How being fair to your research has a new and important meaning than what you may expect, the power you can unlock with custom roxygen tags, and a collection of tips you can apply today for your next visualization.
Episode Links
Episode Links
- This week's curator: Batool Almarzouq - @batool664 (X/Twitter)
- Making your blog FAIR
- Create and use a custom roxygen2 tag
- Five ways to improve your chart axes
- Entire issue available at rweekly.org/2024-W37
- httr2: Perform HTTP requests and process the response https://httr2.r-lib.org/
- Athanasia's GitHub Actions workflow files https://github.com/drmowinckels/drmowinckels.github.io/tree/main/.github/workflows
- maestro: Orchestration of data pipelines https://whipson.github.io/maestro/
- Use the contact page at https://serve.podhome.fm/custompage/r-weekly-highlights/contact to send us your feedback
- R-Weekly Highlights on the Podcastindex.org - You can send a boost into the show directly in the Podcast Index. First, top-up with Alby, and then head over to the R-Weekly Highlights podcast entry on the index.
- A new way to think about value: https://value4value.info
- Get in touch with us on social media
- Eric Nantz: @rpodcast@podcastindex.social (Mastodon) and @theRcast (X/Twitter)
- Mike Thomas: @mikethomas@fosstodon.org (Mastodon) and @mikeketchbrook (X/Twitter)
- Crysis Crystal - Mega Man 9: Black in Blue - k-wix - https://backinblue.ocremix.org/index.php
- Of Whips and Strings - Vampire Variations: A Musical Tribute to Castlevania - Super Guitar Bros. - https://ocremix.org/remix/OCR02480
[00:00:03]
Eric Nantz:
Hello, friends. We're back. That was a 178 of the R Weekly highlights podcast. Almost midway through September already. Time is flying by, but what never slows down is also the fast pace of the r community, where in this podcast we cover the awesome highlights and other resources that are shared every single week at rweekly.org. My name is Eric Nantz, and I'm delighted you join us today from wherever you are around the world. And joining me at the hip with never a dull moment in his life going on right now is my co host, Mike Thomas. Mike, how are you doing today? Doing well, Eric. Hanging in there. I am potentially in the process of of moving, which is both
[00:00:41] Mike Thomas:
exciting and and crazy and stressful all at the same time. So all the emotions.
[00:00:48] Eric Nantz:
Yep. It's it's hard to grasp just one at a time. It all just happens at once. So our our, best of luck to you, and hopefully, you don't lose anything valuable on the move
[00:00:59] Mike Thomas:
over. I'll make sure that the microphone stays intact, and we'll be sure to to make sure that the new podcast space is is set up ready to go.
[00:01:08] Eric Nantz:
Well, you know, that that's that's the real important stuff. You know, those those pets or whatever. Ah, no. You need the mic. No. I'm I'm I'm I'm good. I we know where your priorities are. We we we we get it. We get it. That's right. Yeah. I'm, not moving anytime soon because that would be a herculean effort in this, house here to try and pick up everything there. But luckily, I don't have to think about that. I get to think about the great art content we get to talk about today. And in this week's issue has been curated by Batool Almarsak. And as always, she had tremendous help from our fellow Arruki team members and contributors like all of you around the world with your poll requests and other suggestions. And so one of the biggest reasons we do our weekly is the great content that all of you out there, whether you're in the data science world or other parts of industry, have been showcasing your learnings perhaps through either personal websites, personal blogs, and whatnot.
And, you know, it does beg the question sometimes when we put these resources online, how do we kinda guarantee really tight linkages or ways to get to that content even as the landscape of, like, web hosting providers or other ways that we're deploying these sites change over time? Well, in our first high, we're gonna look at a pretty innovative way to kind of future proof potentially ways to make your your insights on, say, a blog more easily shareable that could be durable for the test of however evolving the tech landscape is. And in particular, this first highlight is coming to us from Athanasia Mowinkle, who is a neuroscientist over in Europe where she talks about making her blog fair.
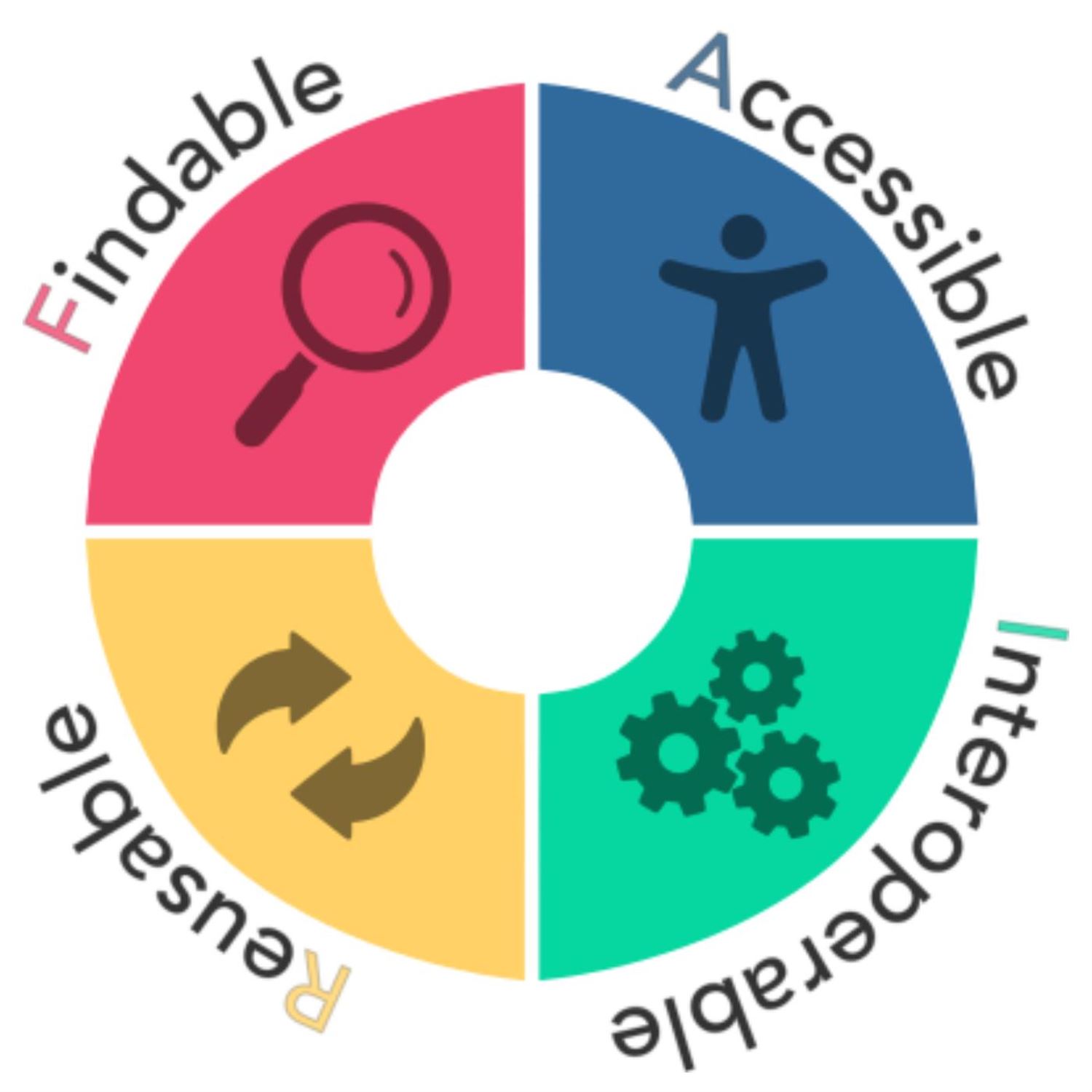
Now I'm not talking about the fair that I often hear from my kids gripe to me when they say, it's not fair. I don't get to do this and that. No. I'm not talking about that kind of fair. The fair we're talking about here is an acronym for findable, accessible, interoperable, and reusable. Boy, that sort of speaks to me with a lot of the reproducibility aspects we talk about all the time with framers, like r markdown and quartile and whatnot. But, of course, this applies to any insights we author or generate. Ethe Nagia has, has worked on her blog for quite some time, and she was inspired actually about a newsletter that she subscribes to from Heidi Seibold about her approach to making her blog this FAIR compliant, if you will.
And in Heidi's approach, we get an outline that it's basically, hosted as a Jekyll website, which for those aren't familiar, Jekyll was a framework and I believe based in Ruby to do, like, a static site kind of generation, was used very many years in the GitHub world. But Heidi also has, you know, a newsletter that she turns into RSS or Adam feed, and then that will post automatically based on the content in her site. And then she also adds her blog to a service called Rogue Scholar, which I believe is an archive for more of the academic or research type blogs.
But what comes with that is robust DOIs or these kind of unique document identifiers and additional metadata that could then be searchable and easily accessible. Athanasia's workflow is pretty similar. It's a Hugo site. Now, again, Hugo, I've been a big fan of for many years. That's what powers the blog down package that EYC has created with, his work at Posit earlier and that. And then she also hosted on GitHub Pages. Again, a framework I like to use quite a bit for hosting. Again, all marked down all the time. And with Hugo, you get an automatic RSS feed. And then she has an idea for a GitHub action that will register each new post to a service called Zenodo, another one of these research type archival services.
And then via their API, she's going to be able to get these robust document identifiers as well as adding additional metadata so that that can be searchable as well. There are a little nuance differences from what Heidi approached, but we're going to walk through just how Athanasia has accomplished this in her workflow here. So with that, we're going to need some packages, right, because she wants to do this all in R because we want to do R all the things here. So we need to communicate with a web service, the Zenodo API. So with that, the h t t r two package authored by Hadley Wickham is a great candidate to interface with those connections.
And then with Hugo and as well as Portal itself, another of these static site generators, many times your content will have a YAML front matter at the top that denotes certain metadata, certain options, or whatnot. So how do you interpret that? Well, appropriately enough, there is an R package called YAML, y a m l, to let you interrogate both from a consuming perspective and actually writing YAML if you need to to documents or whatnot. And then the last step is she's going to take a bit of a detour after what Heidi did. She wants to make sure her blog posts, which often have a great mix of visual content as well as tabular summaries and other narrative to be easily self contained in one artifact.
So she wants to convert these posts to PDF, and for this she is going to turn to quarto for this part of the workflow. So we're going to walk through this step by step, but the first step of this is actually trying to prepare the data of these posts so that it can be archived. And she's got some some example code here. The first grab all these markdown files that make up the source of the posts themselves, And in Hugo, you can do what are called page bundles, which basically means every new page that you make in your site is its own folder with within it an index dot MD file and many other supporting files such as images or whatnot.
So she wanted an easy way to grab the source of all those index dot MDs. So she's got a little, regex action going here and list that files. Not too difficult. She knows the file name, so it's literally index //md is like the regex on that front. Once she got that, now she's got this this vector of files on her file system to have all of the blog content. Okay. Now, examining, we walked through one of these posts that she has, in this case, about random effects. She then reads the contents of that file with the relines function, and you see if you print that out like in the example here, you've get each line or each element is a line from the file. So you got the YAML at the top and then a few blanks and then you've got the actual content itself.
So we've got the content read read in r now. Now how do we extract that metadata first? Like, let's parse the YAML first, and then we'll deal with the content afterwards. There is a handy function within rmarkdown itself that she was able to get some recommendations, from a good friend of hers that we'll hear about later in the highlights of a function called YAML front matter exposed by R Markdown itself, where you feed in the contents of that post with both the YAML and whatever the narrative you have. And it is intelligent enough to scrape that YAML section and then make variables for each field with its actual values. So you see it's got, like, the title, author, you know, date, and even the nested elements are like nested list elements. It's very handy, very, very straightforward.
And so she's able to get that YAML metadata, but she wants to add more to it than just what's in the YAML. She wants a high level description of the post, which in the Hugo world doesn't quite come automatically. You have to kind of inspect the rest of the post to kind of maybe take a portion of it. So she wants to make some code that will do this. So she wrote a custom function that's doing a bit of a grip of, like, all that content that's after the YAML delimiters and then be able to grab that and then see what are the positions where that content actually starts.
And then from there, she's able to then look for what's like the first paragraph of that post or maybe the first few sentences. She's able to grab that with more custom functions of a summary of it and then inject that into the existing metadata variable. So now she's got a simple 2, 3 sentence description vector for that metadata summary. So with that, she's got the metadata ready to go. Now here comes the fun part. As I mentioned, she wants to use the Zenodo service to start archiving the content and have it searchable, but just like anything, an API has got its own set of documentation, what it expects to have.
And, apparently, she's had to do a bit of trial and error, which I can certainly relate to because sometimes I get the requests horribly wrong, and sometimes you get those cryptic errors back of, like, what happened and what didn't happen. So through this, exploration, she was able to compose kind of another list structure of those metadata fields, but in the way that the Zenodo API expects. So it looks like kind of a nested list of elements, which isn't too bad, but it's a lot of just brute force trial and error to get to that point. So then that's not all. As I mentioned, she wants a static archive of the content itself, not just from the metadata, but of the entire post.
That's where our good friend Quartal comes in where once again she's able to leverage a function from Quartal, in this case Quartal render, to compile the web based version or the markdown version into a PDF. But she had a little rabbit hole to navigate here. You know what she tried to do, Mike? She tried that types method, and that didn't quite work. But there's always a plan b. Right? And plan b is good old LaTeX. As much as I rag on it sometimes sometimes it's still the best tool to get the job done.
[00:11:59] Mike Thomas:
Yeah. Unfortunately, Athanasia tried types first and some of the images were not being resized correctly is what she said so that's why she had to switch back to Latex. And, you know, that's a little disheartening for me to hear. I think it's, you know, they're still working on ironing out some of the kinks of of types and how it interacts with quarto. I I do still believe it's the future, but, if you are trying to do, you know, very specific things and, you know, size images a very particular way on the page, you might have a little bit more customizability and full control when you're leveraging LaTeX, as compared to to types, especially if you you actually know how to write a little bit of LaTeX as well.
We are are in the process at Catchbook. I was hoping for our next big model validation project, which are these PDF deliverables, that we could switch over to, types instead of our our current sort of LaTex, framework. But we do need a lot of that customizability to make things sort of look perfect on the page for our clients. So, I'm I'm hesitant to make that switch yet, especially after reading this this blog post. But one of the nice things is you can try the 2 and the the quarto code is still the same. Right? You're still using quarto render with your output format PDF, for the most part.
So it really cool that she was able to do that. I guess it's sort of unfortunate that you have to to render to PDF for the Zenodo service.
[00:13:32] Eric Nantz:
Right? Yeah. Yeah. My hope is that it would have some kind of dynamic view of that content, but it is what it is, I guess. Exactly.
[00:13:41] Mike Thomas:
So, as you said, sort of the the 3 packages that come together here are h t t r 2, YAML, and then what's the last one that I can't have? Quarto itself. And then Quarto itself. Right? So, the sort of the way that she's able to actually send this final request, to the HTTP RT or or to the Zenodo API via HTTR 2 is, obviously, whenever you're dealing with one of these APIs, you're gonna need an API key token. So she stores that as an environment variable called Zenodo API token, and then she has just a variable an object called Zenodo API endpoint, where she specifies the, you know, the URL endpoint of, this Zenodo API where she's going to be sending this request. And you gotta love h t t r two it just makes everything look so absolutely clean.
The the pipe syntax that we're using here in h t t r two starts with a request, then a a bearer token, essentially, where she passes that API token, and then your JSON body as well. And don't forget to use that auto on box equals true if you're switching back and forth between our lists and, JSON data that you are sending up to the API. The nice thing about HDR 2 as well that Athanasio demonstrates here is you can use the request dry run function to be able to see the query that's going out before you actually send it to the API. Take a look at that request and everything Once everything looks good, you can use, request perform to actually send your API request to Zenodo, get the status that comes back.
In in this case, it was a a 201 created, which, is is not the response that she got for many attempts as you said, while trying to figure out the all of the different metadata components for this API. And if you take a look at the blog post, there are a lot of pieces to this list, this metadata list that she puts together that need to be sent to this API, you know, essentially, different parameters that the API expects, you know, within the metadata. It's not just a title description, you know, the creators, her name, her or orchid, you have upload type, publication type, publication date, and about 5 other different parameters that have to be nested correctly in your r list in order for them to be passed correctly via JSON to the, to the, API service. It's you're able to take a look at what came back, from that JSON response and everything looks looks really, really good, and at that point in time, I think she has everything that she needs for the DOI that's actually going to be, get sent, via the GitHub action. It's gonna get published alongside the GitHub action for the most part.
So sort of the last section of of this blog post is actually adding that DOI to the YAML header or front matter, if you will, for the post, that is going to to end up being posted and published. So Afnazia is actually able to put together a single script. It looks like it's about maybe 200 lines here, that sort of put everything together, in one script and mostly it's it's functions here, which is really nice functional programming, that she's put together that walk through all of the different steps that we talked about in this blog post, in terms of, you know, sort of finding the the end of the section, you know, taking a look at whether or not a DOI is needed, you know, actually publishing to Zenodo, which is probably the biggest function, the biggest custom function that she's written and that's going to return, I believe, the path to the PDF file that has been generated by quarto.
And then once you actually have that PDF file and, you're ready to go here it's it's just a few lines of code that she has here, with a nice little s apply to to process files that that do not have a DOI, but are published and supply, those posts essentially and and run all those posts, that need a DOI to her service. And it's it's pretty incredible. Her next step is to to work on the GitHub actions component, which I I think should be fairly straightforward given that she's put, you know, all of the r code here together as best as possible. Obviously, when you're dealing with GitHub actions that's gonna be running on a machine that's not yours. So she will have to ensure that, you know, all of the dependencies including latex, which is probably not fun, when you're doing that in GitHub actions is are installed correctly, and execute correctly on that that GitHub actions runner. But I'm very excited to hopefully sort of see a follow-up here for the next step in this process, which is the GitHub action that's gonna do this all programmatically. So every time that she authors a new post on her website, it will automatically reach out to Zenodo, get that DOI, and publish things, the way that they should be.
[00:18:47] Eric Nantz:
Yeah. As you were talking, I went to that, GitHub repo, and sure enough, there are a few actions here. And I believe she's do indeed has that script that you just outlined in the GitHub, you know, workflows area itself. So I think she's got it. Credit to her. She's actually got 4 actions on there. My goodness. She's a GitHub action ninja, looks like. So I'm gonna have to take some learnings from this. But my goodness. What a what a great, you know, showcase of automation, but also just what you can do when you stitch these services and and workflows together. So I I think this shows a lot of inspiration as we're thinking about, hey, anybody generating or authoring their content, trying to future proof this to some extent? And, you know, we can't predict everything in the future. But, yeah, I'm intrigued by what this Sonoto service is offering her, but I may look at other ways too of making sure that what I produce, maybe it's, you know, the stuff I used to do with the shiny dev series or ever or this very podcast. Right? I wanna make sure this stands the test of time that no matter which fancy technologies out there, we can find a way to search it and be able to to grab it back. So, yeah, lots of lots of interesting nuggets here. And then I really appreciate towards the end of that of that script that she was outlining, she's got a check to make sure that she doesn't do this DOI process for posts that already have it, which is great to minimize, again, calls to an external service because the last thing you wanna do is accidentally DDoS something or worse yet lose your access to that API venture. So being intelligent enough to only run what you need, that's a that's a lifesaver when you do have APIs or even HPC computing. So lots of nuggets in that script that I think are quite inspirational here.
[00:20:41] Mike Thomas:
Absolutely. And, Eric, you and I, you know, don't do a lot of, I guess, academic publishing, but there is a gigantic community of people out there who do that, and I think that this blog post is going to be incredibly powerful and helpful for them.
[00:20:55] Eric Nantz:
Yeah. So definitely check out her, catalog on the re of the previous blog post. So there's a little bit of something for everybody in that world. Really, really good stuff. And one of the nice things about Athanasios' post is that she mentioned that she reached out to a couple of her trusted friends to give some recommendations on how to proceed. And one of those friends just happens to be the author of our next highlight here because Ma'al Salman returns to the highlights once again to talk about her recent discovery about creating and leveraging not just r oxygen 2 but custom r oxygen 2 tags.
Now this has been something I've never dived into myself, but I'm starting to see other packages in the our ecosystem try to do things like this where they'll have a custom tag. And based on that, their package will do additional processing or additional things on the side with it. So she, you know, introduction here, such as making sure that there are internal functions that are documented maybe for only developers and not for like the end user of a package. Also, being able to leverage or record certain standards that are expected for statistical functions.
And lastly, having tests from within our scripts themselves, and that in particular has been contributed by a package called roxy test as well. So I've seen these come through, but I never really knew what was the nuts and bolts on it. So I was supposed to gonna walk us through her journey on this and that she was looking for a way to help with the iGraph package. And for those that aren't aware, iGraph is one of the, you know, more standard and frankly, quite powerful packages that deals with network, network generation, network analysis for simple or complex networks.
Now are the r packages are binding to the c library of the same name, iGraph. And I I remember compiling this back in the day when I was getting into network analysis for the first time. And, admittedly, iGraph is, a bit of a bit of an ordeal to get into, but it's not insurmountable. But what she's learned as she's been working with iGraph is that there may be places where the r function definitely has documentation as it would have any r package, but it's depending on some source in the c library to make all that happen. And she wanted a way to link for a particular r function to the relevant c code binding and whatever it needs in terms of additional considerations within each of the functions manual pages.
So that looks like something that I wouldn't even know heads or tails of how to accomplish it, but we're gonna walk through how she, did this herself. So she starts with, outlining the workflow that ends up doing this. 1st, having, some kind of mapping of the existing documentation for the c library. Maybe you have to hand generate that yourself or hopefully you can scrape that somehow. And then in the rOxygen documentation header for a given function, add a new tag called atcdocs that's going to point to the source c function that that particular r function is using.
And then she says that's going to be kind of manual for now, but there may be ways to do that automatically later. And then building upon the tooling that our oxygen 2 gives you, giving you a way to parse that custom tag and do the necessary bits to write the manual page to link to it. So thankfully, not just showing telling us the workflow, she's going to walk through it for a hypothetical example here where she's got a minimal R package called HGB, where it's got a simple hello world type function. But she's going to put in a custom tag with the custom, literally custom tag, in the rOxygen header. And, of course, it by itself, it looks fine. Nothing's bad is going to happen, but rOxygen by default is not going to know what to do with that yet. So now she's leveraging what's documented in the rxn2vignette to say, okay, there is a method called Roxy tag parse Roxy tag custom. Yes. That is all one function call separated by underscores there, which is telling our oxygen 2 what to do when it sees a set a tag of a certain type.
So she's got some example snippets here where you can see straight from the vignette, you can write these custom functions that are going to either look at the tag and then also x and then be able to write it out as a new section in the docs based on seeing that tag named custom, taking in what was the material from it, and then putting it into this new section. And then well, we were just talking about LaTex earlier, Mike, when you look at an r help file, you see, like, a web view of it. But behind the scenes, that is LaTex style code when these are compiled. And so she has a last section a last function to format that custom rd section that she's making and puts in literally the the latex style code for the section and then an itemized list of the value of, I believe, that source file.
And then she's got the building blocks here. Now it's not quite done yet because then she's got to create what's called a rocklet that's going to help for this custom tag to be shared potentially with other packages that wanna leverage this. So this is an optional step. But if you think you've got a workflow that could benefit the community in your particular package, this is a great way to share that via what she's done here. She's running a custom Rocklet function that's going to declare this Rocklet. It's a fun name to say out loud. Hopefully, I'm saying it right. But then be able to process that and then to be able to export that out as a way for other users to to leverage that. So again, that might not always be the case, but that is one way they set the building block of actually sharing it.
And then there comes the question of, well, do we actually need a separate package to hold this new custom tag processing? And you may or may not need that all the time. There are cases where maybe it's so specialized it would be only your particular package is going to use this custom tag. It may not need to go to that external that extra effort of making an extra package out of it, but others might say, you know what? This is good enough or this is good for the community. Maybe we do want to share it. So there are ways that you could do that because you've got some narrative about where it might be helpful and where it might not. So in the case of the eye graph here, this was a custom tag that was already meant for eye graph itself. So she thinks that could live in the package itself. But again, there could be cases where you want to share that with a community.
So I've been fascinated by this because, again, I've seen packages come through our weekly recently where they say, add this custom tag in your oxygen header, and we're gonna do something with it. Whether it's like this testing generation or in particular that newer package that came out recently that gives you kind of a a workflow for ingesting, like, data in an ETL process, they're also built on our oxygen tags as well. So lots of interesting use cases for this. It'll take me a little bit to wrap my head around this, but it's nice to know that the machinery is there if we wanna do some custom processing with these documentation tags.
[00:29:37] Mike Thomas:
Yeah, Eric. This is interesting. Every once in a while, I come across a package that, allows you to essentially do things in your own package with, you know, these these are oxygen decorators. Right? I think Plumber is an example potentially of a package where we do that. Right? There's sort of That's right. These custom Roxygen, tags that that will stick on top of our code and and quote unquote decorate our code with that serve a specific purpose or, you know, execute the code that is underneath it or the functions underneath it, a particular way actually based upon the roxigen that's been written. You know, one of the the real standout things for me in this blog post is how many functions there are from the roxigen 2 package that I had no idea about, this tag markdown function, rd section function, rocklet function, all of these things that allow you to develop, the custom roxigen as Mel, you know, so eloquently sort of outlines here. I haven't particularly had a use case to do this, yet myself, but I I do leverage some packages, including Plumber and a couple others that that do this. And they they must have, you know, gone about this type of a process in order to develop, you know, this custom roxigen that serves a a particular purpose. So being able to sort of peel back the curtains, for those types of packages that do that, you know, leveraging Mel's blog post here was was really neat to see how it all comes together, how it all works together, you know, all of the different things that you have to watch out for including updates to the the description, file within your R package.
You know, leveraging, this this these particular packages, and the the the config, the needs, and the build, and all sorts of things like that to be able to specify exactly what you're doing here, the the custom rocklet. You know, I took a look at the vignette that Ma'el said she used for for quite a bit of this blog post, called extending roxigen 2, and was able to to take a look, at, you know, how they explain and describe going about this particular process, you know, adding a new dotrd tag and and a lot of the things that Mel did here. Obviously, you know, we look peel back the curtains on that package itself for Oxygen 2 and no surprise Hadley Wickham's the lead developer on that with a couple other folks, including Peter Dannenberg, Gavarsardi, and Emmanuel, Uster.
So a really powerful team working on this set of very powerful functions, and it's it's sort of another way. I don't know. I think of it somewhat akin to, like, object oriented programming where, you know, we're able to just push the boundaries and extend R to do, you know, some pretty incredible things just beyond sort of the functional side that we all think of.
[00:32:27] Eric Nantz:
Yeah. And the package I was thinking of at the name escaping until now is called Maestro. The one that we're there we covered a few weeks ago on on the show. It's gotten this new take on these data specific pipeline, but their their whole API, if you will, for getting opt into it is to decorate your function with these custom Roxtrogen tags called, like, Maestro frequency, Maestro start time. So I have to look at the source, and and if I look at the source of it, it'll probably be very similar to what I was outlining here. So like I said, it's been fascinating to see behind the scenes what's happening with the power of our oxygen to take what you can customize yourself, but then to build the machinery to do things with it. So, yeah, fascinating area.
In my daily work, I haven't had to, but now that I'm consuming more of these, types of packages, it's great to know what's happening here in case that does inspire future work. So, you know, I feel like I've only scratched the surface of what rOxygen 2 can offer. This is just another kind of eye opener for me of just the immense power that that particular package has for not just generating your documentation, but frankly, to give you the gateway to do so much more.
[00:33:42] Mike Thomas:
Yeah. I think it's time to spin up a side project where we kick the tires on this.
[00:33:47] Eric Nantz:
Yeah. Don't please stop nerdcyping me, Mike. I can't take it anymore.
[00:33:53] Mike Thomas:
Yeah. No. I always thought it was just pure magic, those packages like Maestro and Plumber, but, turns out there's actually something to it.
[00:34:12] Eric Nantz:
Well, honestly, Mike, it wouldn't be in our weekly show without at least some visit to what I like to call the visualization corner. And we even know we're an audio podcast, we love talking about the best practice of visualization. And one of the key thought leaders in this space over the years has been the author of our last highlight today, Nicole Rene, who is, of course, a lecturer for health sciences over at the Lancaster Medical Institute. So in this great blog post, she talks about 5 particular tips that she's been using, especially in her latest visualizations where she shares her takes on the TidyTuesday datasets out there that I think we all can benefit from.
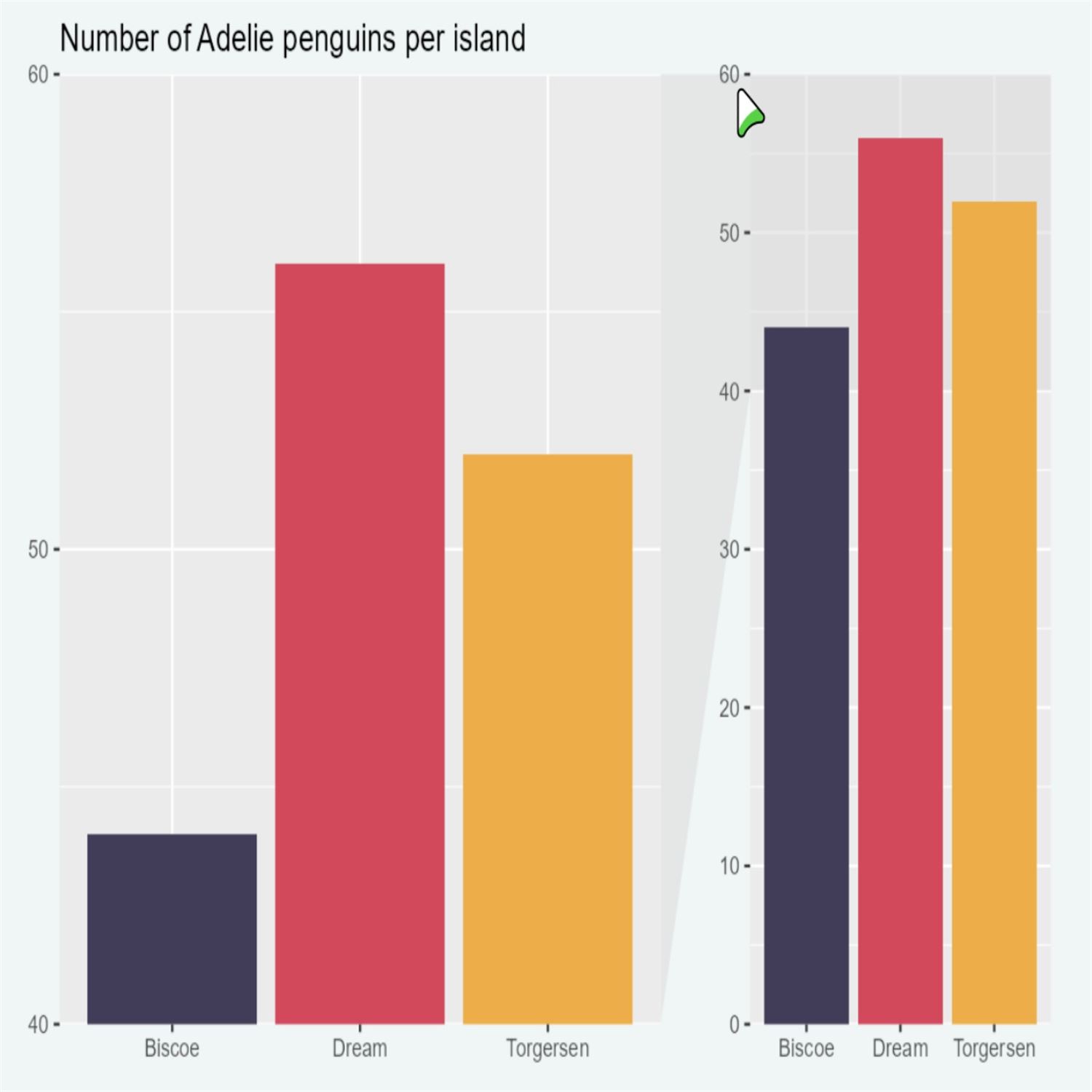
One of which, this is one that I've encountered quite a bit, is that there may be cases where by default, you'll get a certain range of your y axis that is a little more truncated, but there may be cases where maybe you don't wanna do that. Maybe you wanna show what in theory could be the lowest number or the lowest limit, and in particular for in the case of bar charts, having a start at 0 for, say, your frequencies or percentages or whatnot. Most of the time, that's going to help you potentially navigate what could be misleading representations on that. And in this example, she's got looking at the, the very fun penguins dataset looking at the number of penguins per island.
And on the left side of this, she's got a bar chart with those frequencies where the number on the y axis starts at 0 and then another where it starts all the way at 40. Now that might not be exactly a fair representation depending on what what you wanna do with these data. Now there may be there may be cases where it ends up being appropriate. But maybe in the case where they all have a similar height, maybe you don't get a lot of going all the way to the theoretical lowest limit. But there are other cases where other parts of the data that you might superimpose on these bar charts might be more accurate if you wanna impose, say, standard deviations or other types of metrics on top. So, again, that's kind of a case by case basis. But in case of frequencies, a lot of times, especially in my line of work, we still have to start from what literally is the ground 0, so to speak, what kind of frequencies or percentages those numbers could be based on.
And so like I said, yeah, there there is a trade off. There may be some situation such as in line charts where maybe starting at 0 kind of loses the key focus of that visualization. And the next example, she has a line chart where it shows the time course of how a variable, in this case the population of Germany, is changing over time. And in one plot, she does indeed start it at 0 on the right, but then on the left she starts it at a much higher number. So you can see the the increase, the kind of more, you know, what looks like a pretty rapid increase in the early debt part of the century versus kind of leveling off and then increasing again.
You kind of lose that nuance if you started at 0 and already the first measurement was already starting at a value already above, say, 60 or 70, you know, in 1,000,000 on that or, yeah, in 1,000,000 for that. So again, it's not like a one size fits all. You got to look at the context of the visualization you're telling here, the story that you're trying to tell or the insight to really say to yourself, do I really need to go to that lower limit or not? But that that's a nice segue into when you have, say, data of, like, 2 continuous or numeric variables and you're doing the tried and true scatterplot, sometimes you got to look at ways of doing appropriate range for that because sometimes you might not quite get the full gist of it if you are truncating that range too much or widening it too much.
And in her example here, she's got a scatter plot that we often use in model assessments and regression models, a scatter plot of the residuals, which is basically on the y axis. You've got the residual from observed versus the fitted values on the x axis. If you are looking for patterns like, say, symmetry or other, like, you know, indications that maybe you're violating a assumption such as the normal distribution, you wanna be able to compare pretty clearly to those points approaching, say, the zero line on the y axis where the residual and the fitted and observed are basically the same.
So when you truncate the axes going more in one direction versus another, it's hard to really tease out that pattern of potential symmetry if you have, like, the points above 0, the axis limits more than the axis limits below it. So there's a good example where it's a little nuanced, but you can kind of see it'd be harder to tell that pattern if you are not consistent with the level of the range you have above and beyond or above and lower that zero value. And she says similar advice could be done with another tried and true metplot assessment called the qqplot, also used to assess normality.
So again, making sure that you're akin to what type of visual or insight you want to tell to help dictate just how you're gonna, you know, change those limits on those particular axes. Up next, Mike, I didn't wanna touch this one. I'm gonna leave it to you because this can be a controversial topic in some circles in the visualization world, is dealing with the potential of multiple y axis. So why don't you walk us through her advice here?
[00:40:25] Mike Thomas:
Yeah. I remember a time where, you know, having 2 y axes on the same chart, was really, really frowned upon. And I think it got so frowned upon and and so much flack that that maybe, some folks out there started to say, hey. Well, it's maybe it's not as bad as we're completely making it out to be. But I think probably the general consensus is still that it's not the best idea and there's probably a better way to go about ensuring that the conclusions that are drawn from your visualization are the the correct and appropriate conclusions, and your audience is not being misled, by, you know, the differences in scale across these 2 y axes on on the same chart, which can have a big impact in, you know, how the data is interpreted, especially when there's intersection, between those those two particular lines, in my experience.
So I I love, the idea that Nicola had here, where instead of, you know, plotting this chart with these 2 y axes because the scale of the the y axes are very different, instead, bring them both to a down to a, like, percentage change basis, such that you can have a single y axis and you can compare, you know, these on a percent basis a little bit more apples to apples comparison, as opposed to, you know, having to wrangle those 2 very different, y axis scales. And, you know, I I think the plot that she shows here after converting to a percentage change, that the values for both, you know, sort of categories here in the legend, really tells the story that, the author would be trying to tell to the audience much better, than taking a look at what's going on in those dual y axis plots. So that's that's a great idea.
The last one, that she talks about is is how alphabetical categories often don't make sense, and you wanna ensure that you are ordering, you know, in the case of a bar chart in her example, ordering those bars in a way that is going to make the most sense for a user. So if your x axis is representing days of the week, probably not a good idea to order your x axis alphabetically. You probably wanna order it chronologically, right, from from Sunday to Saturday or from Monday to Sunday, in her example here. So you really have to think about and and we'll wrap up here at the end, but I I think a lot of what we're talking about here is just coming down to context and thinking about, you know, the practical ways that your audience are going to consume the data that you're you're showing them, and and making sure that you're thinking critically about what you are showing them. Another one here is, you know, instead of, on a horizontal bar chart, you know, if you're using chord flip and ggplot2, with a with a bar chart. Instead of, you know, ranking that alphabetically again, you might want to start with the bar, at the top that has the the highest magnitude or extends the furthest to the right, if you will. So, you wanna you wanna order your plot by the values on the y axis, if you will, as opposed to the the labels on the x axis prior to to flipping and inverting that scale. Another thing, you know, this is a very Albert Rapp style blog post. It reminds me of a lot of the the work that that he's done here that I think Nicole is doing a great job articulating as well. A little free tip out there that I think I got from either Nicole or Albert in the past is stick your conclusion at in the title, And that will really help, you know, drive home the point that you were trying to make. If there is a point that you're trying to make, you know, sometimes we're really just purely displaying data. But a lot of times, you know, when you're doing data visualization to communicate the data to an end audience, there's there's really, sort of, a standout point to that chart that you want to get across to them. And instead of saying, hey, this chart, shows, you know, car type by weight, we can say, you know, linking Continental has the the highest weight across, you know, the 20 cars in this this particular data set or something like that. You can stick that in the title as opposed to just really making that title an explanation of what's on the the x axis and what's on the y axis. So, excellent job by Nicola. You know, she's fantastic in these blog posts. Obviously, interspersed within these blog posts are the visuals as well as the collapsed code that she used to generate these visuals, I think a great way to round out the highlights this week.
[00:44:59] Eric Nantz:
Yeah. And I that particular point about the bar charts and, you know, the reorder that based on frequency, you often see that quite a bit as you look at the impact of different machine learning models when we look at the impact of variables inside those models, like variable importance or reductions in root mean square error or whatnot, they'll often order that by the one that's most influential according to that metric and then going down further. So, yeah, I've seen her put a lot of these things in practice even in her machine learning workshops that she's been giving a couple of times now.
So, yeah, I think that the idea of having a bit of common sense and maybe, you know, some things that I often do with my app development too is getting feedback early on in the process of, like, that particular output of that visualization, making sure that the key, you know, stakeholders or customers that are gonna be viewing that report or reviewing that app are understanding the intent of what that visualization is trying to show. So getting that feedback sometimes from other people, even if you yourself feel like you've nailed it, so to speak, but getting that extra set of eyes is never a bad idea. And we know the world of visualization can be a bit subjective sometimes. So being able to get that get that opinion early on is is a massive help for sure. That's a great point as well, Eric. Yep. And, we're we're running a little long here. So we're actually gonna wrap up the shop here a little sooner than earlier, but we're gonna leave you with our usual, calls to contribute to our weekly itself, which to get keep the project going. It's, you know, it's, of course, driven by the community.
So one of the best ways you can do that is to share that great new blog post, that new package, that new insight that has got your workflows all all, Jim, you know, improved or whatever. So you can do that via a poll request at the main website at arewehere.org. There's a link to a poll request in the top right corner. It's all marked down. You just fill out a little template, and then you'll be glad for the curator of that particular week to get that resource in the upcoming issue. And, also, we love hearing from you as well, so you can get in touch with us through a few different ways. We have a contact page linked in the episode show notes that you can grab to directly from your podcast player. You can also reach out to us on the, the the podcast apps that are more modern, like Podverse or Phon or Cast O Mac, and send us fun little boost along the way, which a little, side tangent here. But, my good friends at Jupiter Broadcasting that run the CODA radio show authored by, Chris Fischer and Michael Dominick, they've been running a little contest to see what should be the official language of the show.
You would not believe which language is up to run. Based on some recent boost, the r language is almost number 1 now. So, who knows? We may get this in vected into other podcasts as well. We'll see about that. So that that's been fun. If you listen to that show, you may hear from yours truly on that from time to time. Nonetheless, several ways to get in touch with us are on social media as well. You can find me mostly on Mastodon these days with at our podcast at podcast index dot social. You can also find me on LinkedIn. Just search my name, and you'll you'll find me there. And it's frankly on the weapon x thing at the r cast. And, Mike, working with us, get a hold of you. You can find me on mastodon@mike_thomas@phostodon.org,
[00:48:29] Mike Thomas:
or you can find me on LinkedIn if you search Ketchbrook Analytics, k e t c h b r o o k. You can see what I'm up to.
[00:48:37] Eric Nantz:
Very good. Very good. Well, that's, never a dull moment in our lives. So we're gonna close-up shop here, but, of course, we thank you so much for listening from wherever you are. And, little programming note, next week, we might be on at a different time as yours truly is gonna be involved in a virtual event at our usual recording day. So we will we'll communicate one way or another what happens. But, nonetheless, we hope you enjoyed this episode of ROCE Highlights, and we will be back with another episode of Rwicky Highlights either next week or soon.
Hello, friends. We're back. That was a 178 of the R Weekly highlights podcast. Almost midway through September already. Time is flying by, but what never slows down is also the fast pace of the r community, where in this podcast we cover the awesome highlights and other resources that are shared every single week at rweekly.org. My name is Eric Nantz, and I'm delighted you join us today from wherever you are around the world. And joining me at the hip with never a dull moment in his life going on right now is my co host, Mike Thomas. Mike, how are you doing today? Doing well, Eric. Hanging in there. I am potentially in the process of of moving, which is both
[00:00:41] Mike Thomas:
exciting and and crazy and stressful all at the same time. So all the emotions.
[00:00:48] Eric Nantz:
Yep. It's it's hard to grasp just one at a time. It all just happens at once. So our our, best of luck to you, and hopefully, you don't lose anything valuable on the move
[00:00:59] Mike Thomas:
over. I'll make sure that the microphone stays intact, and we'll be sure to to make sure that the new podcast space is is set up ready to go.
[00:01:08] Eric Nantz:
Well, you know, that that's that's the real important stuff. You know, those those pets or whatever. Ah, no. You need the mic. No. I'm I'm I'm I'm good. I we know where your priorities are. We we we we get it. We get it. That's right. Yeah. I'm, not moving anytime soon because that would be a herculean effort in this, house here to try and pick up everything there. But luckily, I don't have to think about that. I get to think about the great art content we get to talk about today. And in this week's issue has been curated by Batool Almarsak. And as always, she had tremendous help from our fellow Arruki team members and contributors like all of you around the world with your poll requests and other suggestions. And so one of the biggest reasons we do our weekly is the great content that all of you out there, whether you're in the data science world or other parts of industry, have been showcasing your learnings perhaps through either personal websites, personal blogs, and whatnot.
And, you know, it does beg the question sometimes when we put these resources online, how do we kinda guarantee really tight linkages or ways to get to that content even as the landscape of, like, web hosting providers or other ways that we're deploying these sites change over time? Well, in our first high, we're gonna look at a pretty innovative way to kind of future proof potentially ways to make your your insights on, say, a blog more easily shareable that could be durable for the test of however evolving the tech landscape is. And in particular, this first highlight is coming to us from Athanasia Mowinkle, who is a neuroscientist over in Europe where she talks about making her blog fair.
Now I'm not talking about the fair that I often hear from my kids gripe to me when they say, it's not fair. I don't get to do this and that. No. I'm not talking about that kind of fair. The fair we're talking about here is an acronym for findable, accessible, interoperable, and reusable. Boy, that sort of speaks to me with a lot of the reproducibility aspects we talk about all the time with framers, like r markdown and quartile and whatnot. But, of course, this applies to any insights we author or generate. Ethe Nagia has, has worked on her blog for quite some time, and she was inspired actually about a newsletter that she subscribes to from Heidi Seibold about her approach to making her blog this FAIR compliant, if you will.
And in Heidi's approach, we get an outline that it's basically, hosted as a Jekyll website, which for those aren't familiar, Jekyll was a framework and I believe based in Ruby to do, like, a static site kind of generation, was used very many years in the GitHub world. But Heidi also has, you know, a newsletter that she turns into RSS or Adam feed, and then that will post automatically based on the content in her site. And then she also adds her blog to a service called Rogue Scholar, which I believe is an archive for more of the academic or research type blogs.
But what comes with that is robust DOIs or these kind of unique document identifiers and additional metadata that could then be searchable and easily accessible. Athanasia's workflow is pretty similar. It's a Hugo site. Now, again, Hugo, I've been a big fan of for many years. That's what powers the blog down package that EYC has created with, his work at Posit earlier and that. And then she also hosted on GitHub Pages. Again, a framework I like to use quite a bit for hosting. Again, all marked down all the time. And with Hugo, you get an automatic RSS feed. And then she has an idea for a GitHub action that will register each new post to a service called Zenodo, another one of these research type archival services.
And then via their API, she's going to be able to get these robust document identifiers as well as adding additional metadata so that that can be searchable as well. There are a little nuance differences from what Heidi approached, but we're going to walk through just how Athanasia has accomplished this in her workflow here. So with that, we're going to need some packages, right, because she wants to do this all in R because we want to do R all the things here. So we need to communicate with a web service, the Zenodo API. So with that, the h t t r two package authored by Hadley Wickham is a great candidate to interface with those connections.
And then with Hugo and as well as Portal itself, another of these static site generators, many times your content will have a YAML front matter at the top that denotes certain metadata, certain options, or whatnot. So how do you interpret that? Well, appropriately enough, there is an R package called YAML, y a m l, to let you interrogate both from a consuming perspective and actually writing YAML if you need to to documents or whatnot. And then the last step is she's going to take a bit of a detour after what Heidi did. She wants to make sure her blog posts, which often have a great mix of visual content as well as tabular summaries and other narrative to be easily self contained in one artifact.
So she wants to convert these posts to PDF, and for this she is going to turn to quarto for this part of the workflow. So we're going to walk through this step by step, but the first step of this is actually trying to prepare the data of these posts so that it can be archived. And she's got some some example code here. The first grab all these markdown files that make up the source of the posts themselves, And in Hugo, you can do what are called page bundles, which basically means every new page that you make in your site is its own folder with within it an index dot MD file and many other supporting files such as images or whatnot.
So she wanted an easy way to grab the source of all those index dot MDs. So she's got a little, regex action going here and list that files. Not too difficult. She knows the file name, so it's literally index //md is like the regex on that front. Once she got that, now she's got this this vector of files on her file system to have all of the blog content. Okay. Now, examining, we walked through one of these posts that she has, in this case, about random effects. She then reads the contents of that file with the relines function, and you see if you print that out like in the example here, you've get each line or each element is a line from the file. So you got the YAML at the top and then a few blanks and then you've got the actual content itself.
So we've got the content read read in r now. Now how do we extract that metadata first? Like, let's parse the YAML first, and then we'll deal with the content afterwards. There is a handy function within rmarkdown itself that she was able to get some recommendations, from a good friend of hers that we'll hear about later in the highlights of a function called YAML front matter exposed by R Markdown itself, where you feed in the contents of that post with both the YAML and whatever the narrative you have. And it is intelligent enough to scrape that YAML section and then make variables for each field with its actual values. So you see it's got, like, the title, author, you know, date, and even the nested elements are like nested list elements. It's very handy, very, very straightforward.
And so she's able to get that YAML metadata, but she wants to add more to it than just what's in the YAML. She wants a high level description of the post, which in the Hugo world doesn't quite come automatically. You have to kind of inspect the rest of the post to kind of maybe take a portion of it. So she wants to make some code that will do this. So she wrote a custom function that's doing a bit of a grip of, like, all that content that's after the YAML delimiters and then be able to grab that and then see what are the positions where that content actually starts.
And then from there, she's able to then look for what's like the first paragraph of that post or maybe the first few sentences. She's able to grab that with more custom functions of a summary of it and then inject that into the existing metadata variable. So now she's got a simple 2, 3 sentence description vector for that metadata summary. So with that, she's got the metadata ready to go. Now here comes the fun part. As I mentioned, she wants to use the Zenodo service to start archiving the content and have it searchable, but just like anything, an API has got its own set of documentation, what it expects to have.
And, apparently, she's had to do a bit of trial and error, which I can certainly relate to because sometimes I get the requests horribly wrong, and sometimes you get those cryptic errors back of, like, what happened and what didn't happen. So through this, exploration, she was able to compose kind of another list structure of those metadata fields, but in the way that the Zenodo API expects. So it looks like kind of a nested list of elements, which isn't too bad, but it's a lot of just brute force trial and error to get to that point. So then that's not all. As I mentioned, she wants a static archive of the content itself, not just from the metadata, but of the entire post.
That's where our good friend Quartal comes in where once again she's able to leverage a function from Quartal, in this case Quartal render, to compile the web based version or the markdown version into a PDF. But she had a little rabbit hole to navigate here. You know what she tried to do, Mike? She tried that types method, and that didn't quite work. But there's always a plan b. Right? And plan b is good old LaTeX. As much as I rag on it sometimes sometimes it's still the best tool to get the job done.
[00:11:59] Mike Thomas:
Yeah. Unfortunately, Athanasia tried types first and some of the images were not being resized correctly is what she said so that's why she had to switch back to Latex. And, you know, that's a little disheartening for me to hear. I think it's, you know, they're still working on ironing out some of the kinks of of types and how it interacts with quarto. I I do still believe it's the future, but, if you are trying to do, you know, very specific things and, you know, size images a very particular way on the page, you might have a little bit more customizability and full control when you're leveraging LaTeX, as compared to to types, especially if you you actually know how to write a little bit of LaTeX as well.
We are are in the process at Catchbook. I was hoping for our next big model validation project, which are these PDF deliverables, that we could switch over to, types instead of our our current sort of LaTex, framework. But we do need a lot of that customizability to make things sort of look perfect on the page for our clients. So, I'm I'm hesitant to make that switch yet, especially after reading this this blog post. But one of the nice things is you can try the 2 and the the quarto code is still the same. Right? You're still using quarto render with your output format PDF, for the most part.
So it really cool that she was able to do that. I guess it's sort of unfortunate that you have to to render to PDF for the Zenodo service.
[00:13:32] Eric Nantz:
Right? Yeah. Yeah. My hope is that it would have some kind of dynamic view of that content, but it is what it is, I guess. Exactly.
[00:13:41] Mike Thomas:
So, as you said, sort of the the 3 packages that come together here are h t t r 2, YAML, and then what's the last one that I can't have? Quarto itself. And then Quarto itself. Right? So, the sort of the way that she's able to actually send this final request, to the HTTP RT or or to the Zenodo API via HTTR 2 is, obviously, whenever you're dealing with one of these APIs, you're gonna need an API key token. So she stores that as an environment variable called Zenodo API token, and then she has just a variable an object called Zenodo API endpoint, where she specifies the, you know, the URL endpoint of, this Zenodo API where she's going to be sending this request. And you gotta love h t t r two it just makes everything look so absolutely clean.
The the pipe syntax that we're using here in h t t r two starts with a request, then a a bearer token, essentially, where she passes that API token, and then your JSON body as well. And don't forget to use that auto on box equals true if you're switching back and forth between our lists and, JSON data that you are sending up to the API. The nice thing about HDR 2 as well that Athanasio demonstrates here is you can use the request dry run function to be able to see the query that's going out before you actually send it to the API. Take a look at that request and everything Once everything looks good, you can use, request perform to actually send your API request to Zenodo, get the status that comes back.
In in this case, it was a a 201 created, which, is is not the response that she got for many attempts as you said, while trying to figure out the all of the different metadata components for this API. And if you take a look at the blog post, there are a lot of pieces to this list, this metadata list that she puts together that need to be sent to this API, you know, essentially, different parameters that the API expects, you know, within the metadata. It's not just a title description, you know, the creators, her name, her or orchid, you have upload type, publication type, publication date, and about 5 other different parameters that have to be nested correctly in your r list in order for them to be passed correctly via JSON to the, to the, API service. It's you're able to take a look at what came back, from that JSON response and everything looks looks really, really good, and at that point in time, I think she has everything that she needs for the DOI that's actually going to be, get sent, via the GitHub action. It's gonna get published alongside the GitHub action for the most part.
So sort of the last section of of this blog post is actually adding that DOI to the YAML header or front matter, if you will, for the post, that is going to to end up being posted and published. So Afnazia is actually able to put together a single script. It looks like it's about maybe 200 lines here, that sort of put everything together, in one script and mostly it's it's functions here, which is really nice functional programming, that she's put together that walk through all of the different steps that we talked about in this blog post, in terms of, you know, sort of finding the the end of the section, you know, taking a look at whether or not a DOI is needed, you know, actually publishing to Zenodo, which is probably the biggest function, the biggest custom function that she's written and that's going to return, I believe, the path to the PDF file that has been generated by quarto.
And then once you actually have that PDF file and, you're ready to go here it's it's just a few lines of code that she has here, with a nice little s apply to to process files that that do not have a DOI, but are published and supply, those posts essentially and and run all those posts, that need a DOI to her service. And it's it's pretty incredible. Her next step is to to work on the GitHub actions component, which I I think should be fairly straightforward given that she's put, you know, all of the r code here together as best as possible. Obviously, when you're dealing with GitHub actions that's gonna be running on a machine that's not yours. So she will have to ensure that, you know, all of the dependencies including latex, which is probably not fun, when you're doing that in GitHub actions is are installed correctly, and execute correctly on that that GitHub actions runner. But I'm very excited to hopefully sort of see a follow-up here for the next step in this process, which is the GitHub action that's gonna do this all programmatically. So every time that she authors a new post on her website, it will automatically reach out to Zenodo, get that DOI, and publish things, the way that they should be.
[00:18:47] Eric Nantz:
Yeah. As you were talking, I went to that, GitHub repo, and sure enough, there are a few actions here. And I believe she's do indeed has that script that you just outlined in the GitHub, you know, workflows area itself. So I think she's got it. Credit to her. She's actually got 4 actions on there. My goodness. She's a GitHub action ninja, looks like. So I'm gonna have to take some learnings from this. But my goodness. What a what a great, you know, showcase of automation, but also just what you can do when you stitch these services and and workflows together. So I I think this shows a lot of inspiration as we're thinking about, hey, anybody generating or authoring their content, trying to future proof this to some extent? And, you know, we can't predict everything in the future. But, yeah, I'm intrigued by what this Sonoto service is offering her, but I may look at other ways too of making sure that what I produce, maybe it's, you know, the stuff I used to do with the shiny dev series or ever or this very podcast. Right? I wanna make sure this stands the test of time that no matter which fancy technologies out there, we can find a way to search it and be able to to grab it back. So, yeah, lots of lots of interesting nuggets here. And then I really appreciate towards the end of that of that script that she was outlining, she's got a check to make sure that she doesn't do this DOI process for posts that already have it, which is great to minimize, again, calls to an external service because the last thing you wanna do is accidentally DDoS something or worse yet lose your access to that API venture. So being intelligent enough to only run what you need, that's a that's a lifesaver when you do have APIs or even HPC computing. So lots of nuggets in that script that I think are quite inspirational here.
[00:20:41] Mike Thomas:
Absolutely. And, Eric, you and I, you know, don't do a lot of, I guess, academic publishing, but there is a gigantic community of people out there who do that, and I think that this blog post is going to be incredibly powerful and helpful for them.
[00:20:55] Eric Nantz:
Yeah. So definitely check out her, catalog on the re of the previous blog post. So there's a little bit of something for everybody in that world. Really, really good stuff. And one of the nice things about Athanasios' post is that she mentioned that she reached out to a couple of her trusted friends to give some recommendations on how to proceed. And one of those friends just happens to be the author of our next highlight here because Ma'al Salman returns to the highlights once again to talk about her recent discovery about creating and leveraging not just r oxygen 2 but custom r oxygen 2 tags.
Now this has been something I've never dived into myself, but I'm starting to see other packages in the our ecosystem try to do things like this where they'll have a custom tag. And based on that, their package will do additional processing or additional things on the side with it. So she, you know, introduction here, such as making sure that there are internal functions that are documented maybe for only developers and not for like the end user of a package. Also, being able to leverage or record certain standards that are expected for statistical functions.
And lastly, having tests from within our scripts themselves, and that in particular has been contributed by a package called roxy test as well. So I've seen these come through, but I never really knew what was the nuts and bolts on it. So I was supposed to gonna walk us through her journey on this and that she was looking for a way to help with the iGraph package. And for those that aren't aware, iGraph is one of the, you know, more standard and frankly, quite powerful packages that deals with network, network generation, network analysis for simple or complex networks.
Now are the r packages are binding to the c library of the same name, iGraph. And I I remember compiling this back in the day when I was getting into network analysis for the first time. And, admittedly, iGraph is, a bit of a bit of an ordeal to get into, but it's not insurmountable. But what she's learned as she's been working with iGraph is that there may be places where the r function definitely has documentation as it would have any r package, but it's depending on some source in the c library to make all that happen. And she wanted a way to link for a particular r function to the relevant c code binding and whatever it needs in terms of additional considerations within each of the functions manual pages.
So that looks like something that I wouldn't even know heads or tails of how to accomplish it, but we're gonna walk through how she, did this herself. So she starts with, outlining the workflow that ends up doing this. 1st, having, some kind of mapping of the existing documentation for the c library. Maybe you have to hand generate that yourself or hopefully you can scrape that somehow. And then in the rOxygen documentation header for a given function, add a new tag called atcdocs that's going to point to the source c function that that particular r function is using.
And then she says that's going to be kind of manual for now, but there may be ways to do that automatically later. And then building upon the tooling that our oxygen 2 gives you, giving you a way to parse that custom tag and do the necessary bits to write the manual page to link to it. So thankfully, not just showing telling us the workflow, she's going to walk through it for a hypothetical example here where she's got a minimal R package called HGB, where it's got a simple hello world type function. But she's going to put in a custom tag with the custom, literally custom tag, in the rOxygen header. And, of course, it by itself, it looks fine. Nothing's bad is going to happen, but rOxygen by default is not going to know what to do with that yet. So now she's leveraging what's documented in the rxn2vignette to say, okay, there is a method called Roxy tag parse Roxy tag custom. Yes. That is all one function call separated by underscores there, which is telling our oxygen 2 what to do when it sees a set a tag of a certain type.
So she's got some example snippets here where you can see straight from the vignette, you can write these custom functions that are going to either look at the tag and then also x and then be able to write it out as a new section in the docs based on seeing that tag named custom, taking in what was the material from it, and then putting it into this new section. And then well, we were just talking about LaTex earlier, Mike, when you look at an r help file, you see, like, a web view of it. But behind the scenes, that is LaTex style code when these are compiled. And so she has a last section a last function to format that custom rd section that she's making and puts in literally the the latex style code for the section and then an itemized list of the value of, I believe, that source file.
And then she's got the building blocks here. Now it's not quite done yet because then she's got to create what's called a rocklet that's going to help for this custom tag to be shared potentially with other packages that wanna leverage this. So this is an optional step. But if you think you've got a workflow that could benefit the community in your particular package, this is a great way to share that via what she's done here. She's running a custom Rocklet function that's going to declare this Rocklet. It's a fun name to say out loud. Hopefully, I'm saying it right. But then be able to process that and then to be able to export that out as a way for other users to to leverage that. So again, that might not always be the case, but that is one way they set the building block of actually sharing it.
And then there comes the question of, well, do we actually need a separate package to hold this new custom tag processing? And you may or may not need that all the time. There are cases where maybe it's so specialized it would be only your particular package is going to use this custom tag. It may not need to go to that external that extra effort of making an extra package out of it, but others might say, you know what? This is good enough or this is good for the community. Maybe we do want to share it. So there are ways that you could do that because you've got some narrative about where it might be helpful and where it might not. So in the case of the eye graph here, this was a custom tag that was already meant for eye graph itself. So she thinks that could live in the package itself. But again, there could be cases where you want to share that with a community.
So I've been fascinated by this because, again, I've seen packages come through our weekly recently where they say, add this custom tag in your oxygen header, and we're gonna do something with it. Whether it's like this testing generation or in particular that newer package that came out recently that gives you kind of a a workflow for ingesting, like, data in an ETL process, they're also built on our oxygen tags as well. So lots of interesting use cases for this. It'll take me a little bit to wrap my head around this, but it's nice to know that the machinery is there if we wanna do some custom processing with these documentation tags.
[00:29:37] Mike Thomas:
Yeah, Eric. This is interesting. Every once in a while, I come across a package that, allows you to essentially do things in your own package with, you know, these these are oxygen decorators. Right? I think Plumber is an example potentially of a package where we do that. Right? There's sort of That's right. These custom Roxygen, tags that that will stick on top of our code and and quote unquote decorate our code with that serve a specific purpose or, you know, execute the code that is underneath it or the functions underneath it, a particular way actually based upon the roxigen that's been written. You know, one of the the real standout things for me in this blog post is how many functions there are from the roxigen 2 package that I had no idea about, this tag markdown function, rd section function, rocklet function, all of these things that allow you to develop, the custom roxigen as Mel, you know, so eloquently sort of outlines here. I haven't particularly had a use case to do this, yet myself, but I I do leverage some packages, including Plumber and a couple others that that do this. And they they must have, you know, gone about this type of a process in order to develop, you know, this custom roxigen that serves a a particular purpose. So being able to sort of peel back the curtains, for those types of packages that do that, you know, leveraging Mel's blog post here was was really neat to see how it all comes together, how it all works together, you know, all of the different things that you have to watch out for including updates to the the description, file within your R package.
You know, leveraging, this this these particular packages, and the the the config, the needs, and the build, and all sorts of things like that to be able to specify exactly what you're doing here, the the custom rocklet. You know, I took a look at the vignette that Ma'el said she used for for quite a bit of this blog post, called extending roxigen 2, and was able to to take a look, at, you know, how they explain and describe going about this particular process, you know, adding a new dotrd tag and and a lot of the things that Mel did here. Obviously, you know, we look peel back the curtains on that package itself for Oxygen 2 and no surprise Hadley Wickham's the lead developer on that with a couple other folks, including Peter Dannenberg, Gavarsardi, and Emmanuel, Uster.
So a really powerful team working on this set of very powerful functions, and it's it's sort of another way. I don't know. I think of it somewhat akin to, like, object oriented programming where, you know, we're able to just push the boundaries and extend R to do, you know, some pretty incredible things just beyond sort of the functional side that we all think of.
[00:32:27] Eric Nantz:
Yeah. And the package I was thinking of at the name escaping until now is called Maestro. The one that we're there we covered a few weeks ago on on the show. It's gotten this new take on these data specific pipeline, but their their whole API, if you will, for getting opt into it is to decorate your function with these custom Roxtrogen tags called, like, Maestro frequency, Maestro start time. So I have to look at the source, and and if I look at the source of it, it'll probably be very similar to what I was outlining here. So like I said, it's been fascinating to see behind the scenes what's happening with the power of our oxygen to take what you can customize yourself, but then to build the machinery to do things with it. So, yeah, fascinating area.
In my daily work, I haven't had to, but now that I'm consuming more of these, types of packages, it's great to know what's happening here in case that does inspire future work. So, you know, I feel like I've only scratched the surface of what rOxygen 2 can offer. This is just another kind of eye opener for me of just the immense power that that particular package has for not just generating your documentation, but frankly, to give you the gateway to do so much more.
[00:33:42] Mike Thomas:
Yeah. I think it's time to spin up a side project where we kick the tires on this.
[00:33:47] Eric Nantz:
Yeah. Don't please stop nerdcyping me, Mike. I can't take it anymore.
[00:33:53] Mike Thomas:
Yeah. No. I always thought it was just pure magic, those packages like Maestro and Plumber, but, turns out there's actually something to it.
[00:34:12] Eric Nantz:
Well, honestly, Mike, it wouldn't be in our weekly show without at least some visit to what I like to call the visualization corner. And we even know we're an audio podcast, we love talking about the best practice of visualization. And one of the key thought leaders in this space over the years has been the author of our last highlight today, Nicole Rene, who is, of course, a lecturer for health sciences over at the Lancaster Medical Institute. So in this great blog post, she talks about 5 particular tips that she's been using, especially in her latest visualizations where she shares her takes on the TidyTuesday datasets out there that I think we all can benefit from.
One of which, this is one that I've encountered quite a bit, is that there may be cases where by default, you'll get a certain range of your y axis that is a little more truncated, but there may be cases where maybe you don't wanna do that. Maybe you wanna show what in theory could be the lowest number or the lowest limit, and in particular for in the case of bar charts, having a start at 0 for, say, your frequencies or percentages or whatnot. Most of the time, that's going to help you potentially navigate what could be misleading representations on that. And in this example, she's got looking at the, the very fun penguins dataset looking at the number of penguins per island.
And on the left side of this, she's got a bar chart with those frequencies where the number on the y axis starts at 0 and then another where it starts all the way at 40. Now that might not be exactly a fair representation depending on what what you wanna do with these data. Now there may be there may be cases where it ends up being appropriate. But maybe in the case where they all have a similar height, maybe you don't get a lot of going all the way to the theoretical lowest limit. But there are other cases where other parts of the data that you might superimpose on these bar charts might be more accurate if you wanna impose, say, standard deviations or other types of metrics on top. So, again, that's kind of a case by case basis. But in case of frequencies, a lot of times, especially in my line of work, we still have to start from what literally is the ground 0, so to speak, what kind of frequencies or percentages those numbers could be based on.
And so like I said, yeah, there there is a trade off. There may be some situation such as in line charts where maybe starting at 0 kind of loses the key focus of that visualization. And the next example, she has a line chart where it shows the time course of how a variable, in this case the population of Germany, is changing over time. And in one plot, she does indeed start it at 0 on the right, but then on the left she starts it at a much higher number. So you can see the the increase, the kind of more, you know, what looks like a pretty rapid increase in the early debt part of the century versus kind of leveling off and then increasing again.
You kind of lose that nuance if you started at 0 and already the first measurement was already starting at a value already above, say, 60 or 70, you know, in 1,000,000 on that or, yeah, in 1,000,000 for that. So again, it's not like a one size fits all. You got to look at the context of the visualization you're telling here, the story that you're trying to tell or the insight to really say to yourself, do I really need to go to that lower limit or not? But that that's a nice segue into when you have, say, data of, like, 2 continuous or numeric variables and you're doing the tried and true scatterplot, sometimes you got to look at ways of doing appropriate range for that because sometimes you might not quite get the full gist of it if you are truncating that range too much or widening it too much.
And in her example here, she's got a scatter plot that we often use in model assessments and regression models, a scatter plot of the residuals, which is basically on the y axis. You've got the residual from observed versus the fitted values on the x axis. If you are looking for patterns like, say, symmetry or other, like, you know, indications that maybe you're violating a assumption such as the normal distribution, you wanna be able to compare pretty clearly to those points approaching, say, the zero line on the y axis where the residual and the fitted and observed are basically the same.
So when you truncate the axes going more in one direction versus another, it's hard to really tease out that pattern of potential symmetry if you have, like, the points above 0, the axis limits more than the axis limits below it. So there's a good example where it's a little nuanced, but you can kind of see it'd be harder to tell that pattern if you are not consistent with the level of the range you have above and beyond or above and lower that zero value. And she says similar advice could be done with another tried and true metplot assessment called the qqplot, also used to assess normality.
So again, making sure that you're akin to what type of visual or insight you want to tell to help dictate just how you're gonna, you know, change those limits on those particular axes. Up next, Mike, I didn't wanna touch this one. I'm gonna leave it to you because this can be a controversial topic in some circles in the visualization world, is dealing with the potential of multiple y axis. So why don't you walk us through her advice here?
[00:40:25] Mike Thomas:
Yeah. I remember a time where, you know, having 2 y axes on the same chart, was really, really frowned upon. And I think it got so frowned upon and and so much flack that that maybe, some folks out there started to say, hey. Well, it's maybe it's not as bad as we're completely making it out to be. But I think probably the general consensus is still that it's not the best idea and there's probably a better way to go about ensuring that the conclusions that are drawn from your visualization are the the correct and appropriate conclusions, and your audience is not being misled, by, you know, the differences in scale across these 2 y axes on on the same chart, which can have a big impact in, you know, how the data is interpreted, especially when there's intersection, between those those two particular lines, in my experience.
So I I love, the idea that Nicola had here, where instead of, you know, plotting this chart with these 2 y axes because the scale of the the y axes are very different, instead, bring them both to a down to a, like, percentage change basis, such that you can have a single y axis and you can compare, you know, these on a percent basis a little bit more apples to apples comparison, as opposed to, you know, having to wrangle those 2 very different, y axis scales. And, you know, I I think the plot that she shows here after converting to a percentage change, that the values for both, you know, sort of categories here in the legend, really tells the story that, the author would be trying to tell to the audience much better, than taking a look at what's going on in those dual y axis plots. So that's that's a great idea.
The last one, that she talks about is is how alphabetical categories often don't make sense, and you wanna ensure that you are ordering, you know, in the case of a bar chart in her example, ordering those bars in a way that is going to make the most sense for a user. So if your x axis is representing days of the week, probably not a good idea to order your x axis alphabetically. You probably wanna order it chronologically, right, from from Sunday to Saturday or from Monday to Sunday, in her example here. So you really have to think about and and we'll wrap up here at the end, but I I think a lot of what we're talking about here is just coming down to context and thinking about, you know, the practical ways that your audience are going to consume the data that you're you're showing them, and and making sure that you're thinking critically about what you are showing them. Another one here is, you know, instead of, on a horizontal bar chart, you know, if you're using chord flip and ggplot2, with a with a bar chart. Instead of, you know, ranking that alphabetically again, you might want to start with the bar, at the top that has the the highest magnitude or extends the furthest to the right, if you will. So, you wanna you wanna order your plot by the values on the y axis, if you will, as opposed to the the labels on the x axis prior to to flipping and inverting that scale. Another thing, you know, this is a very Albert Rapp style blog post. It reminds me of a lot of the the work that that he's done here that I think Nicole is doing a great job articulating as well. A little free tip out there that I think I got from either Nicole or Albert in the past is stick your conclusion at in the title, And that will really help, you know, drive home the point that you were trying to make. If there is a point that you're trying to make, you know, sometimes we're really just purely displaying data. But a lot of times, you know, when you're doing data visualization to communicate the data to an end audience, there's there's really, sort of, a standout point to that chart that you want to get across to them. And instead of saying, hey, this chart, shows, you know, car type by weight, we can say, you know, linking Continental has the the highest weight across, you know, the 20 cars in this this particular data set or something like that. You can stick that in the title as opposed to just really making that title an explanation of what's on the the x axis and what's on the y axis. So, excellent job by Nicola. You know, she's fantastic in these blog posts. Obviously, interspersed within these blog posts are the visuals as well as the collapsed code that she used to generate these visuals, I think a great way to round out the highlights this week.
[00:44:59] Eric Nantz:
Yeah. And I that particular point about the bar charts and, you know, the reorder that based on frequency, you often see that quite a bit as you look at the impact of different machine learning models when we look at the impact of variables inside those models, like variable importance or reductions in root mean square error or whatnot, they'll often order that by the one that's most influential according to that metric and then going down further. So, yeah, I've seen her put a lot of these things in practice even in her machine learning workshops that she's been giving a couple of times now.
So, yeah, I think that the idea of having a bit of common sense and maybe, you know, some things that I often do with my app development too is getting feedback early on in the process of, like, that particular output of that visualization, making sure that the key, you know, stakeholders or customers that are gonna be viewing that report or reviewing that app are understanding the intent of what that visualization is trying to show. So getting that feedback sometimes from other people, even if you yourself feel like you've nailed it, so to speak, but getting that extra set of eyes is never a bad idea. And we know the world of visualization can be a bit subjective sometimes. So being able to get that get that opinion early on is is a massive help for sure. That's a great point as well, Eric. Yep. And, we're we're running a little long here. So we're actually gonna wrap up the shop here a little sooner than earlier, but we're gonna leave you with our usual, calls to contribute to our weekly itself, which to get keep the project going. It's, you know, it's, of course, driven by the community.
So one of the best ways you can do that is to share that great new blog post, that new package, that new insight that has got your workflows all all, Jim, you know, improved or whatever. So you can do that via a poll request at the main website at arewehere.org. There's a link to a poll request in the top right corner. It's all marked down. You just fill out a little template, and then you'll be glad for the curator of that particular week to get that resource in the upcoming issue. And, also, we love hearing from you as well, so you can get in touch with us through a few different ways. We have a contact page linked in the episode show notes that you can grab to directly from your podcast player. You can also reach out to us on the, the the podcast apps that are more modern, like Podverse or Phon or Cast O Mac, and send us fun little boost along the way, which a little, side tangent here. But, my good friends at Jupiter Broadcasting that run the CODA radio show authored by, Chris Fischer and Michael Dominick, they've been running a little contest to see what should be the official language of the show.
You would not believe which language is up to run. Based on some recent boost, the r language is almost number 1 now. So, who knows? We may get this in vected into other podcasts as well. We'll see about that. So that that's been fun. If you listen to that show, you may hear from yours truly on that from time to time. Nonetheless, several ways to get in touch with us are on social media as well. You can find me mostly on Mastodon these days with at our podcast at podcast index dot social. You can also find me on LinkedIn. Just search my name, and you'll you'll find me there. And it's frankly on the weapon x thing at the r cast. And, Mike, working with us, get a hold of you. You can find me on mastodon@mike_thomas@phostodon.org,
[00:48:29] Mike Thomas:
or you can find me on LinkedIn if you search Ketchbrook Analytics, k e t c h b r o o k. You can see what I'm up to.
[00:48:37] Eric Nantz:
Very good. Very good. Well, that's, never a dull moment in our lives. So we're gonna close-up shop here, but, of course, we thank you so much for listening from wherever you are. And, little programming note, next week, we might be on at a different time as yours truly is gonna be involved in a virtual event at our usual recording day. So we will we'll communicate one way or another what happens. But, nonetheless, we hope you enjoyed this episode of ROCE Highlights, and we will be back with another episode of Rwicky Highlights either next week or soon.