends. We're back with us on a 179 of the R Weekly Holidays podcast. We're a day late because yours truly was, busy with other, production stuff with a virtual conference that just happened yesterday, which you might touch on a little bit later. But, nonetheless, we are excited to have you here for this weekly show where we talk about the latest highlights and other resources that are shared on this week's Our Weekly Issue. My name is Eric Nantz, and I'm delighted you join us from wherever you are around the world. And, you know, never a dull moment in your in his life, but my awesome co host, Mike Thomas, is here with me. Mike, how are you doing? I'm doing well, Eric. Busy busy busy as as usual.
[00:00:41] Mike Thomas:
In the process, I think I said this last week of of selling a house, so I'm currently in a room that doesn't have much furniture. It's quite echoey. So hopefully that doesn't come through too bad for the listeners this week.
[00:00:52] Eric Nantz:
We, completely understand, and, yeah. We we hope that that gets more stable for you soon enough, but luckily, we can give you at least a few minutes here to live vicariously through these great resources we have shared for you, this this episode. And before I go on further, I wanna share a little up follow-up to what I teased last week with some of these other podcasts I've listened to and our quest to get the r language to dominate all the things in software development. Well, I'm happy to share that, our quest to get r as the default language for Decoder Radio Show is working very well, so much so that we earned the perk of having a custom song generated for the r language on the Dakota radio program, which I am going to play for you right now.
[00:01:47] Unknown:
Down by the meadow under the banyan tree where old folks gather jabber and take their tea. Talking about numbers, trends to foresee in the world of digits, none purer than thee. And visions divine. Your cold unwrapped stories line by line. Oh, Oh, sweetheart, silent has the dew in the world of 1s and zeros. You're a lighthouse true. When umbers sing and scatter plots bloom through dire slapper and few lead us past gloom.
[00:03:00] Eric Nantz:
And a huge shout out to Brian who goes by b h h for creating that song. And I'll have a link to his profile on Nastur in the show notes as well as the Coda Radio episode, where this came from, if you wanna learn more. Us and the r, you know, community and data science, we tend to we tend to be pretty chill about a few things. There aren't a lot of things that rattle us, and I think I think that suits us quite well. So job well done when we couldn't thank the program enough. And and, yeah. So that was awesome. Nonetheless, we're gonna move on here with the rest of the show here, and our issue this week was curated by Nariel Nakagura, another one of our longtime curators on the ROV team. And as always, he had tremendous help from our ROV team members and contributors like all of you around the world with your poll request and other suggestions.
So we're gonna start off with a visualization a visit to our visualization corner, you might say, in ways that you definitely would not expect. So this harkens back to my days when I was a TA in graduate school where most of the time I was helping in our computation lab, doing some cool at that time, building some innovative r stuff with, I still remember these days using, like, the LAMP stack and doing custom databases and randomly generated exams and whatnot. But there was a semester I had to teach the intro stats course. And, of course, it can be difficult to get the students engaged, especially when you get to, you know, some of the more harder concepts like regression model fitting, trying to make sure you're instilling in in the students the fact that, well, you can come up with the terms in the model, but you do want to check how those models are performing with some various mix of normality assumption tests and also tests about the quality of the model.
Oftentimes, we would use a classic type of visualization, plotting the residuals of your model against the fitted values and looking for any distinct patterns. Or, hopefully, you don't see a pattern, which means that your assumptions are are working well. Well, what if to motivate students to do that kind of checking, you give them a little, hidden Easter egg, if you will, throughout that process? And that's exactly what this first highlight is doing in the form of, you guessed it, an R package that has a lot more behind the scenes here. So we are talking about the latest package called Surreal, awesome name, by the way, authored by James Balamuta, who goes by the cultless professor on social media and LinkedIn. Always enjoy his work. He's also been hugely instrumental in incorporating Quirter and WebAssembly and WebR alongside George Stagg. So I always follow what James does, but this came kind of out of left field on my media feeds and, hence, in our our weekly issue.
But this is a package that gives you data sets that, on the surface, may not seem like very much. It's data sets in x and y coordinates. But when you fit a visualization about those or fit a model around those and you look at the observed, you know, or let's just say the predicted and the residual plot, you can embed basically a hidden image or even text in that actual plot. This is this is mind blowing, but let's let's give some more context here. This stems from research from back in 2007, approximately around that time, by a professor Leonard Stefanski.
He was at NCSU or North Carolina State University back at that time, and he wanted a way to motivate his students to learn about these different model assessment techniques. And one of those, like I said, is that visualization of the residuals versus predictive values. And he came up with a clever algorithm that I'll try to describe, but in essence, you want you know what kind of image or text you want the student to see in this plot. So you start with that, and then you use a a mix of image processing and and some other extraction processing.
So you get, like, a black and white version of that image. You feed that into programs such as ImageMagick or whatever. So you can get on a two dimensional plane kind of like the x and y coordinates of what maybe the black dots are that comprise that image or text as compared to the white, like, the the background, if you will. So then if you also, depending on the image itself or the text, you are he's and his algorithm goes by assuming that the product of the residual vector, if you transpose that and multiply that with the fitted or predicted value, vector in matrix multiplication, that that product is 0, meaning that the residual and the predictive value vectors are orthogonal.
That's another assumption we see in things like principal component analysis and whatnot. But when you go by that, you can come up with an iteration algorithm to introduce new data that meets that requirement that may have 1, 2, 3, or more of these explanatory variables or predicted variables against an outcome variable. So if you do, like, a plot that looks at all these variables together and, like, those pairs plots that we like to do when we have multiple variables, you're not gonna really see much of a pattern to that new data. But then when you do that, that aforementioned visual look at the residuals and predictive value, you're gonna get that original image back. So this, package got a few datasets that correspond to some of these different images that you could that you could use. But I'm also gonna throw in the show notes well, actually, in the in the package site itself, he's got the r logo, the original r logo in this kind of black and white, you know, 2 d dimensional plane. But then when you look at after the transformation that I mentioned, it just looks like a scatterplot of 5 variables against the y, but looks like kind of random blobs really. Nothing nothing discernible here, but it's a hidden image of looking at the quality of the model where you start to see that actual, you know, Easter egg type image.
So there are other datasets here too. He even shows how to do a custom message saying r is awesome. We always agree with that. But then the one I'm gonna throw in the show notes is an archived version of Leonard's, I guess, original site that had more datasets that were fed into this, including some fun, Homer Simpson images and many others that you would not expect in a scatterplot that ends up being there. So if you want more background on just how this all came to be, check out that archive site. And I believe through that, you'll also be able to dig into finding the manuscript and a presentation that this professor did way back in the day.
So if you're looking for ways to engage your students on teaching regression principles, you wanna give them a little fun along the way, like, I wish I'd done back in 2,005 ish when I was doing a TA work on this. I would have loved to have had this to be a way to motivate the students, but real fun package. I can't wait to put some hidden things maybe to do, some pranks on my colleagues at work. I don't know. Could be fun nonetheless. But, Mike, you're gonna do some new residual plots out of this.
[00:10:49] Mike Thomas:
Oh, for sure. We'll stick this in all of our model validation reports at the end. Just some nice Easter eggs for our clients. And just when I think just when I think the art community, you know, can't come up with anything more creative than the last thing that we came up with, a package like surreal drops. And the project I I had never heard about, you know, Stefanski's work back in 2007. And it sounds like there are some earlier art implementations as well, by a few folks, John Stoudenmeyer, Peter Wolf, and Yul Ricky Gromping, who maybe attempted to to try to do the same thing. And the fact that you can stick, you know, images or messages here in your residual plots is pretty cool. And I I agree, Eric. I think, you know, a a really fun utilization of this package and a real good application for it would be in the classroom for, you know, statistics professors trying to teach, how to analyze, you know, model fits and to look at residuals.
I think that would be a pretty fun thing for your students to be able to to see. So this might be, you know, applicable for them and and interesting to them, and it's just, you know, another sort of example in the art ecosystem of all of the different crazy things that we can do with the art language.
[00:12:04] Eric Nantz:
Yeah. Like I said, this this came completely out out of the blue, but, oh, it's just amazing with a little math knowledge what you can accomplish in these in these, assessments. So I I got I told Mike in the pre show, I went down a little rabbit hole last night looking at all these different images that have been generated. There's some real comical ones there, even some nice messages about, you know, George, Box is famous, all models are wrong quote, and many other little things that, again, may get the students thinking not just about how did how is this actually accomplished, which, again, if you look at the manuscript in your spare time, you'll see there is a lot of clever matrix multiplication and iteration here. Like, the this this would have been a fun way in my linear algebra class to learn some of these concepts. But, again, I I I'm I'm in dinosaur age, so to speak. So this even predates that research when I was learning that stuff. But, yeah, this I think this could be great for especially in this day and age where I'm sure there's gonna be more models that are thrown to us may or may not even be generated by humans these days that looking at the integrity of these models, no matter machine learning or in the classical regression sense, is hugely important. So whatever we can do to to spark that light bulb in in students' minds and even those in in the field that are working daily, I'm all for it. So credit to James for putting this through. And, again, I'm I I can't wait to play this more. Yeah. This is like Anscombe's
[00:13:31] Mike Thomas:
quartet on steroids, sort of. And for the folks who are feeling festive or may celebrate Halloween, there is a function in the surreal package called jack o'-lantern surreal data. That's a built in dataset that you can use such that your residuals, when plotted, show a nice jack o'-lantern right in the middle of it.
[00:13:50] Eric Nantz:
That is awesome. Yeah. I think that'll be a good thing for my kids to say, oh, hey. Guess what I can do with r? And they'll be like, no. We want the real pumpkin. But you know what? But
[00:14:13] Unknown:
whatever.
[00:14:15] Eric Nantz:
And, in this next highlight, there's definitely been a lot of news that's been happening across the the pond, as I say, with our, friends at Australia with a recent update to the census that our next highlight is looking at a data driven way to look at the impact of additions in questions, really get a feel for how you can segment populations and looking at different differences amongst them. But, again, taking a data driven approach that I think we all can learn from. And this next highlight comes from Peter Ellis, who is the director of the statistics for development division at the Pacific Community.
So he's also based in Australia, but he in his latest blog post is looking at a recent addition, pushback and then readdition to certain questions in the 2021 ABS standard, which is, I believe, the Australian Bureau of Statistics and their recent update to the census and some of the discourse that follow through with that with respect to sex and gender variations and characteristics that they were trying to measure in an updated census. There was some pushback, and then apparently they've been reintroducing some of these questions dealing with, you know, what is a person's gender, how does that person describe their sexual orientation, and has that person been told that they were born with a variation of sex characteristics.
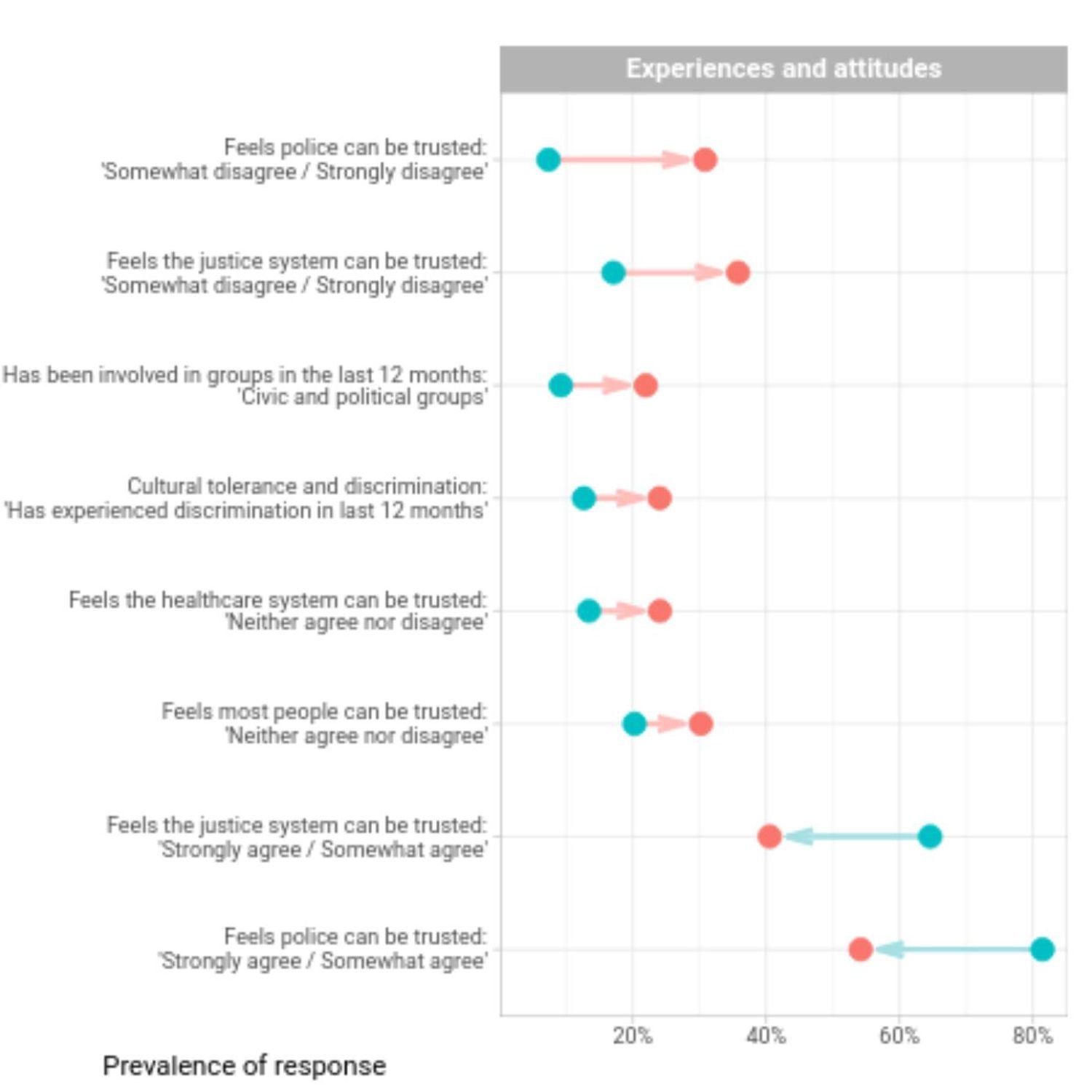
So certainly a a major topic around the world. But he wanted to not just, you know, react to the discourse that's online. He wanted to really dive deeper into with what we currently have, what is a way to convey the impact of trying to accurately distinguish some of these populations and seeing what that relates to other questions in the census itself. So, Peter does a great job in background, which, again, we'll invite you to check the preview or check the link yourself if you wanna read more background. We're gonna dive into more of the data analysis side of it where this is a very much a tidyverse inspired workflow with a real world use case of importing spreadsheet data from the from the ABS in a spreadsheet. So again, that's very common in the in this part of the world of of data analysis. So he's using the read excel package, one I've used great with great success in importing this type of data with a bit of, tidyverse cleaning up with a little bit of filtering for making sure they're getting non missing values and as well as different derivations of variables, a little bit of grouping. So again, pretty, pretty logical. We get to a dataset, eventually leads to a visualization that when you read the blog post, you're gonna have to zoom in on this a little bit. But Peter is trying to illustrate some of the key differences as measured by the data between the LGB plus and the heterosexual Australian responses on this survey from back in 2020 and then seeing what what impact that would be in various questions. And you do expect there will be some differences not just in the in the age categories but also responses such as, like, family composition in their household, income questions, and the like. But he's using a pretty nice kind of, I think, pseudo lines, you know, dot chart but showing the the difference in in arrows pointing at the the shift from the heterosexual side to the LGB plus side of it. So you can kind of see where the wider differences are.
But he says he struggled with how to put this plot more accurately, and he went through quite a few iterations on that. So at the end of the post, he's got kind of what led to that final visualization, a set of faceted bar charts that are basically looking at each of those questions individually in different categories as well as the facets. So you can get a good read on that as well. But he was trying to distill some of the findings from this side by side bar chart analysis into this line plot as well. So as as I said, you can kind of see different types of domains are showing a wider differential in terms of percentages, which again may or may not be expected. But I'm always up for letting the data tell the story and and certainly, hopefully, that in the future, the the census from anywhere in the world is able to accurately portray these different populations that, again, deserve their voices to be heard. So really, really great summary here by Peter. Definitely a lot to digest if you're looking into the space of census analytics.
I think a lot of good ideas to follow here. And again, great visualization, great reproducible code that you can run yourself if you want to import this data. And I'm sure similar techniques could apply to other, census data that's from available around the world. So great post by Peter, and I look forward to learning more about this space.
[00:19:34] Mike Thomas:
Yeah. I thought it was an excellent post as well. Eric and I appreciated the the two different approaches, in terms of data visualization to to representing this data. In the past, you know, when we've worked with survey data, it's for whatever reason, seems to be a little bit more tricky to work with than some of your traditional datasets, you know, that are exported out of a, you know, a database system that is the result of users entering data into your application or something like that. Right? There's a lot of, pivoting, reshaping, you know, some some filling, NA values as well, you know, some work, deciding between whether you want to use a continuous or discrete scale when you have Likert scales and and things like that going on. So I I certainly appreciate, you know, the work that went into curating this data into the visualizations that it became. This is also another reminder for me that I need start leveraging, you know, whether you wanna call them lollipop charts or donut or or, barbell charts or things like that. But, it's this might be the first time that I've ever seen a chart like this, which I think you might call, like, a barbell chart that has two dots, for each line on the y axis representing, you know, the differences between 2 categories in the legend.
And then there is actually an arrow, pointing the direction that it it, you know, increased or decreased. And, typically, I I I feel like in a lot of these charts, I've seen a line, just a straight line with no arrow on it, connecting those 2 each of those two dots. But the fact that, he was able to to employ an arrow here in this visualization was was really, really cool to me. You know, again, sort of demonstrated the the power of ggplot and the fact that that arrow is is colored the same as the the dot that it, you know, sort of is trying to represent the most, but there is also a little alpha component too that makes it a little more subtle than the dot itself. I think it's just a a really nice sorta chef's kiss, on top of that particular data visualization. And, you know, as always in a lot of these blog posts, the the ggplot code is all there. The dplyr data wrangling code is all there.
So it it's it's fantastic in the way that it it ends with this nice faceted bar chart as well. Man, I was working in Python, this week and was using the plot trying to use plot 9. Unfortunately, for a a donut chart, wasn't able to use plot 9 and had the to switch over to matplotlib instead. And I wanted to facet, you know, have these these faceted plots as well. And it's just not quite as easy as, you know, that that one beautiful facet wrap or facet grid, function that we have in ggplot. So it gave me that additional appreciation that, I I always have for for ggplot in the r language, particularly. But fantastic blog post talk top to bottom here, and and love the data visualization.
[00:22:30] Eric Nantz:
Yeah. We've always been spoiled in this community with the the power of visualizations both on the static variety and the interactive variety. So there's, yeah, there's a there's a lot going on in in the code here, but, yeah, I definitely invite you all if you're interested in replicating this to take a look at Peter's code here and and give it a spin for for your next, opportunity for these cool little barbell plots. So, yep, really, really powerful visualization and looking forward to seeing more in this space. And our last highlight today is going to be a healthy mix of some of the additional questions or items that I mentioned in our first slide about modeling techniques. But being careful about the data you're using in your model is definitely a key motivating factor for this this last highlight we have today, which is coming to us from John Mount, who is one of the principal consultants at WindVector LLC, the consulting resource. And they've historically have had the WindVector blog, which, I've been reminiscing about this in previous episodes about what were some of my original resources learning are back in the early 2000 mid 2000. But, John Mount's blog has been right up there as one of the resources I've had bookmarked for many, many years. So it's always great to see posts from him come to the highlights here. But he is motivating a situation that's been inspired by real projects where there can be a bit of a disconnect between the data scientists and analysts performing modeling for prediction and perhaps data engineers that are supplying this data that maybe aren't giving you the full information, so to speak. So in his example that's inspired by real things but kind of more fictitious is that you have, an issue where maybe you wanna run a prediction on forecast, I should say, attendance at a movie theater, and you wanna incorporate attendances from past, you know, events or past movies as part of that along with other factors that might drive that, you know, that influence in the prediction.
So you may be getting from a data engineer or data warehouse, whatever have you, some metrics for each of the dates and each of the movies that were showing in that date, the time of it, and the number of people that attended that. So he's got starting the post, a little example of reading a hypothetical CSV file where we've gotten the month in the month of August, you know, a few movies. I'm not sure these are real names but whatnot, but with the attendees. And you can see there is quite a bit of variation in some of these attendance metrics, which, of course, could be the quality of the movie, but could be other factors. But to motivate the goal of building a model that relates the attendance to one of the key you know, maybe one of the key perks in a movie theater these days or always has been is how much popcorn you sell and whatever snacks you sell. Maybe that is a driver that someone might wanna look at. There could be other factors too along with that.
But but one thing to note is that when the the engineers look at what's going to happen in the future, there could be a disconnect between the type of data. Historical data is looking at the actual numbers of attendees, but the stuff that's being estimated is, of course, not known yet. So continuing on with the example, imagine that they look at the different popcorn sales. They they merge that with the attendance dataset. You're doing what looks to be a pretty decent, you know, model fit with the data you have. But now when you start to do predictions, when you look at the month of September and knowing that the month of September is giving you slightly different types of values and you see that the estimates are in the line plot that he shows here really inflated, like massively inflated from what we see the model saying in the previous month of August. So and the takeaway is that the model is predicting or predicting popcorn sales in the future are going to be double what they see in the month of data that they use to train the data.
That doesn't quite check. So doing a little diagnosis, doing some nice little distribution plots, you see that the pattern of attendance doesn't look anything alike. They look heavily skewed in September compared to the more balanced month of August. And why is this? Well, the estimated attendance figures in September were based on the capacity of the movie theater, the number of seats inside, which is different, of course, than what the actual measures were back in the month of August where they used actually the number of people sitting in the theater at that time. So this is illustrating a case where maybe there's a bit of a disconnect in terms of the type of data that's going to go into your forecast versus the type of data you're using to train the data. So to motivate what John would do in this, you know, solving the issue, instead of using the actual number of movie attendees in August, he recommends moving using the capacity of the theater as additional or replacing the metrics with the capacity numbers instead. And when you do that, then you get data that looks more realistic in his opinion compared to what we saw before.
So my takeaway from this is being consistent with the type of measures you're incorporating in both your training and then eventually your your val your validation or your future prediction set as compared to mixing the different types up. Even though they are technically the same variable, they are in much different context. So this is something I haven't really encountered myself because I'm not as much into the forecasting realm of it, But I could definitely see how this might be a bit of a monkey wrench to a certain, you know, say, to scientists or statistician that see such wildly different metrics when they look at their predictions versus what they actually observe. So interesting thing. I'll probably have to do it on that a bit more, but it was an interesting illustration of what can be a disconnect but hopefully isn't when you have harmony between the engineering of data side of it and the actual data scientist or statistician side of it. So a little bit of food for thought for your prediction,
[00:29:37] Mike Thomas:
adventures in the future. Yeah. Eric, like you, we don't do a ton of forecasting as well, you know, or more along the lines of machine learning and and some Bayesian regression analysis and things like that. But I really appreciate sort of just the the ideology here that as data scientists, we need to do a great job of articulating the work that we're doing. And, you know, in the conclusion here, John has this this quote that really stuck with me, and it it says, you know, most date time questions, unfortunately, you know, can't be simplified down to, you know, what's the prediction for date x? You you really need to ask a question that's more like, you know, what's the best prediction for date x using a model that was trained up through what was known at at date y and taking inputs known up through date z.
So you have sort of these these three different moving time components here, and that's where it gets into the discussion about bitemporal databases that allow you to see what data look like at at different times. And, it resonates a lot with me. It makes me feel like, you know, this AI can't automate our jobs as data scientists because there's so much nuance and and so much that we have to caveat and make sure that we are, articulating correctly. You know, I I had a presentation on on AI recently, and, unfortunately, you know, as much as I like to not look at my notes when I'm giving presentations, the way that we communicate these things is really, really important, and the words that we choose is is extremely important. So I I find myself, you know, making sure that I am spending a lot of time curating my notes for presentations like that when I'm communicating concepts around, you know, machine learning or or AI or statistical modeling, whatever we're calling it these days.
But but, really, that attention to detail and making sure you are explaining things, concretely for for end users is is really, really important because there's a lot of nuance going on here. And I think that, you know, unfortunately, out there in the wild with, you know, a lot of the, maybe, automated machine learning, I saw, Shannon Maklis post something recently where I think that the latest version of some sort of GPT, allows you to just upload a data set, and it'll make predictions for you. I don't know if you saw that come across, Mastodon. Yeah.
But, you know, that made me sort of hang my hang my head in sadness. And I would imagine that if John had seen that post, he he might be doing the same thing as well. So, you know, I appreciate John taking the time to to level set us on the importance of how nuanced, predictive modeling can be.
[00:32:19] Eric Nantz:
Yeah. And a lot of times, you may not really see it again until you look behind the scenes, so to speak. You look at the quality of your model fit. It's not just that p value. You've got to look at what's really happening in the actual trend of your prediction versus observed and looking at that time course. Yeah. It it's very powerful to have that critical eye looking at this carefully. And, yeah, we we cannot expect realistically that we're gonna have AI be able to figure out all those nuances. Certainly, there's a lot of responsibility at play here. That was a a similar theme to what I heard at the recent, Gen AI and pharma conference I was helping out with yesterday when we were as I'm recording this, that nobody had the illusion in our our speakers about this taking away anybody's job. And in fact, we just it's evolving the types of skills that we're we're gonna need to navigate this, but to do it responsibly and making sure that we're looking at these with the right lens.
And there is even some good talk about having the terminology be consistent or or adopting new terminology sometimes when you look at the evaluation of these models compared to when we look at in codevelopment or or maybe application development concepts of CICD. I'm looking at, you know, regression testing and things like that. There are starting to get equivalents of that on the model assessment side of it, but it's quite different in the AI space. So I'm even, as I speak, trying to learn the best way to translate some of the things I know from traditional statistic model building, traditional, you know, software development to this new age of augmenting with these AI tools. And even though this wasn't an AI post, you could definitely see something like this happen if you're gonna use some of these resources without a lot of care in front of it. So yeah. Great. Great. Again, thought provoking post that I can't wait to dive into more.
And with that, there's a lot more to dive into in the rest of the r Wiki issues. So before we wrap up the show, we'll take a couple of minutes for our additional finds here. And for me, I don't know about you, Mike, but I I like to, keep my GitHub, you know, repos organized with, you know, very, clear issues and with that and project boards. But with that in GitHub, one of the features I use a lot is the concept of labeling. And I got a pretty good handle on how to do that for my actual development projects, but this this, additional fine I wanna call out here is coming from Greg Wilson from the rOpenSci blog about some of the types of labels he uses, not just codevelopment, but also actual manuscript and, you know, course development.
So he calls up labels for technical writing projects, and the post itself is a pretty easy read, only a few paragraphs. But you look at interesting labels such as, like, what's the difference between adding a new feature called add versus changing something? And there's a change label that things are already there but could be better. What is required from more of a governance standpoint of the project about kind of meta issues versus general discussion? Or what's more around the infrastructure side for tooling versus, like, what's a one off thing he calls tasks that you have to accomplish? And maybe once you get it knocked out, it's going to be done. But and then also what is actual written contact with prose versus, like, the actual code itself which is in software. So it definitely gave me got me thinking for my projects where I might have a Shiny app, but then within that app, I'll have documentation, maybe an accompanying package down site to help users learn the app. I can have labels that are more tailored to that side of development and not just the actual app development, so to speak. So interesting post, and I'm I'm I I got some interesting things to ponder when I put up my next project in GitHub and what labels I use there. So, Micah, what what did you find? No. It's a great find, Eric, and I'm always interested in in what Greg has to write. He was the instructor for my,
[00:36:34] Mike Thomas:
tidyverse certified trainer course a whole long time ago. So that was that was pretty pretty cool opportunity to be able to to meet him, there. I found a blog post on Medium, published by Numbers Around Us, is the the name of the blog post. I'm I'm not sure exactly the name of the author. Maybe we can stick it in the show notes if I'm able to to pull it out here at some point. But it's it's called Express to Impress, Leveraging IBCS Standards for Powerful Data Presentations. And if you're not familiar with the IBCS standard, it is, the IBCS stands for the International Business Communication Standards Framework.
And its intent is, I guess, sort of like, you know, our our grammar of graphics, which it it sort of aligns pretty well with, is to accomplish, I think, really, these these three different goals for any data reporting work and data visualization work that you do to ensure, that your visualizations are clear and focused, that they're consistent and standardized, which I think, especially, you know, in an organizational context, at your company, you're probably going to want to be providing, you know, consistent types of consistent looking reports, consistent visuals over time, that your users can become familiar with. And then the last one is is one that really sticks with me. It's it's actionable, and ensuring that the visualizations that you're providing are somewhat of a call to action and a very clear call to action in terms of, you know, what you expect the audience to be able to to take away from that visual and, you know, what you expect them to to actually do because of it. So there's some some great examples of, you know, migrating from pie charts to to bar charts instead, and a whole lot of great ggplot calls in here, but an awesome other database post for this week.
[00:38:30] Eric Nantz:
Yeah. Really. Well, I'm looking through it now. There's a lot to a lot to digest here, but all really great concepts here that I'll definitely take with me as I keep building more visualizations in my packages and apps. So great great find there. And there's a lot more to this issue. We always can't talk about all of it, and we don't have enough time, but you're invited to check out the issue itself, which is linked in the show notes at rho.org as well. And, also, this project is a community effort, so we invite your poll requests for new resources, new, blog posts, new packages.
It's all right there, all in markdown. So head to rho.org for all the details now to contribute there. We also like hearing from you in the audience. We have a contact page linked in the show notes that you can find in your podcast, player as well as a way for you to boost the show if you'd like to hear from us and get in touch with us directly. If you get value of this, then we appreciate value back, so to speak, the value for value mindset. Details are in the show notes as well, and we are on social medias. If you wanna get in touch with us personally, I am mostly on Mastodon these days with at our podcast at podcast index.social.
I'm also on LinkedIn. Just search my name and you'll find me there and occasionally on the weapon x thing with that the r cast. Mike, where can the listeners get a hold of you? You can find me on mastodon@mike_thomas@phostodon.org.
[00:39:54] Mike Thomas:
Or you can find me on LinkedIn if you search Ketchbrook Analytics, k e t c h b r o o k. Now you can see what I'm up to lately. Very good. Very good. And, again, special shout out to our friends at Jupiter Broadcasting and Encoder Radio,
[00:40:08] Eric Nantz:
Mike and Chris for keeping the our language, train going for the official language. I'm not sure how long it'll last because those, Go and and, other folks are are nipping at the bud here, but we'll see how far it takes us. Nonetheless, we hope you enjoyed this week's episode of R weekly highlights, and we'll be back with another episode of R weekly highlights next week.
Hello, friends. We're back with us on a 179 of the R Weekly Holidays podcast. We're a day late because yours truly was, busy with other, production stuff with a virtual conference that just happened yesterday, which you might touch on a little bit later. But, nonetheless, we are excited to have you here for this weekly show where we talk about the latest highlights and other resources that are shared on this week's Our Weekly Issue. My name is Eric Nantz, and I'm delighted you join us from wherever you are around the world. And, you know, never a dull moment in your in his life, but my awesome co host, Mike Thomas, is here with me. Mike, how are you doing? I'm doing well, Eric. Busy busy busy as as usual.
[00:00:41] Mike Thomas:
In the process, I think I said this last week of of selling a house, so I'm currently in a room that doesn't have much furniture. It's quite echoey. So hopefully that doesn't come through too bad for the listeners this week.
[00:00:52] Eric Nantz:
We, completely understand, and, yeah. We we hope that that gets more stable for you soon enough, but luckily, we can give you at least a few minutes here to live vicariously through these great resources we have shared for you, this this episode. And before I go on further, I wanna share a little up follow-up to what I teased last week with some of these other podcasts I've listened to and our quest to get the r language to dominate all the things in software development. Well, I'm happy to share that, our quest to get r as the default language for Decoder Radio Show is working very well, so much so that we earned the perk of having a custom song generated for the r language on the Dakota radio program, which I am going to play for you right now.
[00:01:47] Unknown:
Down by the meadow under the banyan tree where old folks gather jabber and take their tea. Talking about numbers, trends to foresee in the world of digits, none purer than thee. And visions divine. Your cold unwrapped stories line by line. Oh, Oh, sweetheart, silent has the dew in the world of 1s and zeros. You're a lighthouse true. When umbers sing and scatter plots bloom through dire slapper and few lead us past gloom.
[00:03:00] Eric Nantz:
And a huge shout out to Brian who goes by b h h for creating that song. And I'll have a link to his profile on Nastur in the show notes as well as the Coda Radio episode, where this came from, if you wanna learn more. Us and the r, you know, community and data science, we tend to we tend to be pretty chill about a few things. There aren't a lot of things that rattle us, and I think I think that suits us quite well. So job well done when we couldn't thank the program enough. And and, yeah. So that was awesome. Nonetheless, we're gonna move on here with the rest of the show here, and our issue this week was curated by Nariel Nakagura, another one of our longtime curators on the ROV team. And as always, he had tremendous help from our ROV team members and contributors like all of you around the world with your poll request and other suggestions.
So we're gonna start off with a visualization a visit to our visualization corner, you might say, in ways that you definitely would not expect. So this harkens back to my days when I was a TA in graduate school where most of the time I was helping in our computation lab, doing some cool at that time, building some innovative r stuff with, I still remember these days using, like, the LAMP stack and doing custom databases and randomly generated exams and whatnot. But there was a semester I had to teach the intro stats course. And, of course, it can be difficult to get the students engaged, especially when you get to, you know, some of the more harder concepts like regression model fitting, trying to make sure you're instilling in in the students the fact that, well, you can come up with the terms in the model, but you do want to check how those models are performing with some various mix of normality assumption tests and also tests about the quality of the model.
Oftentimes, we would use a classic type of visualization, plotting the residuals of your model against the fitted values and looking for any distinct patterns. Or, hopefully, you don't see a pattern, which means that your assumptions are are working well. Well, what if to motivate students to do that kind of checking, you give them a little, hidden Easter egg, if you will, throughout that process? And that's exactly what this first highlight is doing in the form of, you guessed it, an R package that has a lot more behind the scenes here. So we are talking about the latest package called Surreal, awesome name, by the way, authored by James Balamuta, who goes by the cultless professor on social media and LinkedIn. Always enjoy his work. He's also been hugely instrumental in incorporating Quirter and WebAssembly and WebR alongside George Stagg. So I always follow what James does, but this came kind of out of left field on my media feeds and, hence, in our our weekly issue.
But this is a package that gives you data sets that, on the surface, may not seem like very much. It's data sets in x and y coordinates. But when you fit a visualization about those or fit a model around those and you look at the observed, you know, or let's just say the predicted and the residual plot, you can embed basically a hidden image or even text in that actual plot. This is this is mind blowing, but let's let's give some more context here. This stems from research from back in 2007, approximately around that time, by a professor Leonard Stefanski.
He was at NCSU or North Carolina State University back at that time, and he wanted a way to motivate his students to learn about these different model assessment techniques. And one of those, like I said, is that visualization of the residuals versus predictive values. And he came up with a clever algorithm that I'll try to describe, but in essence, you want you know what kind of image or text you want the student to see in this plot. So you start with that, and then you use a a mix of image processing and and some other extraction processing.
So you get, like, a black and white version of that image. You feed that into programs such as ImageMagick or whatever. So you can get on a two dimensional plane kind of like the x and y coordinates of what maybe the black dots are that comprise that image or text as compared to the white, like, the the background, if you will. So then if you also, depending on the image itself or the text, you are he's and his algorithm goes by assuming that the product of the residual vector, if you transpose that and multiply that with the fitted or predicted value, vector in matrix multiplication, that that product is 0, meaning that the residual and the predictive value vectors are orthogonal.
That's another assumption we see in things like principal component analysis and whatnot. But when you go by that, you can come up with an iteration algorithm to introduce new data that meets that requirement that may have 1, 2, 3, or more of these explanatory variables or predicted variables against an outcome variable. So if you do, like, a plot that looks at all these variables together and, like, those pairs plots that we like to do when we have multiple variables, you're not gonna really see much of a pattern to that new data. But then when you do that, that aforementioned visual look at the residuals and predictive value, you're gonna get that original image back. So this, package got a few datasets that correspond to some of these different images that you could that you could use. But I'm also gonna throw in the show notes well, actually, in the in the package site itself, he's got the r logo, the original r logo in this kind of black and white, you know, 2 d dimensional plane. But then when you look at after the transformation that I mentioned, it just looks like a scatterplot of 5 variables against the y, but looks like kind of random blobs really. Nothing nothing discernible here, but it's a hidden image of looking at the quality of the model where you start to see that actual, you know, Easter egg type image.
So there are other datasets here too. He even shows how to do a custom message saying r is awesome. We always agree with that. But then the one I'm gonna throw in the show notes is an archived version of Leonard's, I guess, original site that had more datasets that were fed into this, including some fun, Homer Simpson images and many others that you would not expect in a scatterplot that ends up being there. So if you want more background on just how this all came to be, check out that archive site. And I believe through that, you'll also be able to dig into finding the manuscript and a presentation that this professor did way back in the day.
So if you're looking for ways to engage your students on teaching regression principles, you wanna give them a little fun along the way, like, I wish I'd done back in 2,005 ish when I was doing a TA work on this. I would have loved to have had this to be a way to motivate the students, but real fun package. I can't wait to put some hidden things maybe to do, some pranks on my colleagues at work. I don't know. Could be fun nonetheless. But, Mike, you're gonna do some new residual plots out of this.
[00:10:49] Mike Thomas:
Oh, for sure. We'll stick this in all of our model validation reports at the end. Just some nice Easter eggs for our clients. And just when I think just when I think the art community, you know, can't come up with anything more creative than the last thing that we came up with, a package like surreal drops. And the project I I had never heard about, you know, Stefanski's work back in 2007. And it sounds like there are some earlier art implementations as well, by a few folks, John Stoudenmeyer, Peter Wolf, and Yul Ricky Gromping, who maybe attempted to to try to do the same thing. And the fact that you can stick, you know, images or messages here in your residual plots is pretty cool. And I I agree, Eric. I think, you know, a a really fun utilization of this package and a real good application for it would be in the classroom for, you know, statistics professors trying to teach, how to analyze, you know, model fits and to look at residuals.
I think that would be a pretty fun thing for your students to be able to to see. So this might be, you know, applicable for them and and interesting to them, and it's just, you know, another sort of example in the art ecosystem of all of the different crazy things that we can do with the art language.
[00:12:04] Eric Nantz:
Yeah. Like I said, this this came completely out out of the blue, but, oh, it's just amazing with a little math knowledge what you can accomplish in these in these, assessments. So I I got I told Mike in the pre show, I went down a little rabbit hole last night looking at all these different images that have been generated. There's some real comical ones there, even some nice messages about, you know, George, Box is famous, all models are wrong quote, and many other little things that, again, may get the students thinking not just about how did how is this actually accomplished, which, again, if you look at the manuscript in your spare time, you'll see there is a lot of clever matrix multiplication and iteration here. Like, the this this would have been a fun way in my linear algebra class to learn some of these concepts. But, again, I I I'm I'm in dinosaur age, so to speak. So this even predates that research when I was learning that stuff. But, yeah, this I think this could be great for especially in this day and age where I'm sure there's gonna be more models that are thrown to us may or may not even be generated by humans these days that looking at the integrity of these models, no matter machine learning or in the classical regression sense, is hugely important. So whatever we can do to to spark that light bulb in in students' minds and even those in in the field that are working daily, I'm all for it. So credit to James for putting this through. And, again, I'm I I can't wait to play this more. Yeah. This is like Anscombe's
[00:13:31] Mike Thomas:
quartet on steroids, sort of. And for the folks who are feeling festive or may celebrate Halloween, there is a function in the surreal package called jack o'-lantern surreal data. That's a built in dataset that you can use such that your residuals, when plotted, show a nice jack o'-lantern right in the middle of it.
[00:13:50] Eric Nantz:
That is awesome. Yeah. I think that'll be a good thing for my kids to say, oh, hey. Guess what I can do with r? And they'll be like, no. We want the real pumpkin. But you know what? But
[00:14:13] Unknown:
whatever.
[00:14:15] Eric Nantz:
And, in this next highlight, there's definitely been a lot of news that's been happening across the the pond, as I say, with our, friends at Australia with a recent update to the census that our next highlight is looking at a data driven way to look at the impact of additions in questions, really get a feel for how you can segment populations and looking at different differences amongst them. But, again, taking a data driven approach that I think we all can learn from. And this next highlight comes from Peter Ellis, who is the director of the statistics for development division at the Pacific Community.
So he's also based in Australia, but he in his latest blog post is looking at a recent addition, pushback and then readdition to certain questions in the 2021 ABS standard, which is, I believe, the Australian Bureau of Statistics and their recent update to the census and some of the discourse that follow through with that with respect to sex and gender variations and characteristics that they were trying to measure in an updated census. There was some pushback, and then apparently they've been reintroducing some of these questions dealing with, you know, what is a person's gender, how does that person describe their sexual orientation, and has that person been told that they were born with a variation of sex characteristics.
So certainly a a major topic around the world. But he wanted to not just, you know, react to the discourse that's online. He wanted to really dive deeper into with what we currently have, what is a way to convey the impact of trying to accurately distinguish some of these populations and seeing what that relates to other questions in the census itself. So, Peter does a great job in background, which, again, we'll invite you to check the preview or check the link yourself if you wanna read more background. We're gonna dive into more of the data analysis side of it where this is a very much a tidyverse inspired workflow with a real world use case of importing spreadsheet data from the from the ABS in a spreadsheet. So again, that's very common in the in this part of the world of of data analysis. So he's using the read excel package, one I've used great with great success in importing this type of data with a bit of, tidyverse cleaning up with a little bit of filtering for making sure they're getting non missing values and as well as different derivations of variables, a little bit of grouping. So again, pretty, pretty logical. We get to a dataset, eventually leads to a visualization that when you read the blog post, you're gonna have to zoom in on this a little bit. But Peter is trying to illustrate some of the key differences as measured by the data between the LGB plus and the heterosexual Australian responses on this survey from back in 2020 and then seeing what what impact that would be in various questions. And you do expect there will be some differences not just in the in the age categories but also responses such as, like, family composition in their household, income questions, and the like. But he's using a pretty nice kind of, I think, pseudo lines, you know, dot chart but showing the the difference in in arrows pointing at the the shift from the heterosexual side to the LGB plus side of it. So you can kind of see where the wider differences are.
But he says he struggled with how to put this plot more accurately, and he went through quite a few iterations on that. So at the end of the post, he's got kind of what led to that final visualization, a set of faceted bar charts that are basically looking at each of those questions individually in different categories as well as the facets. So you can get a good read on that as well. But he was trying to distill some of the findings from this side by side bar chart analysis into this line plot as well. So as as I said, you can kind of see different types of domains are showing a wider differential in terms of percentages, which again may or may not be expected. But I'm always up for letting the data tell the story and and certainly, hopefully, that in the future, the the census from anywhere in the world is able to accurately portray these different populations that, again, deserve their voices to be heard. So really, really great summary here by Peter. Definitely a lot to digest if you're looking into the space of census analytics.
I think a lot of good ideas to follow here. And again, great visualization, great reproducible code that you can run yourself if you want to import this data. And I'm sure similar techniques could apply to other, census data that's from available around the world. So great post by Peter, and I look forward to learning more about this space.
[00:19:34] Mike Thomas:
Yeah. I thought it was an excellent post as well. Eric and I appreciated the the two different approaches, in terms of data visualization to to representing this data. In the past, you know, when we've worked with survey data, it's for whatever reason, seems to be a little bit more tricky to work with than some of your traditional datasets, you know, that are exported out of a, you know, a database system that is the result of users entering data into your application or something like that. Right? There's a lot of, pivoting, reshaping, you know, some some filling, NA values as well, you know, some work, deciding between whether you want to use a continuous or discrete scale when you have Likert scales and and things like that going on. So I I certainly appreciate, you know, the work that went into curating this data into the visualizations that it became. This is also another reminder for me that I need start leveraging, you know, whether you wanna call them lollipop charts or donut or or, barbell charts or things like that. But, it's this might be the first time that I've ever seen a chart like this, which I think you might call, like, a barbell chart that has two dots, for each line on the y axis representing, you know, the differences between 2 categories in the legend.
And then there is actually an arrow, pointing the direction that it it, you know, increased or decreased. And, typically, I I I feel like in a lot of these charts, I've seen a line, just a straight line with no arrow on it, connecting those 2 each of those two dots. But the fact that, he was able to to employ an arrow here in this visualization was was really, really cool to me. You know, again, sort of demonstrated the the power of ggplot and the fact that that arrow is is colored the same as the the dot that it, you know, sort of is trying to represent the most, but there is also a little alpha component too that makes it a little more subtle than the dot itself. I think it's just a a really nice sorta chef's kiss, on top of that particular data visualization. And, you know, as always in a lot of these blog posts, the the ggplot code is all there. The dplyr data wrangling code is all there.
So it it's it's fantastic in the way that it it ends with this nice faceted bar chart as well. Man, I was working in Python, this week and was using the plot trying to use plot 9. Unfortunately, for a a donut chart, wasn't able to use plot 9 and had the to switch over to matplotlib instead. And I wanted to facet, you know, have these these faceted plots as well. And it's just not quite as easy as, you know, that that one beautiful facet wrap or facet grid, function that we have in ggplot. So it gave me that additional appreciation that, I I always have for for ggplot in the r language, particularly. But fantastic blog post talk top to bottom here, and and love the data visualization.
[00:22:30] Eric Nantz:
Yeah. We've always been spoiled in this community with the the power of visualizations both on the static variety and the interactive variety. So there's, yeah, there's a there's a lot going on in in the code here, but, yeah, I definitely invite you all if you're interested in replicating this to take a look at Peter's code here and and give it a spin for for your next, opportunity for these cool little barbell plots. So, yep, really, really powerful visualization and looking forward to seeing more in this space. And our last highlight today is going to be a healthy mix of some of the additional questions or items that I mentioned in our first slide about modeling techniques. But being careful about the data you're using in your model is definitely a key motivating factor for this this last highlight we have today, which is coming to us from John Mount, who is one of the principal consultants at WindVector LLC, the consulting resource. And they've historically have had the WindVector blog, which, I've been reminiscing about this in previous episodes about what were some of my original resources learning are back in the early 2000 mid 2000. But, John Mount's blog has been right up there as one of the resources I've had bookmarked for many, many years. So it's always great to see posts from him come to the highlights here. But he is motivating a situation that's been inspired by real projects where there can be a bit of a disconnect between the data scientists and analysts performing modeling for prediction and perhaps data engineers that are supplying this data that maybe aren't giving you the full information, so to speak. So in his example that's inspired by real things but kind of more fictitious is that you have, an issue where maybe you wanna run a prediction on forecast, I should say, attendance at a movie theater, and you wanna incorporate attendances from past, you know, events or past movies as part of that along with other factors that might drive that, you know, that influence in the prediction.
So you may be getting from a data engineer or data warehouse, whatever have you, some metrics for each of the dates and each of the movies that were showing in that date, the time of it, and the number of people that attended that. So he's got starting the post, a little example of reading a hypothetical CSV file where we've gotten the month in the month of August, you know, a few movies. I'm not sure these are real names but whatnot, but with the attendees. And you can see there is quite a bit of variation in some of these attendance metrics, which, of course, could be the quality of the movie, but could be other factors. But to motivate the goal of building a model that relates the attendance to one of the key you know, maybe one of the key perks in a movie theater these days or always has been is how much popcorn you sell and whatever snacks you sell. Maybe that is a driver that someone might wanna look at. There could be other factors too along with that.
But but one thing to note is that when the the engineers look at what's going to happen in the future, there could be a disconnect between the type of data. Historical data is looking at the actual numbers of attendees, but the stuff that's being estimated is, of course, not known yet. So continuing on with the example, imagine that they look at the different popcorn sales. They they merge that with the attendance dataset. You're doing what looks to be a pretty decent, you know, model fit with the data you have. But now when you start to do predictions, when you look at the month of September and knowing that the month of September is giving you slightly different types of values and you see that the estimates are in the line plot that he shows here really inflated, like massively inflated from what we see the model saying in the previous month of August. So and the takeaway is that the model is predicting or predicting popcorn sales in the future are going to be double what they see in the month of data that they use to train the data.
That doesn't quite check. So doing a little diagnosis, doing some nice little distribution plots, you see that the pattern of attendance doesn't look anything alike. They look heavily skewed in September compared to the more balanced month of August. And why is this? Well, the estimated attendance figures in September were based on the capacity of the movie theater, the number of seats inside, which is different, of course, than what the actual measures were back in the month of August where they used actually the number of people sitting in the theater at that time. So this is illustrating a case where maybe there's a bit of a disconnect in terms of the type of data that's going to go into your forecast versus the type of data you're using to train the data. So to motivate what John would do in this, you know, solving the issue, instead of using the actual number of movie attendees in August, he recommends moving using the capacity of the theater as additional or replacing the metrics with the capacity numbers instead. And when you do that, then you get data that looks more realistic in his opinion compared to what we saw before.
So my takeaway from this is being consistent with the type of measures you're incorporating in both your training and then eventually your your val your validation or your future prediction set as compared to mixing the different types up. Even though they are technically the same variable, they are in much different context. So this is something I haven't really encountered myself because I'm not as much into the forecasting realm of it, But I could definitely see how this might be a bit of a monkey wrench to a certain, you know, say, to scientists or statistician that see such wildly different metrics when they look at their predictions versus what they actually observe. So interesting thing. I'll probably have to do it on that a bit more, but it was an interesting illustration of what can be a disconnect but hopefully isn't when you have harmony between the engineering of data side of it and the actual data scientist or statistician side of it. So a little bit of food for thought for your prediction,
[00:29:37] Mike Thomas:
adventures in the future. Yeah. Eric, like you, we don't do a ton of forecasting as well, you know, or more along the lines of machine learning and and some Bayesian regression analysis and things like that. But I really appreciate sort of just the the ideology here that as data scientists, we need to do a great job of articulating the work that we're doing. And, you know, in the conclusion here, John has this this quote that really stuck with me, and it it says, you know, most date time questions, unfortunately, you know, can't be simplified down to, you know, what's the prediction for date x? You you really need to ask a question that's more like, you know, what's the best prediction for date x using a model that was trained up through what was known at at date y and taking inputs known up through date z.
So you have sort of these these three different moving time components here, and that's where it gets into the discussion about bitemporal databases that allow you to see what data look like at at different times. And, it resonates a lot with me. It makes me feel like, you know, this AI can't automate our jobs as data scientists because there's so much nuance and and so much that we have to caveat and make sure that we are, articulating correctly. You know, I I had a presentation on on AI recently, and, unfortunately, you know, as much as I like to not look at my notes when I'm giving presentations, the way that we communicate these things is really, really important, and the words that we choose is is extremely important. So I I find myself, you know, making sure that I am spending a lot of time curating my notes for presentations like that when I'm communicating concepts around, you know, machine learning or or AI or statistical modeling, whatever we're calling it these days.
But but, really, that attention to detail and making sure you are explaining things, concretely for for end users is is really, really important because there's a lot of nuance going on here. And I think that, you know, unfortunately, out there in the wild with, you know, a lot of the, maybe, automated machine learning, I saw, Shannon Maklis post something recently where I think that the latest version of some sort of GPT, allows you to just upload a data set, and it'll make predictions for you. I don't know if you saw that come across, Mastodon. Yeah.
But, you know, that made me sort of hang my hang my head in sadness. And I would imagine that if John had seen that post, he he might be doing the same thing as well. So, you know, I appreciate John taking the time to to level set us on the importance of how nuanced, predictive modeling can be.
[00:32:19] Eric Nantz:
Yeah. And a lot of times, you may not really see it again until you look behind the scenes, so to speak. You look at the quality of your model fit. It's not just that p value. You've got to look at what's really happening in the actual trend of your prediction versus observed and looking at that time course. Yeah. It it's very powerful to have that critical eye looking at this carefully. And, yeah, we we cannot expect realistically that we're gonna have AI be able to figure out all those nuances. Certainly, there's a lot of responsibility at play here. That was a a similar theme to what I heard at the recent, Gen AI and pharma conference I was helping out with yesterday when we were as I'm recording this, that nobody had the illusion in our our speakers about this taking away anybody's job. And in fact, we just it's evolving the types of skills that we're we're gonna need to navigate this, but to do it responsibly and making sure that we're looking at these with the right lens.
And there is even some good talk about having the terminology be consistent or or adopting new terminology sometimes when you look at the evaluation of these models compared to when we look at in codevelopment or or maybe application development concepts of CICD. I'm looking at, you know, regression testing and things like that. There are starting to get equivalents of that on the model assessment side of it, but it's quite different in the AI space. So I'm even, as I speak, trying to learn the best way to translate some of the things I know from traditional statistic model building, traditional, you know, software development to this new age of augmenting with these AI tools. And even though this wasn't an AI post, you could definitely see something like this happen if you're gonna use some of these resources without a lot of care in front of it. So yeah. Great. Great. Again, thought provoking post that I can't wait to dive into more.
And with that, there's a lot more to dive into in the rest of the r Wiki issues. So before we wrap up the show, we'll take a couple of minutes for our additional finds here. And for me, I don't know about you, Mike, but I I like to, keep my GitHub, you know, repos organized with, you know, very, clear issues and with that and project boards. But with that in GitHub, one of the features I use a lot is the concept of labeling. And I got a pretty good handle on how to do that for my actual development projects, but this this, additional fine I wanna call out here is coming from Greg Wilson from the rOpenSci blog about some of the types of labels he uses, not just codevelopment, but also actual manuscript and, you know, course development.
So he calls up labels for technical writing projects, and the post itself is a pretty easy read, only a few paragraphs. But you look at interesting labels such as, like, what's the difference between adding a new feature called add versus changing something? And there's a change label that things are already there but could be better. What is required from more of a governance standpoint of the project about kind of meta issues versus general discussion? Or what's more around the infrastructure side for tooling versus, like, what's a one off thing he calls tasks that you have to accomplish? And maybe once you get it knocked out, it's going to be done. But and then also what is actual written contact with prose versus, like, the actual code itself which is in software. So it definitely gave me got me thinking for my projects where I might have a Shiny app, but then within that app, I'll have documentation, maybe an accompanying package down site to help users learn the app. I can have labels that are more tailored to that side of development and not just the actual app development, so to speak. So interesting post, and I'm I'm I I got some interesting things to ponder when I put up my next project in GitHub and what labels I use there. So, Micah, what what did you find? No. It's a great find, Eric, and I'm always interested in in what Greg has to write. He was the instructor for my,
[00:36:34] Mike Thomas:
tidyverse certified trainer course a whole long time ago. So that was that was pretty pretty cool opportunity to be able to to meet him, there. I found a blog post on Medium, published by Numbers Around Us, is the the name of the blog post. I'm I'm not sure exactly the name of the author. Maybe we can stick it in the show notes if I'm able to to pull it out here at some point. But it's it's called Express to Impress, Leveraging IBCS Standards for Powerful Data Presentations. And if you're not familiar with the IBCS standard, it is, the IBCS stands for the International Business Communication Standards Framework.
And its intent is, I guess, sort of like, you know, our our grammar of graphics, which it it sort of aligns pretty well with, is to accomplish, I think, really, these these three different goals for any data reporting work and data visualization work that you do to ensure, that your visualizations are clear and focused, that they're consistent and standardized, which I think, especially, you know, in an organizational context, at your company, you're probably going to want to be providing, you know, consistent types of consistent looking reports, consistent visuals over time, that your users can become familiar with. And then the last one is is one that really sticks with me. It's it's actionable, and ensuring that the visualizations that you're providing are somewhat of a call to action and a very clear call to action in terms of, you know, what you expect the audience to be able to to take away from that visual and, you know, what you expect them to to actually do because of it. So there's some some great examples of, you know, migrating from pie charts to to bar charts instead, and a whole lot of great ggplot calls in here, but an awesome other database post for this week.
[00:38:30] Eric Nantz:
Yeah. Really. Well, I'm looking through it now. There's a lot to a lot to digest here, but all really great concepts here that I'll definitely take with me as I keep building more visualizations in my packages and apps. So great great find there. And there's a lot more to this issue. We always can't talk about all of it, and we don't have enough time, but you're invited to check out the issue itself, which is linked in the show notes at rho.org as well. And, also, this project is a community effort, so we invite your poll requests for new resources, new, blog posts, new packages.
It's all right there, all in markdown. So head to rho.org for all the details now to contribute there. We also like hearing from you in the audience. We have a contact page linked in the show notes that you can find in your podcast, player as well as a way for you to boost the show if you'd like to hear from us and get in touch with us directly. If you get value of this, then we appreciate value back, so to speak, the value for value mindset. Details are in the show notes as well, and we are on social medias. If you wanna get in touch with us personally, I am mostly on Mastodon these days with at our podcast at podcast index.social.
I'm also on LinkedIn. Just search my name and you'll find me there and occasionally on the weapon x thing with that the r cast. Mike, where can the listeners get a hold of you? You can find me on mastodon@mike_thomas@phostodon.org.
[00:39:54] Mike Thomas:
Or you can find me on LinkedIn if you search Ketchbrook Analytics, k e t c h b r o o k. Now you can see what I'm up to lately. Very good. Very good. And, again, special shout out to our friends at Jupiter Broadcasting and Encoder Radio,
[00:40:08] Eric Nantz:
Mike and Chris for keeping the our language, train going for the official language. I'm not sure how long it'll last because those, Go and and, other folks are are nipping at the bud here, but we'll see how far it takes us. Nonetheless, we hope you enjoyed this week's episode of R weekly highlights, and we'll be back with another episode of R weekly highlights next week.